







首先 数据下载网站:
下载下来数据后,需要对其进行合并,合并方法:
data_01 = pd.read_csv('data_01.csv')
data_02 = pd.read_csv('data_02.csv')
data_03 = pd.read_csv('data_03.csv')
data = pd.concat([data_01,data_02,data_03])合并数据后,对数据进行处理。
数据预处理
print(data.describe())
print(data.info())运行结果:

可以看出,info()函数主要是判断里面是否含有空变量,如果存在的话,则可以用fillna来进行处理。
添加党派关系
temp=data['cand_nm'].unique()
#print(temp)
parties = {'Bachmann, Michelle': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'Huntsman, Jon': 'Republican',
'Johnson, Gary Earl': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Obama, Barack': 'Democrat',
'Paul, Ron': 'Republican',
'Pawlenty, Timothy': 'Republican',
'Perry, Rick': 'Republican',
"Roemer, Charles E. 'Buddy' III": 'Republican',
'Romney, Mitt': 'Republican',
'Santorum, Rick': 'Republican'}
data['parties']=data['cand_nm'].map(parties)
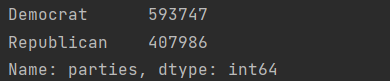
print(data['parties'].value_counts())unique():该函数的作用是得到里面的唯一量
map():将人名映射到列表里面。
运行结果:
根据职业和雇主统计赞助信息
没有什么新东西,但是需要仔细钻研代码
代码为:
occupation_map = {
'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED',
'C.E.O.':'CEO',
'LAWYER':'ATTORNEY',
}
emp_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
'INFORMATION REQUESTED' : 'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED',
}
f=lambda g:occupation_map.get(g,g)
data['contbr_occupation']=data['contbr_occupation'].map(f)
f=lambda g:emp_mapping.get(g,g)
data.contbr_employer = data.contbr_employer.map(f)
by_occ=data.pivot_table('contb_receipt_amt',index='contbr_occupation',columns='parties',aggfunc='sum')
over_2=by_occ[by_occ.sum(1)>2000000]
print(over_2)
over_2.plot(kind='barh')
plt.show()主要的是添加了映射,其实这个用groupby也是可以的
运行结果

按照每个人捐助的金额进行排序代码:
data=data[data['contb_receipt_amt']>0]
print(data.groupby('cand_nm')['contb_receipt_amt'].sum().sort_values())
运行结果为:

对出资额分组
先上代码:
data=data[data['contb_receipt_amt']>0]
#print(data.groupby('cand_nm')['contb_receipt_amt'].sum().sort_values())
bins = np.array([0,1,10,100,1000,10000,100000,1000000,10000000])
data_vs = data[data['cand_nm'].isin(['Obama, Barack','Romney, Mitt'])]
labels=pd.cut(data_vs['contb_receipt_amt'],bins)
#print(labels)
print(data_vs.groupby(['cand_nm',labels]).size().unstack(0))
其中,看到最后一句
print(data_vs.groupby(['cand_nm',labels]).size().unstack(0))
size()的意义是 得到个数,如果将其改成sum(),则得到的是总金额
unstace(0)表示不分开表示两个表格,如果变成 unstack(),则会将其行列反转。
上述代码跑出的结果如下:

之后,我们算出每个捐赠金额的所占比例,然后根据比例画出图表,代码如下所示:
temp2=data_vs.groupby(['cand_nm',labels]).sum().unstack(0)
temp3=temp2.div(temp2.sum(axis=1),axis=0)
print(temp2.div(temp2.sum(axis=1),axis=0))
temp3.plot(kind='barh',stacked=True)
plt.show()在这个代码中,我们可以看到,用到了div()函数,该函数的主要作用是除法,即给每个变量除以函数的第一个所给值
画图时,指定stacked=True进行堆叠,即可完成百分比堆积图
运行结果为

完整代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data_01 = pd.read_csv('data_01.csv')
data_02 = pd.read_csv('data_02.csv')
data_03 = pd.read_csv('data_03.csv')
data = pd.concat([data_01,data_02,data_03])
#print(data.describe())
#print(data.info())
temp=data['cand_nm'].unique()
#print(temp)
parties = {'Bachmann, Michelle': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'Huntsman, Jon': 'Republican',
'Johnson, Gary Earl': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Obama, Barack': 'Democrat',
'Paul, Ron': 'Republican',
'Pawlenty, Timothy': 'Republican',
'Perry, Rick': 'Republican',
"Roemer, Charles E. 'Buddy' III": 'Republican',
'Romney, Mitt': 'Republican',
'Santorum, Rick': 'Republican'}
data['parties']=data['cand_nm'].map(parties)
#print(data['parties'].value_counts())
occupation_map = {
'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED',
'C.E.O.':'CEO',
'LAWYER':'ATTORNEY',
}
emp_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
'INFORMATION REQUESTED' : 'NOT PROVIDED',
'SELF' : 'SELF-EMPLOYED',
'SELF EMPLOYED' : 'SELF-EMPLOYED',
}
f=lambda g:occupation_map.get(g,g)
data['contbr_occupation']=data['contbr_occupation'].map(f)
f=lambda g:emp_mapping.get(g,g)
data.contbr_employer = data.contbr_employer.map(f)
by_occ=data.pivot_table('contb_receipt_amt',index='contbr_occupation',columns='parties',aggfunc='sum')
over_2=by_occ[by_occ.sum(1)>2000000]
#print(over_2)
#over_2.plot(kind='barh')
#plt.show()
data=data[data['contb_receipt_amt']>0]
#print(data.groupby('cand_nm')['contb_receipt_amt'].sum().sort_values())
bins = np.array([0,1,10,100,1000,10000,100000,1000000,10000000])
data_vs = data[data['cand_nm'].isin(['Obama, Barack','Romney, Mitt'])]
labels=pd.cut(data_vs['contb_receipt_amt'],bins)
#print(labels)
temp2=data_vs.groupby(['cand_nm',labels]).sum().unstack(0)
#print(data_vs.groupby(['cand_nm',labels]).sum().unstack(0))
temp3=temp2.div(temp2.sum(axis=1),axis=0)
#print(temp2.div(temp2.sum(axis=1),axis=0))
temp3.plot(kind='barh',stacked=True)
#plt.show()
grouped=data_vs.groupby(['cand_nm','contbr_st'])
totals=grouped.contb_receipt_amt.sum().unstack(0).fillna(0)
totals=totals[totals.sum(1)>100000]
percent=totals.div(totals.sum(1),axis=0)
参考书籍:《利用Python进行数据分析》















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









