






这一章的课后题基本都是理论推导,自己会了但没整理,所以当个答案搬运工,记录一下hhh。
原文章:https://datawhalechina.github.io/d2l-ai-solutions-manual/#/ch03/ch03?id=_31-%e7%ba%bf%e6%80%a7%e5%9b%9e%e5%bd%92
3.1 线性回归

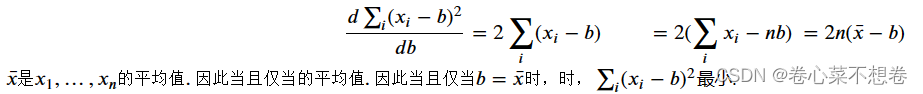






3.2 线性回归的从0开始实现


import torch
# 生成数据
x = torch.randn(100, 1)
y = 30 * x
# 定义模型
model = torch.nn.Linear(1, 1)
# 定义损失函数和优化器
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(500):
# 前向传播
y_pred = model(x)
# 计算损失
loss = criterion(y_pred, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(model.weight)
print(model.bias)





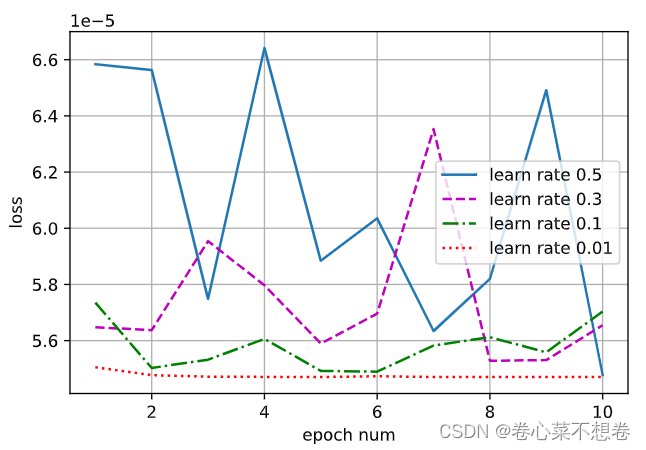
lrs = [0.5, 0.3, 0.1, 0.01]#前面建立模型什么的代码都一样,只有这里lr弄了多个数,用于比较
num_epochs = 10
net = linreg
loss = squared_loss
batch_size = 10
all_lrs = []#多了个定义数组
for lr in lrs:#将所有的lr都遍历一遍
train_lrs = []
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
train_lrs.append(float(train_l.mean()))
all_lrs.append(train_lrs)#弄到all_lrs里
#开始画图
epochs = np.arange(1, num_epochs+1)
d2l.plot(epochs, all_lrs, xlabel='epoch num', ylabel='loss',
legend=[f'learn rate {lr}' for lr in lrs],
figsize=(6, 4))


3.3 线性回归的简洁实现



类似书上:
3.4 softmax回归
3.5 图像分类数据集
3.6 softmax回归的从零开始实现
3.7 softmax回归的简洁实现
剩下的大家可以直接看这个书https://datawhalechina.github.io/d2l-ai-solutions-manual/#/ch03/ch03?id=_34-softmax%e5%9b%9e%e5%bd%92















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









