







演进历史: Seq2Seq 到 Transformer
引言
本文将首先介绍序列到序列(Seq2Seq)模型的概念与演进过程,包括其在处理变长输入和输出序列方面的优势与局限。随后重点阐述了注意力机制(Attention)的提出背景、核心思想与重要特性,并结合自注意力(Self-Attention)、交叉注意力(Cross-Attention)等不同形式,剖析了它们在解决长时依赖与信息丢失问题中的关键作用。接着,本文详细展示了基于 Transformer 的编码器-解码器(Encoder-Decoder)结构,包括多头注意力、多层前馈网络、残差连接和掩码技术在解码过程中的应用。最后,通过一个小型中英翻译任务的示例,从数据预处理、模型构建、训练到推理做了完整代码实践演示,为理解和动手实现 Transformer 在自然语言处理中的核心原理与流程提供了参考。
序列到序列(Seq2Seq)模型概述
Seq2Seq 全称为 Sequence to Sequence 序列变为序列 , 原来用Mask解决Padding问题,但是对于长度事先并不知道的问题,使用seq2seq解决。
Seq2Seq主要有四个优势:
首先是,Seq2Seq是端到端学习,从原始数据可以直接到输出数据,不需要中间进行特征提取或工程化步骤。
例如: 我有一个机器翻译的任务,想将“我想喝水。”翻译为“I want to drink water.”。传统方法的“特征工程”思路是,首先进行文本预处理:
- 对句子进行分词、去除停用词、做词形还原、构造词典等。
然后进行特征提取:
- 需要人工或基于规则提取句子中的关键词、词频、文本统计特征等,甚至需要对上下文进行复杂的标注或编码。
其次使用机器学习模型:
- 将提取好的特征输入传统机器学习模型(如 SVM、逻辑回归等),尝试输出目标句子的相应翻译片段,然后再做组合或拼接。
最后进行后处理:
- 对模型输出的碎片化翻译结果进行人工后处理或整合,才能形成相对通顺的翻译句子。
而Seq2Seq 的“端到端”思路就简单很多,例如使用Encoder(编码器):将原始中文句子(“我想喝水。”)的词或字序列直接输入模型的 Encoder。
常见做法是先将每个词/字映射成向量(嵌入向量),再通过 RNN、LSTM、GRU 或 Transformer 等神经网络来编码句子,得到一个语义向量表示(hidden states)。
然后使用Decoder(解码器):Decoder 根据 Encoder 的输出语义向量,逐步生成目标句子的每个单词 “I”、 “want”、 “to”、 “drink”、 “water”、“.”,其中实现了完全自动化。
在训练阶段,整个过程从中文句子的原始字符/词序列到英文句子的输出序列都是一个统一的模型,这个模型会自动学习到最适合翻译的特征表。我们无需人为地额外设计、挑选或拼接特征。
为什么说是 “端到端”?首先,Seq2Seq无需特征工程:模型会在训练过程中通过误差反向传播自主学习如何将输入序列映射到输出序列,并把所有中间特征的提取都放到神经网络内部来完成。其次,Seq2Seq训练简洁:只需准备对应的中文→英文的配对数据,即可让模型自动优化参数,以得到最优的翻译效果。最后,Seq2Seq部署便利:训练完成后,只需一个模型文件,直接输入一句中文就能得到翻译结果,无需复杂的中间处理步骤。
通过这个简单例子可以看出,Seq2Seq 的核心优势在于它是一种 端到端 的学习方式:从原始数据(如中文句子)出发,直接学习到目标数据(如英文翻译),不再需要像传统方法那样在手工设计的特征工程上投入大量精力。
第二个优势,显而易见,Seq2Seq处理可变长度序列,模型具备处理输入和输出序列的能力,能够适应不同长度的序列数据。
第三个优势,是Seq2Seq的信息压缩与表示。编码器通过编码过程将输入序列压缩为一个固定维度的上下文向量,该向量作为输入序列的抽象表示,解码器基于此上下文向量进行解码操作以生成目标输出序列。
最后,第四个优势是Seq2Seq有良好的可扩展性,能够与卷积神经网络(CNNs)、循环神经网络(RNNs)等神经网络架构无缝集成,以应对更加复杂的数据处理任务和场景。
SeqToSeq模型本身也存在缺陷:
首先是上下文向量信息压缩问题,输入序列的全部信息需要被编码成一个固定维度的上下文向量,这导致了信息压缩和信息损失的问题,尤其是细粒度细节的丢失
其次是短期记忆限制,由于循环神经网络(RNN)的固有特性,Seq2Seq模型在处理长序列时存在短期记忆限制,难以有效捕获和传递长期依赖性。这限制了模型在处理具有长距离时间步依赖的序列时的性能
最后是训练与实战的差距,专业术语是暴露偏差(Exposure Bias),在Seq2Seq模型的训练过程中,经常采用“teacher forcing”策略,这就像是考试时老师不断给你提示答案。但是,在实际使用模型时,它需要自己猜测下一步该做什么,这就可能导致模型在实际应用时表现不如训练时那么出色,因为它可能会过分依赖那些训练时的“提示”,而忽略了如何独立解决问题。这种训练和实际应用之间的差异,我们称之为“Exposure Bias”。
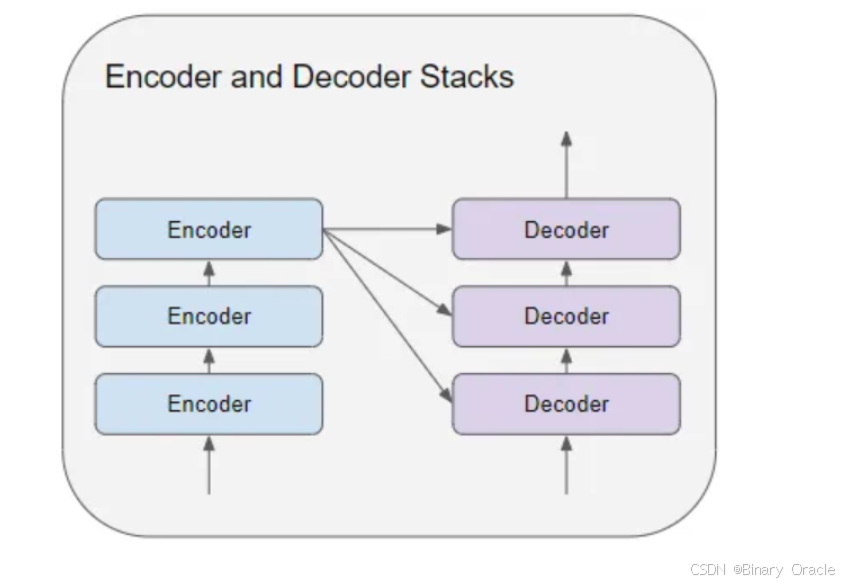
Encoder-Decoder模型
Seq2Seq(Sequence-to-Sequence)模型的主要目的是实现输入序列到输出序列的映射
Seq2Seq 使用的具体方法:通常基于 Encoder-Decoder 架构。这一方法旨在通过编码器将输入序列压缩为固定长度的潜在表示(向量),并通过解码器生成目标输出序列。
编码器(Encoder)
编码器是一个循环神经网络(RNN),由多个循环单元(如 LSTM 或 GRU)堆叠而成。
每个单元通过依次处理输入序列中的一个元素,生成一个上下文向量。
这个上下文向量汇总了输入序列的全部信息,它通过在单元间传递当前元素的信息,逐步构建对整个序列的理解。
工作流程:
- 词序列转换,输入文本(例如一个句子)通过一个嵌入层(embedding layer)进行转换成词嵌入。
- 序列处理:随后,这些经过嵌入的向量序列被送入一个基于循环神经网络(RNN)的结构中,该结构可能由普通的RNN单元、长短期记忆网络(LSTM)单元或门控循环单元(GRU)组成。RNN的递归性质允许它处理时序数据,从而捕捉输入序列中的顺序信息和上下文关系。在每个时间步,RNN单元不仅处理当前词汇的向量,还结合了来自前一个时间步的隐藏状态信息。
- 生成上下文向量,经过一系列时间步的计算,RNN的最后一个隐藏层输出被用作整个输入序列的表示,这个输出被称为上下文向量。其是一个固定长度的向量,它通过汇总和压缩整个序列的信息,有效地编码了输入文本的整体语义内容。这个向量随后将作为Decoder端的重要输入,用于生成目标序列。
解码器(Decoder)
解码器是一个基于递归神经网络(RNN)的模型组件,它的任务是接收编码器生成的上下文向量,并逐步生成目标序列,就像学生根据老师给的笔记复述故事一样。
在这个过程中,解码器的“头脑”(隐藏状态:权重和偏置)需要初始化,通常根据激活函数,分为Xavier初始化(适用于Sigmoid或Tanh激活函数)和He初始化(通常用于ReLU激活函数),通常用编码器生成的上下文向量作为起点。
解码器生成目标序列的过程可以看作一个接力,每一步都依赖之前的结果和来自编码器的信息。
它先以编码器生成的上下文向量作为起点,同时用一个特定的开始符号SOS(Start-of-Sequence, )来启动生成序列的过程。
在运行时,解码器每一步的输入是前一步的输出,而在训练时可以直接用目标序列的下一部分来指导。
上下文向量帮助解码器总结和理解源序列的信息,特别是在注意力机制中,它会动态调整焦点,确保解码器能根据当前需要更准确地关注源序列的不同部分,从而生成更符合上下文的输出。
Seq2Seq模型的训练过程
扮演一名老师,教一个学生(解码器)如何根据一本故事书(源序列)来复述故事。
1. 准备数据 1.准备数据 1.准备数据
- 数据预处理:首先,你需要把故事书的内容翻译成学生能理解的词汇表(分词),并为每个词汇分配一个编号,同时在故事的开始和结束加上特殊的标记(编码),告诉学生何时开始和结束复述。
- 批量处理:然后,你把这些故事分成几个小部分,每次给学生讲一个小故事,这样他们可以同时学习多个故事。
2. 初始化模型参数 2. 初始化模型参数 2.初始化模型参数
- 解码器RNN:学生的大脑就像一个初始状态,需要学习如何理解和复述故事。
- 输出层:学生的嘴巴就像一个输出层,需要学习如何将大脑中的故事转换成语言表达出来。
3. 编码器处理 3. 编码器处理 3.编码器处理
- 运行编码器: 你先给学生讲一遍故事,让他们理解故事的情节和要点,这些信息被总结成一个简短的笔记。
4. 解码器训练过程 4. 解码器训练过程 4.解码器训练过程
- 初始化隐藏状态: 学生开始复述前,先看看你给他们的笔记。
- 时间步迭代:
- 输入: 学生首先根据你给的开头标记开始复述,然后根据他们自己的记忆或者你给的提示来继续。
- 解码器RNN: 学生的大脑根据当前的输入和之前的记忆来决定下一步该说什么。
- 输出层: 学生尝试用语言表达出他们大脑中的故事。
- 损失计算: 你评估学生复述的故事和你讲的故事之间的差异,通常是通过比较他们说的词汇和你期望的词汇。
5. 反向传播和参数更新 5. 反向传播和参数更新 5.反向传播和参数更新
- 计算梯度: 学生根据你的反馈来调整他们的记忆和学习方法。
- 参数更新: 学生通过不断的练习来改进他们的复述技巧。
6. 循环训练 6. 循环训练 6.循环训练
- 多个epoch: 学生需要反复练习,多次复述不同的故事,直到他们能够熟练地复述任何故事。
7. 评估和调优 7.评估和调优 7.评估和调优
- 验证集评估: 定期让学生在新的故事(验证集)上测试他们的复述能力。
- 超参数调优: 根据学生的表现,调整教学的方法,比如改变练习的难度或频率(学习率、批次大小)。
通过这个过程,学生(解码器)学会了如何根据你提供的笔记(上下文向量)来复述故事(生成目标序列)。在实际训练中,教师强制(Teacher Forcing)等技巧可以帮助学生更快地学习,而梯度裁剪(Gradient Clipping)等技术可以防止他们在学习过程中过度自信或偏离正确的路径。
Encoder-Decoder 的应用
机器翻译、对话机器人、诗词生成、代码补全、文章摘要(文本 – 文本)
语音识别(音频 – 文本)
图像描述生成(图片 – 文本)
Encoder-Decoder 的缺陷
只有一个固定长度的“上下文向量 ”来传递信息
当输入信息太长时,会丢失掉一些信息
注意力机制
历程和影响
Attention的发展历程如下:
| 时间 | 发展 | 描述 |
|---|---|---|
| 早期 | 循环神经网络(RNNs) 长短期记忆网络(LSTMs) | RNNs能够处理变长的序列数据,但由于梯度消失和梯度爆炸问题,它们在长序列上的表现并不理想。LSTMs是对RNNs的改进,通过引入门控机制来解决长序列学习中的梯度消失问题。 |
| 2014年 | Seq2Seq模型的提出 | Seq2Seq模型由一个编码器和一个解码器组成,两者都是基于LSTM。该模型在机器翻译任务上取得了显著的成功。历史地位:首次引入了编码器-解码器框架;端到端的学习成为可能;中间产生了上下文向量,把编码过程和解码过程进行了解耦。 |
| 2015年 | 注意力机制的引入 | 在Seq2Seq模型的基础上,Bahdanau等人提出了带注意力机制的Seq2Seq模型。 |
| 2017年 | 自注意力与Transformer模型 | Transformer模型完全基于自注意力机制,摒弃了传统的循环网络结构,在处理长距离依赖方面表现卓越。 |
| 2018年 | 多头注意力与BERT | Transformer模型进一步发展为多头注意力机制,并在BERT模型中得到应用,BERT在多项NLP任务上取得了突破性的成果。 |
从计算区域、所用信息、使用模型、权值计算方式和模型结构方面对Attention的形式进行归类,如下表所示:
| 计算区域 | 所用信息 | 使用模型 | 权值计算方式 | 模型结构 |
|---|---|---|---|---|
| 1. Soft Attention(Global Attention) | 1. General Attention | 1. CNN + Attention | 1. 点乘算法 | 1. One-Head Attention |
| 2. Local Attention | 2. Self Attention | 2. RNN + Attention | 2. 矩阵相乘 | 2. Multi-layer Attention |
| 3. Hard Attention | 3. LSTM + Attention | 3. Cos相似度 | 3. Multi-head Attention | |
| 4. pure-Attention | 4. 串联方式 | |||
| 5. 多层感知 |
Attention 模型的特点是 Encoder 不再将整个输入序列编码为固定长度的“向量C” ,而是编码成一个向量(Context vector)的序列(“C1”、“C2”、“C3”),解决“信息过长,信息丢失”的问题。
Attention 的核心工作就是“关注重点”。在特定场景下,解决特定问题。
- 信息:整个画面
- 有效信息:画面中心位置
- 无效信息:画面的边边角角、底色、花纹等等
Attention 的3大优点:
- 参数少:模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
- 速度快:Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
- 效果好:在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
词嵌入
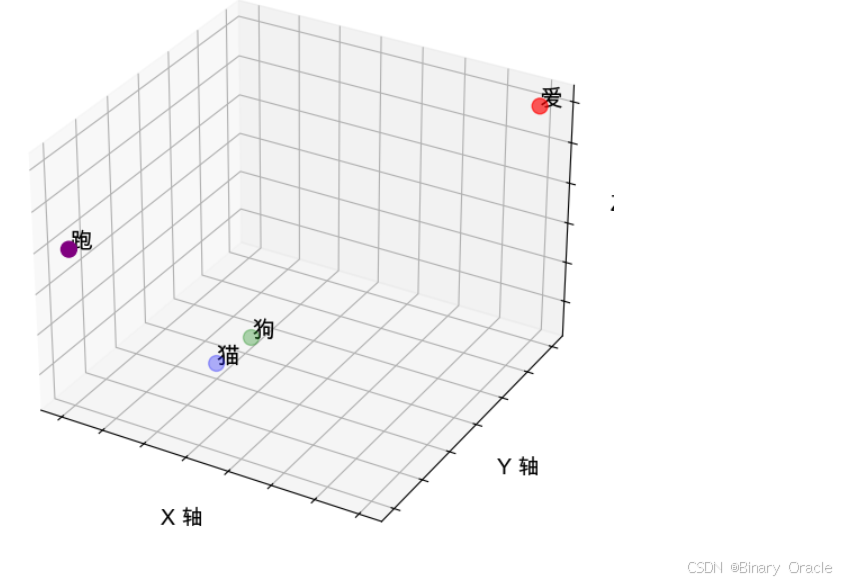
词嵌入是通过将词汇映射到一个高维稠密向量空间中来表示其语义信息的方式,这些向量的位置反映了词汇之间的语义相似性,例如: “猫”和“狗”的向量在空间中更接近,而与“爱”或“跑”距离较远,这种表示能够用向量的距离或角度来度量词汇关系,从而有效捕捉其语义复杂性,并在实际应用中通过更高维度的表示来提升精度。
例如:
“猫” = [0.3, 0.4, 0.25]
“狗” = [0.35, 0.45, 0.3]
“爱” = [0.8, 0.8, 0.8]
“跑” = [0.1, 0.2, 0.6]
在这个例子中,每个词汇被表示为一个三维向量。这些向量在多维空间中的位置是根据词汇的语义相似性来确定的。在实际应用中,词嵌入通常是在一个更高的维度空间中进行的,比如50维、100维、甚至更高,这样可以更准确地捕捉词汇的复杂语义关系。这种稠密向量的表示方式使得词汇之间的关系可以通过向量之间的距离或角度来度量。
我们将例子中给出的向量投影到三维空间中,可观察到距离越近的两个向量,往往也代表其具有更强的语义相关性:
原理
注意力机制(Attention Mechanism) 是 自然语言处理(NLP)中的一项关键创新,最初用于提升神经机器翻译(NMT)的效果,优化编码器-解码器(Encoder-Decoder)架构的表现。该机制最早提出于经典论文 《Attention Is All You Need》,奠定了基于 Transformer 的模型基础。
传统的编码器-解码器模型问题:
- 传统的编码器-解码器(Encoder-Decoder)模型在处理长句子时存在长时依赖(Long-term dependency)问题,即在处理长序列时容易遗忘早期信息。
- 在这些模型中,编码器会将整个句子压缩成一个上下文向量(context vector),但如果这个摘要信息不足,就会影响翻译质量。
注意力机制:
- 注意力机制的核心思想是:不使用单一的上下文向量,而是为输入序列的不同部分分配不同的重要性(权重),使得解码器在生成翻译时能够动态地获取更加相关的信息。
在 Transformer 等模型中,注意力机制的作用是提取重要信息,具体步骤包括:
- 分解输入信息
- 识别关键部分
- 依据重要性对信息进行排序
- 聚焦关键元素,形成总结性表示
这一过程使得模型能够从大规模语言数据中学习,并有效地将知识迁移到不同的上下文环境中。
分类
根据Attention的计算区域,可以分成以下几种:
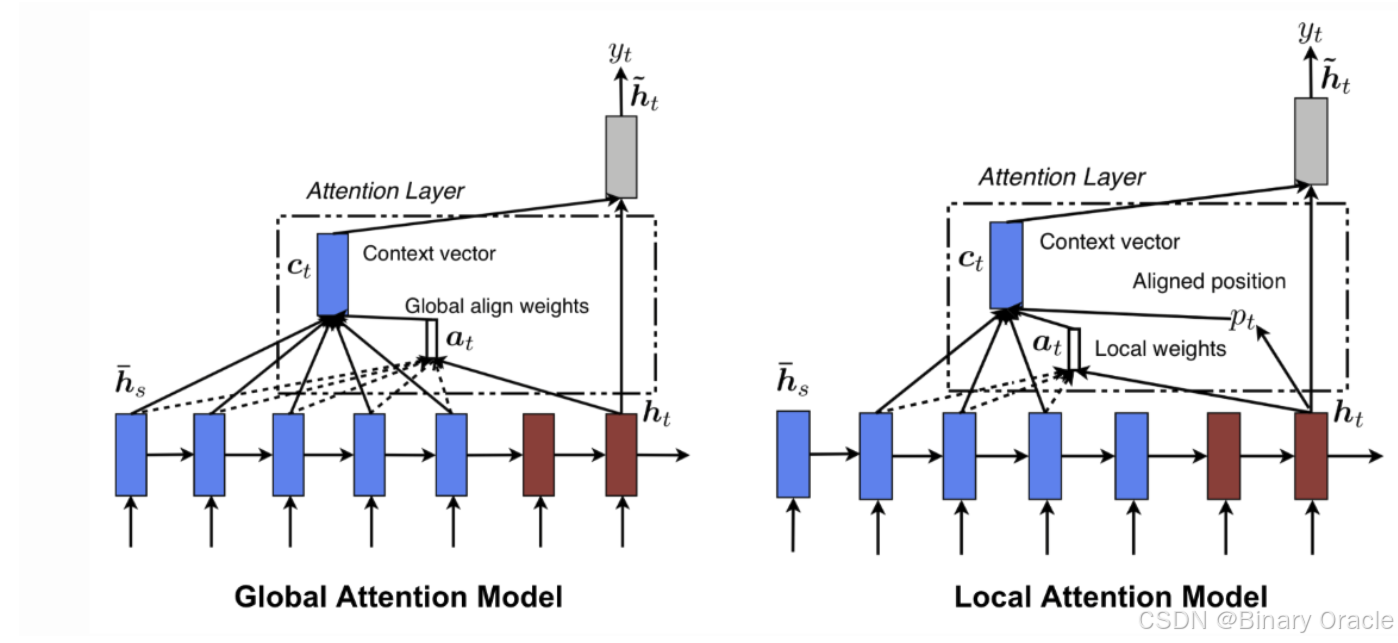
- Soft Attention,这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
- Hard Attention,这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
- Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
局部注意力的实现方式包括:
- 设定一个注意力窗口,仅计算窗口内的上下文向量
- 基于位置信息计算上下文权重
- 通过进阶位置模型定义二维注意力窗口,优化计算效率
局部注意力的优势在于计算效率更高,可在全局注意力与局部注意力之间取得平衡。
Transformer模型
概览
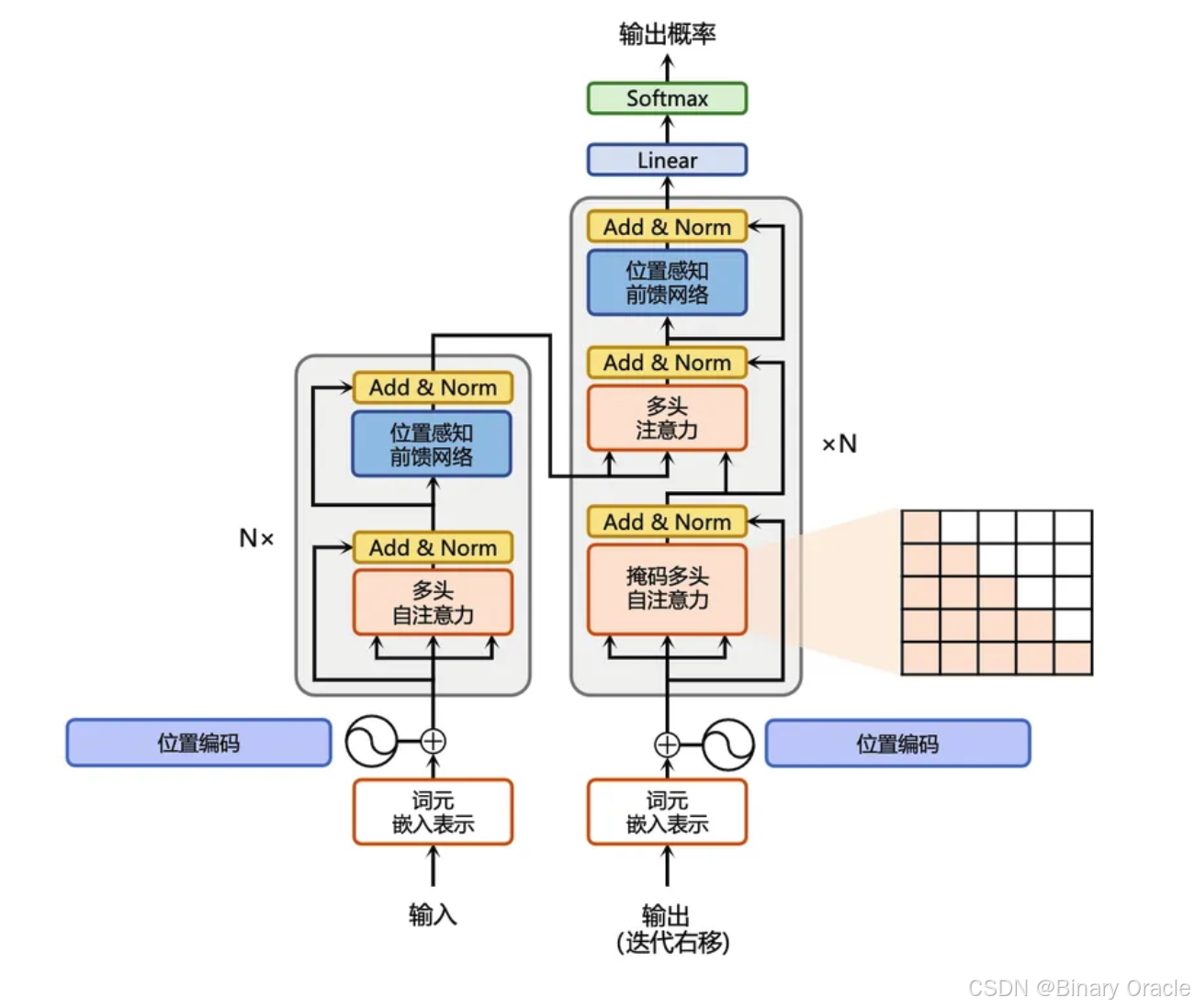
Transformer 是一种基于编码器-解码器(Encoder-Decoder)的架构,其中:
- 编码器(Encoder) 负责处理输入序列
- 解码器(Decoder) 负责生成输出序列
每一层的编码器和解码器都包含:
- 自注意力机制(Self-Attention Mechanism)
- 前馈神经网络(Feedforward Network, FFN)
这种架构能够充分理解输入序列,并生成具有丰富上下文的输出。
位置编码(Positional Encoding):
- 由于 Transformer 无法直接理解序列的顺序,因此需要通过 位置编码(Positional Encoding) 来引入位置信息。
- 位置编码的作用:
- 结合词嵌入(Word Embedding)与位置信息,使模型能够区分序列中的不同元素
- 通过捕捉语言的时序动态,确保模型准确理解文本内容
多头注意力(Multi-Head Attention):
- Transformer 的核心特性之一是 多头注意力(Multi-Head Attention),它允许模型同时关注输入序列的多个部分。
- 具体原理:
- 将查询(Query)、键(Key) 和 值(Value) 向量拆分为多个注意力头
- 不同注意力头捕获不同的上下文信息
- 综合多个注意力结果,提高模型处理复杂语言结构的能力
前馈神经网络(Feedforward Network, FFN):
- 在 Transformer 的每一层中,都会使用 前馈神经网络(FFN) 进行处理,作用类似于人脑中的并行信息处理:
- 通过线性变换和非线性激活函数,提取复杂的特征关系
- 增强模型对语义结构的理解能力
Transformer 的工作流程:
- 输入序列 经过 词嵌入(Embedding)
- 编码器(Encoder) 处理嵌入后的输入
- 解码器(Decoder) 结合编码器的输出和先前的解码结果
- Softmax 层 计算下一个单词的概率分布
Transformer 的编码器-解码器结构 使其在 机器翻译、文本生成和其他 NLP 任务 中表现优异,能够高效地并行处理数据,并捕捉长距离依赖关系。
Transformer 的工作原理:
自注意力机制(Self-Attention Mechanism) 在 Transformer 中起到了核心作用,它帮助模型识别句子内部的单词之间的关系。
例如,考虑以下两个句子:
“The cat drank the milk because it was hungry.” (其中 “it” 指代 “cat”)
“The cat drank the milk because it was sweet.” (其中 “it” 指代 “milk”)
当 Transformer 处理单词 “it” 时,自注意力机制会:
- 分析周围单词的上下文,确定 “it” 的具体指代
- 为 “cat” 和 “milk” 分配不同的注意力权重,使得 “it” 在不同句子中正确关联到相应的词汇
通过 多个注意力分数(Multiple Attention Scores),Transformer 能够捕捉细微的语义差异,从而提升机器翻译、文本生成和 NLP 任务的准确性。

对 Seq2Seq 模型的影响
Transformer 通过 自注意力机制(Self-Attention Mechanism) 取代了传统的 RNN:
- 允许所有元素并行处理
- 在计算时同时考虑整个序列
- 通过 位置向量(Position Vector) 维护序列顺序
- 训练效率更高
对比CNN和RNN
假设输入序列的长度为 n,每个元素的维度为 d,输出序列的长度同样为 n,维度为 d。可以对比 Transformer、CNN 和 RNN 在以下三个方面的表现:
| 特性 | Transformer | CNN | RNN |
|---|---|---|---|
| 计算复杂度 | O(n²·d) | O(k·n·d²) | O(n·d²) |
| 并行性 | 高 | 高 | 低 |
| 最长学习距离 | O(1) | O(log(n)) | O(n) |
词嵌入层
在 PyTorch 中,nn.Embedding 层用于实现词嵌入,通常有两种方法:
- 使用预训练嵌入并冻结(Frozen)
- 随机初始化并进行训练
可训练的嵌入在训练过程中不断优化,而冻结的嵌入保持不变。
位置编码层
由于 Transformer 不具备序列顺序感知能力,因此需要通过 位置编码(Positional Encoding) 来补充位置信息。
Transformer 论文提出了一种基于固定公式的编码方式,确保模型能够学习相对位置信息,从而更好地理解文本结构。
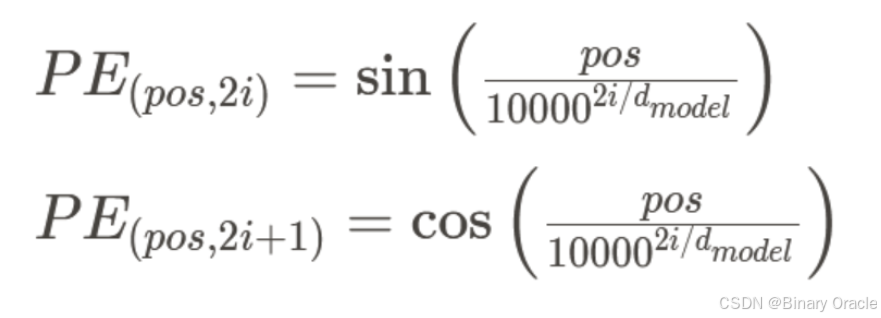
工作流程
Encoder工作流程
输入:
- 初始输入:将词嵌入(Input Embedding)和位置编码(Position Embedding)相加后得到输入序列。
- 后续 Encoder 输入:若有多层 Encoder,则后面的 Encoder 会接收前一个 Encoder 的输出作为输入。
核心处理阶段
多头自注意力层(Multi-Head Self-Attention):
- 通过多头自注意力机制,分别计算序列内部不同位置之间的依赖关系。
- 具体地,对于每个“头”,将输入序列分别映射为 Query、Key、Value,计算注意力权重,并对 Value 做加权求和,输出各头结果后再拼接并线性变换。
前馈层(Feedforward layer):
- 在得到自注意力层输出后,通过一系列全连接网络(常见为两层线性层 + 非线性激活)对特征进一步变换和提取。
- 残差与归一化阶段
残差连接(Residual Connection):
- 自注意力层及前馈层的输入与输出相加,以缓解梯度消失或爆炸,提升训练稳定性。
层归一化(LayerNorm):
- 对每一层的神经元输入归一化,可加速收敛并提高模型的泛化能力。
Encoder 组成:
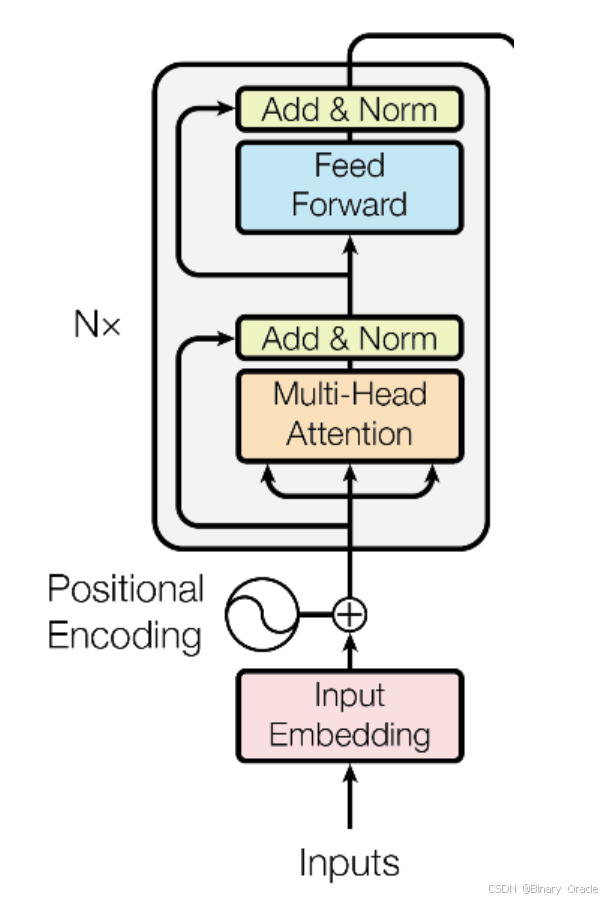
- Multi-Head Attention(多头注意力)
- Residual Connection(残差连接)
- Normalisation(层归一化)
- Position-wise Feed-Forward Networks(逐位置前馈网络)
通过堆叠多个相同的 Encoder Layer(每层都包含多头自注意力与前馈网络),实现对输入序列的深层次特征编码。
多头自注意力 (Multi-Head Self-Attention)
缩放点积注意力 (Scaled Dot-Product Attention)
- 将输入序列映射得到 Query(Q)、Key(K)、Value(V)。
- 计算公式:
Q = linear_q(x)
K = linear_k(x)
V = linear_v(x)
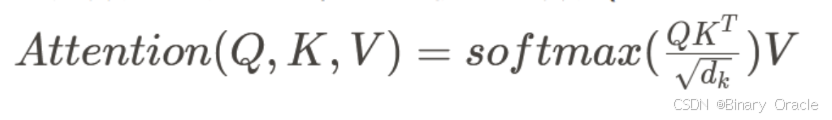
-
其中 d_k为 Key/Query 的向量维度。
-
缩放因子 用于避免向量点乘过大导致 softmax 进入饱和区间。
多头注意力机制 (Multi-Head Attention)
- 将 Q、K、V 分成多个“头”,在较低维空间并行计算注意力后再拼接,能让模型从不同子空间学习多种关系。
- 优点:捕捉多种上下文信息、增强模型表达能力、提升并行计算效率。
自注意力机制 (Self Attention)
- Q、K、V 都来自同一个序列,模型可同时考虑序列中所有元素之间的相互依赖。
- 优点:并行处理、长距离依赖捕捉、参数利用效率高。
- 缺点:计算量随序列长度增大,无法显式捕捉位置信息(需显式加位置编码)。
- Add & Norm:自注意力或前馈层输出后与输入相加(残差连接),并做层归一化,稳定训练并防止梯度消失。
前馈全连接网络 (Position-wise Feed-Forward Networks)
- 典型结构:两层全连接(升维→非线性激活→降维)。
- 在每个位置上独立进行计算,用于进一步提取高层次特征,提升模型表达能力。
Multi-Head Attention vs Multi-Head Self-Attention
- 核心机制相同:都基于多头注意力;均对 Q、K、V 做线性变换,并计算注意力分数。
- 差异:
- Self-Attention:Q、K、V 都来自同一序列,用于建模序列内部依赖。
- Cross-Attention:Q 来自一个序列,K、V 来自另一个序列,用于跨序列/跨模态的交互。
Cross Attention
交叉注意力(Cross Attention)让一个序列(Query)“关注”另一个序列(Key、Value),从而在两个不同序列或不同模态间建立联系。
序列维度应一致,以便进行点积操作。
交叉注意力的操作:
- 查询序列:决定输出序列的长度。
- 键、值序列:提供信息来源,用于匹配与加权求和。
Cross Attention 与 Self Attention 的主要区别:
输入来源
- Self Attention:Q、K、V 同源,关注自身内部依赖。
- Cross Attention:Q、K、V 分别来自不同序列,让一个序列与另一个序列互动。
信息交互对象
- Self Attention:序列内部元素两两关联。
- Cross Attention:一个序列的每个元素与另一个序列所有元素关联。
应用场景
- Self Attention:单序列的编码理解,如句子内部词的关联。
- Cross Attention:多序列或多模态的交互,如机器翻译中的 Encoder 与 Decoder 之间的信息融合、图文匹配等。
小结
总结而言,Encoder 的关键在于“多头自注意力 + 前馈网络 + 残差连接和归一化”的组合结构,能在并行计算中高效捕捉序列内部特征。多头注意力又可细分为自注意力和交叉注意力,分别适用于序列内部和跨序列/模态的信息交互,为 Transformer 模型在自然语言处理、计算机视觉等领域的成功提供了重要支撑。
Decoder工作流程
解码器是Transformer架构中的重要组成部分,主要负责生成目标序列。在此过程中,它通过多头注意力机制和前馈神经网络处理输入,并结合编码器的信息来生成符合上下文的输出。
解码流程:
- 输出嵌入的右向偏移:在训练阶段,解码器内的每个符号都能获取之前生成符号的上下文信息。
- 位置编码的整合:结合位置编码以保留序列顺序信息。
- 带掩码的多头自注意力机制:使用掩码防止模型窥视未来符号,确保生成过程的因果性。
- 编码器-解码器注意力交互:使解码器能够聚焦于输入序列的重要部分。
- 基于位置的前馈网络:作用于每个符号,捕捉复杂模式和关联。
Decoder子结构:
- 子结构-1:带掩码的多头注意力机制,防止信息泄露。
- 子结构-2:编码器-解码器注意力交互,建立输入与输出的联系。
- 子结构-3:线性层+softmax,预测目标词汇的概率分布。
Encoder vs. Decoder:
- Encoder 多头自注意力:
- 任务:提取输入序列的全局特征。
- 无因果掩码,可访问整个输入序列。
- Decoder 多头自注意力:
- 任务:生成输出序列的下一个词。
- 采用因果掩码,防止访问未来信息。
- 掩码机制(Masking):
- Encoder:不使用掩码。
- Decoder:使用因果掩码(Mask),确保当前词仅与之前的词进行交互。
- 模型结构差异:
- Encoder:仅依赖输入序列。
- Decoder:包含自注意力层和交叉注意力层。
- 训练与生成差异:
- Encoder:训练和推理阶段处理方式相同。
- Decoder:训练时并行处理,推理时逐步生成。
掩码(Mask)机制
Decoder 为什么要加 因果掩码 ?
- 确保当前位置的输出仅依赖于其之前的位置,避免信息泄露。
Padding Masking
- Padding:用于填充不等长的序列,使其长度一致。
- Masking:用于标识填充部分,避免其影响计算。
Masked Multi-Head Attention
- 使用下三角矩阵作为因果掩码,阻止Decoder窥视未来信息。
生成输出概率
- 线性层+softmax预测目标词汇。
- 训练阶段使用交叉熵损失进行优化。
训练与生成
预测阶段
- 贪心搜索:每步选择最高概率词。
- 束搜索(Beam search):保留多个可能路径,提高质量。
训练阶段
- 自由运行(Free Running)模式:使用上一步的预测值作为输入,可能导致误差累积。
- 教师强制(Teacher Forcing)模式:使用真实标签作为输入,提高训练稳定性。
- 计划采样(Scheduled Sampling):混合使用预测值和真实标签,提升泛化能力。
评估模型预测质量
- BLEU分数:衡量预测文本与参考文本的相似度。
- 困惑度(Perplexity):衡量语言模型对数据的适应性,值越低越好。
相关模型
BERT
- 预训练模型,双向编码。
- 适用于文本分类、命名实体识别等任务。
GPT
- 生成式预训练模型,仅基于解码器。
- 适用于文本生成、对话系统等任务。
分词(Tokenization)
中文 vs. 英文分词
- 英文:单词由空格分隔,易于分割。
- 中文:无空格,需借助分词工具(如Jieba)。
分词方式
- 字级分词:逐字拆分,适用于小型数据集。
- 词级分词:基于词典(Jieba等)。
- 子词分词(Subword Tokenization):如BPE、WordPiece。
繁体中文Tokenization
- 研究者提出SubChar分词方法,结合字形和发音特征。
- Taiwan-LLM团队针对繁体中文优化预训练。
中英文翻译实战
代码:
# ============================================
# 中文到英文的微型 Transformer 示例
# ============================================
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
# ==============================
# 1) 简单的中英文对照句子
# ==============================
sentences = [
['我 是 学 生 P', 'S I am a student', 'I am a student E'],
['我 喜 欢 学 习', 'S I like learning P', 'I like learning P E'],
['我 是 男 生 P', 'S I am a boy', 'I am a boy E']
]
# ==============================
# 2) 中英词典
# ==============================
src_vocab = {'P': 0, '我': 1, '是': 2, '学': 3, '生': 4, '喜': 5, '欢': 6, '习': 7, '男': 8}
src_idx2word = {src_vocab[key]: key for key in src_vocab}
src_vocab_size = len(src_vocab)
tgt_vocab = {'S': 0, 'E': 1, 'P': 2, 'I': 3, 'am': 4, 'a': 5, 'student': 6,
'like': 7, 'learning': 8, 'boy': 9}
idx2word = {tgt_vocab[key]: key for key in tgt_vocab}
tgt_vocab_size = len(tgt_vocab)
src_len = len(sentences[0][0].split()) # 5
tgt_len = len(sentences[0][1].split()) # 5
# ==============================
# 3) 函数:将句子转换为索引表示
# ==============================
def make_data(sentences):
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
print("enc_inputs:\n", enc_inputs)
print("dec_inputs:\n", dec_inputs)
print("dec_outputs:\n", dec_outputs)
# ==============================
# 4) 构建 DataLoader
# ==============================
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), batch_size=2, shuffle=False)
# ==============================
# 5) 参数定义
# ==============================
d_model = 512 # 词向量维度
d_ff = 2048 # 前馈网络隐藏层大小
d_k = d_v = 64 # Q, K, V 向量维度
n_layers = 6 # Encoder/Decoder 堆叠层数
n_heads = 8 # Multi-Head 数量
# ==============================
# 6) 位置编码
# ==============================
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pos_table = np.array([
[pos / np.power(10000, 2 * i / d_model) for i in range(d_model)]
if pos != 0 else np.zeros(d_model) for pos in range(max_len)
])
pos_table[1:, 0::2] = np.sin(pos_table[1:, 0::2]) # 偶数位置
pos_table[1:, 1::2] = np.cos(pos_table[1:, 1::2]) # 奇数位置
self.pos_table = torch.FloatTensor(pos_table)
def forward(self, enc_inputs):
# enc_inputs: [seq_len, batch_size, d_model] 或 [batch_size, seq_len, d_model]
enc_inputs += self.pos_table[:enc_inputs.size(1), :]
return self.dropout(enc_inputs)
# ==============================
# 7) Mask 相关函数
# ==============================
def get_attn_pad_mask(seq_q, seq_k):
"""seq_k中,等于0的部分需要被mask。"""
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# pad_attn_mask: [batch_size, 1, len_k], 与后面计算时会扩展维度
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
return pad_attn_mask.expand(batch_size, len_q, len_k) # 最终变成[batch_size, len_q, len_k]
def get_attn_subsequence_mask(seq):
"""未来时刻的 Mask,上三角为1,下三角含对角线为0"""
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 上三角
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask
# ==============================
# 8) Scaled Dot-Product Attention
# ==============================
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
# 分数矩阵: [batch_size, n_heads, len_q, len_k]
scores = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(d_k)
# 利用 mask 将需要忽略的位置置为 -1e9
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
# ==============================
# 9) 多头注意力
# ==============================
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
# 残差连接
residual = input_Q
batch_size = input_Q.size(0)
# 做线性映射并 reshape
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2)
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2)
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1, 2)
# 让 mask 的维度与 Q, K 对齐
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
# 通过 Scaled Dot-Product Attention
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
# 把多头拼回
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v)
output = self.fc(context)
# 层归一化
return nn.LayerNorm(d_model)(output + residual), attn
# ==============================
# 10) 前馈网络
# ==============================
class FF(nn.Module):
def __init__(self):
super(FF, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model)(output + residual)
# ==============================
# 11) EncoderLayer
# ==============================
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = FF()
def forward(self, enc_inputs, enc_self_attn_mask):
# 自注意力
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask)
# 前馈网络
enc_outputs = self.pos_ffn(enc_outputs)
return enc_outputs, attn
# ==============================
# 12) Encoder
# ==============================
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
# 词嵌入
enc_outputs = self.src_emb(enc_inputs)
# 位置编码 (注意维度转置处理)
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)
# 获取自注意力mask
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
# ==============================
# 13) DecoderLayer
# ==============================
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = FF()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
# Masked Self-Attention
dec_outputs, dec_self_attn = self.dec_self_attn(
dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask
)
# Encoder-Decoder Attention
dec_outputs, dec_enc_attn = self.dec_enc_attn(
dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask
)
# 前馈网络
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
# ==============================
# 14) Decoder
# ==============================
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
dec_outputs = self.tgt_emb(dec_inputs)
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1)
# PAD mask
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
# Subsequence mask
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs)
# 合并两种 mask
dec_self_attn_mask = torch.gt(
(dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0
)
# Encoder-Decoder mask
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(
dec_outputs, enc_outputs,
dec_self_attn_mask, dec_enc_attn_mask
)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
# ==============================
# 15) Transformer
# ==============================
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.Encoder = Encoder()
self.Decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
# 编码器
enc_outputs, enc_self_attns = self.Encoder(enc_inputs)
# 解码器
dec_outputs, dec_self_attns, dec_enc_attns = self.Decoder(dec_inputs, enc_inputs, enc_outputs)
# 线性映射到词表大小
dec_logits = self.projection(dec_outputs)
dec_logits = dec_logits.view(-1, dec_logits.size(-1))
return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns
# ==============================
# 16) 训练
# ==============================
model = Transformer()
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
for epoch in range(50):
for enc_inputs_, dec_inputs_, dec_outputs_ in loader:
# 前向计算
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs_, dec_inputs_)
# 计算损失
loss = criterion(outputs, dec_outputs_.view(-1))
print(f"Epoch {epoch + 1:04d}, loss = {loss:.6f}")
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ==============================
# 17) 推理(预测函数)
# ==============================
def test(model, enc_input, start_symbol):
# 先通过 Encoder
enc_outputs, enc_self_attns = model.Encoder(enc_input)
# 准备一个解码器输入 dec_input,用于逐步预测
dec_input = torch.zeros(1, tgt_len).type_as(enc_input.data)
# 设定第一个 token 为 "S"(start_symbol)
next_symbol = start_symbol
for i in range(tgt_len):
dec_input[0][i] = next_symbol
# 通过 Decoder
dec_outputs, _, _ = model.Decoder(dec_input, enc_input, enc_outputs)
projected = model.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1)[1]
next_word = prob.data[i]
next_symbol = next_word.item()
return dec_input
# 取一个样本测试
enc_inputs_batch, _, _ = next(iter(loader))
predict_dec_input = test(model, enc_inputs_batch[1].view(1, -1), start_symbol=tgt_vocab["S"])
predict, _, _, _ = model(enc_inputs_batch[1].view(1, -1), predict_dec_input)
predict = predict.data.max(1, keepdim=True)[1]
print("原始中文:", [src_idx2word[int(i)] for i in enc_inputs_batch[1]],
"-> 预测英文:",
[idx2word[n.item()] for n in predict.squeeze()])
输出:
enc_inputs:
tensor([[1, 2, 3, 4, 0],
[1, 5, 6, 3, 7],
[1, 2, 8, 4, 0]])
dec_inputs:
tensor([[0, 3, 4, 5, 6],
[0, 3, 7, 8, 2],
[0, 3, 4, 5, 9]])
dec_outputs:
tensor([[3, 4, 5, 6, 1],
[3, 7, 8, 2, 1],
[3, 4, 5, 9, 1]])
Epoch 0001, loss = 2.383261
Epoch 0001, loss = 2.223256
Epoch 0002, loss = 1.950412
Epoch 0002, loss = 1.462204
Epoch 0003, loss = 1.521105
Epoch 0003, loss = 1.001927
Epoch 0004, loss = 1.496170
Epoch 0004, loss = 0.681899
Epoch 0005, loss = 1.323147
Epoch 0005, loss = 0.309556
Epoch 0006, loss = 0.923205
Epoch 0006, loss = 0.172054
Epoch 0007, loss = 0.672667
Epoch 0007, loss = 0.081261
Epoch 0008, loss = 0.477376
Epoch 0008, loss = 0.060068
Epoch 0009, loss = 0.292324
Epoch 0009, loss = 0.049399
Epoch 0010, loss = 0.212375
Epoch 0010, loss = 0.068548
Epoch 0011, loss = 0.166106
Epoch 0011, loss = 0.145608
Epoch 0012, loss = 0.128163
Epoch 0012, loss = 0.137805
Epoch 0013, loss = 0.101175
Epoch 0013, loss = 0.091254
Epoch 0014, loss = 0.073734
Epoch 0014, loss = 0.037230
Epoch 0015, loss = 0.053008
Epoch 0015, loss = 0.009194
Epoch 0016, loss = 0.063382
Epoch 0016, loss = 0.005398
Epoch 0017, loss = 0.068872
Epoch 0017, loss = 0.003885
Epoch 0018, loss = 0.078867
Epoch 0018, loss = 0.003253
Epoch 0019, loss = 0.088870
Epoch 0019, loss = 0.003127
Epoch 0020, loss = 0.107721
Epoch 0020, loss = 0.006412
Epoch 0021, loss = 0.038241
Epoch 0021, loss = 0.004151
Epoch 0022, loss = 0.014953
Epoch 0022, loss = 0.002520
Epoch 0023, loss = 0.012771
Epoch 0023, loss = 0.002712
Epoch 0024, loss = 0.008948
Epoch 0024, loss = 0.001324
Epoch 0025, loss = 0.006874
Epoch 0025, loss = 0.002235
Epoch 0026, loss = 0.005681
Epoch 0026, loss = 0.001689
Epoch 0027, loss = 0.004785
Epoch 0027, loss = 0.002944
Epoch 0028, loss = 0.008063
Epoch 0028, loss = 0.002666
Epoch 0029, loss = 0.007973
Epoch 0029, loss = 0.002172
Epoch 0030, loss = 0.010472
Epoch 0030, loss = 0.002975
Epoch 0031, loss = 0.008048
Epoch 0031, loss = 0.006916
Epoch 0032, loss = 0.014917
Epoch 0032, loss = 0.003601
Epoch 0033, loss = 0.017201
Epoch 0033, loss = 0.006562
Epoch 0034, loss = 0.011879
Epoch 0034, loss = 0.003400
Epoch 0035, loss = 0.008576
Epoch 0035, loss = 0.008156
Epoch 0036, loss = 0.012405
Epoch 0036, loss = 0.008039
Epoch 0037, loss = 0.014016
Epoch 0037, loss = 0.004655
Epoch 0038, loss = 0.010728
Epoch 0038, loss = 0.000866
Epoch 0039, loss = 0.007466
Epoch 0039, loss = 0.000393
Epoch 0040, loss = 0.005055
Epoch 0040, loss = 0.000478
Epoch 0041, loss = 0.003964
Epoch 0041, loss = 0.000350
Epoch 0042, loss = 0.002492
Epoch 0042, loss = 0.000291
Epoch 0043, loss = 0.003787
Epoch 0043, loss = 0.000449
Epoch 0044, loss = 0.002577
Epoch 0044, loss = 0.000525
Epoch 0045, loss = 0.001581
Epoch 0045, loss = 0.000622
Epoch 0046, loss = 0.001420
Epoch 0046, loss = 0.000812
Epoch 0047, loss = 0.001598
Epoch 0047, loss = 0.000897
Epoch 0048, loss = 0.001907
Epoch 0048, loss = 0.000920
Epoch 0049, loss = 0.002190
Epoch 0049, loss = 0.001339
Epoch 0050, loss = 0.002480
Epoch 0050, loss = 0.001917
原始中文: ['我', '喜', '欢', '学', '习'] -> 预测英文: ['I', 'like', 'learning', 'P', 'E']

















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









