







什么是队列
队列的存储方式是“先进先出”,只能向队尾插入数据,从队头移出数据。队列的原型在生活中也很常见,比如排队打饭,先来的先打。
队列的实现有两种方式:链队列和循环队列,像下面这个图一样
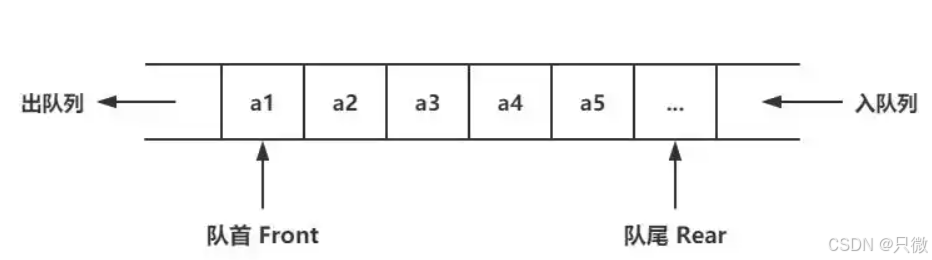
链队列可以看做是单链表的一种特殊情况,用指针连接各个节点
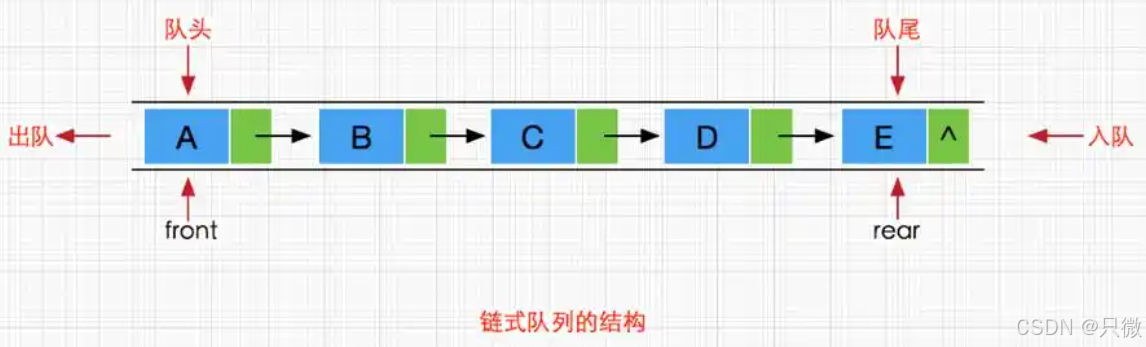
循环队列是一种顺序表,使用一组连续的存储单元依次存放队列元素,用两个指针front和rear分别指向队首和队尾元素,当head和rear走到底时,下一步回到开始的位置,从而在这组连续空间内循环,循环队列能够解决溢出问题,如果不循环的话两个指针都是一直往前的,可能会导致溢出。
队列的缺点是查找较慢,要从头开始一个一个查找,在某些情况下可以使用优先队列,让优先级高的先出队
队列的简要实现代码很容易,最简单的手写队列如下
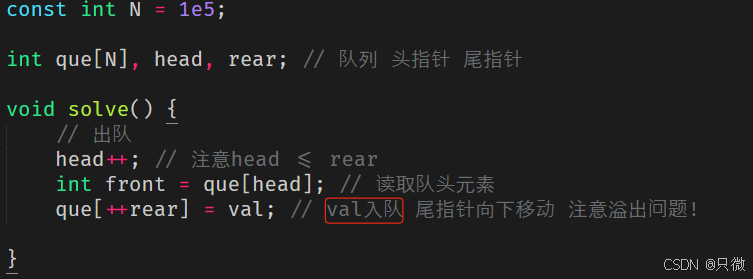
请务必注意这个队列不是循环队列,rear可能大于N从而可能会有溢出问题。在竞赛中一般采用STL中的queue或者手写静态数组实现队列。
STL queue
STL queue的主要操作如下
queue<int> que:定义一个名为que的队列,数据类型为int,可以更具实际需求换成其它的类型que.push(i):将i这个元素入队que.front():返回队首元素que.pop():删除队首元素que.back():返回队尾元素que.size():返回队列中元素的个数que.empty():判断队列是否为空
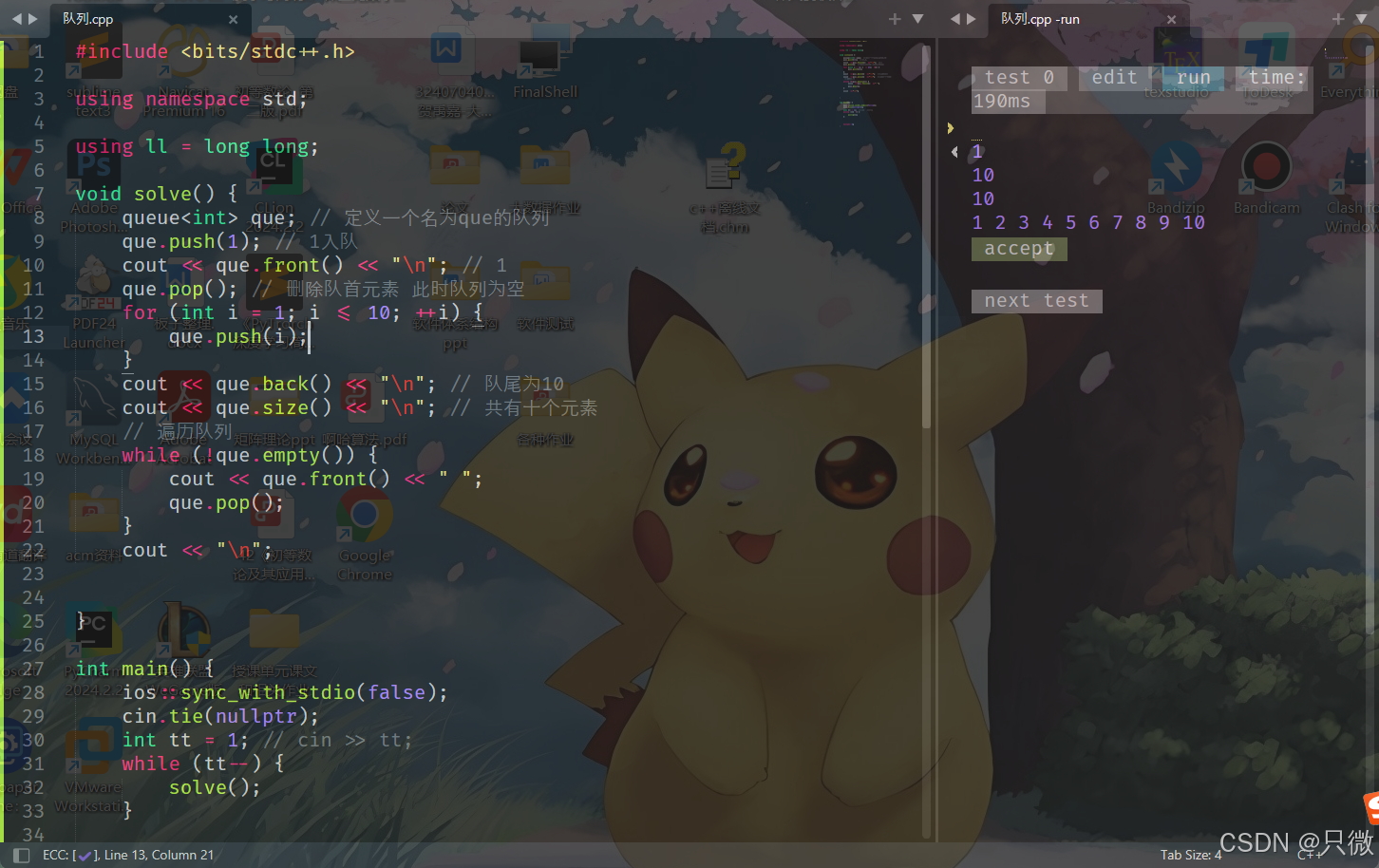
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
void solve() {
queue<int> que; // 定义一个名为que的队列
que.push(1); // 1入队
cout << que.front() << "\n"; // 1
que.pop(); // 删除队首元素 此时队列为空
for (int i = 1; i <= 10; ++i) {
que.push(i);
}
cout << que.back() << "\n"; // 队尾为10
cout << que.size() << "\n"; // 共有十个元素
// 遍历队列
while (!que.empty()) {
cout << que.front() << " ";
que.pop();
}
cout << "\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int tt = 1; // cin >> tt;
while (tt--) {
solve();
}
return 0;
}
下面这个题是对queue的一个应用,后面还有手动实现队列的代码
机器翻译(洛谷P1540)
题目传送门: 机器翻译
[NOIP2010 提高组] 机器翻译
题目背景
NOIP2010 提高组 T1
题目描述
小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章。
这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换。对于每个英文单词,软件会先在内存中查找这个单词的中文含义,如果内存中有,软件就会用它进行翻译;如果内存中没有,软件就会在外存中的词典内查找,查出单词的中文含义然后翻译,并将这个单词和译义放入内存,以备后续的查找和翻译。
假设内存中有 M M M 个单元,每单元能存放一个单词和译义。每当软件将一个新单词存入内存前,如果当前内存中已存入的单词数不超过 M − 1 M-1 M−1,软件会将新单词存入一个未使用的内存单元;若内存中已存入 M M M 个单词,软件会清空最早进入内存的那个单词,腾出单元来,存放新单词。
假设一篇英语文章的长度为 N N N 个单词。给定这篇待译文章,翻译软件需要去外存查找多少次词典?假设在翻译开始前,内存中没有任何单词。
输入格式
共 2 2 2 行。每行中两个数之间用一个空格隔开。
第一行为两个正整数 M , N M,N M,N,代表内存容量和文章的长度。
第二行为 N N N 个非负整数,按照文章的顺序,每个数(大小不超过 1000 1000 1000)代表一个英文单词。文章中两个单词是同一个单词,当且仅当它们对应的非负整数相同。
输出格式
一个整数,为软件需要查词典的次数。
样例 #1
样例输入 #1
3 7
1 2 1 5 4 4 1
样例输出 #1
5
提示
样例解释
整个查字典过程如下:每行表示一个单词的翻译,冒号前为本次翻译后的内存状况:
1:查找单词 1 并调入内存。1 2:查找单词 2 并调入内存。1 2:在内存中找到单词 1。1 2 5:查找单词 5 并调入内存。2 5 4:查找单词 4 并调入内存替代单词 1。2 5 4:在内存中找到单词 4。5 4 1:查找单词 1 并调入内存替代单词 2。
共计查了 5 5 5 次词典。
数据范围
- 对于 10 % 10\% 10% 的数据有 M = 1 M=1 M=1, N ≤ 5 N \leq 5 N≤5;
- 对于 100 % 100\% 100% 的数据有 1 ≤ M ≤ 100 1 \leq M \leq 100 1≤M≤100, 1 ≤ N ≤ 1000 1 \leq N \leq 1000 1≤N≤1000。
这个题题意不难,拿队列模拟即可,代码如下
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
int vis[1500];
queue<int> q;
void solve() {
memset(vis, 0, sizeof(vis));
int m, n; cin >> m >> n;
int cnt = 0;
for (int i = 1; i <= n; ++i) {
int x; cin >> x;
if (!vis[x]) {
++cnt;
q.push(x);
vis[x] = 1;
while (q.size() > m) {
vis[q.front()] = 0;
q.pop();
}
}
}
cout << cnt << "\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int tt = 1; // cin >> tt;
while (tt--) {
solve();
}
return 0;
}
手写循环队列
我们来手写一下循环队列然后用我们手写的循环队列解决该题,竞赛里一般使用静态的,动态的用起来不方便
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 1500;
int vis[N];
struct myqueue {
int data[N];
// 如果是动态分配 int *data;
int head, rear; // 队头 队尾
bool init() {
// 动态分配这样写
// q.data = (int *)malloc(N * sizeof(int));
// if (!q.data) return false;
head = rear = 0;
return true;
}
int size() {
return (rear - head + N) % N; //队列长度
}
bool empty() {
if (size() == 0) return true;
else return false;
}
bool push(int x) {
if ((rear + 1) % N == head) return false; // 队列满了
data[rear] = x;
rear = (rear + 1) % N;
return true;
}
bool pop(int &x) {
if (head == rear) return false; // 队列为空
x = data[head];
head = (head + 1) % N;
return true;
}
int front() {
return data[head];
}
}q;
void solve() {
int m, n; cin >> m >> n;
memset(vis, 0, sizeof(vis));
q.init();
int cnt = 0;
for (int i = 1; i <= n; ++i) {
int x; cin >> x;
if (!vis[x]) {
++cnt;
q.push(x);
vis[x] = 1;
while (q.size() > m) {
int tmp;
q.pop(tmp);
vis[tmp] = 0;
}
}
}
cout << cnt << "\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int tt = 1; // cin >> tt;
while (tt--) {
solve();
}
return 0;
}
双端队列和单调队列
双端队列和单调队列的概念
双端队列是两头都可进可出的队列,同时具有队列和栈 (先进后出)性质,它能在两端进行插入和删除,而且也只能在两端插入和删除
简单手写的双端队列如下 但是请务必追不能让队头和队尾溢出
const int N = 1e5 + 5;
int que[N], head, tail; // 队头队尾指针 队列大小为 tail - head + 1
head++; // 出队
que[--head] = data; // 数据入队头
que[head]; // 读取队头数据
tail--; // 弹走队尾
que[tail++] = data; // 从队尾入队
也可以使用STL中的deque,用法如下
dq[i]:返回队列中下标为i的元素dq.front():返回队头dq.back():返回队尾dq.pop_back():删除队尾 不返回值dq.pop_front():删除队头 不返回值dq.push_back(x):队尾入队dq.push_front(x):队首入队
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
void solve() {
deque<int> dq;
for (int i = 1; i <= 10; ++i) {
if (i & 1) dq.push_back(i);
else dq.push_front(i);
}
// 10 8 6 4 2 1 3 5 7 9
for (auto it : dq) cout << it << " ";
cout << "\n";
cout << dq[0] << " " << dq.front() << "\n"; // 10 10
cout << dq[9] << " " << dq.back() << "\n"; // 9 9
dq.pop_back();
// 10 8 6 4 2 1 3 5 7
dq.pop_front();
// 8 6 4 2 1 3 5 7
for (auto it : dq) cout << it << " ";
cout << "\n";
dq.push_front(15);
dq.push_back(20);
// 15 8 6 4 2 1 3 5 7 20
for (auto it : dq) cout << it << " ";
cout << "\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int tt = 1; // cin >> tt;
while (tt--) {
solve();
}
return 0;
}
双端队列的经典应用是单调队列。单调队列中的元素是单调有序的,且元素在队列中的顺序和原来在队列中的顺序一致,单调队列的队头和队尾都能入队和出队。用单调队列处理时,每个元素只需要进出队一次,复杂度为 O ( n ) O(n) O(n)
单调队列与滑动窗口
来介绍一下单调队列的基本应用,了解如何通过单调队列获得优化,注意队列中的删头,去尾,窗口操作。
滑动窗口/单调队列(洛谷P1886)
题目传送门: 滑动窗口 /【模板】单调队列
滑动窗口 /【模板】单调队列
题目描述
有一个长为 n n n 的序列 a a a,以及一个大小为 k k k 的窗口。现在这个从左边开始向右滑动,每次滑动一个单位,求出每次滑动后窗口中的最大值和最小值。
例如,对于序列 [ 1 , 3 , − 1 , − 3 , 5 , 3 , 6 , 7 ] [1,3,-1,-3,5,3,6,7] [1,3,−1,−3,5,3,6,7] 以及 k = 3 k = 3 k=3,有如下过程:
窗口位置 最小值 最大值 [1 3 -1] -3 5 3 6 7 − 1 3 1 [3 -1 -3] 5 3 6 7 − 3 3 1 3 [-1 -3 5] 3 6 7 − 3 5 1 3 -1 [-3 5 3] 6 7 − 3 5 1 3 -1 -3 [5 3 6] 7 3 6 1 3 -1 -3 5 [3 6 7] 3 7 \def\arraystretch{1.2} \begin{array}{|c|c|c|}\hline \textsf{窗口位置} & \textsf{最小值} & \textsf{最大值} \\ \hline \verb![1 3 -1] -3 5 3 6 7 ! & -1 & 3 \\ \hline \verb! 1 [3 -1 -3] 5 3 6 7 ! & -3 & 3 \\ \hline \verb! 1 3 [-1 -3 5] 3 6 7 ! & -3 & 5 \\ \hline \verb! 1 3 -1 [-3 5 3] 6 7 ! & -3 & 5 \\ \hline \verb! 1 3 -1 -3 [5 3 6] 7 ! & 3 & 6 \\ \hline \verb! 1 3 -1 -3 5 [3 6 7]! & 3 & 7 \\ \hline \end{array} 窗口位置[1 3 -1] -3 5 3 6 7 1 [3 -1 -3] 5 3 6 7 1 3 [-1 -3 5] 3 6 7 1 3 -1 [-3 5 3] 6 7 1 3 -1 -3 [5 3 6] 7 1 3 -1 -3 5 [3 6 7]最小值−1−3−3−333最大值335567
输入格式
输入一共有两行,第一行有两个正整数
n
,
k
n,k
n,k。
第二行
n
n
n 个整数,表示序列
a
a
a
输出格式
输出共两行,第一行为每次窗口滑动的最小值
第二行为每次窗口滑动的最大值
样例 #1
样例输入 #1
8 3
1 3 -1 -3 5 3 6 7
样例输出 #1
-1 -3 -3 -3 3 3
3 3 5 5 6 7
提示
【数据范围】
对于
50
%
50\%
50% 的数据,
1
≤
n
≤
1
0
5
1 \le n \le 10^5
1≤n≤105;
对于
100
%
100\%
100% 的数据,
1
≤
k
≤
n
≤
1
0
6
1\le k \le n \le 10^6
1≤k≤n≤106,
a
i
∈
[
−
2
31
,
2
31
)
a_i \in [-2^{31},2^{31})
ai∈[−231,231)。
这个题用暴力肯定是很容易想到的,从头到尾扫描,每次检查k个数,一共检查$O(nk)$次。暴力显然是会超时的,下面是用单调队列解决该题的思路,复杂度为$O(n)$。
在这个题中单调队列有如下特征
-
队头元素始终是队列中最小的。根据需要输出队头 但是不一定弹出
-
元素只能从头到尾进入队列 从队头 队尾都可以弹出
-
序列中的每个元素都必须进入队列,比如 x x x进入队尾时,和原队尾y比较,如果 x ≤ y x \le y x≤y就从队尾弹出 y y y,一值弹到队尾所有比x大的元素,最后x进入队尾,这个入队操作就保证了队头元素是队列中最小的。
我这样说可能有点抽象,举个实际点的例子。
- 到食堂打饭排队时大家都有一个心理,在打饭之前要看看有什么菜,如果不好吃就走了。不过,能不能看到和身高有关,站在队尾的人如果个子高,眼光就能越过前面的人看到里面的菜,如果个子矮,会被挡住看不见。
- 一个矮个子来排队,他希望队伍前面的人都比他更矮。如果他会魔法,他来排队时,队尾比他高的人就会自动从队尾离开,新的队尾如果仍然比他高,也会离开,最后新来的矮个子成了新的队尾,而且是最高的。他终于可以看到菜了,让人兴奋的是,菜很好吃,所以他肯定不想走。
- 假设每个新来的人的魔法本领都比队列中的人更厉害,这样队伍就会变成这样:每个新来的人都能排到队尾,但是都会被后来的矮个子赶走,这样一来,整个队伍会始终满足单调性,由队头到队尾,由矮到高。
- 但是,让这个魔法队伍郁闷的是,打饭阿姨一直忙自己的,顾不上打饭。所以排头的人等了一会就走了,等待时间就是题目中的 k k k。这里附带一个现象:队伍的长度不会超过 k k k。
- 输出是什么?每新来一个排队的人,排头如果还没走,他就向阿姨喊一声,这就是输出。
- 以上就是这个题的现实模型。
下面我们举例来描述一下该算法的流程,队列为
{
1
,
3
,
−
1
,
−
3
,
5
,
3
,
6
,
7
}
\{1, 3, -1, -3, 5, 3, 6, 7\}
{1,3,−1,−3,5,3,6,7},你们可以理解这些数字为身高,想象一下负的身高哈哈哈,便于理解啦。下表中的“输出队首”就是本题的结果。
元素进入队尾
元素进队顺序
队列
窗口范围
队首是否在窗口内
输出队首
弹出队尾
弹出队首
1
1
{
1
}
[
1
]
是
3
2
{
1
,
3
}
[
1
,
2
]
是
−
1
3
{
−
1
}
[
1
,
2
,
3
]
是
−
1
3
,
1
−
3
4
{
−
3
}
[
2
,
3
,
4
]
是
−
3
−
1
5
5
{
−
3
,
5
}
[
3
,
4
,
5
]
是
−
3
3
6
{
−
3
,
3
}
[
4
,
5
,
6
]
是
−
3
5
6
7
{
3
,
6
}
[
5
,
6
,
7
]
−
3
否,
3
是
3
−
3
7
8
{
3
,
6
,
7
}
[
6
,
7
,
8
]
是
3
\def\arraystretch{1.2} \begin{array}{|c|c|c|c|c|c|c|c|}\hline \textsf{元素进入队尾} & \textsf{元素进队顺序} & \textsf{队列} & \textsf{窗口范围}& \textsf{队首是否在窗口内}& \textsf{输出队首}& \textsf{弹出队尾}& \textsf{弹出队首}\\ \hline 1& 1& \{1\} & \ [1 \ ]& 是 & & & \\ \hline 3& 2& \{1, 3\} & \ [1, 2 \ ]& 是 & & &\\ \hline -1& 3& \{-1\} & \ [1, 2,3 \ ]& 是 &-1 &3,1 &\\ \hline -3& 4& \{-3\} & \ [2,3,4\ ]& 是 &-3 &-1 &\\ \hline 5& 5& \{-3, 5\} & \ [3,4,5 \ ]& 是 & -3& &\\ \hline 3& 6& \{-3, 3\} & \ [4,5,6\ ]& 是 & -3& 5 &\\ \hline 6& 7& \{3, 6\} & \ [5,6,7 \ ]& -3否,3是 & 3 & &-3\\ \hline 7& 8& \{3, 6, 7\} & \ [6,7,8 \ ]& 是 & 3& &\\ \hline \end{array}
元素进入队尾13−1−35367元素进队顺序12345678队列{1}{1,3}{−1}{−3}{−3,5}{−3,3}{3,6}{3,6,7}窗口范围 [1 ] [1,2 ] [1,2,3 ] [2,3,4 ] [3,4,5 ] [4,5,6 ] [5,6,7 ] [6,7,8 ]队首是否在窗口内是是是是是是−3否,3是是输出队首−1−3−3−333弹出队尾3,1−15弹出队首−3
下面是这个题的具体实现代码
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 1e6 + 5;
int a[N];
deque<int> q;
void solve() {
int n, k; cin >> n >> k;
for (int i = 1; i <= n; ++i) {
cin >> a[i];
}
for (int i = 1; i <= n; ++i) {
while (!q.empty() && a[q.back()] > a[i]) q.pop_back(); // 去尾
q.push_back(i);
if (i >= k) { // 每个窗口输出一次
while (!q.empty() && q.front() <= i - k) q.pop_front(); // 删头
cout << a[q.front()] << " ";
}
}
cout << "\n";
while (!q.empty()) q.pop_back(); // 清空队列 输出最大值
for (int i = 1; i <= n; ++i) {
while (!q.empty() && a[q.back()] < a[i]) q.pop_back(); // 去尾
q.push_back(i);
if (i >= k) { // 每个窗口输出一次
while (!q.empty() && q.front() <= i - k) q.pop_front(); // 删头
cout << a[q.front()] << " ";
}
}
cout << "\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int tt = 1; // cin >> tt;
while (tt--) {
solve();
}
return 0;
}
单调队列与最大子序和问题
下面再介绍一下单调队列的典型应用–最大子序和问题
子序和:在给定长度为n的整数序列A,它的子序列定义为A中非空的一段连续的元素,例如序列(6, -1, 5, 4, -7)前4个子序和为6 + -1 + 5 + 4 = 14
最大子序和问题按子序列有无长度限制为两种
- 问题一,不限制子序列的长度,在所有可能的子序列中找到一个子序列,该子序列和最大。
- 问题二,限制了子序列的长度m,找出一段长度不超过m的连续子序列,使得它的子序和最大。
问题一比较easy,可以用贪心或者DP做,复杂度都是 O ( n ) O(n) O(n)
问题二用单调队列,复杂度也是 O ( n ) O(n) O(n)。通过这个例子,我想你应该会明白为什么单调队列能用于DP优化
问题一不是本节要写的,不过也可以先给出来作为对比,后面我会写DP专题。
用贪心或者DP, O ( n ) O(n) O(n)时间内解决,下面是这个题
问题一 Max Sum(hdu 1003)
传送门: hdu1003
中文题意
给定一个序列,求最大的子序和。
INPUT: 第一行输入整数T,表示测试用例的个数
T
∈
[
1
,
20
]
T \in[1, 20]
T∈[1,20],每行第一个数输入
N
N
N,后面输入
N
N
N个数,
N
∈
[
1
,
100000
]
N \in [1, 100000]
N∈[1,100000],每个数在
[
−
1000
,
1000
]
[-1000, 1000]
[−1000,1000]区间内
OUTPUT: 每个测试输出两行。第一行是"Case #:“其中”#"表示测试序号
第二行输出三个数,第一个数表示最大子序和,第二个和第三个是开始和终止位置。两个测试用例之间输出一个空行。
贪心
思路: 逐个扫描序列中的元素并累加,加上一个正数时,子序和会增加,加负数会减小。如果当前得到的和变成了负数,这个负数在接下来的累加中会减少后面的求和,所以不取它,从下一个位置重新开始求和。
代码
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
void solve() {
int t; cin >> t;
for (int tt = 1; tt <= t; ++tt) {
int n; cin >> n;
int maxsum = INT_MIN;
int l = 1, r = 1, p = 1; // 起点 终点 扫描位置
int sum = 0; // 子序和
for (int i = 1; i <= n; ++i) {
int x; cin >> x;
sum += x;
if (sum > maxsum) {
maxsum = sum;
l = p;
r = i;
}
if (sum < 0) {
// 扫描到i时,若前面的最大子序和是负数 从下一个数开始求和
sum = 0;
p = i + 1;
}
}
printf("Case %d:\n", tt);
printf("%d %d %d\n", maxsum, l, r);
if (tt != t) printf("\n");
}
}
int main() {
//ios::sync_with_stdio(false);
// cin.tie(nullptr);
int tt = 1; // cin >> tt;
while (tt--) {
solve();
}
return 0;
}
动态规划做法
定义状态dp[i]表示以a[i]为结尾的最大子序和。转移有两种情况
dp[i]只包括一个情况 就是a[i]
dp[i]包括多个元素,从前面某个a[v]开始, v < i, 到a[i]结束
dp[i] = max(dp[i - 1] + a[i], a[i])
代码
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
int dp[100005];
void solve() {
int t; cin >> t;
for (int tt = 1; tt <= t; ++tt) {
int n; cin >> n;
for (int i = 1; i <= n; ++i) {
cin >> dp[i];
}
int l = 1, r = 1, p = 1;
int maxsum = dp[1];
for (int i = 2; i <= n; ++i) {
if (dp[i - 1] + dp[i] >= dp[i])
dp[i] = dp[i - 1] + dp[i];
else p = i;
if (dp[i] > maxsum) {
maxsum = dp[i];
l = p;
r = i;
}
}
printf("Case %d:\n", tt);
printf("%d %d %d\n", maxsum, l, r);
if (tt != t) printf("\n");
}
}
int main() {
//ios::sync_with_stdio(false);
// cin.tie(nullptr);
int tt = 1; // cin >> tt;
while (tt--) {
solve();
}
return 0;
}
问题二的求解
这个要用到前缀和,还是先普及一下前缀和这个知识吧。
顾名思义前缀和sum[i]表示数组a第一个元素到第i个元素的和
即sum[i] = a[1] + a[2] + … + a[i]
利用递推可以
O
(
n
)
O(n)
O(n)时间复杂度求前缀和
sum[i] = sum[i - 1] + a[i]
ok下面进入正题
和前面例题的"滑动窗口"类似,可以利用单调队列的“窗口,删头,去尾”解决问题二
首先求前缀和s[i],问题转换为找出两个位置l, r使得s[r]-s[l]最大,r-l<=m(m是限制的最大子序列的长度)
首先考虑用DP来求解,把问题进一步转化为:首先固定一个l,找到它左边的一个端点r,r-l<=m,使得s[r] - s[l]最大 定义这个最大值是dp[l],逐渐扩大l,求得所有的dp[l],其中的最大值就是该问题的解。
如果简单地暴力,对每个i检查比它小的m个s[k],那么总时间复杂度为
O
(
n
m
)
O(nm)
O(nm),这是会TLE(超时)的。
暴力的方法不可行,那么我们可以改用一个大小为m的窗口寻找最大子序和ans。从头到尾依次把s的元素放入这个窗口。
- 首先把s[1]放入窗口,并且记录ans的初始值s[1]
- 接着把s[2]放入窗口(假设窗口长度大于2),有两种情况,如果 s [ 1 ] ≤ s [ 2 ] s[1] \le s[2] s[1]≤s[2],那么更新 a n s = m a x { s [ 1 ] , s [ 2 ] , s [ 2 ] − s [ 1 ] } ans = max\{s[1], s[2],s[2]-s[1]\} ans=max{s[1],s[2],s[2]−s[1]},如果 s [ 1 ] > s [ 2 ] s[1] >s[2] s[1]>s[2],那么保持 a n s = s [ 1 ] ans=s[1] ans=s[1]不变,从队列中弹出 s [ 1 ] s[1] s[1],只留下 s [ 2 ] s[2] s[2],类似于上面那个打饭的例子,前面比他高的就要出队,这是因为后面如果再将新的 s [ k ] s[k] s[k]放入窗口时, s [ k ] − s [ 2 ] s[k]-s[2] s[k]−s[2]比 s [ k ] − s [ 1 ] s[k]-s[1] s[k]−s[1]更大,这样就不满足单调性了。
- 继续这个过程,直到所有的 s s s处理结束
总结上面的思路,把新的 s [ i ] s[i] s[i]放入窗口时:
- 把窗口内比 s [ i ] s[i] s[i]大的所有 s [ j ] s[j] s[j]都出队, i − j ≤ m i-j\le m i−j≤m,因为这些 s [ j ] s[j] s[j]在处理 s [ i ] s[i] s[i]后面的 s [ k ] s[k] s[k]时用不到了, s [ k ] − s [ i ] s[k]-s[i] s[k]−s[i]优于 s [ k ] − s [ j ] s[k]-s[j] s[k]−s[j],于是保留 s [ i ] s[i] s[i]就可以了。
- 若窗口内最小的是 s [ k ] s[k] s[k],此时肯定有 s [ k ] ≤ s [ i ] s[k]\le s[i] s[k]≤s[i],检查 s [ i ] − s [ k ] s[i]-s[k] s[i]−s[k]是否为当前的最大子序和,若是,就更新 a n s ans ans。
- 每个 s [ i ] s[i] s[i]都会进入队列
此时最优的策略是一个“位置递增,前缀和也递增”的序列,用单调队列是最合适的。 s [ i ] s[i] s[i]进入队尾时,如果原队尾比 s [ i ] s[i] s[i]大,则去尾;如果队头超过窗口范围 m m m,则删头,而最小的 s [ k ] s[k] s[k]就是队头。该做法的原理和“滑动窗口”这个题差不多。在这个单调队列中,每个 s [ i ] s[i] s[i]只进出队列一次,时间复杂度为 O ( n ) O(n) O(n)。
c++代码如下所示
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
deque<int> dq;
ll s[100005], a[100005]; //前缀和数组
void solve() {
int n, m;
cin >> n >> m;
for (int i = 1; i <= m; ++i) {
cin >> a[i];
s[i] = s[i - 1] + a[i];
}
int ans = -1e8;
dq.push_back(0);
for (int i = 1; i <= n; ++i) {
while (!dq.empty() && dq.front() < i - m) dq.pop_front(); //队头超过m范围,删头
if (dq.empty()) ans = max(ans, s[i]);
else ans = max(ans, s[i] - s[dq.front()]); // 队头就是最小的s[k]
while (!dq.empty() && s[dq.back()] >= s[i]) dq.pop_back(); // 队尾大于s[i] 去尾
dq.push_back(i);
}
cout << ans << "\n";
}
int main() {
//ios::sync_with_stdio(false);
// cin.tie(nullptr);
int tt = 1; // cin >> tt;
while (tt--) {
solve();
}
return 0;
}
在这个题中,用到了DP+单调队列,关于单调队列优化DP后面我会写个专题慢慢说。
优先队列
优先队列的特点是每次让优先级最高的先出队,优先队列的底层实现是堆这种数据结构,代码写起来复杂点,所以一般都不手写,而是使用STL中的priority_queu来实现,下面介绍一下使用。
STL priority_queue
priority_queue 是 C++ 标准模板库(STL)中的一个容器适配器,用于管理元素的优先级。它通常实现为一个堆(heap),默认情况下是一个最大堆,即最大的元素位于顶部。你可以通过自定义比较器将其转换为最小堆或实现其他优先级策略。
下面是 priority_queue 的详细使用指南,包括基本操作、不同的底层容器、如何自定义比较器等内容。
基本介绍
1. 定义
#include <queue>
#include <vector>
#include <functional>
2. 基本操作
构造函数:创建一个空的优先队列或从其他容器复制。push(const T& value):向队列中添加元素。pop():移除队列顶部的元素。top():访问队列顶部的元素。empty()检查队列是否为空。size():返回队列中元素的数量。
3.创建最大堆(默认)
默认情况下,priority_queue 是一个最大堆,最大的元素位于顶部。
#include <iostream>
#include <queue>
#include <vector>
int main() {
std::priority_queue<int> pq;
// 插入元素
pq.push(10);
pq.push(30);
pq.push(20);
pq.push(5);
pq.push(1);
// 输出并移除元素
while (!pq.empty()) {
std::cout << pq.top() << " "; // 输出最大元素
pq.pop();
}
// 输出: 30 20 10 5 1
return 0;
}
4. 创建最小堆
要创建一个最小堆,可以使用 std::greater 作为比较器。
#include <iostream>
#include <queue>
#include <vector>
#include <functional>
int main() {
// 最小堆
std::priority_queue<int, std::vector<int>, std::greater<int>> pq;
pq.push(10);
pq.push(30);
pq.push(20);
pq.push(5);
pq.push(1);
while (!pq.empty()) {
std::cout << pq.top() << " "; // 输出最小元素
pq.pop();
}
// 输出: 1 5 10 20 30
return 0;
}
5. 自定义比较器为最小堆
假设你有一个自定义的 struct,例如学生结构体,你希望根据成绩来排序。
#include <iostream>
#include <queue>
#include <vector>
#include <string>
// 定义学生结构体
struct Student {
std::string name;
int score;
// 构造函数
Student(const std::string& n, int s) : name(n), score(s) {}
};
// 自定义比较器(最大堆,根据成绩排序)
struct CompareStudent {
bool operator()(const Student& a, const Student& b) {
// 如果 a 的成绩小于 b,则 a 在 b 之后
return a.score < b.score;
}
};
int main() {
// 使用自定义比较器
std::priority_queue<Student, std::vector<Student>, CompareStudent> pq;
pq.emplace("Alice", 85);
pq.emplace("Bob", 95);
pq.emplace("Charlie", 75);
pq.emplace("Diana", 90);
while (!pq.empty()) {
Student top = pq.top();
std::cout << top.name << ": " << top.score << "\n";
pq.pop();
}
// 输出:
// Bob: 95
// Diana: 90
// Alice: 85
// Charlie: 75
return 0;
}
6. 自定义比较器为最小堆
#include <iostream>
#include <queue>
#include <vector>
#include <string>
struct Student {
std::string name;
int score;
Student(const std::string& n, int s) : name(n), score(s) {}
};
// 自定义比较器(最小堆,根据成绩排序)
struct CompareStudentMinHeap {
bool operator()(const Student& a, const Student& b) {
// 如果 a 的成绩大于 b,则 a 在 b 之后
return a.score > b.score;
}
};
int main() {
// 最小堆
std::priority_queue<Student, std::vector<Student>, CompareStudentMinHeap> pq;
pq.emplace("Alice", 85);
pq.emplace("Bob", 95);
pq.emplace("Charlie", 75);
pq.emplace("Diana", 90);
while (!pq.empty()) {
Student top = pq.top();
std::cout << top.name << ": " << top.score << "\n";
pq.pop();
}
// 输出:
// Charlie: 75
// Alice: 85
// Diana: 90
// Bob: 95
return 0;
}
7. 使用 Lambda 表达式作为比较器
自 C++11 起,可以使用 Lambda 表达式作为比较器,配合 std::function·或其他方式。不过,由于 priority_queue 需要比较器类型在编译时已知,因此直接在模板参数中使用 Lambda 是不太方便的。一个常见的解决方案是使用 std::vector 和 std::make_heap 等函数,或定义一个单独的比较器结构。
不过,如果你仍然希望使用 Lambda,可以使用std::function,但这可能带来性能开销。
#include <iostream>
#include <queue>
#include <vector>
#include <functional>
#include <string>
struct Student {
std::string name;
int score;
Student(const std::string& n, int s) : name(n), score(s) {}
};
int main() {
// 使用 std::function 包装 Lambda
auto cmp = [](const Student& a, const Student& b) -> bool {
return a.score < b.score; // 最大堆
};
std::priority_queue<Student, std::vector<Student>, decltype(cmp)> pq(cmp);
pq.emplace("Alice", 85);
pq.emplace("Bob", 95);
pq.emplace("Charlie", 75);
pq.emplace("Diana", 90);
while (!pq.empty()) {
Student top = pq.top();
std::cout << top.name << ": " << top.score << "\n";
pq.pop();
}
// 输出:
// Bob: 95
// Diana: 90
// Alice: 85
// Charlie: 75
return 0;
}
常见用法
- 优先级调度:任务调度系统中,可以根据任务的优先级执行任务。
- 图算法:如 Dijkstra 算法中,用于选择当前最短路径的节点。
- 合并多个有序序列:例如,合并 K 个有序链表。
- 实时数据流的 Top K 问题:维护实时数据流中的前 K 大元素。
注意事项 - 效率:priority_queue 的插入和删除操作的时间复杂度为 O ( l o g n ) O(log n) O(logn)。
- 访问限制:priority_queue 仅允许访问顶部元素,不支持随机访问或遍历。
- 底层容器:默认使用
std::vector,但也可以使用其他容器,如std::deque,前提是满足RandomAccessIterator要求。
7. 完整示例
以下是一个综合示例,展示如何使用 priority_queue 进行任务调度,根据任务优先级执行任务
#include <iostream>
#include <queue>
#include <vector>
#include <string>
// 定义任务结构体
struct Task {
std::string name;
int priority;
Task(const std::string& n, int p) : name(n), priority(p) {}
};
// 自定义比较器(优先级高的任务先执行)
struct CompareTask {
bool operator()(const Task& a, const Task& b) {
// 如果 a 的优先级低于 b,则 a 在 b 之后
return a.priority < b.priority;
}
};
int main() {
// 创建优先队列
std::priority_queue<Task, std::vector<Task>, CompareTask> taskQueue;
// 添加任务
taskQueue.emplace("Task1", 3);
taskQueue.emplace("Task2", 1);
taskQueue.emplace("Task3", 4);
taskQueue.emplace("Task4", 2);
// 执行任务
while (!taskQueue.empty()) {
Task current = taskQueue.top();
std::cout << "Executing " << current.name << " with priority " << current.priority << "\n";
taskQueue.pop();
}
// 输出:
// Executing Task3 with priority 4
// Executing Task1 with priority 3
// Executing Task4 with priority 2
// Executing Task2 with priority 1
return 0;
}


















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











