






 文章探讨了企业在收集用户数据以优化算法时面临的隐私问题,介绍了数据匿名化和差分隐私的概念。差分隐私通过添加随机噪声来保护用户隐私,尽管在大型数据集中效果显著,但在小型数据集上可能不准确。文章还通过计算平均年龄的例子展示了差分隐私如何防止个人信息泄露。
文章探讨了企业在收集用户数据以优化算法时面临的隐私问题,介绍了数据匿名化和差分隐私的概念。差分隐私通过添加随机噪声来保护用户隐私,尽管在大型数据集中效果显著,但在小型数据集上可能不准确。文章还通过计算平均年龄的例子展示了差分隐私如何防止个人信息泄露。
当企业需要用户的数据提升自己算法的性能,用户担心数据隐私遭到泄露时,矛盾便出现了。
数据匿名化用来保护用户隐私,但用户不确定企业是否将隐私匿名化,以及匿名化的程度。Netflix发布了电影评分数据集,包括100M条评分,480k用户,17K电影,并匿名化处理,但有研究者结合Netflix和IMDB数据库,成功识别出一些人;匿名化后的马萨诸塞州的医疗记录和选票记录相结合,发现符合州长的邮编、出生日期、性别只有一人,因此暴露了州长的医疗记录。一项研究表明只要邮编、出生日期、性别三样信息就能确定87%的美国人。
差分隐私被提出,在不暴露用户隐私的前提下还能不影响统计结果。原理是,在用户数据到达企业时,用抛硬币算法决定是否给真实的数据。
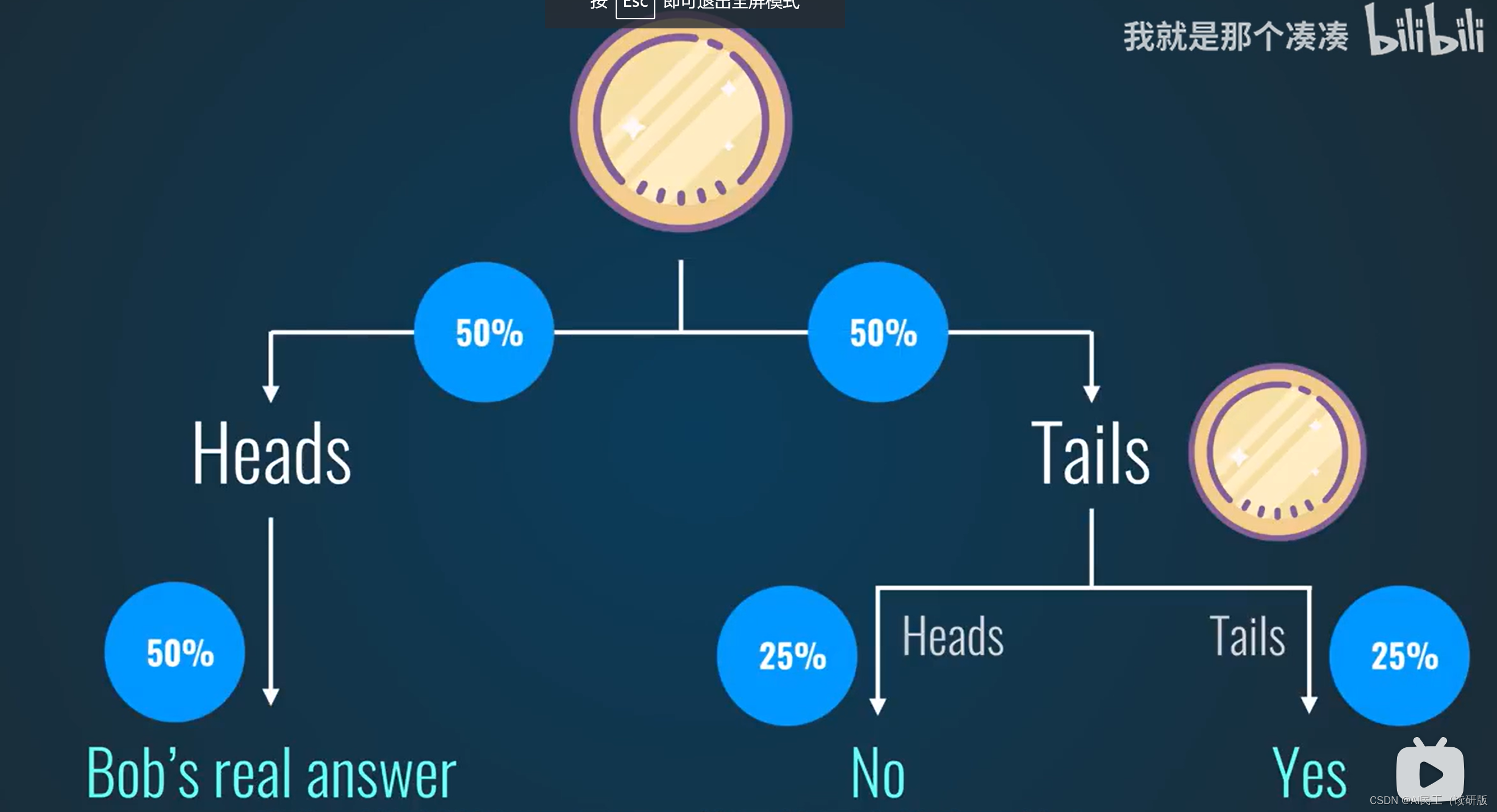
这样数据有25%的概率为假数据,从源头使得数据变得不可信,抛硬币算法被称为“噪声”,在已知噪声分布的前提下,给出一些补偿,最终得到一个相对准确的统计结果。在实际应用中,拉普拉斯分布(laplace distribution)用于扩大数据的分布范围,提高匿名性。
由于注入的噪声,差分隐私只适用于大型数据集,小型数据集会因为噪声导致不准确的结果。差分隐私相较于匿名化更难实现。
总之:差分隐私能帮助企业更了解一群用户,但不侵犯个人用户的隐私。
但DP难以完全保护数据内容的隐私,因为它更关注保护个人身份不被泄露,而不是数据本身的泄露。PII泄露的问题通常涉及数据内容(数据本身)的隐私性,而DP更适用于对个体身份的隐私保护。比如在一群用户之间传播的信息“简患有癌症”。差分隐私能保护每个用户的身份不被泄露(没人知道谁说过这个话),但信息本身通过LM泄露出来。
不使用差分隐私,为什么存在隐私泄露的风险:
你有一个小型数据库,里面包含了5个人的年龄信息:30岁、40岁、29岁、25岁和31岁。你想要计算这个群体的平均年龄。
在不使用差分隐私的情况下,你会直接计算这些年龄的平均值。对这5个数字求平均,结果是(30+40+29+25+31)/5 = 31岁。
现在,假设有一个新的数据项加入,这个人的年龄是60岁。你再次计算平均年龄,现在的结果是(30+40+29+25+31+60)/6 ≈ 35.83岁。
在这个例子中,仅仅通过观察平均年龄的变化,我们就能推断出新加入的这个人的年龄明显高于群体的原始平均年龄。这就暴露了这个新加入的人相对较高的年龄信息。
应用差分隐私:
- 计算平均年龄:首先计算所有人的平均年龄,假设这个真实平均年龄是30岁。
- 选择噪声分布:根据选定的ε值,选择一个噪声分布,如拉普拉斯分布。在差分隐私中,拉普拉斯分布的标准差与ε成反比
- 生成噪声:从所选的噪声分布中生成一个随机噪声值。例如,如果ε是0.01,则从一个具有较高标准差的拉普拉斯分布中提取噪声,这会生成一个较大的随机数,如果ε是1,噪声值会小得多
- 添加噪声到结果:将噪声值添加到真实的平均年龄,例如,如果真实平均年龄是30岁,从拉普拉斯分布中生成的噪声是2岁,那么发布的平均年龄是32岁。
为什么差分隐私能保护隐私
你有一个小型数据库,里面包含了5个人的年龄信息:30岁、40岁、29岁、25岁和31岁。你想要计算这个群体的平均年龄。
在不使用差分隐私的情况下,你会直接计算这些年龄的平均值。对这5个数字求平均,结果是(30+40+29+25+31)/5 = 31岁。
使用差分隐私后,假设噪声值=8,添加到平均年龄,31+8 = 39;噪声值为1,31+1 = 32
现在,假设有一个新的数据项加入
这个人的年龄是60岁,噪声为1,现在的结果是(30+40+29+25+31+60)/6 + 1 ≈ 36.83岁。
这个人的年龄是20岁,噪声为8,现在的结果是(30+40+29+25+31+20)/6 + 8 ≈ 37.16岁
加入噪声后,通过观察平均年龄,变化仅仅可能是因为随机噪声,而不是新数据点的实际值。这样即使有新数据点加入,观察者也不能确定新数据点的具体影响,从而保护的个人隐私。

















 2698
2698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









