








注意这里的一号仓入口

船长让妇女儿童先上船,但先上船的妇女儿童都是头等舱的。


一.数据探索
我们首先导入数据
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
train_df = pd.read_csv(r'C:\Users\dahuo\Desktop\数据集2\train.csv')
print(train_df.columns)
PassengerId => 乘客ID
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
数据特征分为:连续值和离散值
-
离散值:性别(男,女) 登船地点(S,Q,C)船舱等级(1,2,3)
-
连续值:年龄,船票价格
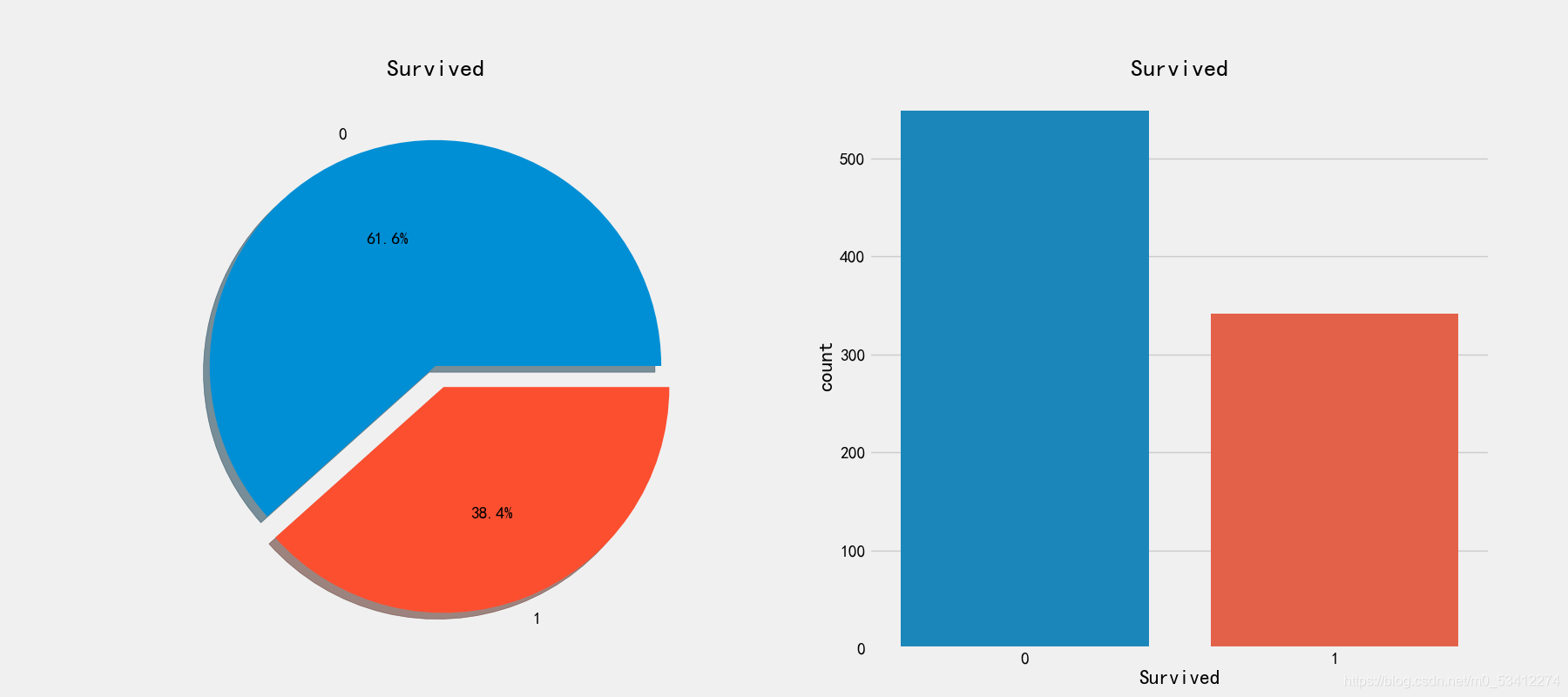
接着我们来看看人员生存情况
# 查看生存比例
fig,axes = plt.subplots(1,2,figsize=(18,8))
train_df['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=axes[0],shadow=True)
axes[0].set_title('Survived')
axes[0].set_ylabel(' ')
sns.countplot('Survived',data=train_df,ax=axes[1])
axes[1].set_title('Survived')
这里只是训练集的数据
探索离散特征
单特征
整个船上当中只有38.4%的人员存活了下来,接下来查看各个属性和留存的关系吧!
# 性别和生存率的关系
fig,axes = plt.subplots(1,2,figsize=(18,8))
train_df[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=axes[0])
axes[0].set_title('Survived vs Sex')
sns.countplot('Sex',hue='Survived',data=train_df,ax=axes[1])
axes[1].set_title('Sex:Survived vs Dead')
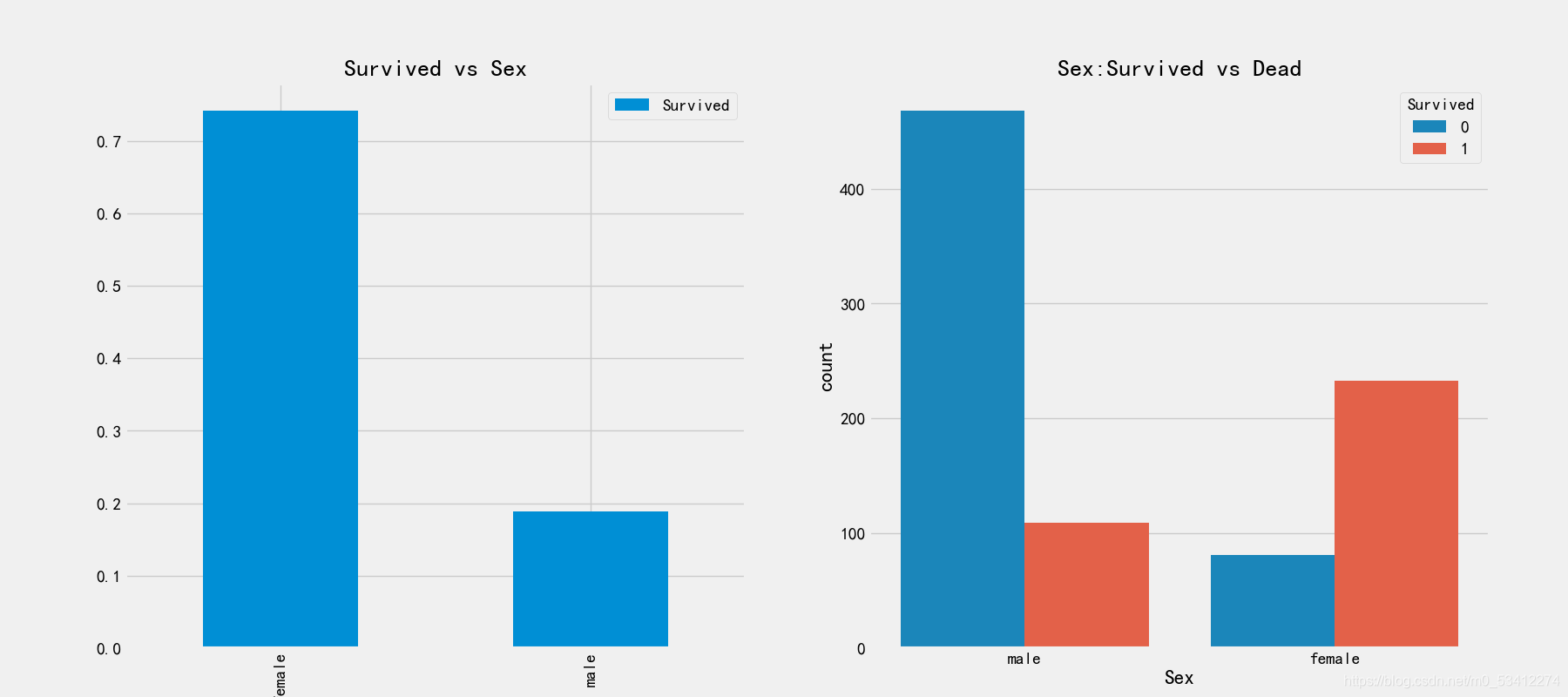
从第一张图可以看出来,女性的获救比例在75%,而男性还不足20% 从右图,又可以观察出来,船上男性的数量比女性多的多,但是存活率却很低 这是一个很有区分度的特征,必须使用
接下来我们看看船舱等级和生存率的关系
# 船舱等级和生存率的关系
print(pd.crosstab(train_df['Pclass'],train_df['Survived'],margins=True).style.background_gradient(cmap='summer_r'))
# 船舱等级和生存率的关系
fig,axes = plt.subplots(1,2,figsize=(18,8))
train_df['Pclass'].value_counts().plot.bar(ax=axes[0])
axes[0].set_title('Number Of Passengers By Pclass')
axes[0].set_ylabel('Count')
sns.countplot('Pclass',hue='Survived',data=train_df,ax=axes[1])
axes[1].set_title('Pclass:Survived vs Dead')
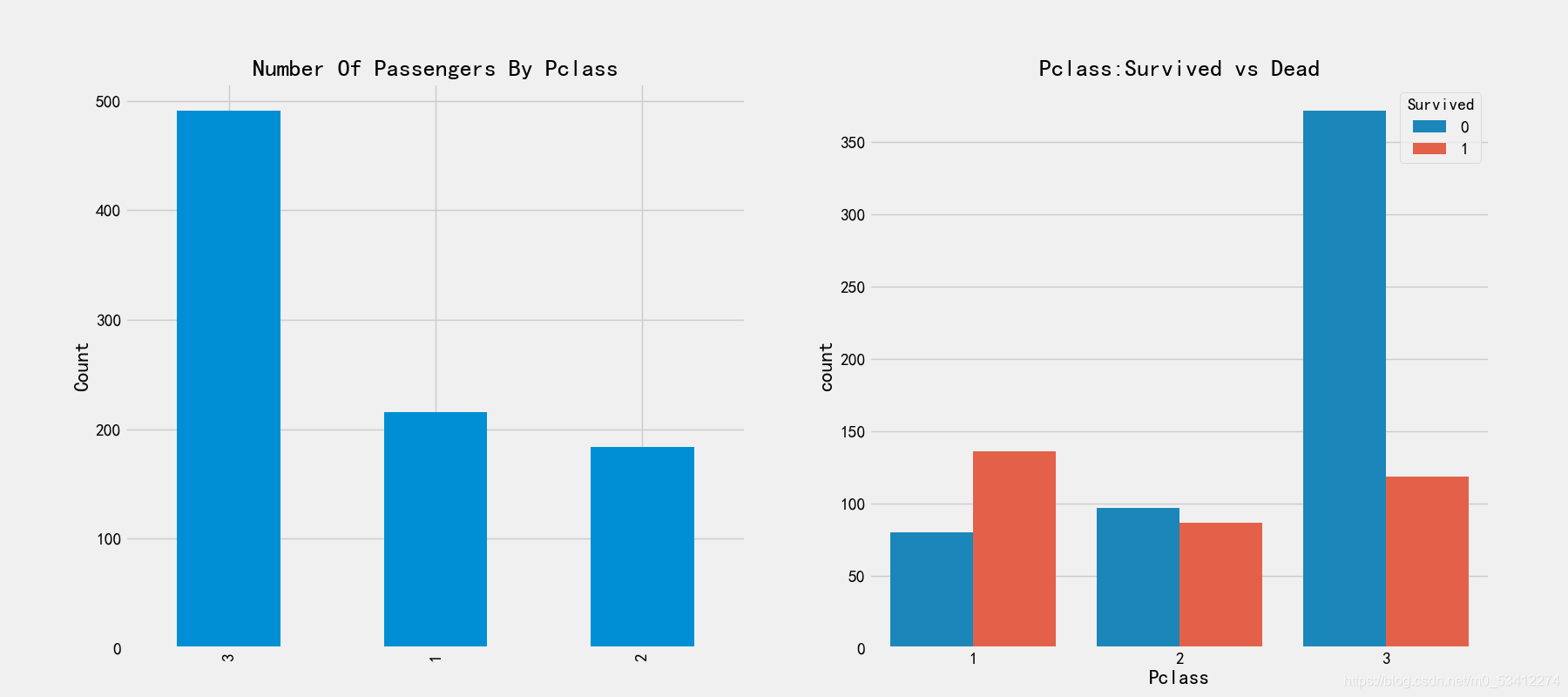
由左图可知,船舱登记为3的乘客最低,但是在右图中对应的存活率却是很低的,船舱登记为1和2的存活率较高,我们可以分析出,1,2船舱的乘客级别高,富有,被救援的机会大。
# 登陆港口和生存率的关系
fig,axes = plt.subplots(1,2,figsize=(18,8))
train_df['Embarked'].value_counts().plot.bar(ax=axes[0])
axes[0].set_title('Number Of Passengers By Embarked')
axes[0].set_ylabel('Count')
sns.countplot('Embarked',hue='Survived',data=train_df,ax=axes[1])
axes[1].set_title('Embarked:Survived vs Dead')
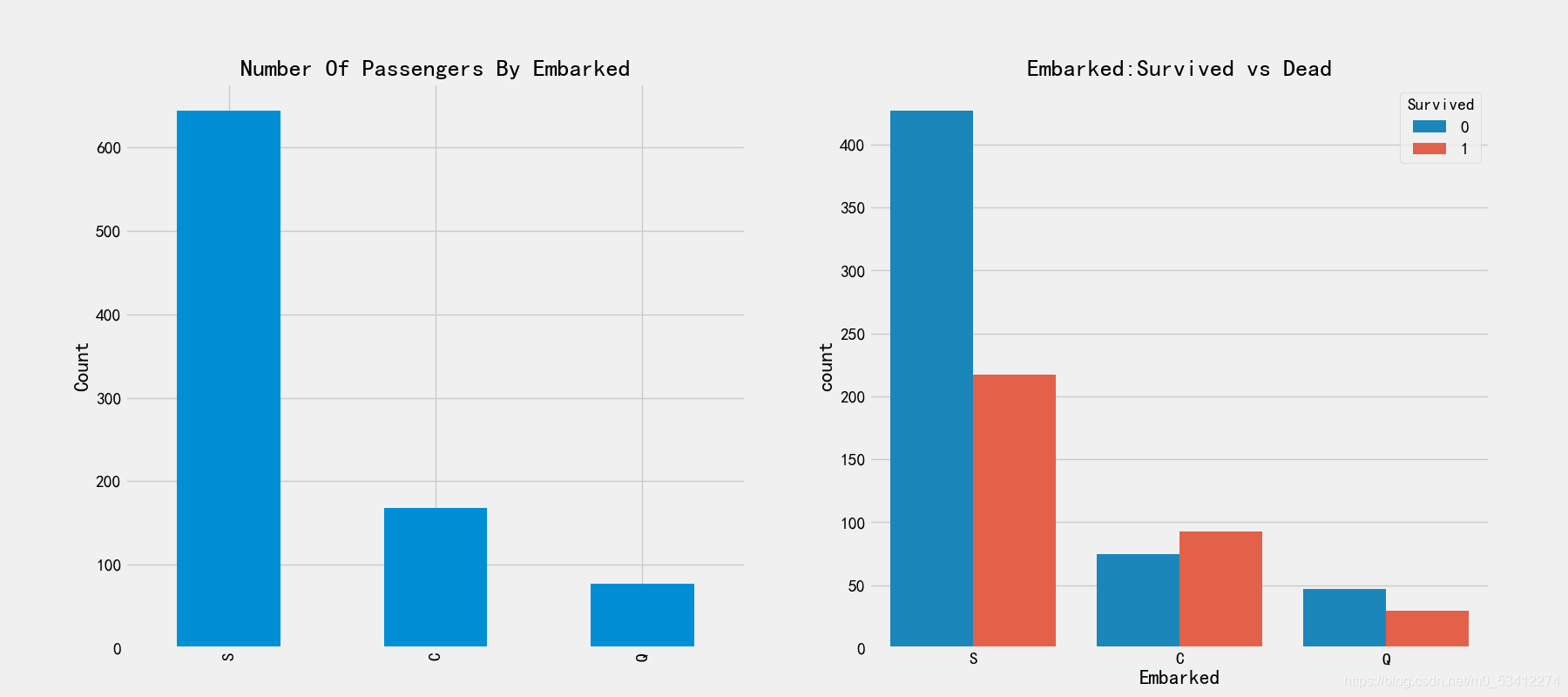
S、Q没有明显差别,S的登船人数最多。C登船港口有明显的区别,登船人数最少,且获救比例高于50%,我们暂时先记住这个特征。
我们现在来看看登船港口和性别与生存率情况
sns.barplot('Pclass','Survived',hue='Sex',data=train_df)
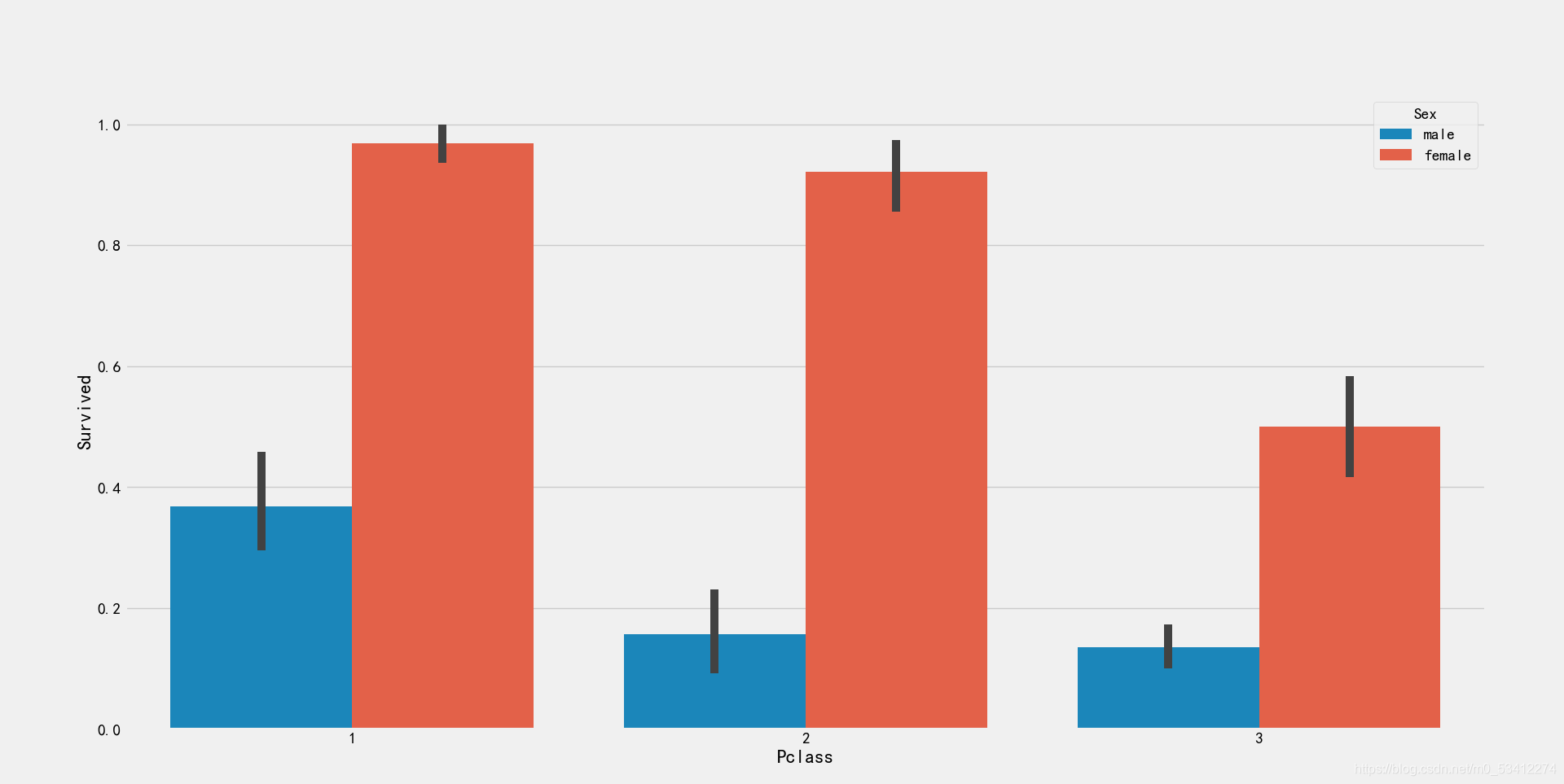
1港口的存活比例是比较高的,这与之前的分析是一致的,3港口的男性存活率最低,大概只有15%左右
登船港口和船舱等级与生存率
sns.factorplot('Pclass','Survived',hue='Sex',col='Embarked',data=train_df)
plt.show()
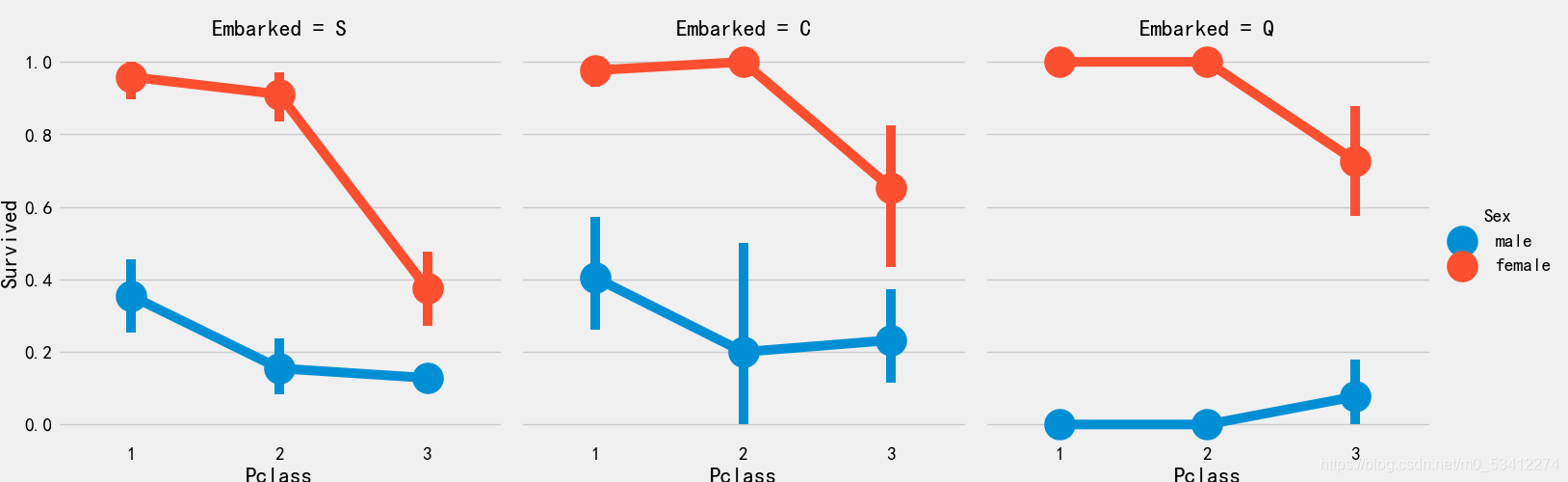
探索连续特征
# 年龄
print('Oldest Passenger was of:',train_df['Age'].max(),'Years')
print('Youngest Passenger was of:',train_df['Age'].min(),'Years')
print('Average Age on the ship:',train_df['Age'].mean(),'Years')
Oldest Passenger was of: 80.0 Years
Youngest Passenger was of: 0.42 Years
Average Age on the ship: 29.69911764705882 Years
# 绘图可视化年龄、船舱等级、性别对生存的影响和关系
fig,axes = plt.subplots(1,3,figsize=(18,8))
sns.violinplot('Pclass','Age',hue='Survived',data=train_df,split=True,ax=axes[0])
axes[0].set_title('Pclass and Age vs Survived')
axes[0].set_yticks(range(0,110,10))
sns.violinplot("Sex","Age", hue="Survived", data=train_df,split=True,ax=axes[1])
axes[1].set_title('Sex and Age vs Survived')
axes[1].set_yticks(range(0,110,10))
sns.violinplot("Embarked","Age", hue="Survived", data=train_df,split=True,ax=axes[2])
axes[2].set_title('Embarked and Age vs Survived')
axes[2].set_yticks(range(0,110,10))
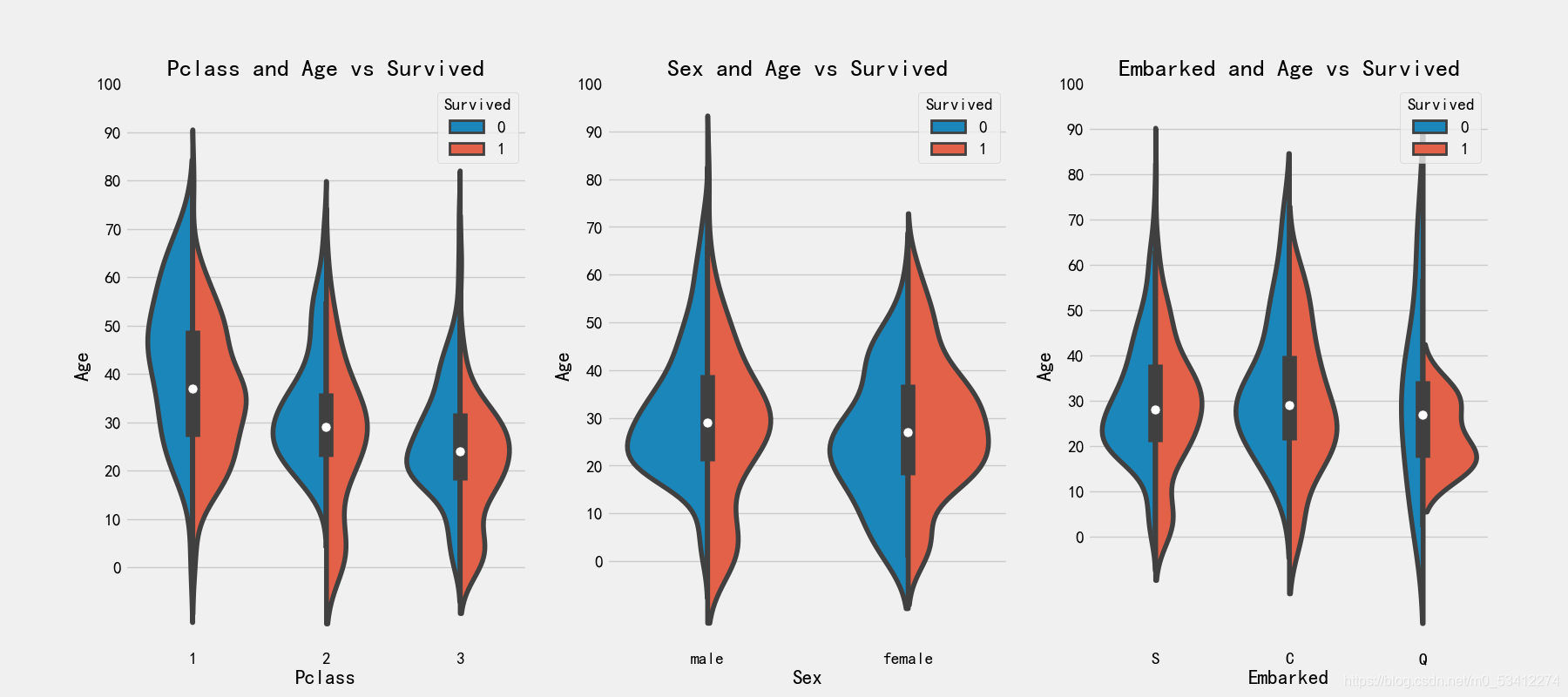
结论:
- 10岁以下儿童的存活率随passenger数量增加而增加
- 20-50岁的获救几率更高一些
- Q港口45以上和5岁以下没有生还可能
接下来将数据进行填充
# 按照分组来求平均年龄
train_df.groupby('Initial')['Age'].mean()
Initial
Master 4.574167
Miss 21.860000
Mr 32.739609
Mrs 35.981818
Other 45.888889
Name: Age, dtype: float64
# 使用每组的均值来进行填充缺失值
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Mr'),'Age']=33
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Mrs'),'Age']=36
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Master'),'Age']=5
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Miss'),'Age']=22
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Other'),'Age']=46
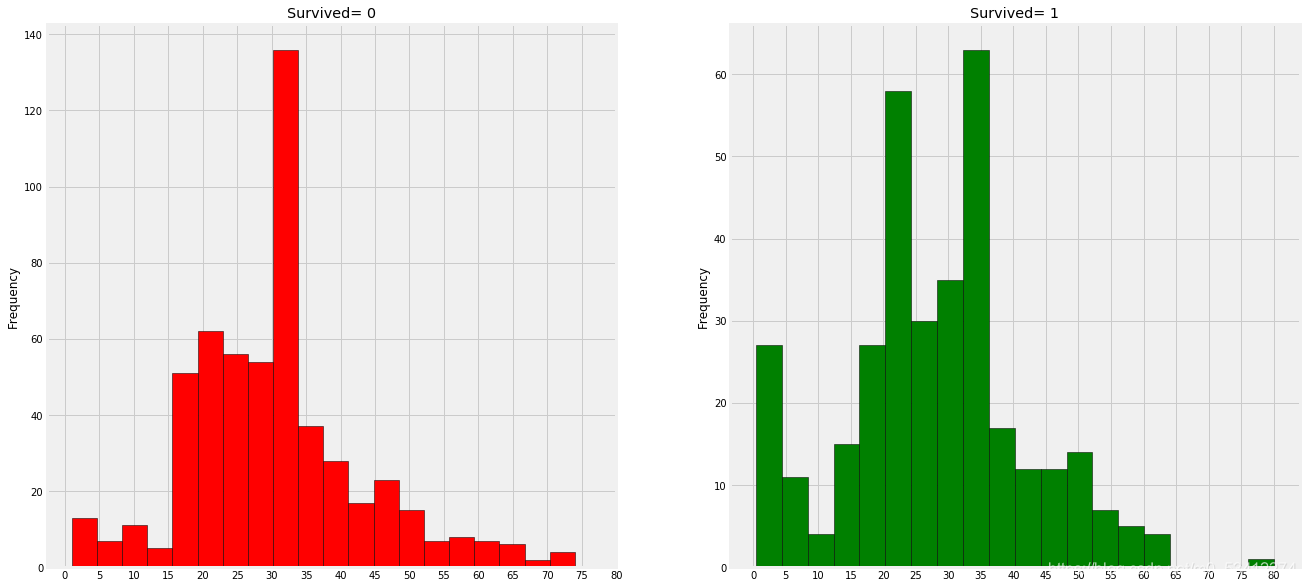
# 绘图可视化
fig,axes = plt.subplots(1,2,figsize=(20,10))
train_df[train_df['Survived']==0].Age.plot.hist(ax=axes[0],bins=20,edgecolor='black',color='red')
axes[0].set_title('Survived= 0')
x1 = list(range(0,85,5))
axes[0].set_xticks(x1)
train_df[train_df['Survived']==1].Age.plot.hist(ax=axes[1],color='green',bins=20,edgecolor='black')
axes[1].set_title('Survived= 1')
x2 = list(range(0,85,5))
axes[1].set_xticks(x2)
sns.factorplot('Pclass','Survived',col='Initial',data=train_df)

# 为Embarked属性填充缺失值
# 使用众数来填充港口缺失值,众数为S港
train_df['Embarked'].fillna('S',inplace=True)
# 挖掘兄弟姐妹的数量
pd.crosstab(train_df['SibSp'],train_df['Survived']).style.background_gradient(cmap='summer_r')
# 绘图显示兄弟姐妹数量和存活的关系
fig,axes = plt.subplots(1,2,figsize=(20,8))
sns.barplot('SibSp','Survived',data=train_df,ax=axes[0])
axes[0].set_title('SibSp vs Survived')
sns.factorplot('SibSp','Survived',data=train_df,ax=axes[1])
axes[1].set_title('SibSp vs Survived')
plt.close(2)
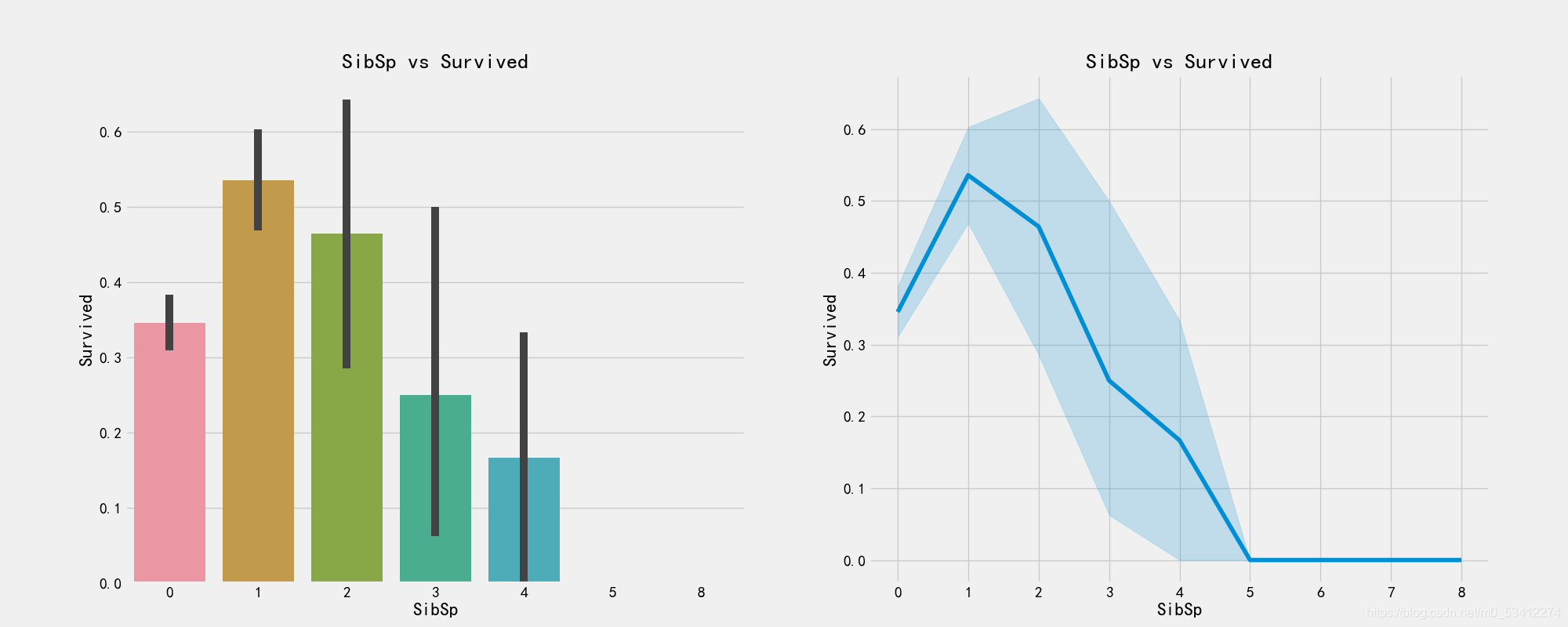
# 是否有兄弟姐妹和船舱等级关系
pd.crosstab(train_df['SibSp'],train_df['Pclass']).style.background_gradient(cmap='summer_r')
# 父母的数量
pd.crosstab(train_df['Parch'],train_df['Pclass']).style.background_gradient(cmap='summer_r')
# 绘图可视化出是否有父母和孩子与存活之间的关系
f,ax = plt.subplots(1,2,figsize=(20,8))
sns.barplot('Parch','Survived',data=train_df,ax=ax[0])
ax[0].set_title('Parch vs Survived')
sns.factorplot('Parch','Survived',data=train_df,ax=ax[1])
ax[1].set_title('Parch vs Survived')
plt.close(2)
plt.show()
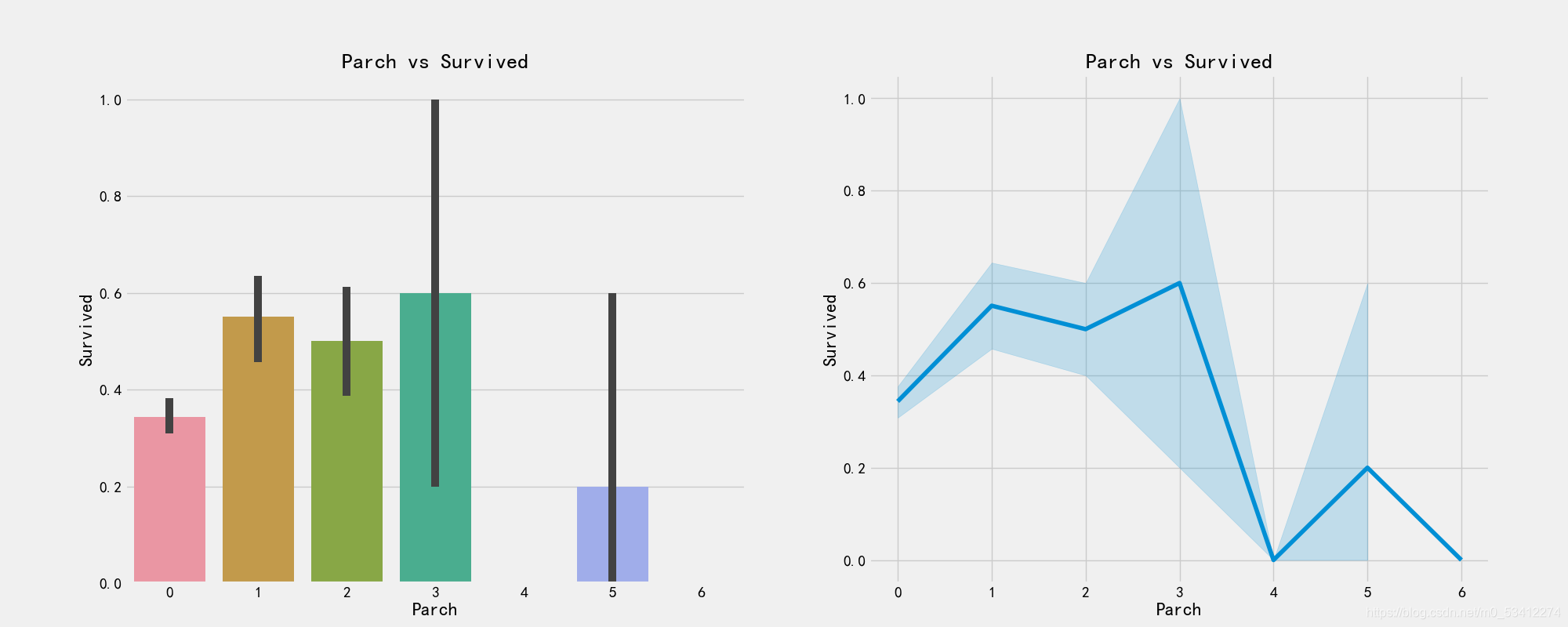
# 船票价格
print('Highest Fare was:',train_df['Fare'].max())
print('Lowest Fare was:',train_df['Fare'].min())
print('Average Fare was:',train_df['Fare'].mean())
Highest Fare was: 512.3292
Lowest Fare was: 0.0
Average Fare was: 32.204207968574636
# 绘图可视化
f,ax = plt.subplots(1,3,figsize=(20,8))
sns.distplot(train_df[train_df['Pclass']==1].Fare,ax=ax[0])
ax[0].set_title('Fares in Pclass 1')
sns.distplot(train_df[train_df['Pclass']==2].Fare,ax=ax[1])
ax[1].set_title('Fares in Pclass 2')
sns.distplot(train_df[train_df['Pclass']==3].Fare,ax=ax[2])
ax[2].set_title('Fares in Pclass 3')
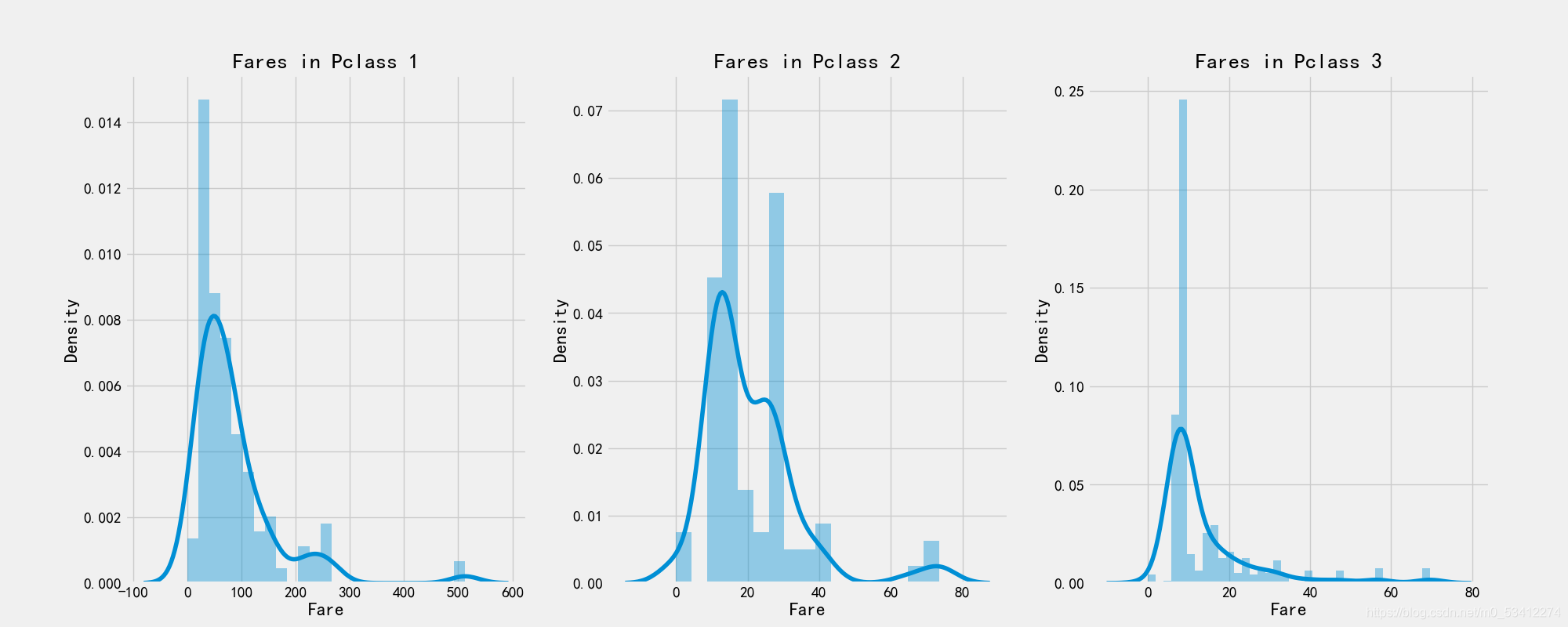
- 性别:与男性相比,女性的生存机会很高。
- Pclass:一级船舱的存活率很高,很遗憾对于pclass3成活率很低。
- 年龄:小于5-10岁的儿童存活率高。年龄在15到35岁之间的乘客死亡很多。
- 港口:上来的仓位也有区别,死亡率也很大!
- 家庭:有1-2的兄弟姐妹、配偶或父母上1-3显示而不是独自一人或有一个大家庭旅行,你有更大的概率存活。
二数据清洗
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
train_df = pd.read_csv(r'C:\Users\dahuo\Desktop\数据集2\train.csv')
print(train_df.columns)
# 绘制热力图来查看先有各个特征之间的相关性
sns.heatmap(train_df.corr(),annot=True,cmap='RdYlGn',linewidths=0.2)
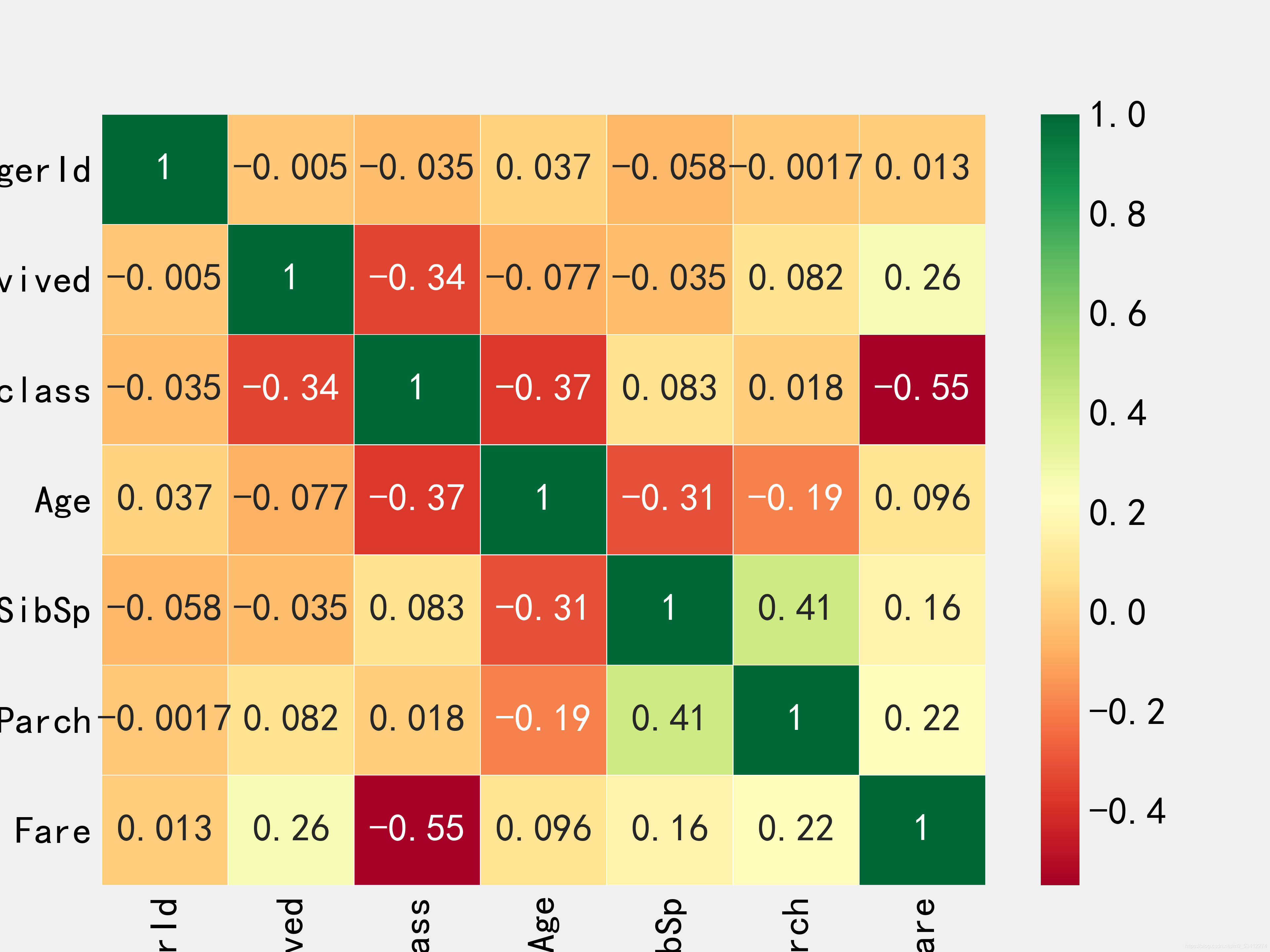
缺失值填充
填充年龄缺失值
train_df['Initial'] = train_df.Name.str.extract('([A-Za-z]+)\.')
train_df['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],inplace=True)
# 按照分组来求平均年龄
train_df.groupby('Initial')['Age'].mean()
# 使用每组的均值来进行填充缺失值
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Mr'),'Age']=33
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Mrs'),'Age']=36
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Master'),'Age']=5
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Miss'),'Age']=22
train_df.loc[(train_df.Age.isnull())&(train_df.Initial=='Other'),'Age']=46
填充港口缺失值
# 使用众数S
train_df.Embarked.fillna('S',inplace=True)
train_df.Embarked.isnull().any()
数据清洗
# 年龄特征离散化
# 将乘客的年龄分布分为5组,一组的年龄间距为16
train_df.loc[train_df['Age']<=16,'Age_band'] = 0;
train_df.loc[(train_df['Age']>16)&(train_df['Age']<=32),'Age_band'] = 1;
train_df.loc[(train_df['Age']>32)&(train_df['Age']<=48),'Age_band'] = 2;
train_df.loc[(train_df['Age']>48)&(train_df['Age']<=64),'Age_band'] = 3;
train_df.loc[train_df['Age']>64,'Age_band'] = 4;
# 增加家庭总人口数
train_df['Family_num'] = train_df['Parch'] + train_df['SibSp']
# 增加是否孤独一人特征
train_df['Alone'] = 0
train_df.loc[train_df['Family_num']==0,'Alone'] = 1;
fig,ax = plt.subplots(1,2,figsize=(18,6))
sns.factorplot('Family_num','Survived',data=train_df,ax=ax[0])
ax[0].set_title('Family_Size vs Survived')
sns.factorplot('Alone','Survived',data=train_df,ax=ax[1])
ax[1].set_title('Alone vs Survived')
plt.close(2)
plt.close(3)
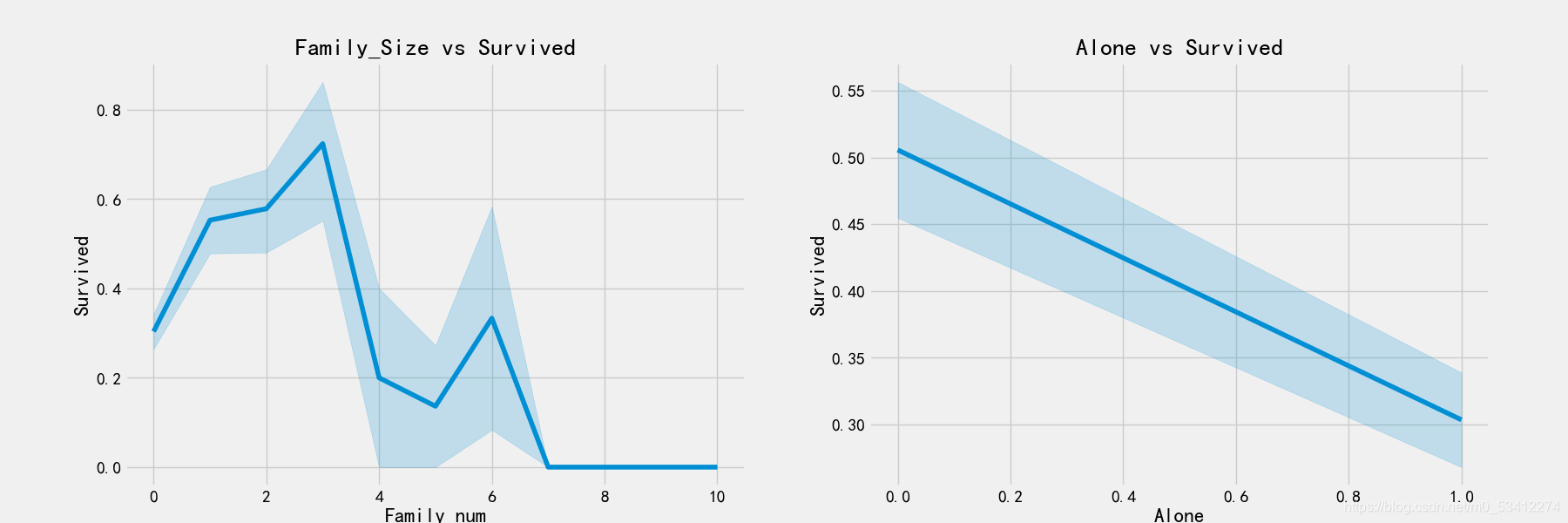
从上图可以看出来,孤独的人生还的可能性只有30%,与有亲属的相差较多,同时还可以看出,在亲属数量>=4个的时候,生还可能性开始下降
sns.factorplot('Alone','Survived',data=train_df,hue='Sex',col='Pclass')
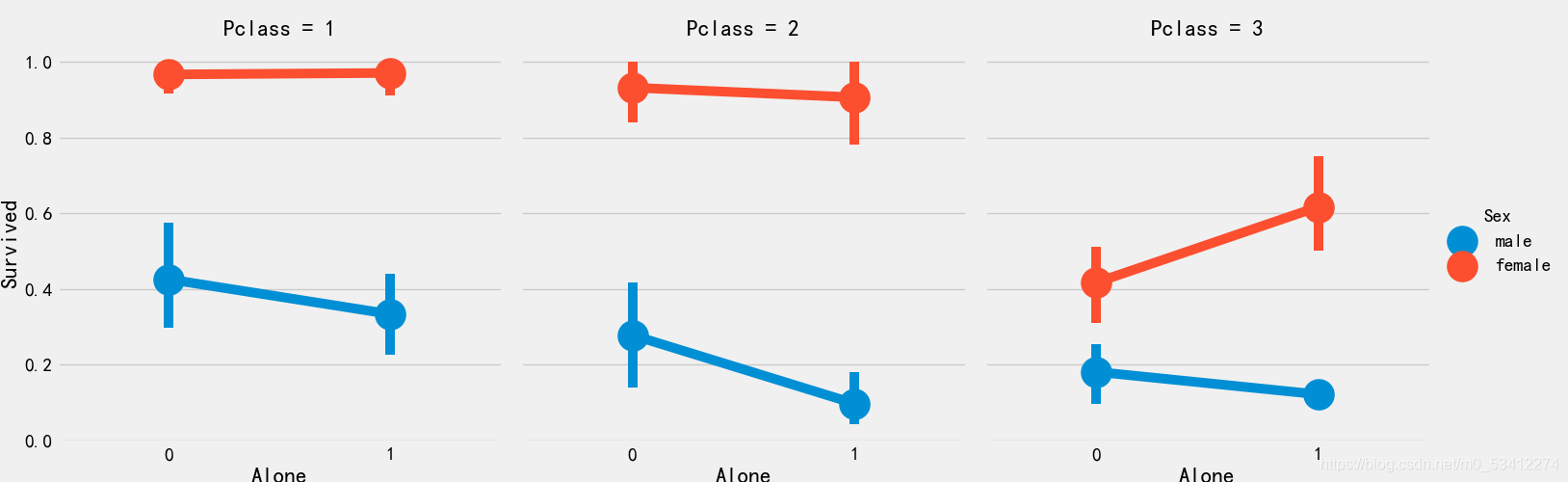
# 船票离散化
train_df['Fare_range'] = pd.qcut(train_df['Fare'],4)
train_df.groupby(['Fare_range'])['Survived'].mean().to_frame()
train_df.loc[train_df['Fare']<=7.91,'Fare_cat'] = 0
train_df.loc[(train_df['Fare']>7.91)&(train_df['Fare']<=14.454),'Fare_cat']=1
train_df.loc[(train_df['Fare']>14.454)&(train_df['Fare']<=31),'Fare_cat']=2
train_df.loc[(train_df['Fare']>31)&(train_df['Fare']<=513),'Fare_cat']=3
sns.lineplot('Fare_cat','Survived',hue='Sex',data=train_df)
plt.show()
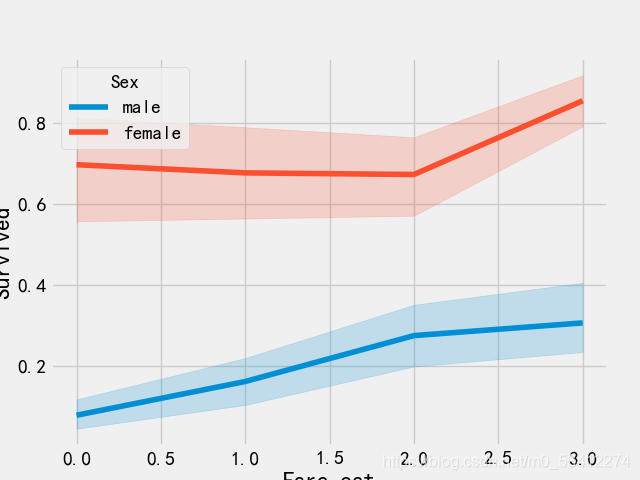
从上图可以看出,生存几率随船票价格增加而增加
# 将离散特征转化为数字
train_df['Sex'].replace(['male','female'],[0,1],inplace=True)
train_df['Embarked'].replace(['S','C','Q'],[0,1,2],inplace=True)
train_df['Initial'].replace(['Mr','Mrs','Miss','Master','Other'],[0,1,2,3,4],inplace=True)
# 去掉姓名、年龄、票号、票价、船舱号等特征
train_df.drop(['Name','Age','Ticket','Fare','Cabin','Fare_range','PassengerId'],axis=1,inplace=True)
train_df.info()
sns.heatmap(train_df.corr(),annot=True,cmap='RdYlGn',linewidths=0.2)
fig = plt.gcf()
fig.set_size_inches(18,15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()
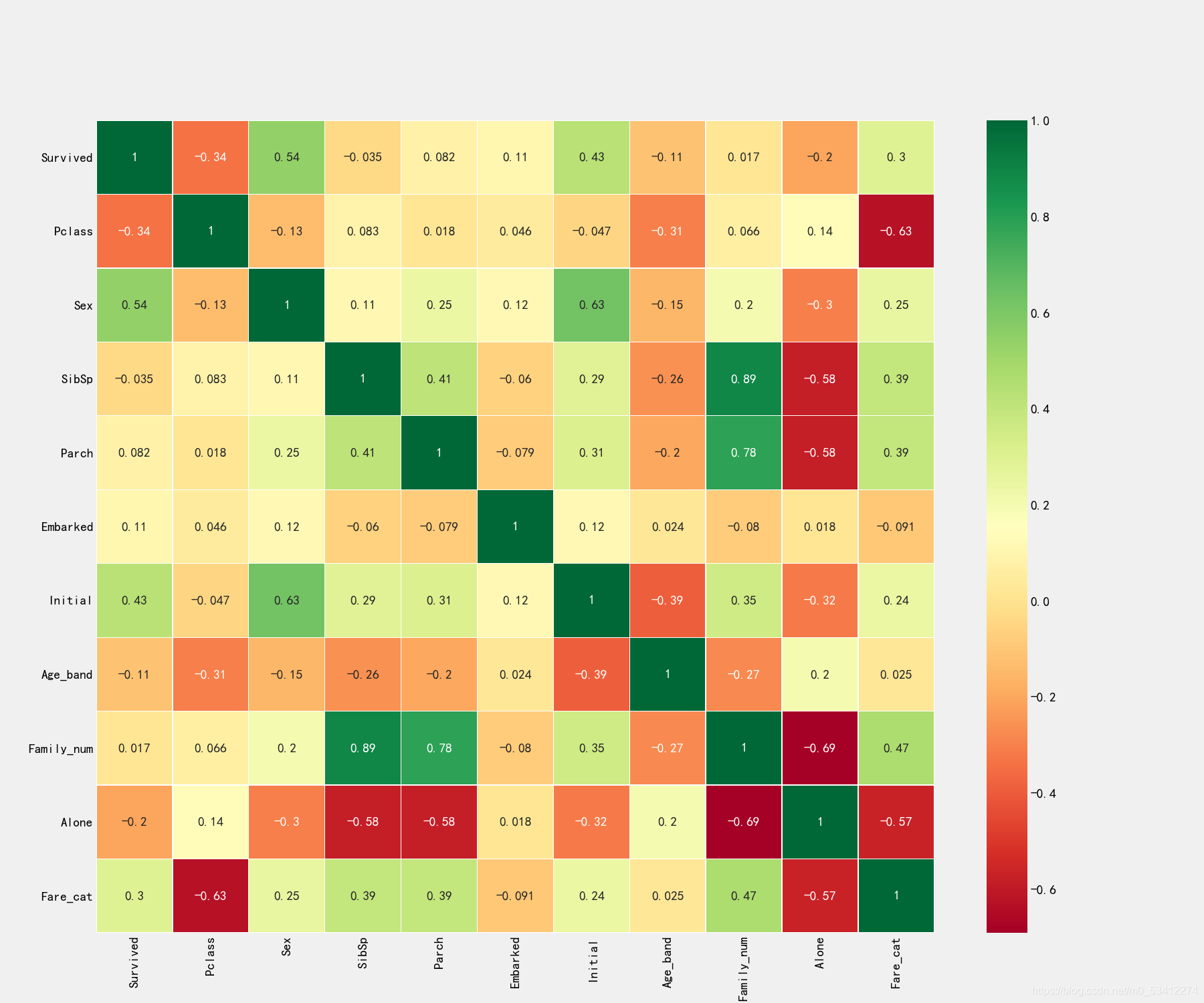
# 将处理后的数据暂时保存下来
train_df.to_csv(r'C:\Users\dahuo\Desktop\数据集2\processed_train.csv',encoding='utf-8',index=False)
三训练模型
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import GridSearchCV
划分数据集
data = pd.read_csv(r'C:\Users\dahuo\Desktop\数据集2\processed_train.csv')
train_df,test_df = train_test_split(data,test_size=0.3,random_state=0,stratify=data['Survived'])
train_X = train_df[train_df.columns[1:]]
train_y = train_df[train_df.columns[:1]]
test_X = test_df[test_df.columns[1:]]
test_y = test_df[test_df.columns[:1]]
X = data[data.columns[1:]]
y = data['Survived']
SVM(高斯核)
model = svm.SVC(kernel='rbf',C=1,gamma=0.1)
model.fit(train_X,train_y)
prediction = model.predict(test_X)
metrics.accuracy_score(prediction,test_y)
SVM(线性)
model = svm.SVC(kernel='linear',C=0.1,gamma=0.1)
model.fit(train_X,train_y)
prediction = model.predict(test_X)
metrics.accuracy_score(prediction,test_y)
** LR**
model = LogisticRegression()
model.fit(train_X,train_y)
prediction = model.predict(test_X)
metrics.accuracy_score(prediction,test_y)
决策树
model = DecisionTreeClassifier()
model.fit(train_X,train_y)
prediction = model.predict(test_X)
metrics.accuracy_score(prediction,test_y)
KNN
model = KNeighborsClassifier(n_neighbors=9)
model.fit(train_X,train_y)
prediction = model.predict(test_X)
metrics.accuracy_score(prediction,test_y)
0.835820895522388
predict_arr = pd.Series()
for i in range(1,11):
model = KNeighborsClassifier(n_neighbors=i)
model.fit(train_X,train_y)
prediction = model.predict(test_X)
predict_arr = predict_arr.append(pd.Series(metrics.accuracy_score(prediction,test_y)))
# 绘图展示
index = list(range(1,11))
plt.plot(index,predict_arr)
plt.xticks(list(range(0,11)))
print(predict_arr.values.max)
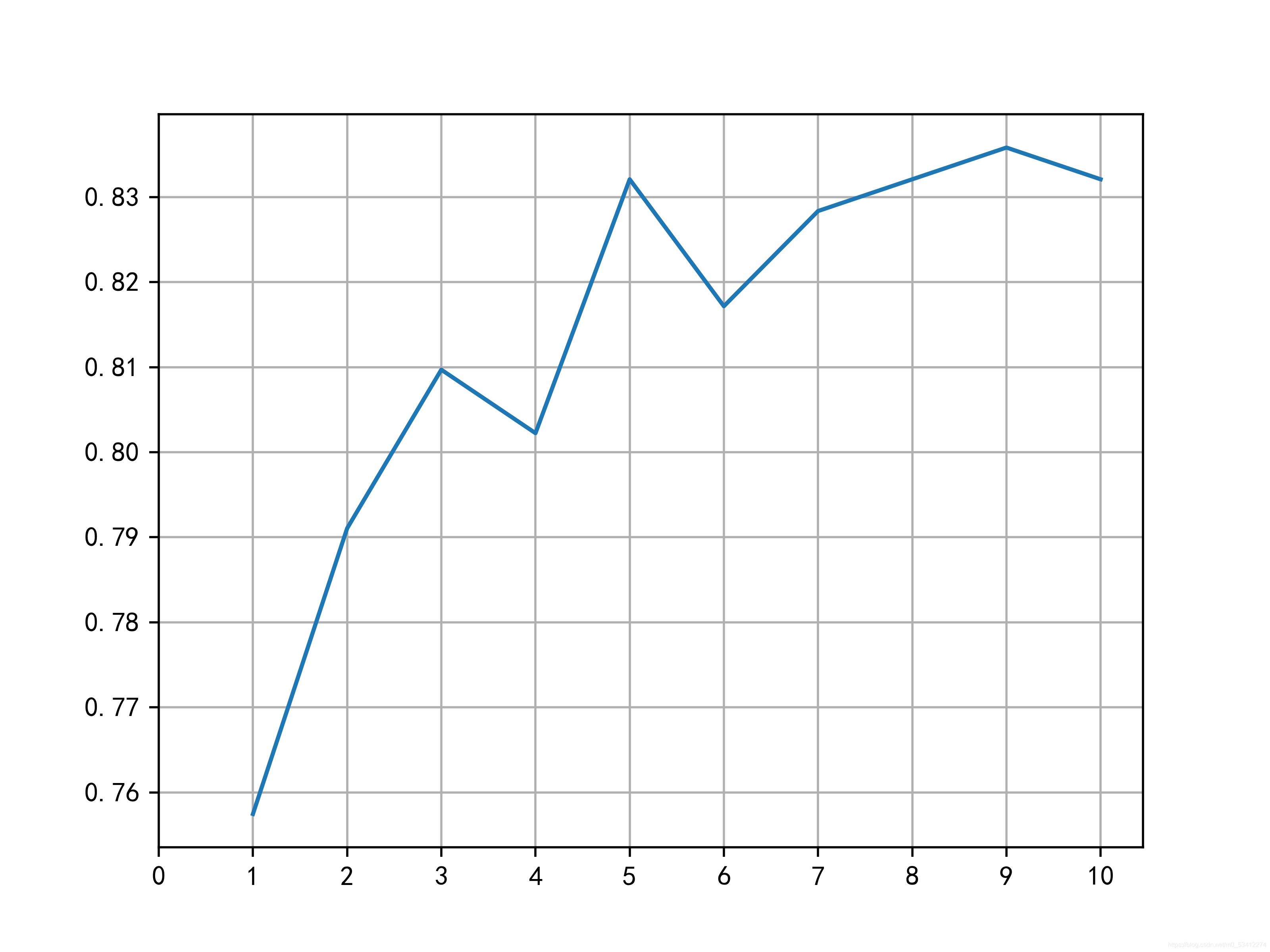
朴素贝叶斯
model = GaussianNB()
model.fit(train_X,train_y)
prediction = model.predict(test_X)
metrics.accuracy_score(prediction,test_y)
0.8134328358208955
随机森林
model = RandomForestClassifier(n_estimators=100)
model.fit(train_X,train_y)
prediction = model.predict(test_X)
metrics.accuracy_score(prediction,test_y)
交叉验证
kfold = KFold(n_splits=10,random_state=2019)
classifiers=['Linear Svm','Radial Svm','Logistic Regression','KNN','Decision Tree','Naive Bayes','Random Forest']
models = [svm.SVC(kernel='linear'),svm.SVC(kernel='rbf'),LogisticRegression(),KNeighborsClassifier(n_neighbors=9),DecisionTreeClassifier(),GaussianNB(),RandomForestClassifier(n_estimators=100)]
mean = []
std = []
auc = []
for model in models:
res = cross_val_score(model,X,y,cv=kfold,scoring='accuracy')
mean.append(res.mean())
std.append(res.std())
auc.append(res)
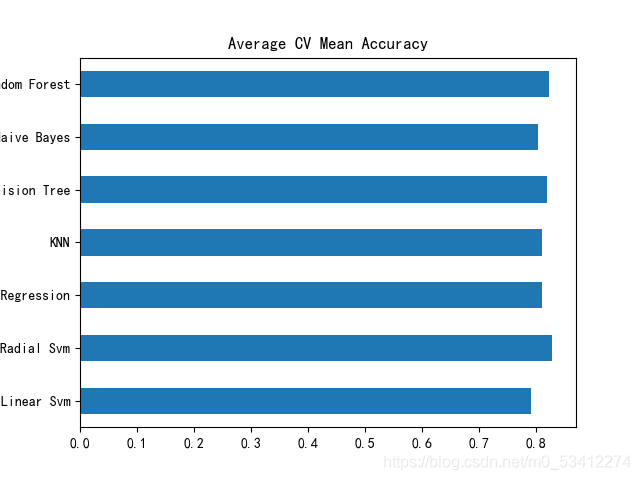
res_df = pd.DataFrame({'Mean':mean,'Std':std},index=classifiers)
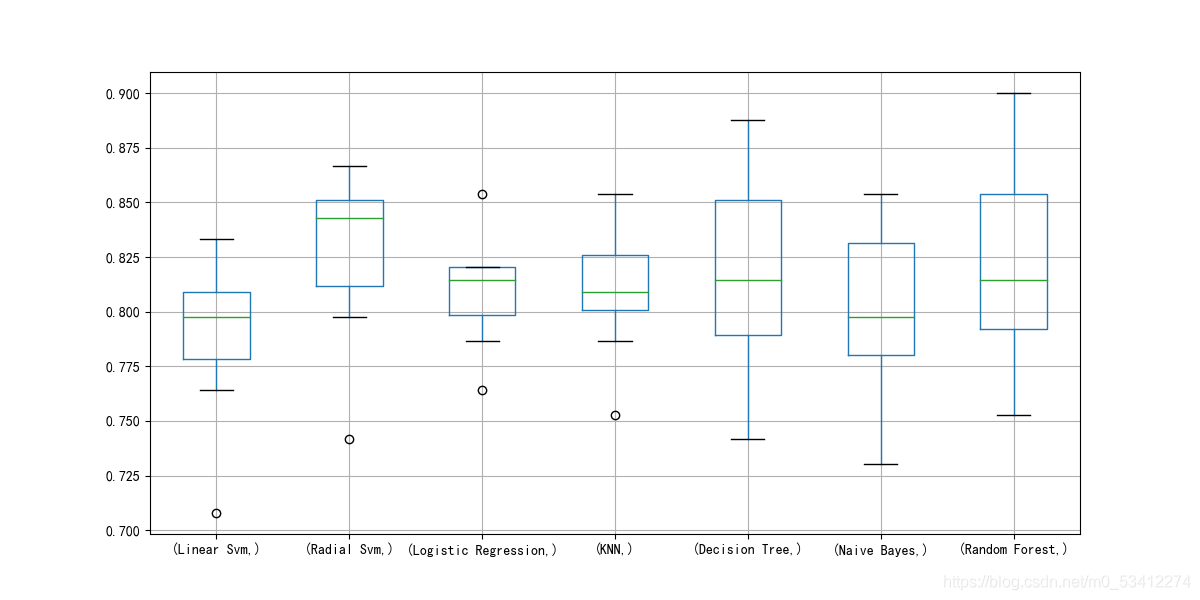
绘制各个算法相应的箱型图
plt.subplots(figsize=(12,6))
box = pd.DataFrame(auc,index=[classifiers])
box.T.boxplot()
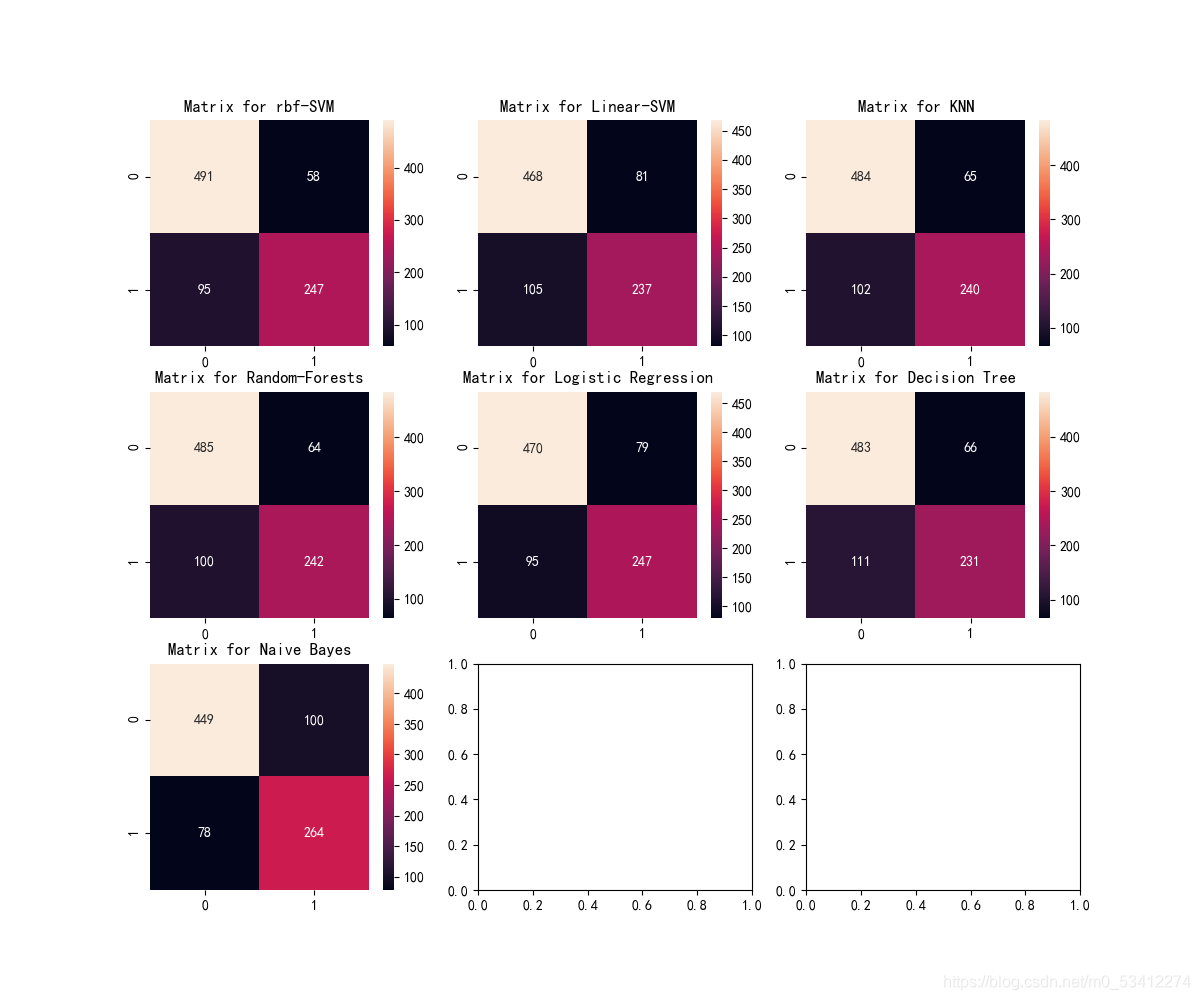
绘制混淆矩阵,给出正确分类和不正确分类的数量
fig,ax = plt.subplots(3,3,figsize=(12,10))
y_pred = cross_val_predict(svm.SVC(kernel='rbf'),X,y,cv=10)
sns.heatmap(confusion_matrix(y,y_pred),ax=ax[0,0],annot=True,fmt='2.0f')
ax[0,0].set_title('Matrix for rbf-SVM')
y_pred = cross_val_predict(svm.SVC(kernel='linear'),X,y,cv=10)
sns.heatmap(confusion_matrix(y,y_pred),ax=ax[0,1],annot=True,fmt='2.0f')
ax[0,1].set_title('Matrix for Linear-SVM')
y_pred = cross_val_predict(KNeighborsClassifier(n_neighbors=9),X,y,cv=10)
sns.heatmap(confusion_matrix(y,y_pred),ax=ax[0,2],annot=True,fmt='2.0f')
ax[0,2].set_title('Matrix for KNN')
y_pred = cross_val_predict(RandomForestClassifier(n_estimators=100),X,y,cv=10)
sns.heatmap(confusion_matrix(y,y_pred),ax=ax[1,0],annot=True,fmt='2.0f')
ax[1,0].set_title('Matrix for Random-Forests')
y_pred = cross_val_predict(LogisticRegression(),X,y,cv=10)
sns.heatmap(confusion_matrix(y,y_pred),ax=ax[1,1],annot=True,fmt='2.0f')
ax[1,1].set_title('Matrix for Logistic Regression')
y_pred = cross_val_predict(DecisionTreeClassifier(),X,y,cv=10)
sns.heatmap(confusion_matrix(y,y_pred),ax=ax[1,2],annot=True,fmt='2.0f')
ax[1,2].set_title('Matrix for Decision Tree')
y_pred = cross_val_predict(GaussianNB(),X,y,cv=10)
sns.heatmap(confusion_matrix(y,y_pred),ax=ax[2,0],annot=True,fmt='2.0f')
ax[2,0].set_title('Matrix for Naive Bayes')
plt.subplots_adjust(hspace=0.2,wspace=0.2)
plt.show()
利用网格搜索进行超参数设定
C = [0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
gamma = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]
kernel = ['rbf','linear']
hyper = {'kernel':kernel,'C':C,'gamma':gamma}
gd = GridSearchCV(estimator=svm.SVC(),param_grid=hyper,verbose=True)
gd.fit(X,y)
print(gd.best_estimator_)
print(gd.best_score_)
C = 0.5
gamma = 0.1
n_estimators = range(100,1000,100)
hyper = {'n_estimators':n_estimators}
gd = GridSearchCV(estimator=RandomForestClassifier(random_state=0),param_grid=hyper,verbose=True)
gd.fit(X,y)
print(gd.best_score_)
print(gd.best_estimator_)
Mean Std
Linear Svm 0.790075 0.033587
Radial Svm 0.828240 0.036060
Logistic Regression 0.809213 0.022927
KNN 0.809176 0.026277
Decision Tree 0.817004 0.046226
Naive Bayes 0.803620 0.037507
Random Forest 0.815880 0.038200
Fitting 5 folds for each of 240 candidates, totalling 1200 fits
SVC(C=0.4, gamma=0.3)
0.8282593685267716
Fitting 5 folds for each of 9 candidates, totalling 45 fits
0.819327098110602
RandomForestClassifier(n_estimators=300, random_state=0)
四模型融合
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.ensemble import VotingClassifier
import xgboost as xgb
from sklearn.ensemble import AdaBoostClassifier
data = pd.read_csv(r'C:\Users\dahuo\Desktop\数据集2\processed_train.csv')
train_df,test_df = train_test_split(data,test_size=0.3,random_state=0,stratify=data['Survived'])
train_X = train_df[train_df.columns[1:]]
train_y = train_df[train_df.columns[:1]]
test_X = test_df[test_df.columns[1:]]
test_y = test_df[test_df.columns[:1]]
X = data[data.columns[1:]]
y = data['Survived']
#投票分类器
estimators = [
('linear_svm',svm.SVC(kernel='linear',probability=True)),
('rbf_svm',svm.SVC(kernel='rbf',C=0.5,gamma=0.1,probability=True)),
('lr',LogisticRegression(C=0.05)),
('knn',KNeighborsClassifier(n_neighbors=10)),
('rf',RandomForestClassifier(n_estimators=500,random_state=0)),
('dt',DecisionTreeClassifier(random_state=0)),
('nb',GaussianNB())
]
vc = VotingClassifier(estimators=estimators,voting='soft')
vc.fit(train_X,train_y)
print('The accuracy for ensembled model is:',vc.score(test_X,test_y))
# cross = cross_val_score(vc,X,y,cv=10,scoring='accuracy')
# mean=cross.mean()
# print(mean)
#xgboost
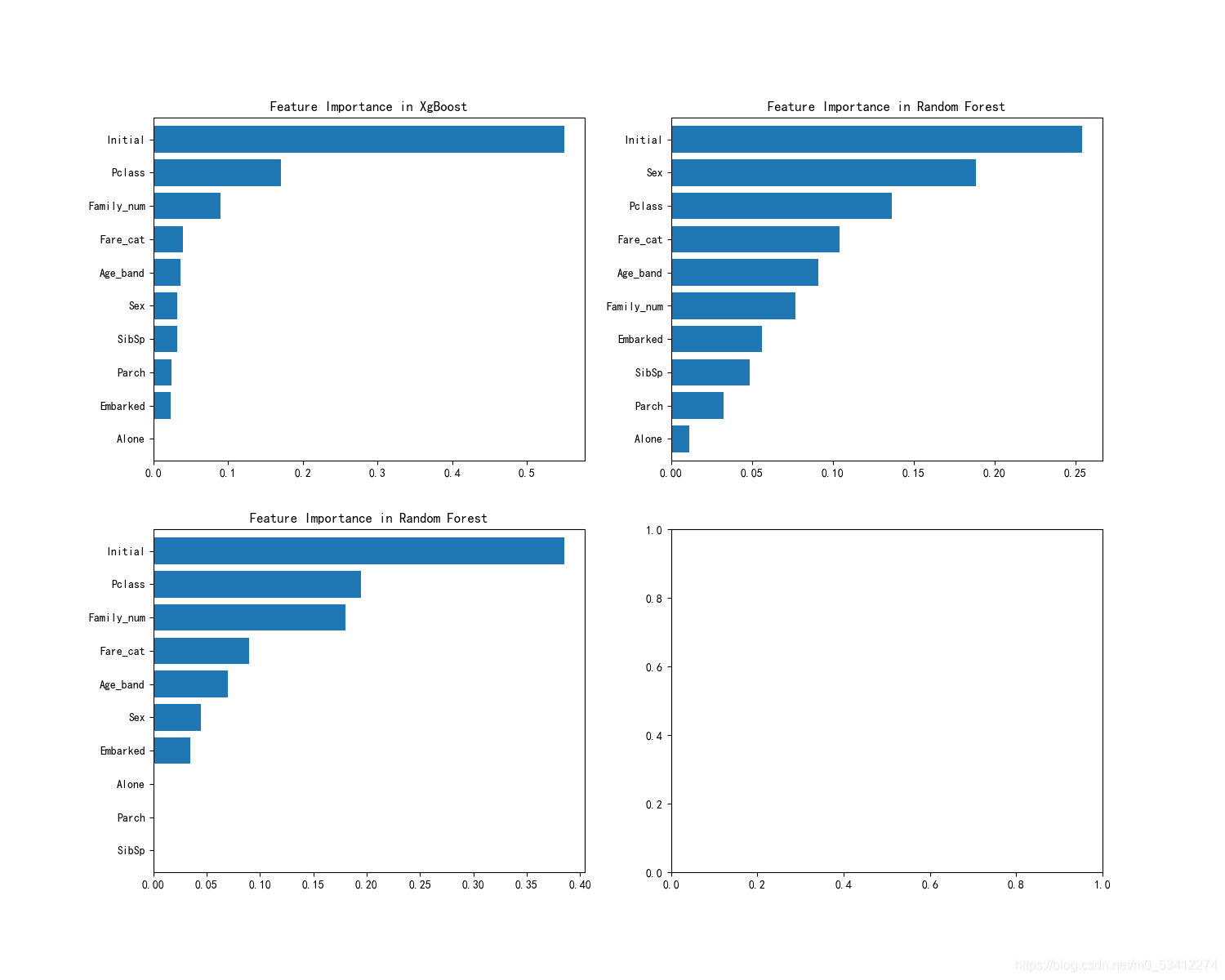
fig,ax = plt.subplots(2,2,figsize=(15,12))
model = xgb.XGBClassifier(n_estimators=900,learning_rate=0.1)
model.fit(X,y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,0])
ax[0,0].set_title('Feature Importance in XgBoost')
plt.grid()
model = RandomForestClassifier(n_estimators=500,random_state=0)
model.fit(X,y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,1])
ax[0,1].set_title('Feature Importance in Random Forest')
plt.grid()
model=AdaBoostClassifier(n_estimators=200,learning_rate=0.05,random_state=0)
model.fit(X,y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[1,0])
ax[1,0].set_title('Feature Importance in Random Forest')
plt.grid()
model = RandomForestClassifier(n_estimators=500,random_state=0)
model.fit(X,y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,1])
ax[0,1].set_title('Feature Importance in Random Forest')
plt.grid()
plt.show()


















 3590
3590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









