






[新手小白刚接触深度学习&时序网络,试着上手跑一跑Informer,以下一切都是我在学习其他作者文章后的个人理解,求大佬指正!!!--虚心的研一orz]
论文指路→[2012.07436] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (arxiv.org)
源码指路→
[2012.07436] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (arxiv.org)
有很多作者大大给出了Informer网络创新点&与原始Transformer的对比,我要去补课了555
调试环节我学习了以下作者大大的文章:
时间序列预测实战(十九)魔改Informer模型进行滚动长期预测(科研版本,结果可视化)-CSDN博客
-----------------------------------------------------------分割线------------------------------------------------------------[24/04/29]
[前言:这篇博客可能是我对Informer实战的最后一篇,因为今天组会和老师汇报了Informer的相关内容,但是Informer网络目前不太符合我研究方向所需要的网络条件...我导让我另谋网络啦,但是我还是决定把我最近学习的内容分享出来]
-----------------------------------------------------------分割线------------------------------------------------------------
一、结果可视化
接我上一篇关于Informer学习的博客,当给网络输入模型和数据集后,网络开始运行[指路链接]Informer长时序预测网络(1.环境配置&按例跑网络)--小白粥学习笔记-CSDN博客]
1、如果想要输出预测结果,需要在[main_informer.py]中将“do_predict”改为:
parser.add_argument('--do_predict', action='store_false',help='whether to predict unseen future data')网络运行结束后会将权重结果存放在“checkpoints”文件夹下,将网络结果存放在“results/setting(你网络的setting数据)”文件夹下。脚本中是以下代码表示:

文件夹内容如图:
输出的结果表示为.npy文件,即用numpy存储的文件,如何可视化呢?
2、新建脚本“results”,脚本思路很简单,想要把真实值和预测值放在一张图,看看预测结果和真实值的差距,因为是.npy文件因此思路是:load npy文件—绘图。
[以下参考了别的博主]为了让结果更好观察,可以添加标签和输出他们的维度,方便改网络。完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
folder = 'informer_ETTh1_ftM_sl96_ll48_pl23_dm512_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_0'
pred = np.load('./results/'+folder+'/pred.npy')
true = np.load('./results/'+folder+'/true.npy')
print(pred.shape)
print(true.shape)
plt.figure(1)
plt.plot(true[0,:,-1], label='GroundTruth')
plt.plot(pred[0,:,-1], label='Prediction')
plt.legend()
plt.show()
real_pred=np.load('./results/'+folder+'/real_prediction.npy')
print(real_pred.shape)
plt.figure()
plt.plot(real_pred[0,:,-1],label='real_prediction')
plt.legend()
plt.show()输出结果如下(我更改了epoch、pred_len等节省时间+方便观察,所以结果可能不太一样,但是思路差不多):
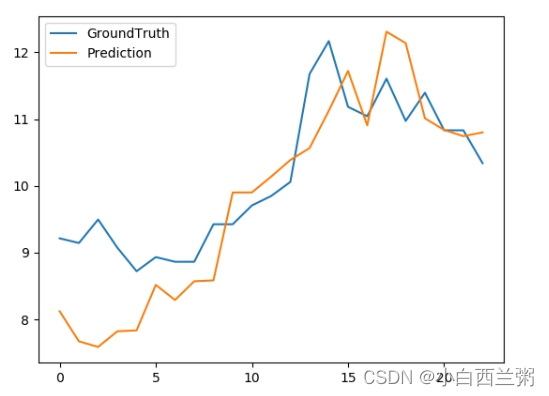
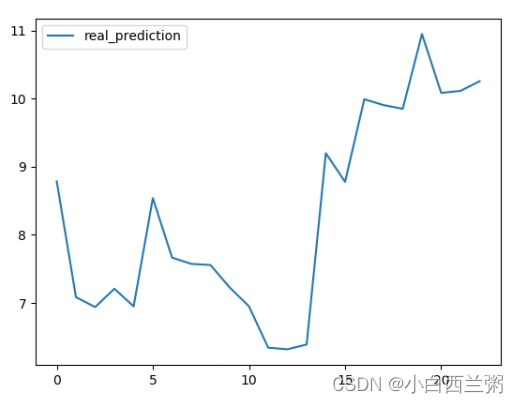

第一张图是真实值和预测值的比较,第二张图是未来的预测,第三张图是我输出的三个量的维度,其中我把“pred_len”改成23,也就是只输出了未来的23个值(根据需求更改)。
二、更改自己的数据集
这个问题我学了好几天,总结了几个我认为可以直接上手改的地方。
1、--data
首先肯定是你自己数据集的地址需要修改,如果嫌麻烦可以放在ETT下,但得是csv格式,红框里的需要适当修改

2、--feature
其次需要更改你数据集的预测种类“--feature”,到底是属于M,还是MS,还是S,就看你预测的方法,是多测多还是其他的。
3、--target
这个target是你csv文件里标签的那一列的名称,ETT的数据集标签都是“OT”,自定义修改(注:自己数据集时间那列的标签得是data,不然得去脚本里改)
4、--freq
源码中说的很清楚,就是你data中相隔的时间,直接改default,如果是相隔一天就是d,其他同理,但是也可以15min或者3h,但是间隔得相同!!
5、各种len长度
我觉得没什么太大必要改,就看你数据集大小和你想要预测未来的天数自定义更改,如果数据集笑,seq_len可以适当调小一些
6、enc_in/dec_in/c_out
这些默认为7,是因为ETTh1数据集除了日期那一列有7列(特征点+标签),根据你自己数据集定,但是要相同
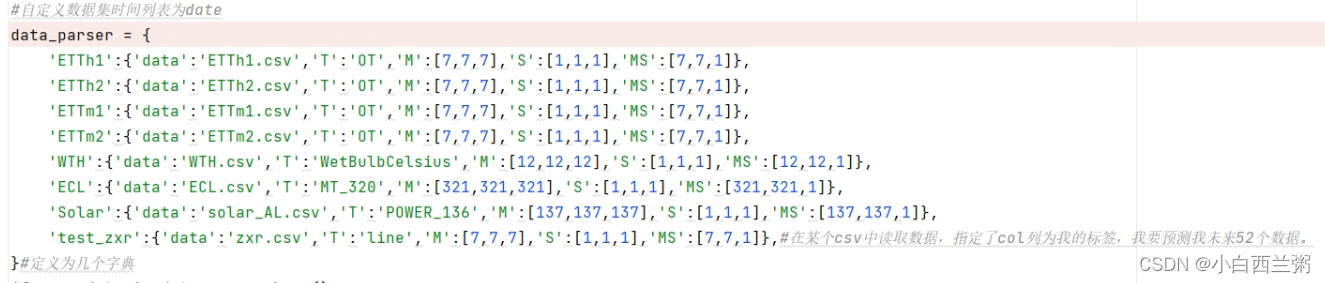
7、data_parser字典
需要增加自己数据集的字典信息,比如我这里把我的数据集名称为“test_zxr”,我的csv文件为“zxr.csv”(与上面--data对应),输出列名为“line”
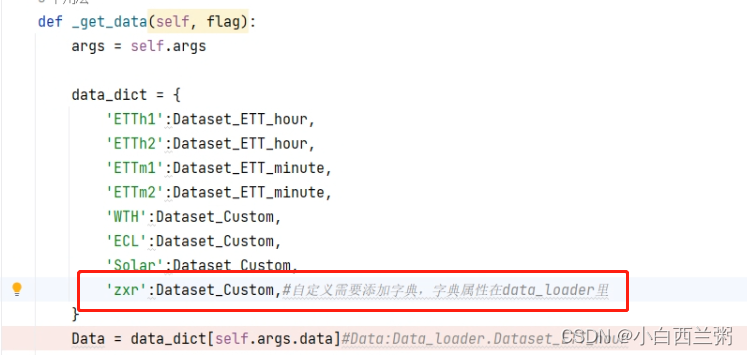
8、 在get_data中需要给字典data_dict加入自己数据集的信息,这里后面的字典属性要对应data_loader里,在里面看看你的数据集适合哪种方法,不然就自己写一个
以上就是我学习的进度,改自己数据集应该还有一些需要更改的代码内容,欢迎补充~















 2415
2415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









