







LSTM是RNN的改进型,传统RNN模型会随着时间区间的增长,对早期的因素的权重越来越低,有可能会损失重要数据。而LSTM模型通过遗忘门、输入门、输出门三个逻辑,来筛选和保留数据。
原理详解可以参考如何从RNN起步,一步一步通俗理解LSTM这个博主讲的非常通俗易懂,本文主要是项目实操。
实验环境
Windows11、python3.8、Keras框架、Tensorflow
实验目的
使用新冠疫情历史每日新增感染人数数据训练LSTM模型,然后用此模型预测未来21天每日新增感染人数,这里将对数据集进行一阶差分以保证数据平稳性(根据数据具体情况处理)
实验数据介绍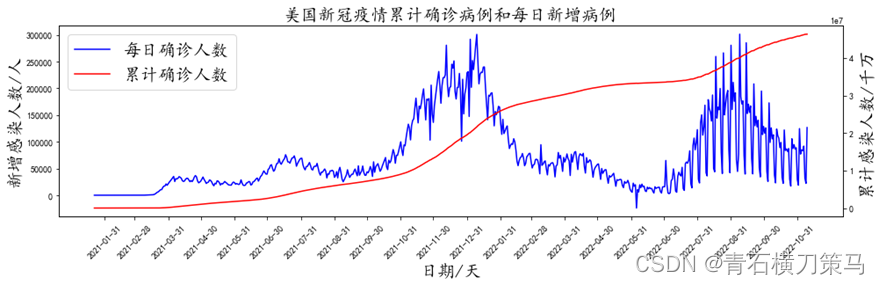
数据归一化
为了加快模型收敛速度,这里将对实验数据进行归一化,本文使用sklearn库中的MinMaxScaler方法,将实验数据压缩到0到1之间
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
dataset_sc = scaler.fit_transform(temp)
#dataset_sc为归一化后的数据,temp为原始数据
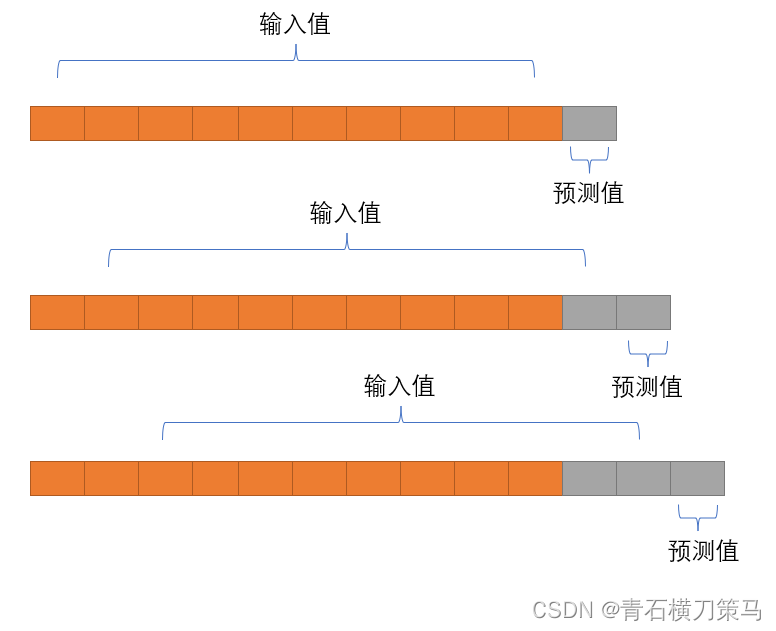
制作时间滑动窗口
由于LSTM模型输入数据格式的要求,使用LSTM模型需要制作时间滑动窗口,如下图
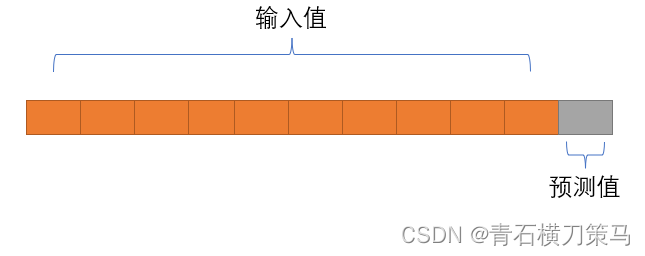
上图即使一个时间窗口,含义为用前10天的历史数据预测后一天的值,而预测值作为验证数据,用以计算预测值与真实值的误差。
但实际上我们不止11个数据,我们有上百个数据,所以得让时间窗口滑动起来,如下图所示
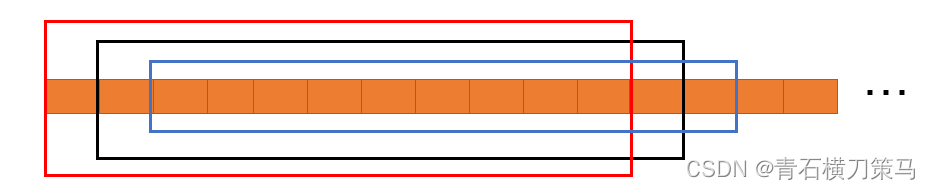
时间滑动窗口制作代码如下
#dataset为数据集
#timestep为准备使用的历史数据的步长
#dataX为时间窗口的输入值
#dataY为时间窗口的预测值(真实值)
def create_dataset(dataset, timestep ):
dataX, dataY = [], []
for i in range(len(dataset)-timestep -1):
a = dataset[i:(i+timestep )]
dataX.append(a)
dataY.append(dataset[i + timestep])
return np.array(dataX),np.array(dataY)
timestep = 10
trainX1,trainY1 = create_dataset(dataset_sc,timestep )
#把输入值的列表变换为符合LSTM输入格式的形式
trainX = np.reshape(trainX1, (trainX1.shape[0], trainX1.shape[1], 1))
构建模型并训练
本文使用单层LSTM层,并加上一层Dropout层防止过拟合。使用MSE作为损失函数,MAPE作为评价指标,模型构建代码如下
from keras.models import Sequential
from keras.layers import LSTM,Dense,Dropout
import tensorflow as tf
from sklearn import metrics
units =30#LSTM层单元数
rate=0.3#Dropout损失率
epochs=590
batch_size=64
optimizer=tf.keras.optimizers.Adam(learning_rate=0.01)#使用Adam优化器
model = Sequential()#序贯模型
model.add(LSTM(units = units,activation='tanh', input_shape = (None,1)))
model.add(Dropout(rate=rate))
model.add(Dense(units = 1,activation='linear'))#采用linear激活函数
model.compile(loss='mean_squared_error', optimizer=optimizer,metrics='mape')
model.fit(trainX, trainY1, epochs=epochs, batch_size=batch_size, verbose=1)#训练
对训练结果和预测结果进行可视化
train_pre=model.predict(trainX)
plt.figure(figsize=(15, 8))
train_pre=scaler.inverse_transform(train_pre)#反归一化
trainY1_pre=scaler.inverse_transform(trainY1)#反归一化
plt.plot(range(496),trainY1_pre,range(496),train_pre)
plt.legend(['true','pre'])
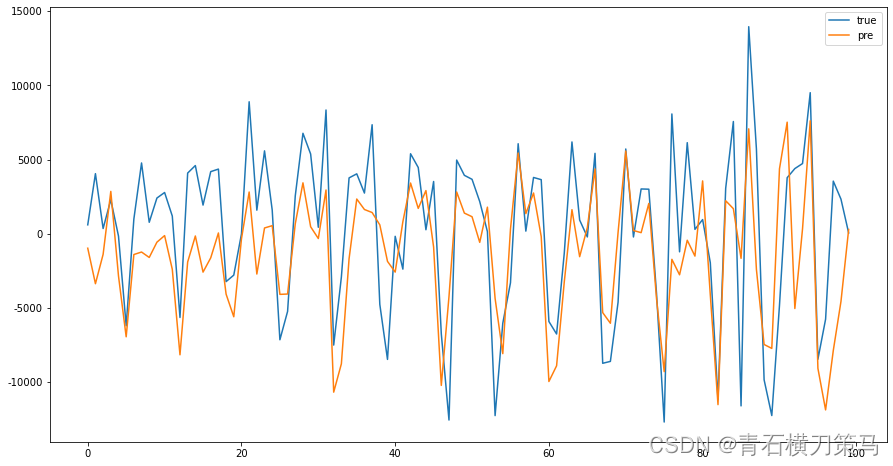
训练数据集的预测结果如下图
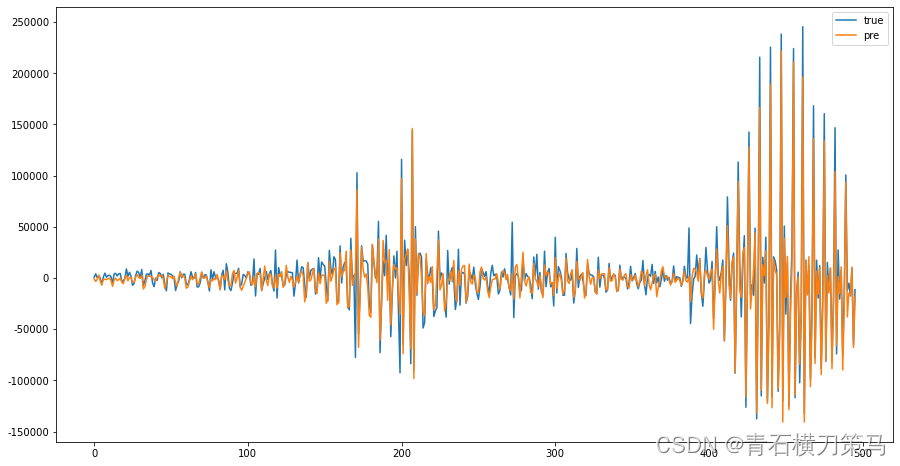
截取前100个数据进行放大观察
预测未来
首先我们要知道,这个时间窗口只能往后预测一个值,但是本文的目的是预测未来21天的值。目前有多种方法,一种是seq2seq,顾名思义直接用一段序列预测下一段序列,但是本文采用迭代预测法,即将预测出来的值,又作为下一个时间窗口的输入值,以此来迭代预测,如下图所示
代码如下:
#测试集
test_data=diff2[-timestep-pre_day:-pre_day]#用于预测第一天
test_data=np.array(test_data)#转化为数组
test_data = test_data.astype('float32')#转化为浮点数
li_test=list(test_data.reshape(timestep))#转化为list
for i in range(pre_day):
temp=np.array(li_test[-timestep:]).reshape(timestep,1)#取列表最后timestep个值输入
test_data2 = scaler.fit_transform(temp)#归一化
test_data3=test_data2.reshape(1,timestep,1)#转化为LSTM需要的输入格式
re1=model.predict(test_data3)#预测结果
re2=scaler.inverse_transform(re1)#反归一化
li_test.append(float(re2))#将预测值转化为float添加的列表末尾
这段代码因为涉及到数据类型的转化,可能比较难以理解,如有不懂,可在评论区留言。
测试集结果如下
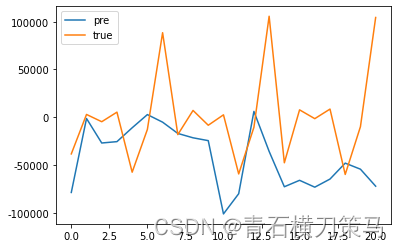
由于模型参数没有讨论,所以看起来预测结果比较差,但通过调参后(本文采用网格搜索),结果会好很多
实验结果
最后通过调参调整模型,并对结果进行反差分,得到的未来21天每日新增感染人数预测值与真实值结果如下图:

正方形虚线为真实值,三角形实线为预测值
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











