






分布式文件系统,解决了海量数据无法单台机器存储的问题,将海量的数据存储在不同的机器中 ,由HDFS文件系统统一管理和维护, 提供统一的访问目录和API
原理简介
存储原理
环境
- java环境
- 集群中的每台机器的ip
- 主机名
- 域名映射
- 关闭防火墙
- 时间同步
- ssh免密
步骤
- 上传
- 解压
- 配置
- 分发
- 初始化
- 启动
安装过程
rz 命令上传 将hadoop-3.1.1.tar.gz 上传到/opt/apps
cd /opt/apps
rz 上传
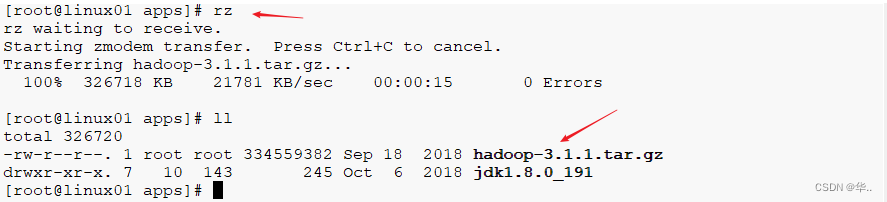
解压
tar -zxvf hadoop-3.1.1.tar.gz
删除文档 rm -rf /opt/apps/hadoop-3.1.1/share/doc
配置
配置JavaHome
/opt/apps/hadoop-3.1.1/etc/hadoop/hadoop-env.sh
vi /opt/apps/hadoop-3.1.1/etc/hadoop/hadoop-env.sh
shift + G 最后一行 o 下一行插入
export JAVA_HOME=/opt/apps/jdk1.8.0_191配置namenode
/opt/apps/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
vi hdfs-site.xml
将复制的内容粘贴到<configuration></configuration>标签中
注意 先进入到插入模式 按i 再粘贴
<!-- 集群的namenode的位置 datanode能通过这个地址注册-->
<property>
<name>dfs.namenode.rpc-address</name>
<value>linux01:8020</value>
</property>
<!-- namenode存储元数据的位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hdpdata/name</value>
</property>
<!-- datanode存储数据的位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hdpdata/data</value>
</property>
<!-- secondary namenode机器的位置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>linux02:50090</value>
</property>分发安装包
进入到apps文件夹中
cd /opt/apps
将hadoop文件远程复制linux02 linux03
scp -r hadoop-3.1.1 linux02:$PWD
scp -r hadoop-3.1.1 linux03:$PWD初始化
进入到hadoop的bin文件夹下 进行初始化 linux01
./hadoop namenode -format
初始化后 opt下会多出一个文件夹hdpdata
启动
单节点启动
先启动namenode
进入到hadoop的sbin目录下 linux01
./hadoop-daemon.sh start namenode 单个启动namenode
启动成功后可以访问页面
http://linux01:9870启动datanode
进入到hadoop的sbin目录下 linux01 linux02 linux03
./hadoop-daemon.sh start datanode 一键启停
为了方便今后启动我们将sbin目录配置到环境变量中
vi /etc/profile
export JAVA_HOME=/opt/apps/jdk1.8.0_191
export HADOOP_HOME=/opt/apps/hadoop-3.1.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存后
source /etc/profile
配置集群文件 hadoop的etc/hadoop/目录下workers 告知有哪些机器
vi workers
linux01
linux02
linux03
修改hadoop的sbin下的 start-dfs.sh stop-dfs.sh
vi start-dfs.sh
在第一行后插入
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vi stop-dfs.sh
在第一行后插入
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置后 可以在任意目录下
stop-dfs.sh 停止
start-dfs.sh 启动














 1794
1794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









