






先导入包
import pandas as pd
读取函数
1:读取csv格式文件
pd.read_csv()参数
| 参数名 | 参数意义 | 参数类型 |
|---|---|---|
| names | 定义列索引的值 | 列表[] |
| header | 是否将第一行作为列索引 | False;True |
| index_col | 指定,列索引为“(城市)“的这一列数据,作为行索引。 | 字符串,前提是列索引中存在这个字符串 |
| sep | 分隔符 | , |
2:读取xlsx文件
pd.read_excel() 直接填入问价路径即可
pd.read.csv
示例如下:
path=r'C:/Users/cloud/Desktop/dataone.csv'
test_data=pd.read_csv(path,sep=',')#直接读取数据
默认第一行作为列索引

test_data=pd.read_csv(path,sep=',',header=None)#读取数据,header为None则去掉行索引,行索引变为默认索引[0,1,2,3....]
读取数据,header为None则去掉行索引,行索引变为默认索引[0,1,2,3…]

test_data=pd.read_csv(path,sep=',',index_col='城市')#index_col指定列索引为“城市“的这一列数据作为行索引
#index_col指定列索引为“城市“的这一列数据作为行索引

test_data=pd.read_csv(path,sep=',',header=None,names=['one','two','three','four'])#names重新定义列索引的值

2:查看数据
| datafram的属性、方法 | 返回值 |
|---|---|
| colums | 返回列索引对象 |
| keys() | 返回列索引对象 |
| index | 返回行索引对象 |
| shape | 返回数据的行数与列数 |
| dtypes | 返回每一列数据的数据类型 |
| head(1) | 返回头(1)行, |
| tail() | 返回尾(1)行 |
| describe() | #返回对每一列数据的描述性统计,包括总数,非重复值,最大值,频率等等 |
test_data数据如下:

test_data.columns#返回列索引的一个对象
test_data.keys()#返回列索引的一个对象
test_data.columns.to_list()#转化为列表

test_data.index
#返回行索引的一个对象
test_data.index.to_list()#转化为列表

test_data.head(1)#返回datafram的头5行
test_data.tail()#返回datafram的尾5行

test_data.shape#返回数据的行数与列数
test_data.types#每一列数据的数据类型
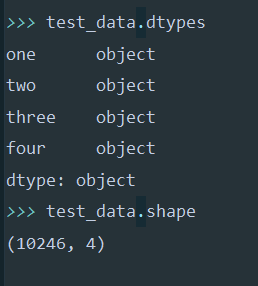
test_data.describe()

test_data['one'].to_list()#将数据转化为列表















 4671
4671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









