






一. Local Minima & Saddle Point
在这个地方参数对loss的微分为零,gradient descent就没有办法再update参数了,这个时候training就停下来了,参数不再update了,loss当然就不会再下降了。
gradient为零的时候:
- local minima
- saddle point(gradient是零,但是不是local minima,也不是local maxima的地方)
gradient为零的点统称为critical point。

如何区分local minima和saddle point?
因为如果是卡在local minima,现在所在的位置已经是loss最低的点,往四周走 loss都会比较高,那可能就没有路可以走了。但saddle point就比较没有这个问题,saddle point旁边还是有路可以走的,只要逃离saddle point,就有可能让loss更低。
尽可能知道loss function的形状:

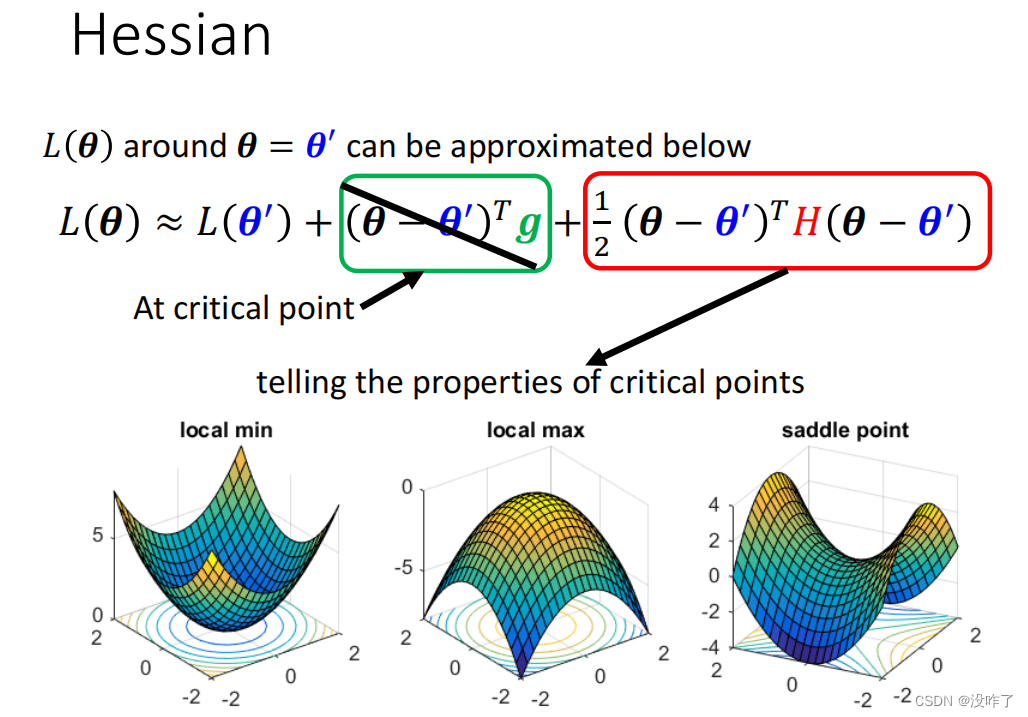
- 当H矩阵为正定,eigen value(特征值)全正时,临界点为local minima
- 当H为负定,eigen value全负时,临界点为local maxima
- 如果eigen value有正有负,临界点为saddle point


例子:在(0,0)这个点,矩阵有两个eigen value 2和-2,有正有负,代表是saddle point。

之前我们参数update的时候,都是看gradient 看g,发现g变成0了 不能再看g了,但如果是一个saddle point的话,还可以再看H。
因为u是一个eigen vector,所以H乘上eigen vector会得到λ eigen value乘上eigen vector,所以在这边得到uᵀ乘上λu,把uᵀ跟u乘起来得到‖u‖²,所以得到λ‖u‖²。
θ减θ'是一个eigen vector的话,会发现说我们这个红色的项里面其实就是λ‖u‖²。
如果eigen value小于零的话,那λ‖u‖²就会小于零,因为‖u‖²一定是正的,所以eigen value是负的。那这一整项就会是负的,也就是u的transpose乘上H乘上u是负的,也就是红色这个框框里面是小于零的 是负的。
只要沿著u也就是eigen vector的方向,去更新你的参数 去改变你的参数,你就可以让loss变小了。虽然在critical point没有gradient,如果是在一个saddle point,只要找出负的eigen value,再找出它对应的eigen vector,用这个eigen vector去加θ',就可以找到一个新的点,这个点的loss比原来还要低。

 在一维中,一维的一个参数的error surface好像到处都是local minima,但是在二维空间来看它可能就只是一个saddle point。现实中极少碰到local minima。
在一维中,一维的一个参数的error surface好像到处都是local minima,但是在二维空间来看它可能就只是一个saddle point。现实中极少碰到local minima。

二、Batch
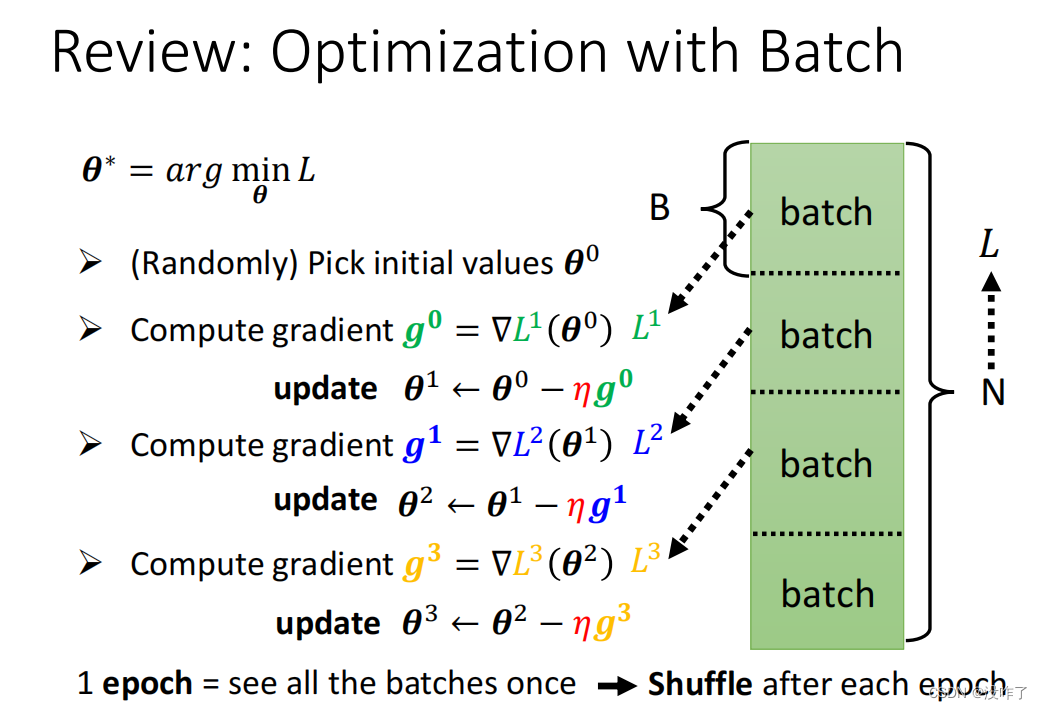
我们不会拿所有的资料一起去算出 Loss,我们只会拿一个 Batch 的资料拿出来算 Loss。
Epoch:所有的 Batch 看过一遍叫做一个 Epoch
Shuffle:在每一个 Epoch 开始之前会分一次 Batch,每一个 Epoch 的 Batch 都不一样,每一个 Epoch 都不一样叫做 Shuffle。
Small Batch or Large Batch?

使用Batch, 如果 Batch Size 等于1的话代表我们每次 Update 参数的时候,只需要拿一笔资料出来算 Loss。看一笔资料 就 Update 一次参数。如果今天总共有20笔资料的话,那在每在一个 Epoch 里面,参数会 Update 20次。用一笔资料算出来的 Loss显然是比较 Noisy 的,所以Update 的方向是曲曲折折的。
左边的方法有一个优点就是它这一步走的是稳的。而右边这个方法它的缺点就是它每一步走的是不稳的。


一个 Epoch 大的 Batch 花的时间反而是比较少的。
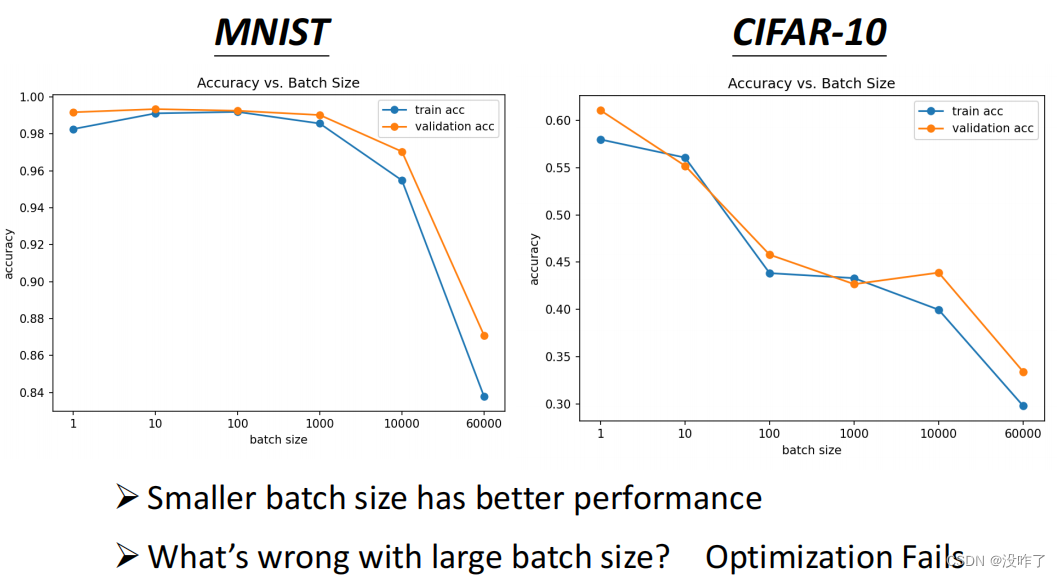
神奇的地方是 Noisy 的 Gradient反而可以帮助 Training。Batch Size 越大,Training 的结果也是越差的。同样的 Model,所以这个不是 Model Bias 的问题,这个是 Optimization 的问题。
why?
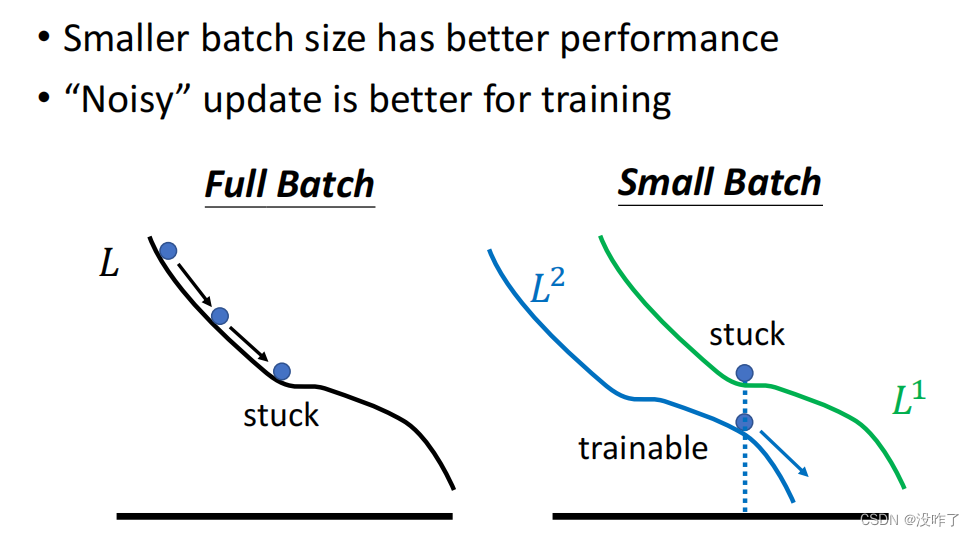
假设是 Full Batch,那在 Update 你的参数的时候,就是沿著一个 Loss Function 来 Update 参数,Update 参数的时候走到一个 Local Minima,走到一个 Saddle Point就停下来了,Gradient 是零。
但是假如是 Small Batch 的话,因为每次是挑一个Batch出来,算它的Loss,等于每一次Update参数的时候,用的Loss Function都是有差异的。选到第一个 Batch 的时候,用 L1 来算Gradient,到第二个 Batch 的时候,用 L2 来算Gradient,假设用 L1 算 Gradient 的时候发现 Gradient 是零,卡住了。但 L2 它的 Function 跟 L1 又不一样,所以 L1 卡住了,但L2 就不一定会卡住啊,所以 L1 卡住了没关系,换下一个 Batch ,L2 再算 Gradient。还是有办法 Training Model。
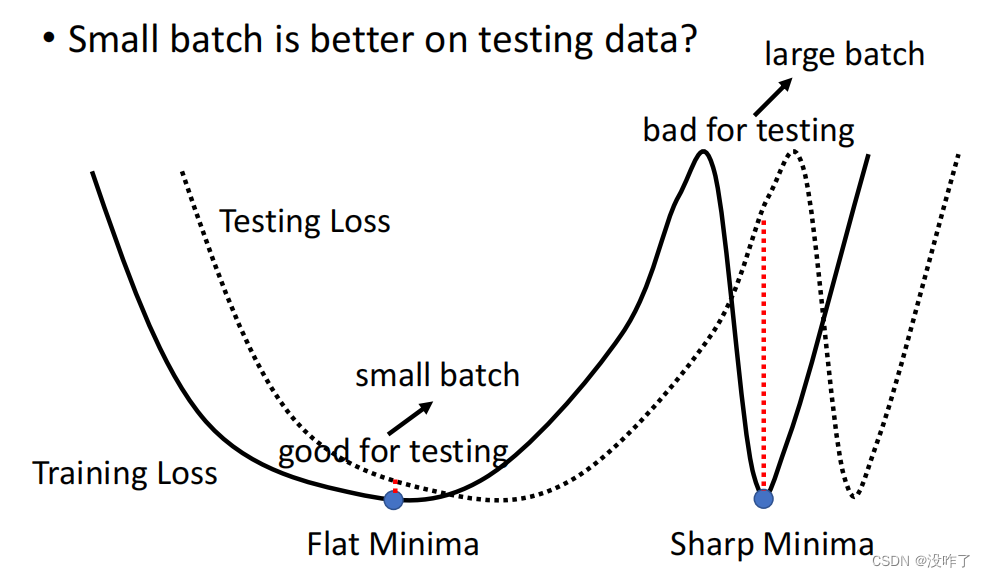
对这个在一个盆地里面的 Minima 来说,它的在 Training 跟 Testing 上面的结果不会差太多。但是对右边这个在峡谷里面的 Minima 来说,一差就可以天差地远。
小的 Batch它有很多的 Loss,它每次 Update 的方向都不太一样,所以如果今天这个峡谷非常地窄,它可能一个不小心就跳出去了。所以一个很小的峡谷没有办法困住小的 Batch。而大的 Batch容易在峡谷里面。
testing时small batch效果更好,large batch效果更差。
总结
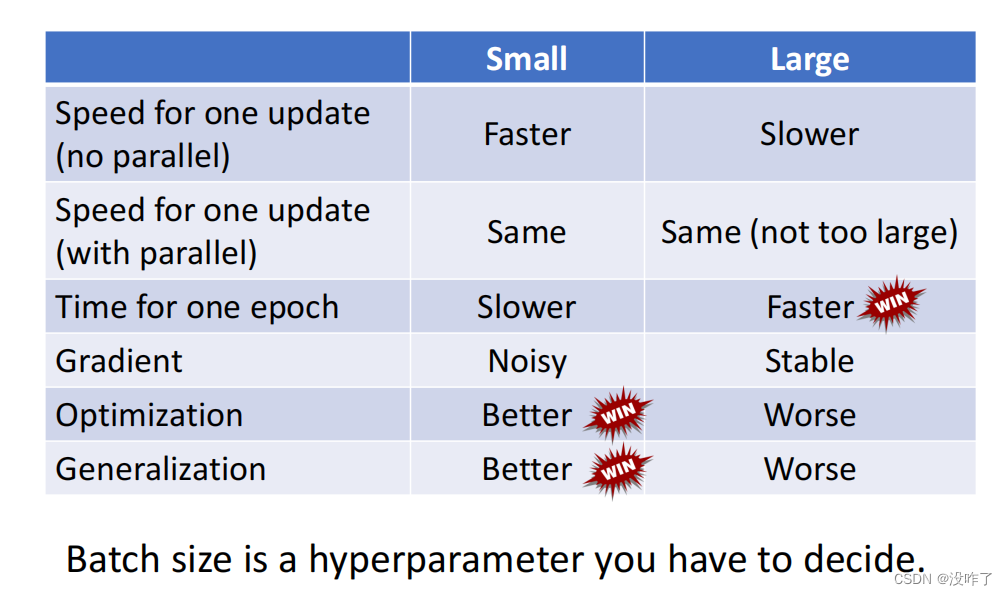
Parameter:模型参数;Hyperparameter:超参数
Momentum
 一般的Gradient Descent:计算一下 Gradient,然后往 Gradient 的反方向去 Update 参数;再计算一次 Gradient,再往 Gradient 的反方向再 Update 一次参数。
一般的Gradient Descent:计算一下 Gradient,然后往 Gradient 的反方向去 Update 参数;再计算一次 Gradient,再往 Gradient 的反方向再 Update 一次参数。
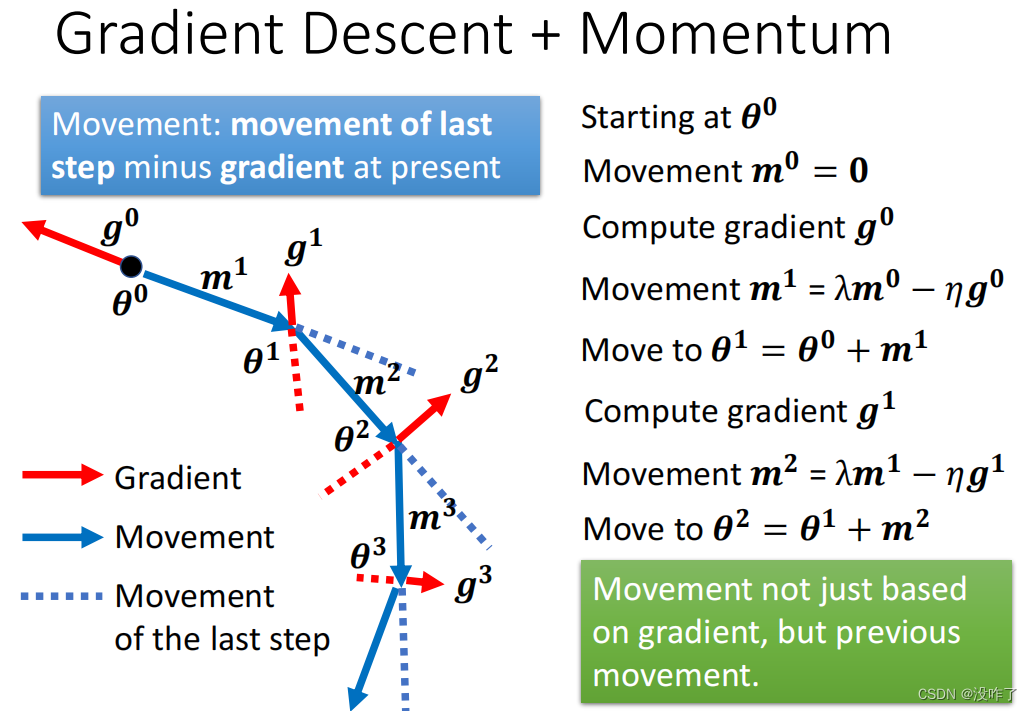
如果加上 Momentum 的话:找一个初始的参数,然后假设潜在一开始的时候前一步的变化量就设为 0,然后在 θ0 的地方,计算 g0,计算 Gradient 的方向。
从第二步开始,计算 g1,用上一次 Update 方向也就是 m1 减掉 g1,当做新的 Update 的方向,写成 m2,以此类推。
加上 Momentum 以后,Gradient 的负反方向加上前一次移动的方向。也就是说Update 的方向,不是只考虑现在的 Gradient,而是考虑过去所有 Gradient 的总合。

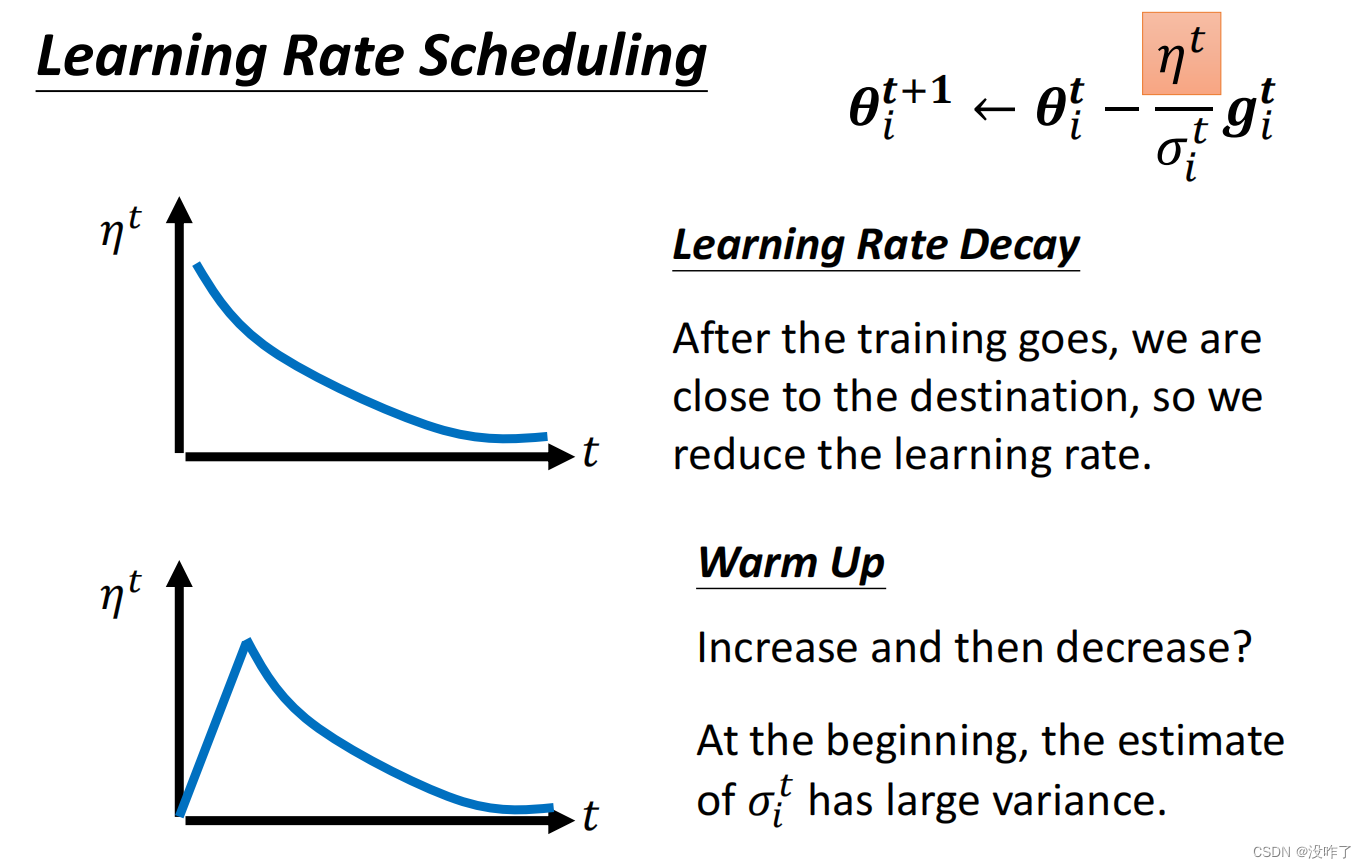
三、自动调整学习率Adaptive Learning Rate
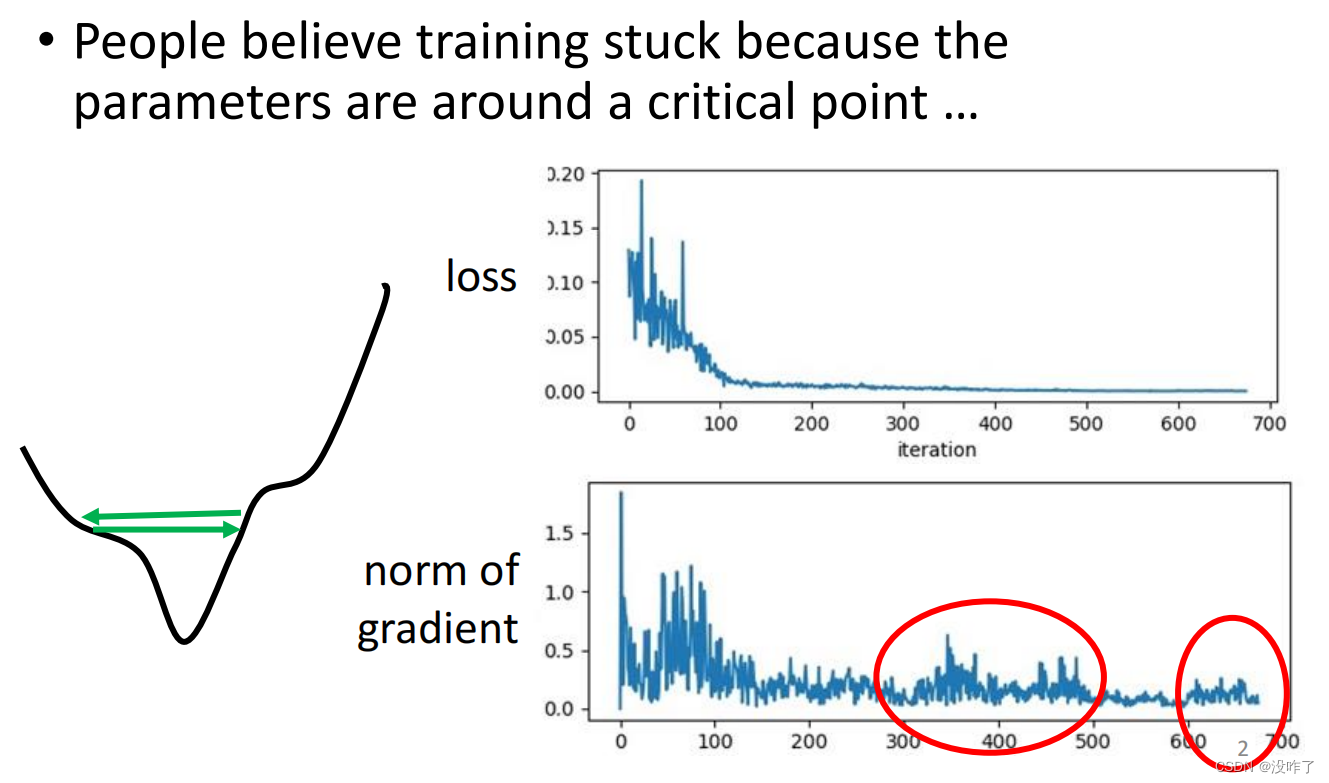 训练一个network,train到发现loss不再下降的時候,并不一定是梯度为0或者极小。
训练一个network,train到发现loss不再下降的時候,并不一定是梯度为0或者极小。
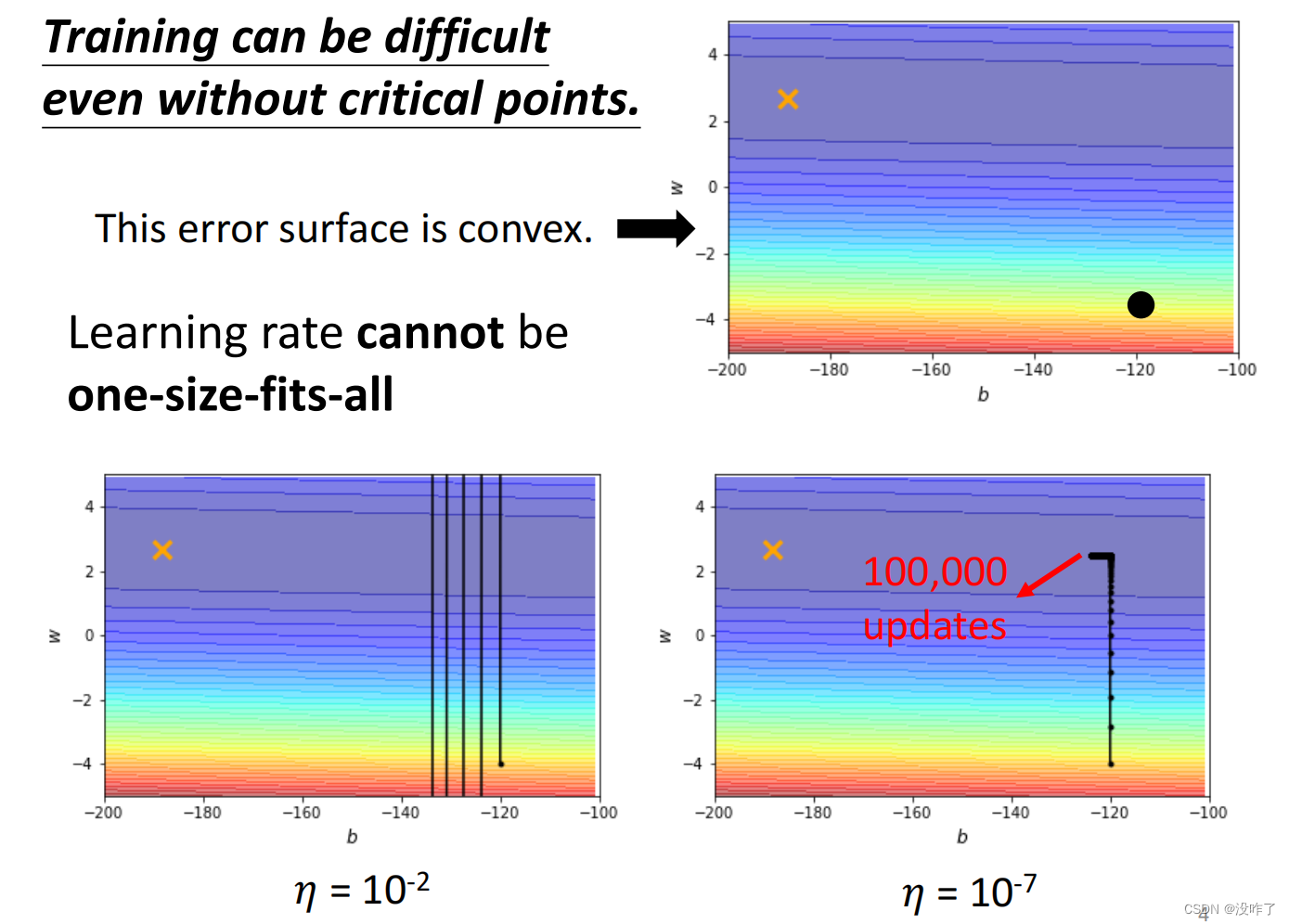
这个训练永远走不到终点,因为learning rate已经太小了,上面这个地方坡度已经非常的平滑了,这么小的learning rate根本没有办法再让训练前进。
在之前的gradient descend,所有的参数都是设同样的learning rate。现在需要会客制化的learning rate。
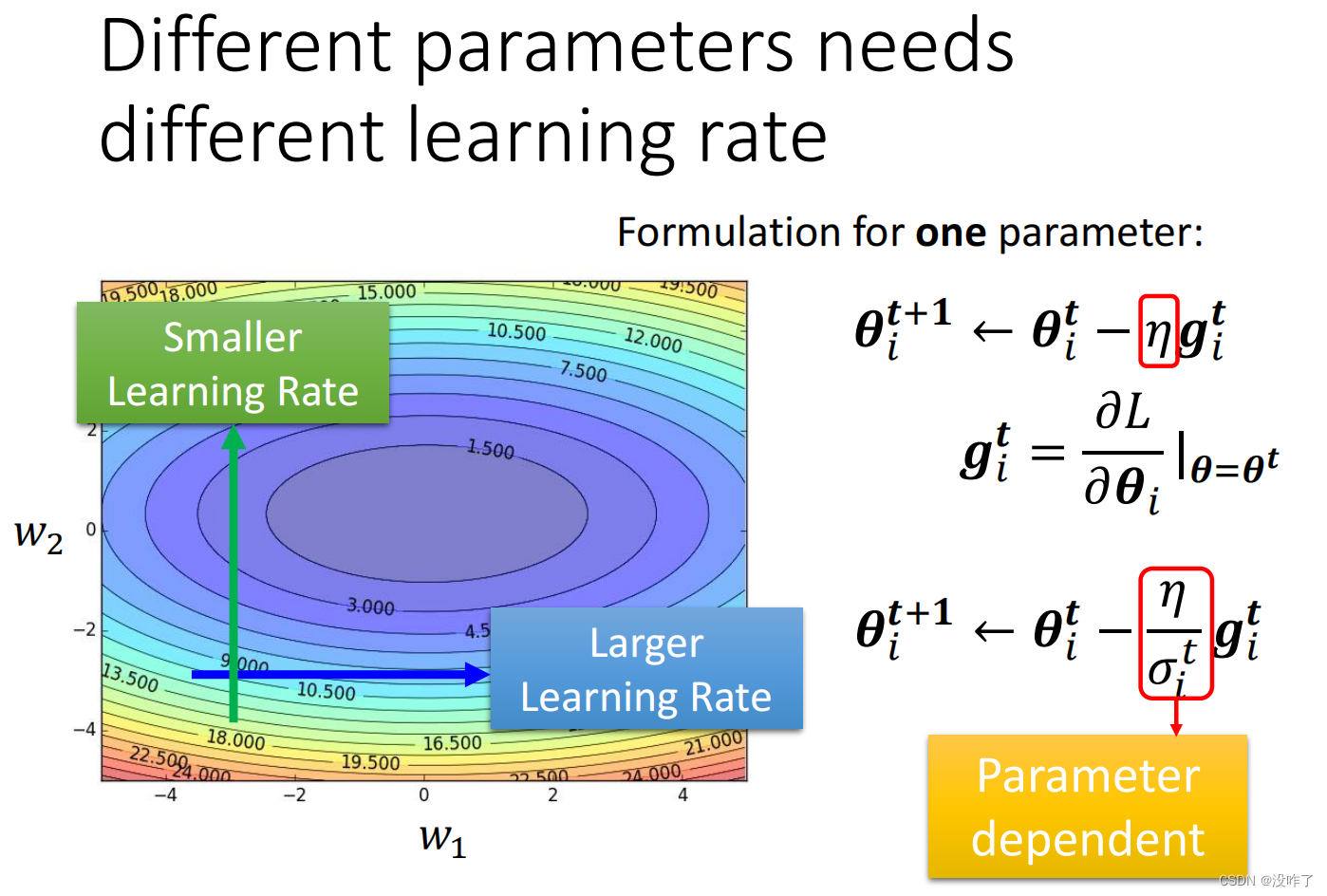
1、Root Mean Square
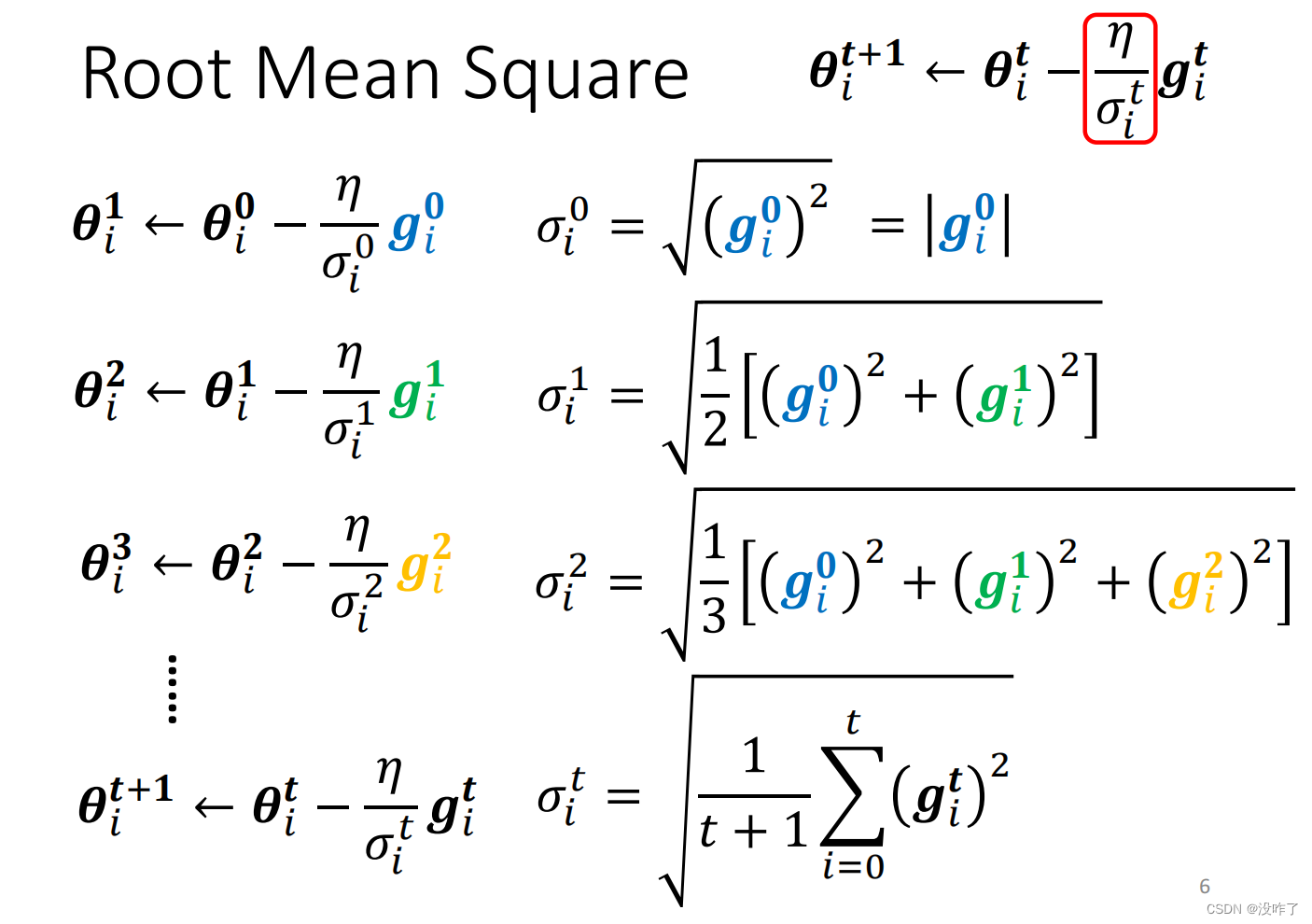
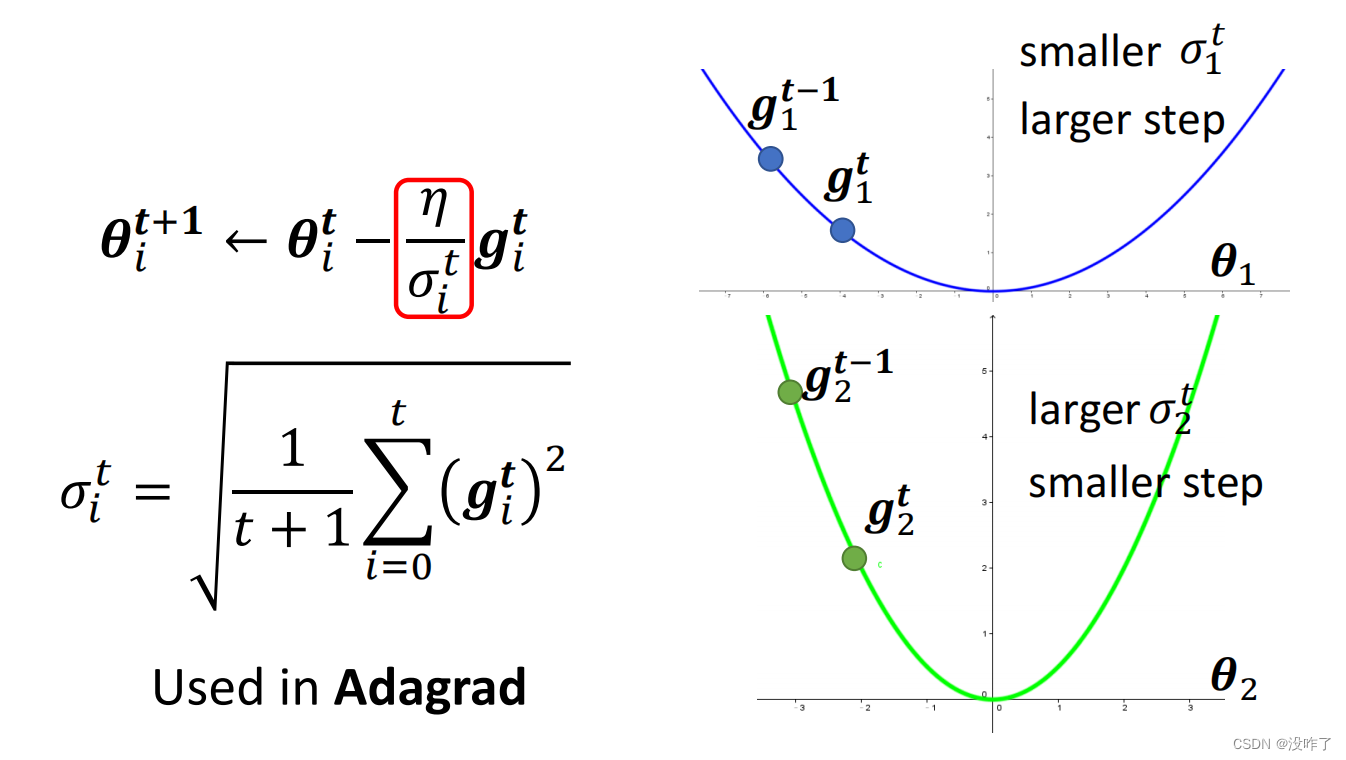
在θᵢ²这个方向上loss的变化比较大,所以算出来的gradient都比较大,σ就比较大;σ比较大,update的时候step就比较小。所以有了σ这一项以后呢,就可以随着gradient的不同来自动的调整learning rate的大小。但是这个有个问题:就算是同一个参数,它需要的learning rate也会随着时间而改变。
2、RMSProp



四、Classification

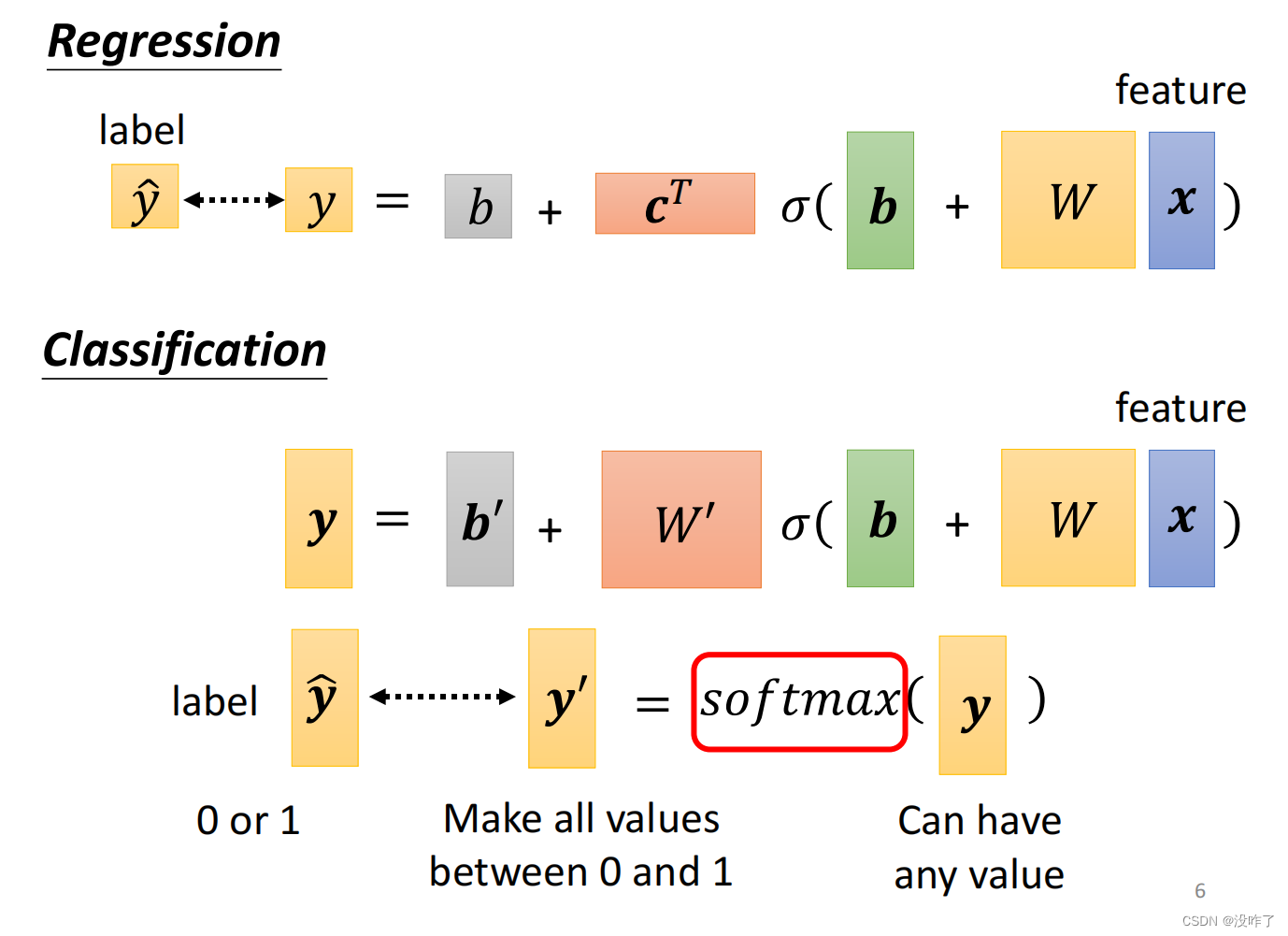
两个class更常用sigmoid
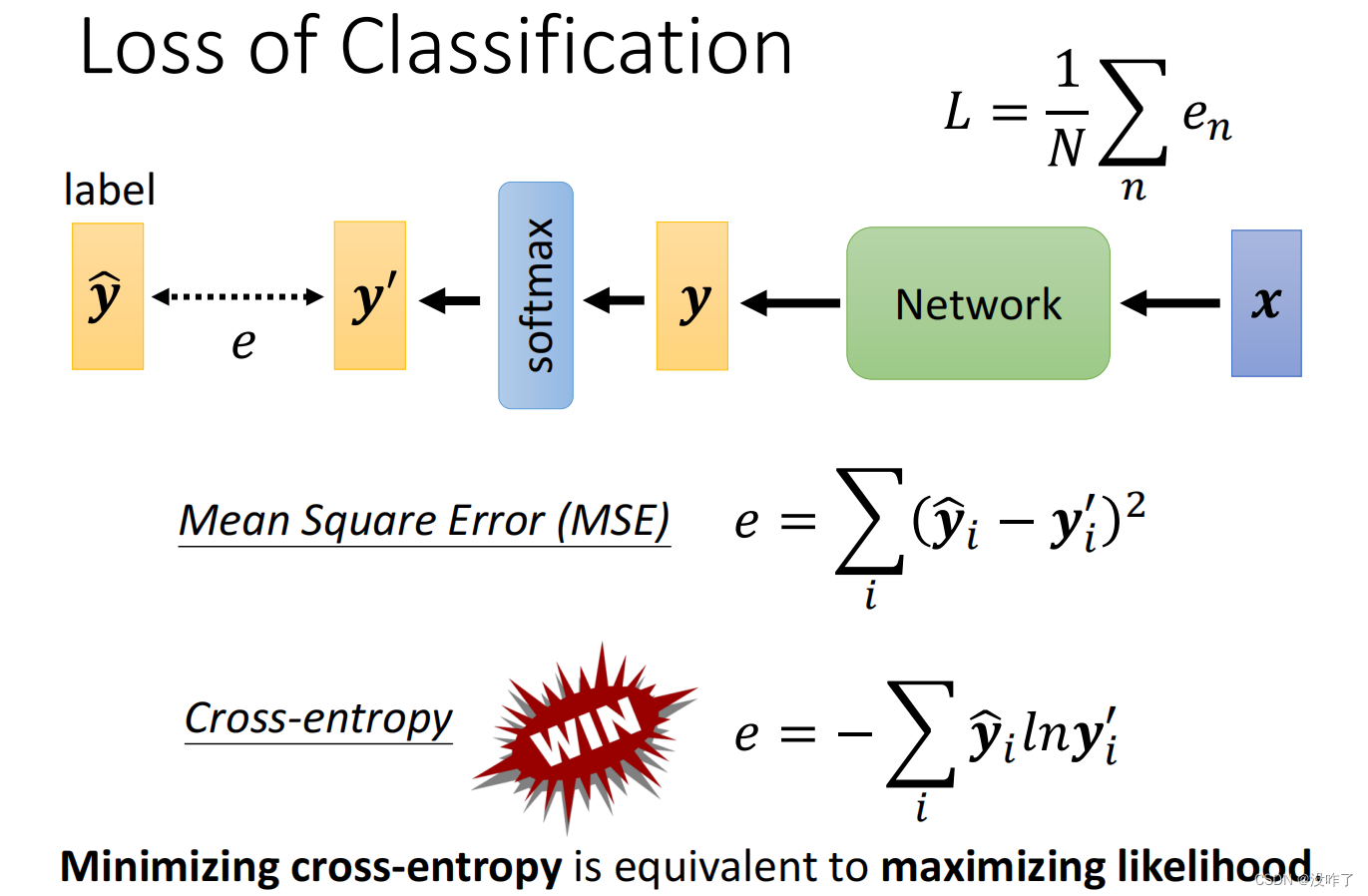

从optimization的角度,Cross-entropy比Mean Square Error更加适合用在分类上。使用Cross-entropy这个Loss function的时候,pytorch自动帮你把Soft-max加到你的Network的最后一层。














 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









