







重点问题概述
接前两篇文章:
知识工程复习之十八类重点问题(1-7)
知识工程复习之十八类重点问题(8-12)
导论:
知识问答:
(13)问答系统的发展简史,不同时期的代表性系统或平台
(14)知识库问答的三种常见方法(基本原理),优缺点有哪些?
(15)Elasticsearch系统、gAnswer系统的主要算法框架是什么?优缺点有哪些?
知识推理:
(16)传统推理的三种形式
(17)归纳推理算法PRA、AMIE的基本原理
(18)嵌入式模型TransE、TransH、TransR、TransC的基本原理和优缺点
(13)问答系统的发展简史,不同时期的代表性系统或平台
关于问答系统的历史:
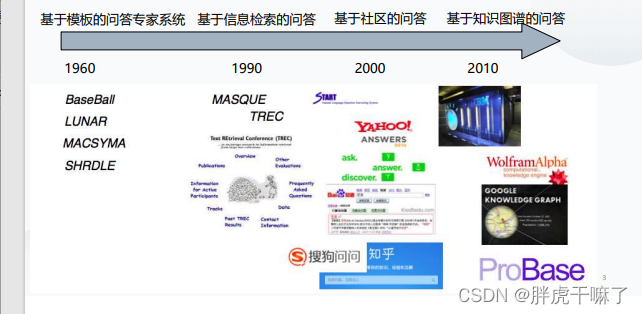
分为大致四个阶段:
(1)基于模板的问答专家系统
BaseBall
LUNAR
MACSYMA
SHRDLE
(2)基于信息检索的问答:基于关键词匹配+信息抽取,基于浅层的语义分析
MASQUE
TREC
(3)基于社区的问答:依赖于网民的贡献,问答过程依赖于关键词检索技术
yahoo
百度
搜狗
知乎
(4)基于知识图谱的问答:知识库、语义解析
ProBase
Wolfram Alpha
(14)知识库问答的三种常见方法(的基本原理),优缺点有哪些?
基于模板的方法
以TBSL方法为例进行讲解
分为三步:模板定义、模板生成、模板匹配

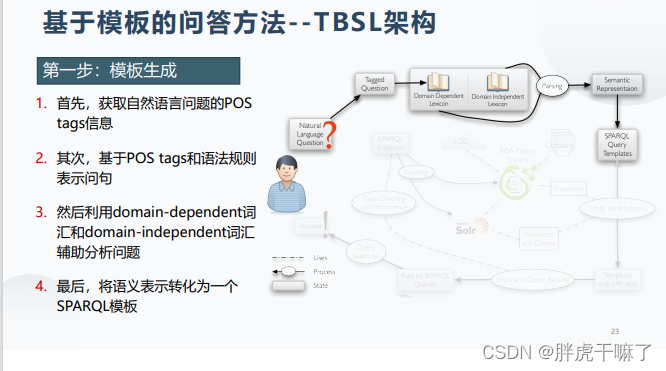

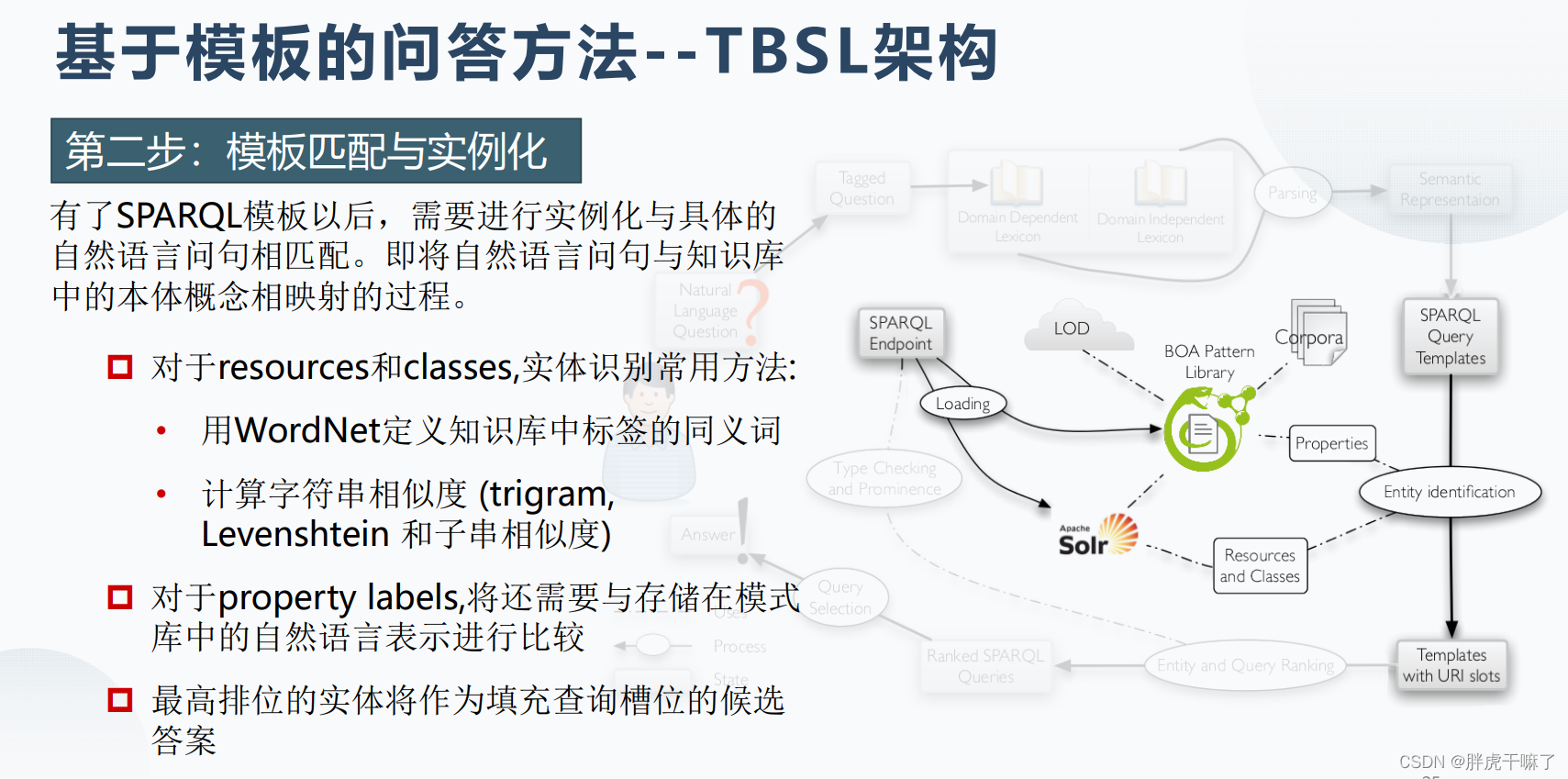

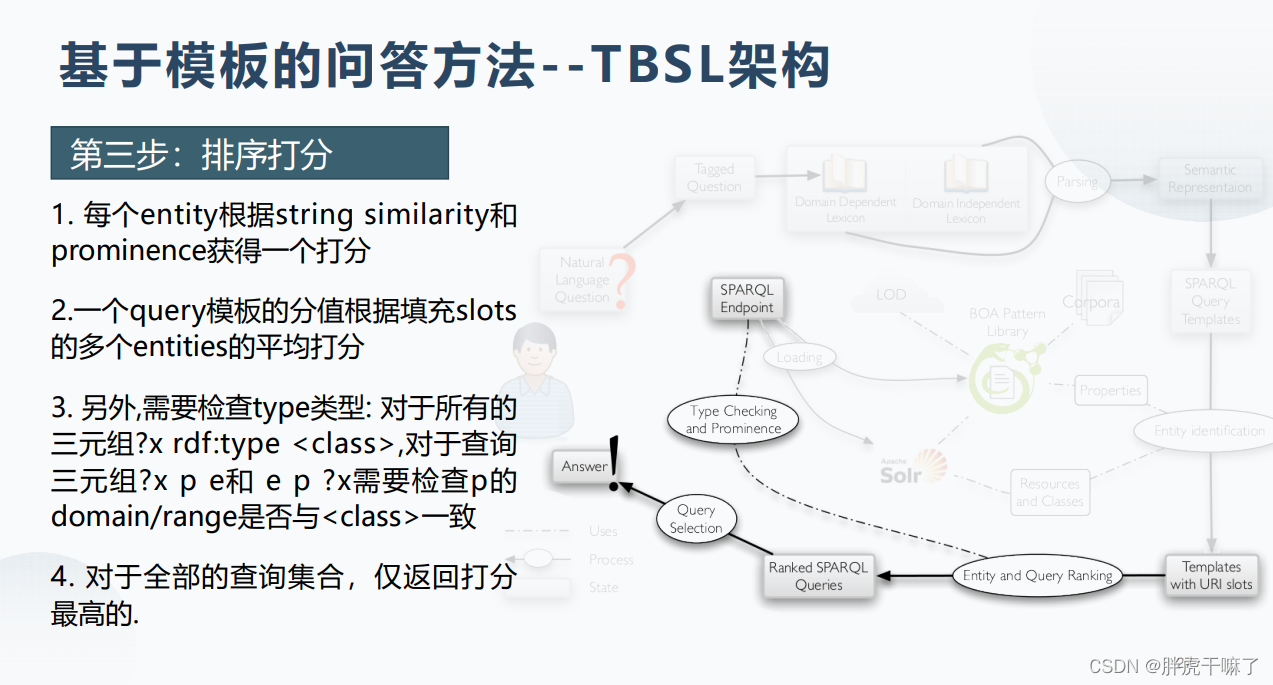

基于模板的问答方法的优缺点:
优点:
(1)模板查询相应速度快
(2)准确率较高,可以回答相对复杂的复合问题
缺点:
(1)人工定义的模板结构经常无法与真实的用户问题进行匹配
(2)如果为了尽可能匹配上一个问题的多种不同表述,则需要建立起庞大的模板库,耗时耗力而查询起来效率降低
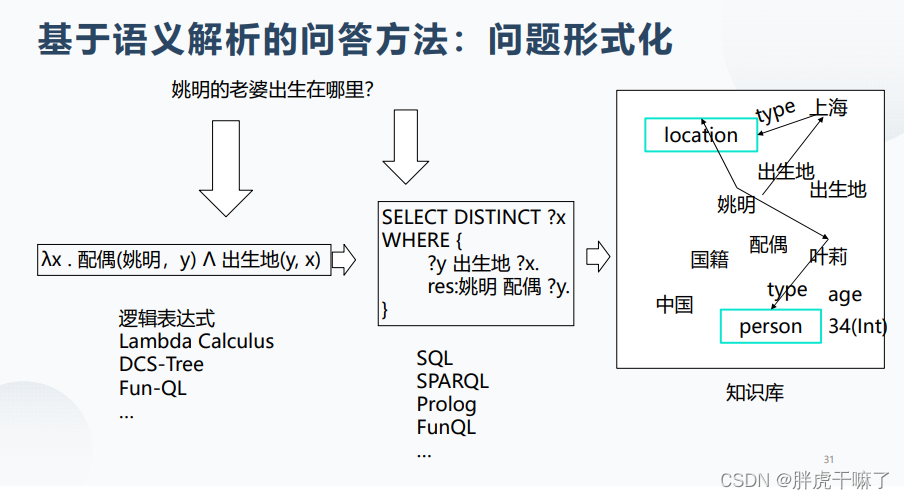
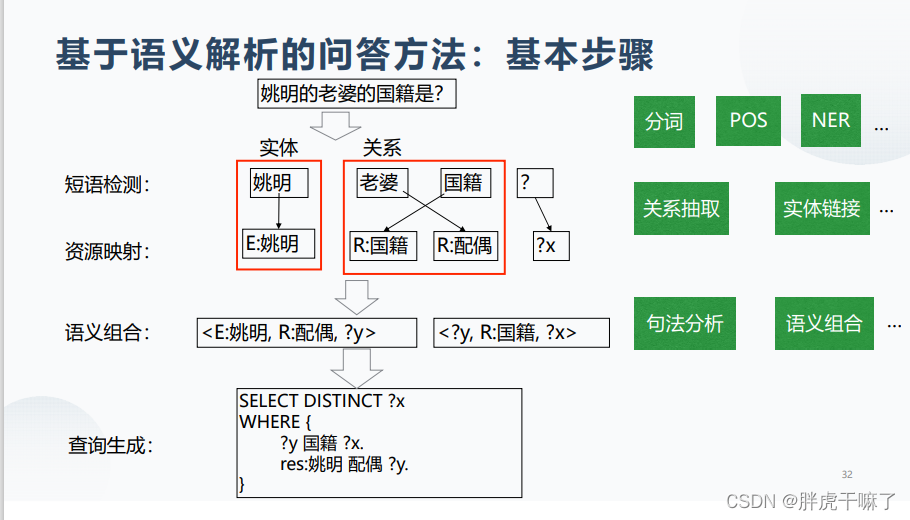
基于语义解析的(问答)方法
- 资源映射
- Logic Form
- 候选答案生成
- 排序
在这里暂停
基于语义解析的问答方法的优缺点
其目标为,通过大规模知识库上的问题、答案对集合训练Parer
优点:
可以较为轻松地从普通民众获得
缺点:
(1)需要专家编写,导致进度缓慢、代价昂贵、不可扩展
(2)仅可在受限领域推广
基于深度学习的方法
优点:
无需人工编写规则定义模板,整个学习过程都是自动进行的
缺点:
(1)目前只能处理简单题目和单边关系问题
(2)深度学习方法通常不包含聚类操作,因此无法应对时序性问题
(14)(知识库问答系统,KBQA)Elasticsearch系统、gAnswer系统的主要算法框架是什么?优缺点有哪些?
知识库问答的方法主要可以分成两类:基于语义分析的方法和基于信息检索的方法。针对两种方法,我们介绍两个知识库问答系统:Elasticsearch系统(基于语义分析的方法)和gAnswer(基于信息检索的方法)
Elasticsearch系统
Elasticsearch系统的知识问答主要基于以下四个功能来实现,也就是主要被设计来回答下面四个问题:
(1)基于实体检索的问答
(2)基于实体的属性检索的问答
(3)基于多跳查询的问答
(4)根据属性值查询实体的问答





基于Elasticsearch的知识问答流程:
(1)数据准备:将数据集转化为JSON格式,必要时可以进行属性同义词扩展
(2)导入Elasticsearch:在Elasticsearch:在Elasticsearch中创建index和type索引,并导入JSON数据
(3)自然语言转化为Logical form:解析自然语言,生成logical form
(4)Logical form翻译成ES查询语句:生成ES查询语句,并执行查询
-
数据准备:Elasticsearch要求文档的输入格式为JSON,因此需要将txt文本数据转化为JSON格式。将数据集转化为JSON格式后,每个实体对应一个json的object,也就是Elasticsearch中的一个文档
-
数据导入:Elasticsearch用index和type管理导入的文档。其中index可以类比为一个单独的数据库,其中存放的是结构相似的文档;type是index的一个子结构,可以存放不同部分的数据;type可以类比为一张表,而每一篇文章都存储在一个type中,类似于一条记录存储在一张表中。

-
自然语言解析(将自然语言转化为Logical form)
基于Elasticsearch的知识问答时需要首先预定logic form(逻辑形式)模板,然后使用解析自然语言问句填充模板生成logic form
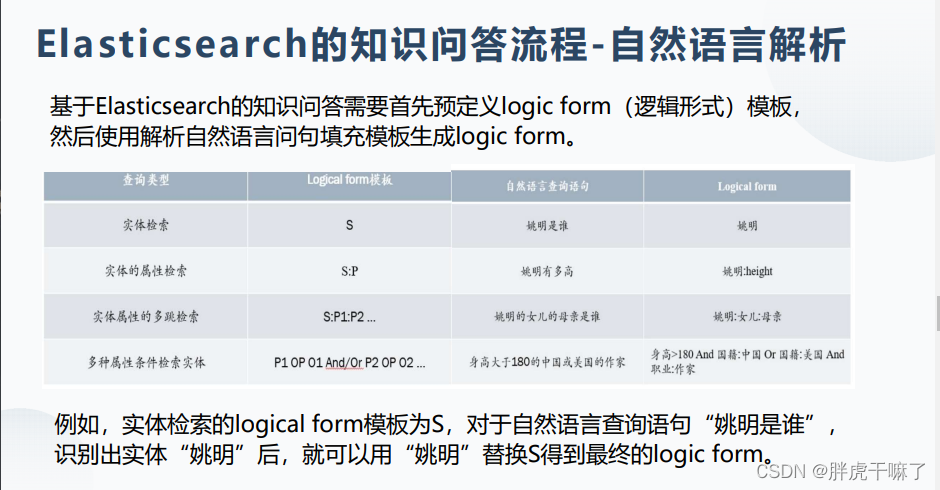
- Logical form翻译成ES查询语句:在生成logical form之后,需要查询的实体和属性,以及查询的类型都已经明确了,因此可以直接用对应的ES模板将logical form翻译成ES查询语句;相同地,对于每种查询类型,需要预定义ES模板,。然后使用logical form填充模板,生成最终的查询语句

Elasticsearch系统(基于语义解析的方法)的优缺点
优点:
(1)分布式索引、搜索
(2)索引自动分片、负载均衡
(3)自动发现机器、组件集群
(4)支持Restful峰哥接口
(5)配置简单
缺点:
(1)只支持简单的自然语句查询,对于复杂的问题无法回答
(2)在需要添加新数据与新字段的时候,ElasticSearch进行搜索可能会需要重新修改格式
(3)Elasticsearch方法是基于符号逻辑的,符号的匹配会造成语义鸿沟的问题
gAnswer系统(基于信息检索的问答方法)
gAnswer针对性地解决RDF Q/A的以下两个挑战:
(1)语义消歧(资源映射),即,如何将自然语言问题中具备歧义的实体短语和关系短语对应到知识库中确定的实体和谓词上。例如短语 “PaulAnderson” 在知
识库中可能有多个候选实体如 < Paul S.Anderson> 和 < Paul W. S. Anderson>,需要我们消除错误的歧义,而找到其正确的映射
(2)查询构建(语义组合),即,如何将映射后的实体和谓词拼接成一个完整的SPARQL查询

gAnswer系统功能:首先将自然语言问题转化成包含语义信息的查询图,然后,将查询图转化成标准的SPARQL查询,并将这些查询在图数据库中执行,最终得到用户的答案
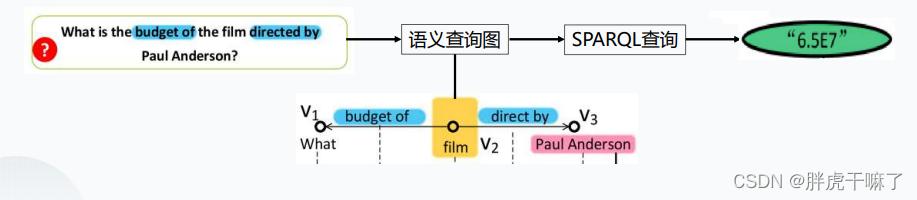
gAnswer系统框架
gAnswer知识问答系统使用两个数据驱动框架,将消歧和查询评估结合在一起
- 关系优先框架,解决了查询评估中短语链接的歧义
- 节点优先框架,短语链接和查询图形结构的模糊性都得到了解决
对于关系优先框架
先通过谓词复述词典识别问题中的关系(谓词),再通过启发式规则确定两边的节点(实体/疑问词)
这样做的优点,在于通过句法依存树进行模板匹配,能够识别出多条关系从而可以回答多跳问题
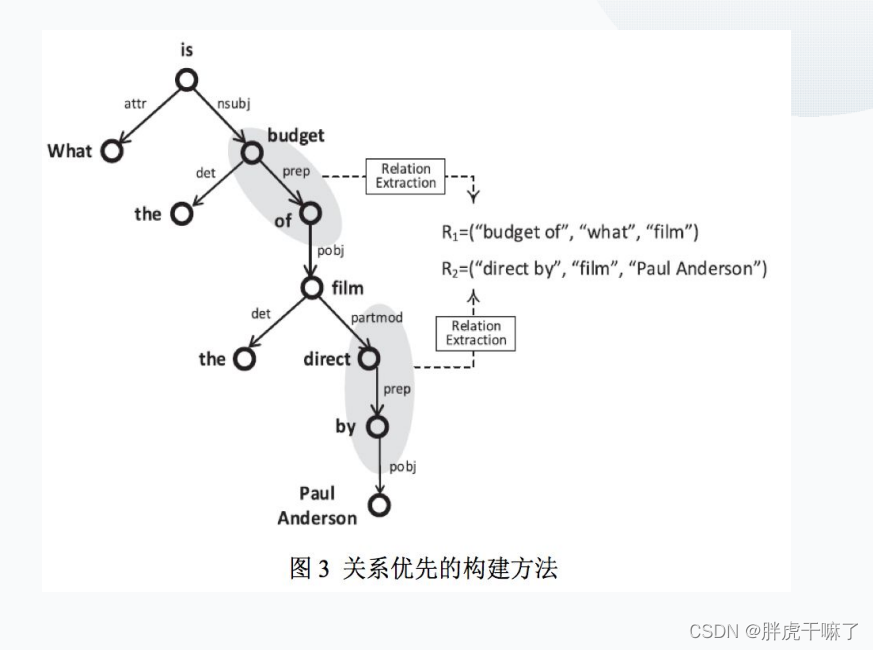
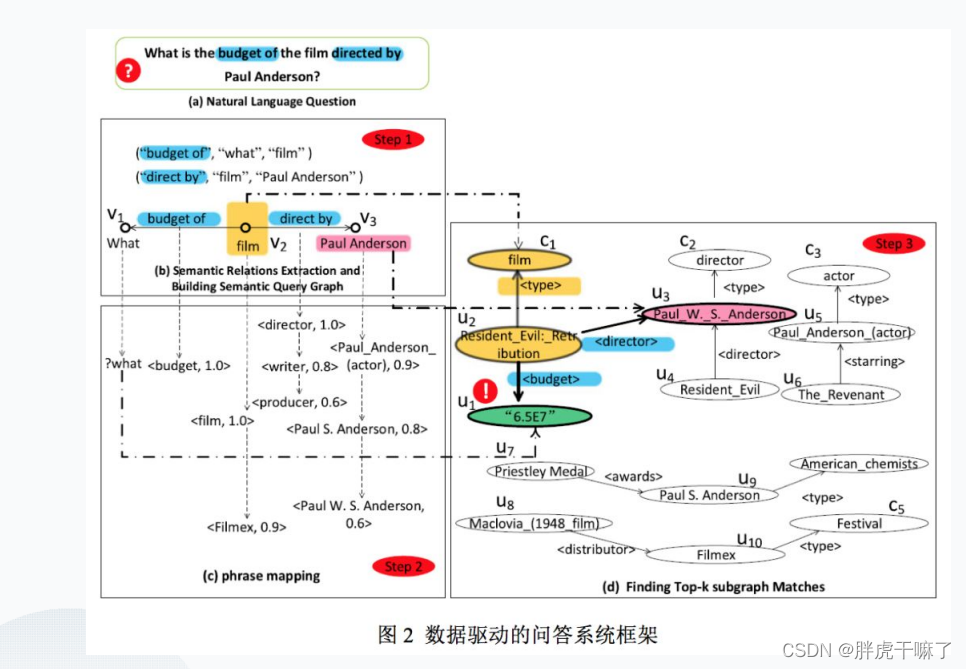
我们将对上面这幅流程图进行解释:
第一步,提取所有的语义关系,每个语义关系对应语义查询图中的一个边。如果两个语义关系有一个公共节点,那么他们在语义查询图中共享一个端点。在上图中,我们能够得到两个语义关系,

第二步,找到与语义查询图匹配的RDF图的子图。匹配是根据子图同构定义的。每个子图匹配都能得到一个分数,而目标是i找到所有子图与K个得分最高的匹配项。语义查询图的每个子图匹配都意味着对自然语言问题的回答
在上面很远的地方,我们陈述过关系优先框架的优点后,我们将对关系优先框架的缺点进行阐述:
(1)有些关系很难提取。如果关系在问题sentence中没有显式地出现,就很难提取出来这种语义关系,因为关系提取依赖于关系提及字典中提到的关系,例如:

(2)在关系优先框架中,语义关系提取依赖于用户疑问句的句法依赖树和启发式语言骨子额。而如果句法依赖树存在一定的错误,必然导致语义查询图的结构错误和答案错误
对于结点优先框架
核心阐述:先识别问题中的节点(实体、类别、变量),再通过句法依存树构造查询图结构,而后为图中各边分配候选谓词
这样做的优点:不但可以识别多关系,还可以处理隐式关系,并且不依赖于预先定义的图结构模板
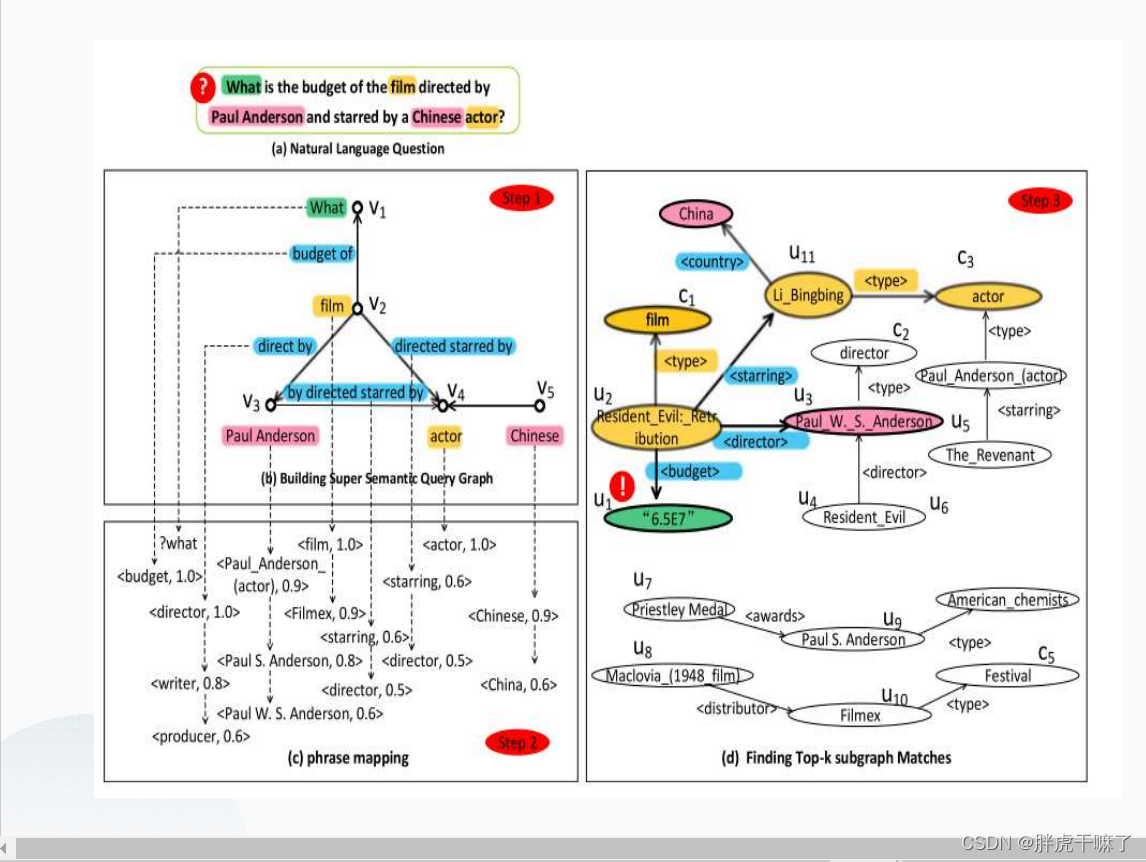

gAnswer的优缺点
优点:
(1)在问题理解阶段允许短语和结构的歧义,将消除歧义推到查询评估阶段
(2)有效地解决了模糊问题
缺点:
难以解决复杂问题
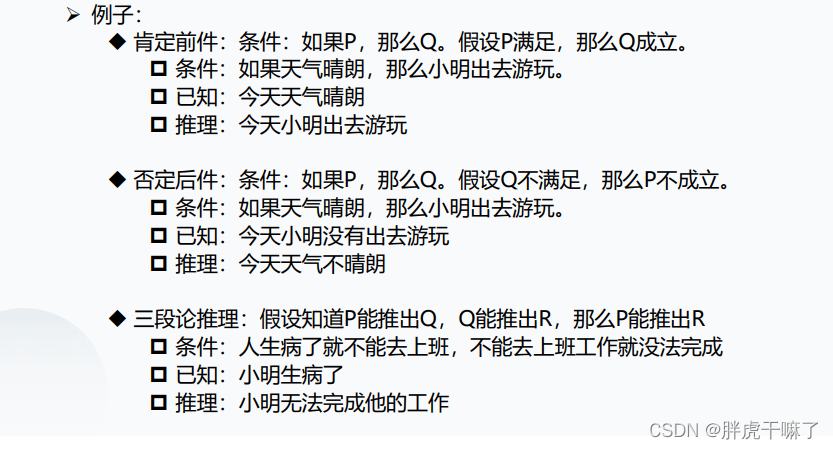
(16)传统推理的三种形式
传统推理的三种形式:
演绎推理、归纳推理、溯因推理
演绎推理
定义:从 一般的前提出发,通过推导得出具体的结论的过程。这是一种从一般到特殊(Top-down logic)的推导过程
归纳推理
定义:通过观察客观事实,进而总结和归纳抽象知识的推理过程。这是一种从特殊到一般(bottom up logic)的推导过程
注:归纳推理不一定是正确的

溯因推理
定义:将抽象的规则知识与观察现象相结合,寻找可能的原因的推理过程。该方法更加关注推理结果的可解释性

(17)(基于规则的推理之归纳推理【机器学习领域】)归纳推理算法PRA、AMIE的基本原理
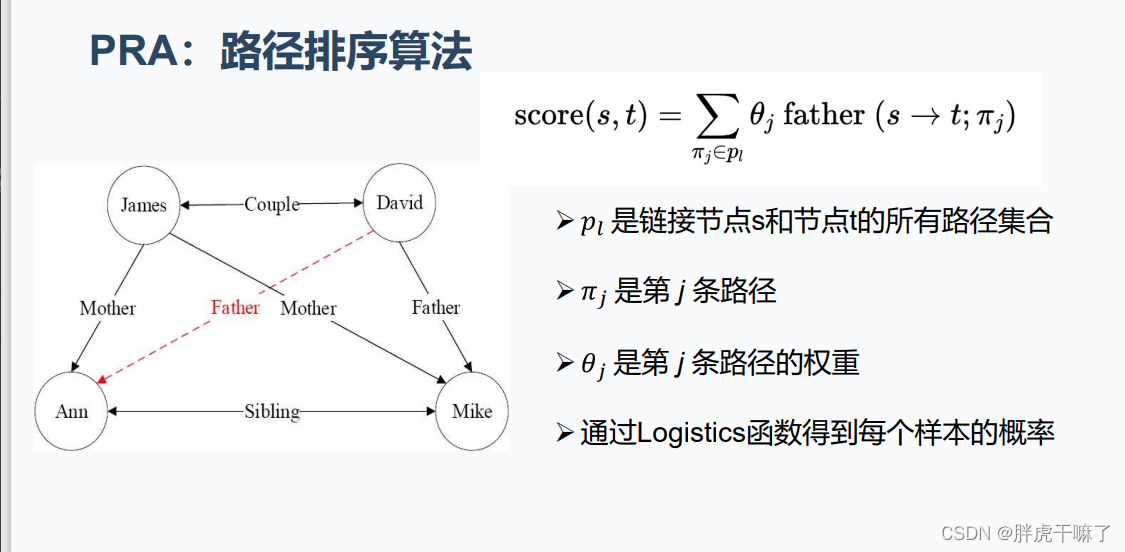
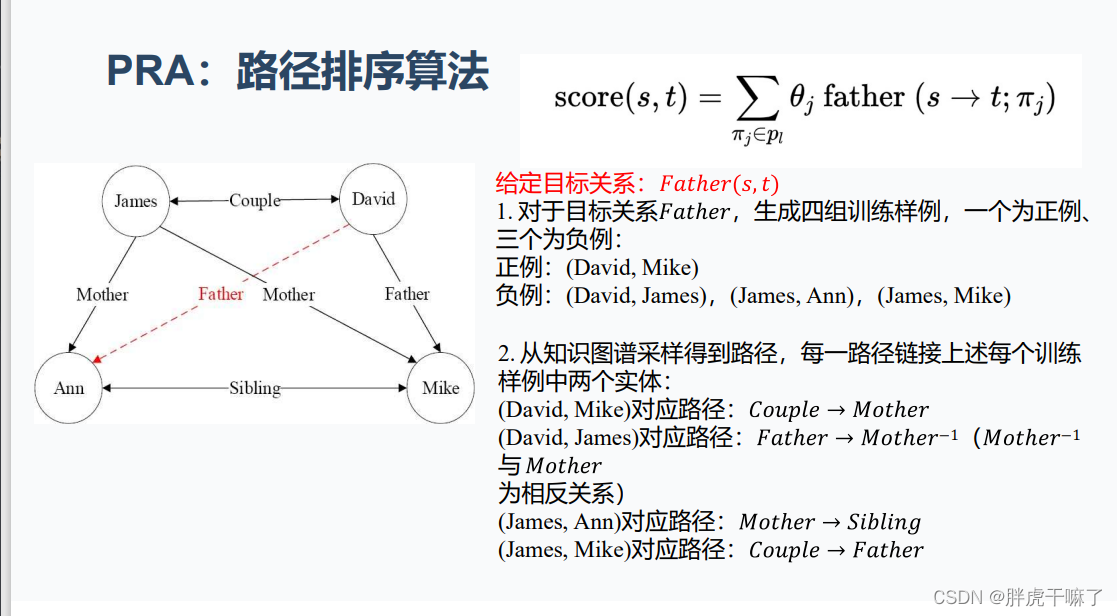
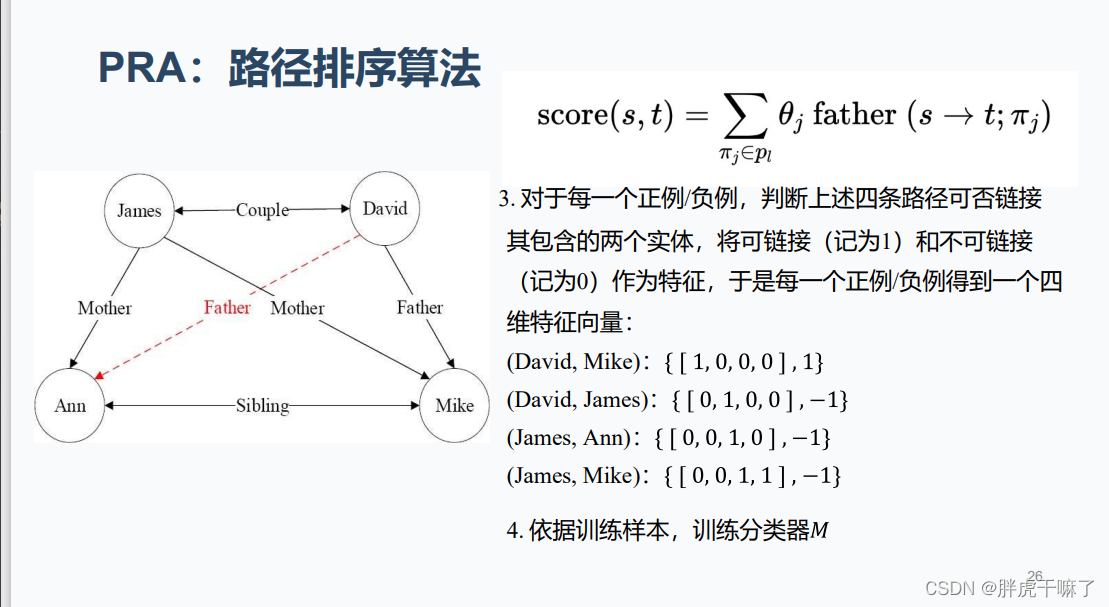
归纳推理算法PRA的基本原理——Path Ranking Algorithm,路径排序算法
该算法根据实体间存在的路径来判断实体间是否存在指定关系

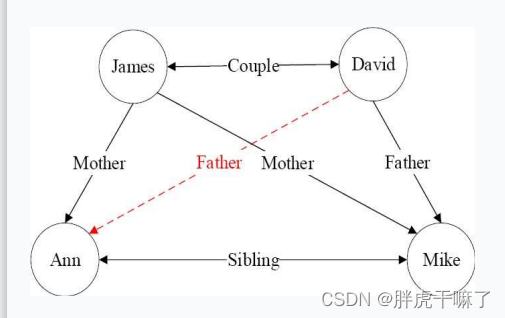
- 特征抽取:生成并选择路径特征集合。生成路径的方法有随机游走、广度优先搜索、深度优先搜索等等
- 特征计算:计算每个训练样例的特征值P(s->t; πj)。该特征值可以表示从实体节点s出发,通过关系路径πj到达实体节点t的概率;这种特征值也可以表示为布尔值,表示实体s到实体t之间是否存在路径πj;这种特征值,也可以是实体s到t之间的路径出现的频次、频率等
- 分类器训练:根据训练样例的特征值,为目标关系训练分类器。当训练好分类器后,。可以将该分类器用于推理两个实体之间是否存在目标关系
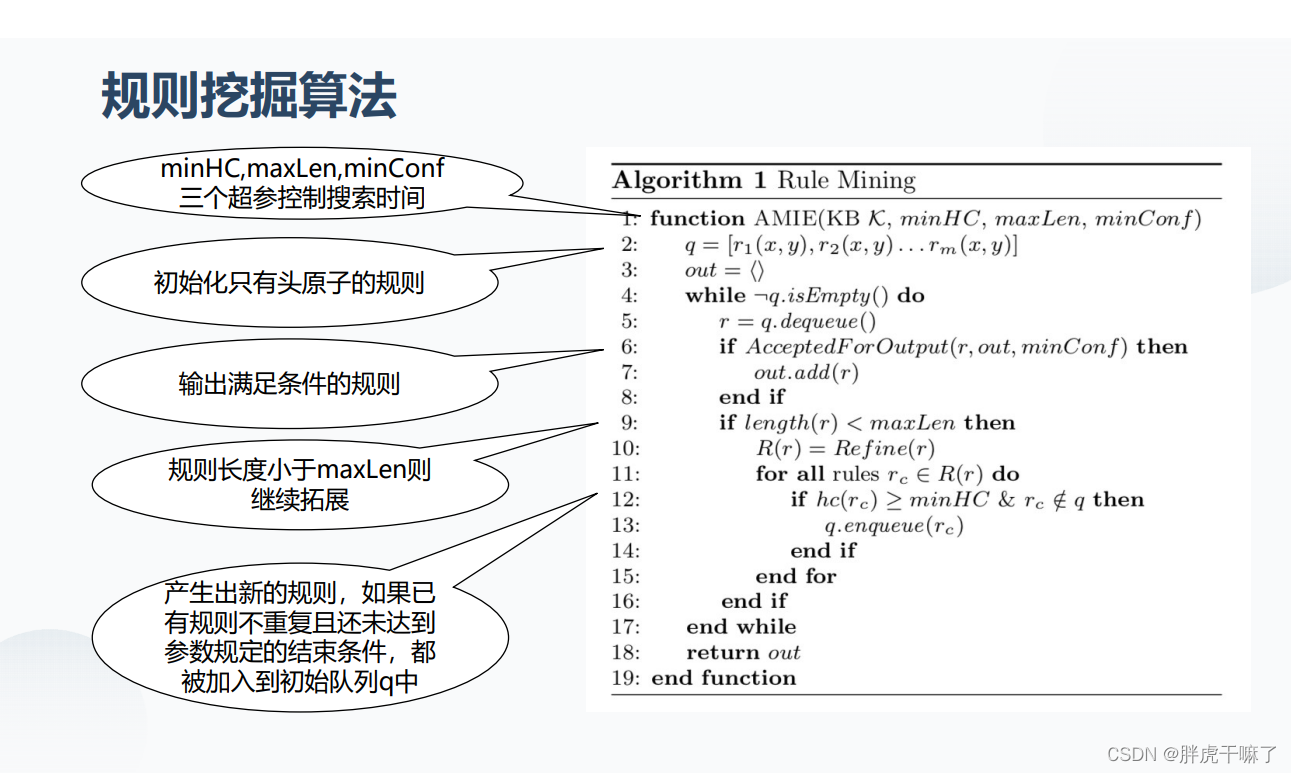
归纳推理算法AMIE的基本原理(规则挖掘算法)
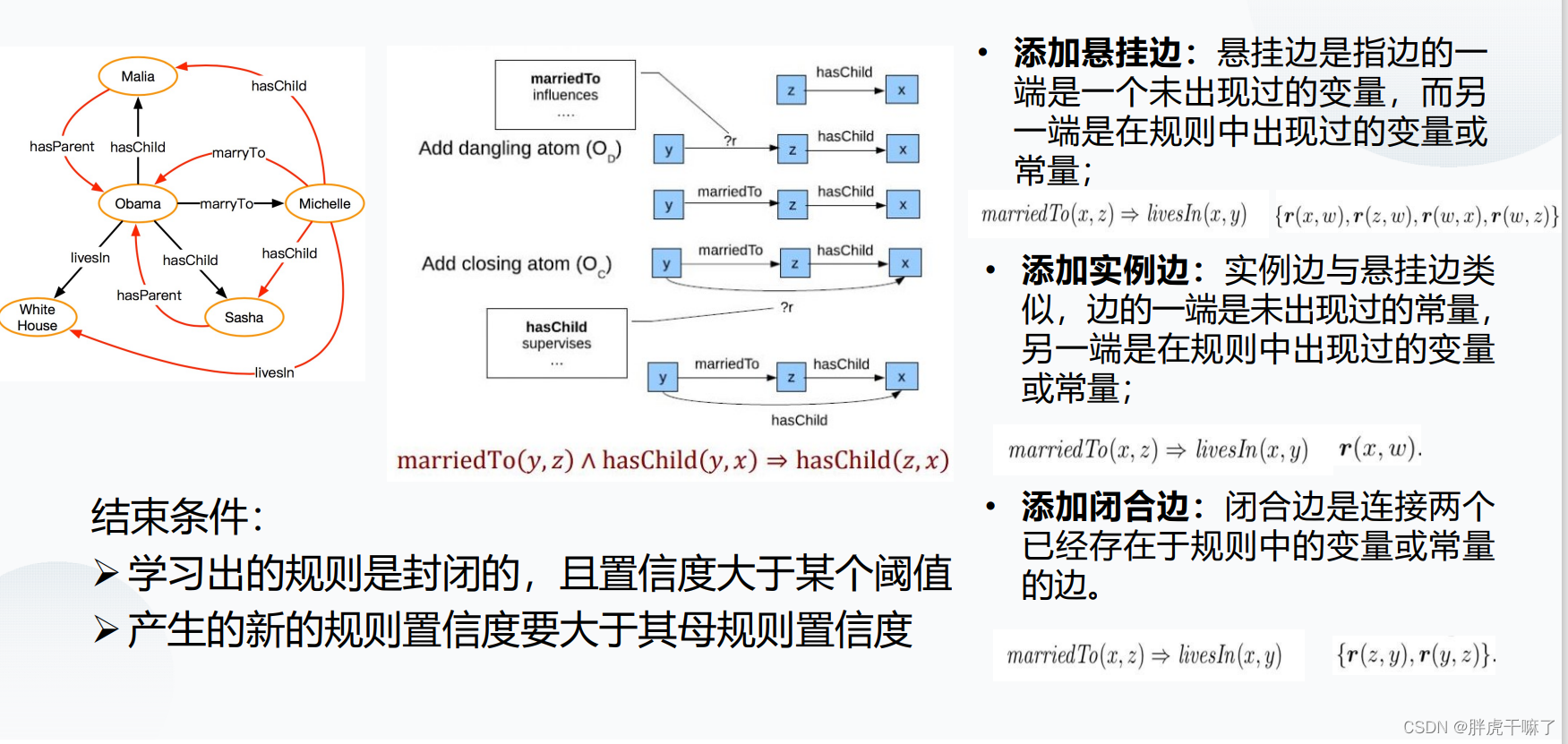
期望从不完备的知识库中来挖掘规则
规则发掘算法:对于每种关系,从规则体为空开始,通过三种扩展操作,保留支持度大于阈值的规则
上面提到的三种扩展操作:添加悬挂边、添加实例边、添加闭合边

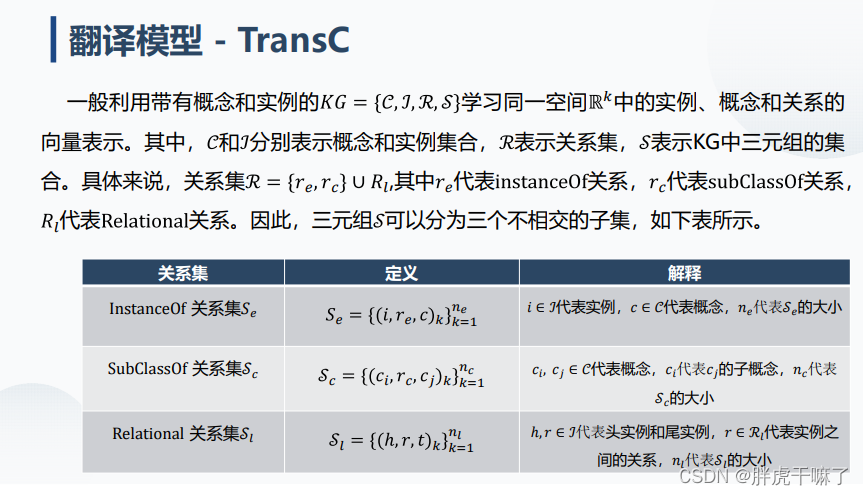
(18)嵌入式模型TransE、TransH、TransR、TransC的基本原理和优缺点
翻译模型的基本思想:将实体向量表示在低维稠密向量空间中,通过关系翻译衡量三元组的合理性。

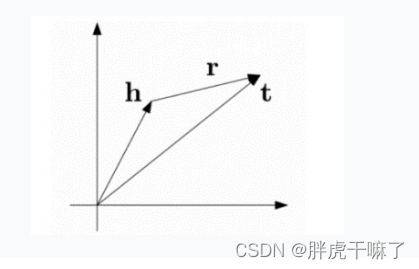
TransE
其基本思想,是把每个三元组(h,r,t)中的关系r看作从实体h到实体t的翻译,通过不断调整h,r,t,使得h+r与t尽量相等,即h+r≈t
d
(
h
+
r
,
t
)
=
∣
h
+
r
−
t
∣
L
1
/
L
2
d(h+r, t) = |h+r-t|_{L1/L2}
d(h+r,t)=∣h+r−t∣L1/L2
TransE优点:简单
TransE缺点:
(1)自反性问题,如果关系r具有自反性,即(h, r, t), (t, r, h)∈G,那么根据TransE模型可以知道h = t, r = 0
(2)不适合处理一对多、多对一、多对多等复杂问题

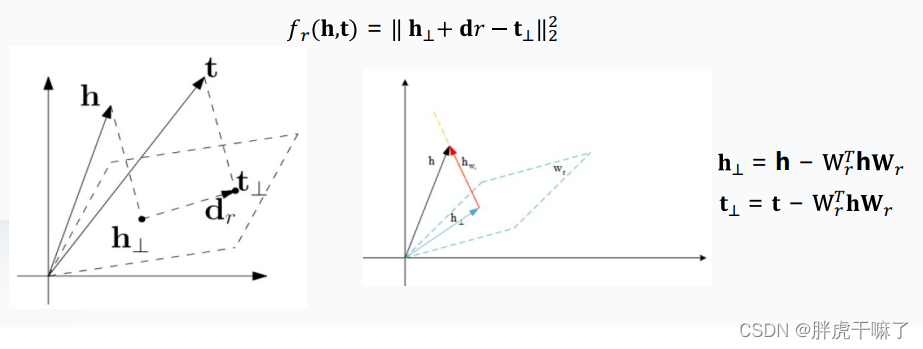
TransH
TransH对于每一个关系r,都定义一个超平面wr和一个关系dr(关系dr实际上是超平面wr的单位法向量),将三元组中的头、尾实体分别映射到该超平面中
TransH的优点:
每个实体在不同的关系下有不同的表示
TransH的缺点:
仍然假设实体和关系处于相同的语义空间中
TransR
该模型认为不同的关系应该拥有不同的语义空间,因此为每个关系构造相应的向量空间。对于每个三元组,首先应将实体投影到对应的关系空间中,然后再建立从头实体到尾实体的翻译关系
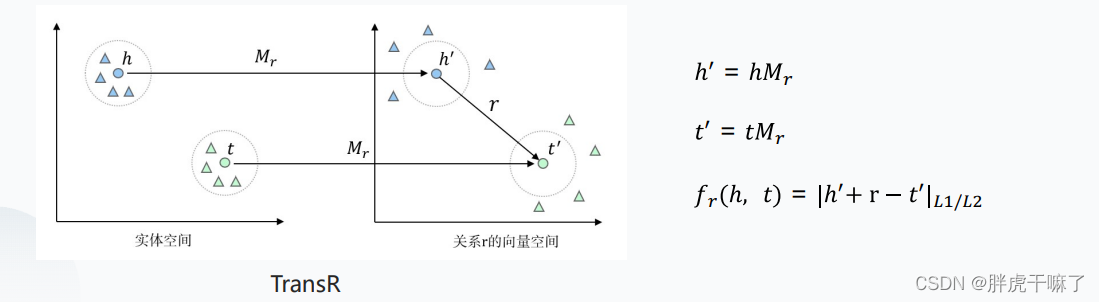
TransR的优点:
不同关系有不同的语义空间
TransR的缺点:
(1)在同一个关系r下,头、尾实体共享相同的投影矩阵,而且投影矩阵仅与关系有关
(2)模型参数增加,计算复杂度增加
TransC
基本思想:将每个概念 编码成球体,将每个实例编码为向量,在相同的语义空间中,使用相对位置对概念和实例、概念和子概念之间的关系进行建模
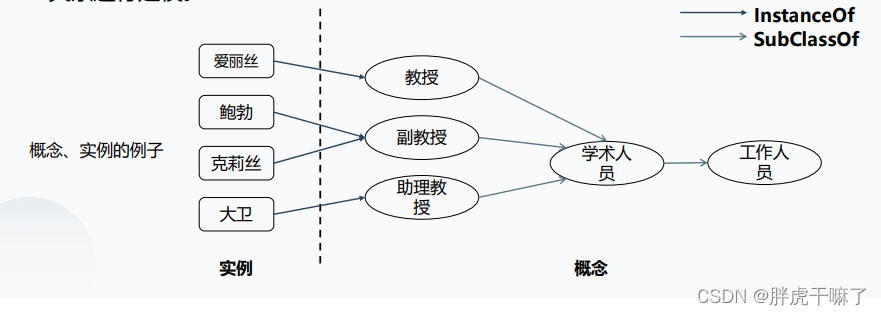

TransC的优点:
将概念和实例进行了区分
TransC的缺点:
(1)用球来表示概念,这是一种简单模型,过于幼稚,存在一定的局限性
(2)存在一个概念,在不同的三元组中,可能有不同的含义的问题
















 1723
1723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











