







Unique in the Crowd: The privacy bounds of human mobility
本文发表在2013年的Nature杂志上,主要阐述了一个人类流动性的隐私保护问题。
论文获取网址:Unique in the Crowd: The privacy bounds of human mobility | Scientific Reports (nature.com)
摘要
摘要部分作者研究了 150 万人的 15 个月的人员流动数据,发现人员流动轨迹非常独特。作者的主要发现是四个时空点就可以识别95%的人,并且粗略的数据集也无法有效地保障用户的隐私性。
正文
隐私问题一直是一个值得关注的问题。特别在美国,隐私的概念一直是他们多元化社会发展的基础,构成了言论自由和宗教自由等个人权利的基础。如果一个人隐私泄露出去,那么结果肯定是严重的。现当今随着互联网的迅速发展,人人都在用智能手机,手机的定位,软件的定位,网页的定位都在无时无刻提取着用户的轨迹信息,即使这些信息有些是匿名的,但通过多次的数据出现与偏好设置,仍然可以识别出其用户。所有这些都助长了简单匿名移动数据集的普遍存在,并为隐私问题提供了空间。
简单匿名化的数据集不包含姓名、家庭住址、电话号码或其他明显的标识符。 然而,如果个人的模式足够独特,则可以使用外部信息将数据链接回个人。
总之,移动数据集的普遍性、人类轨迹的独特性以及可以从中推断出的信息突出了理解人类移动隐私边界的重要性。
本文表明:
1.人类移动轨迹的独特性很高,并且移动数据集很可能仅使用少数外部位置的信息即可重新识别。
2.证明了一个公式,确定了移动轨迹的唯一性,为移动数据的隐私提供了数学界限。
3.发现轨迹迹线的唯一性根据幂函数降低,指数函数与已知时空点的数量成线性比例。 这意味着即使是粗略的数据集也几乎无法提供匿名性。
实验结果
我们先了解论文中的几个图:
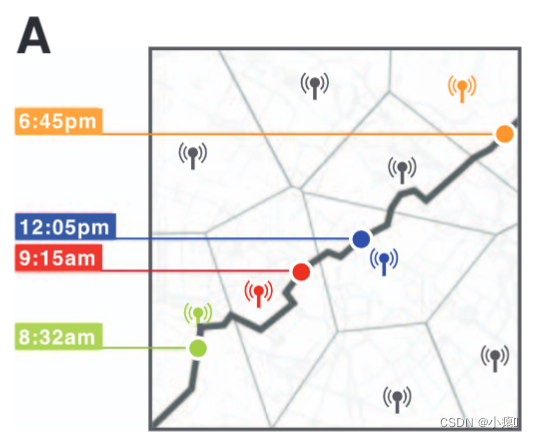
图1A:一天中匿名手机用户的轨迹。 这些点代表用户拨打或接听电话的时间和地点。 每次用户进行此类交互时,都会记录路由呼叫的最近天线(基站)。
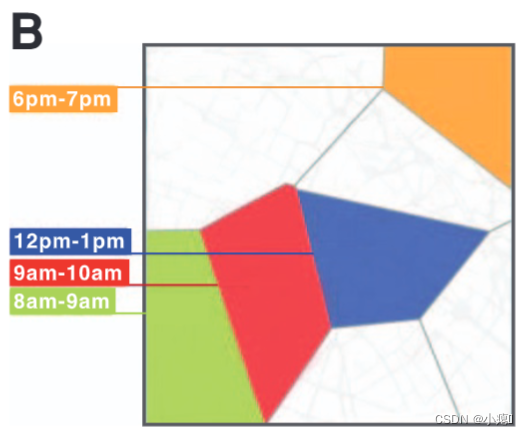
图1B:移动数据集中记录的同一用户的轨迹。 由灰线表示的 V o r o n o i Voronoi Voronoi 晶体形状的单元格是天线接收区域的近似值,是我们可用的最精确的位置信息。 此处记录用户的交互时间,精度为一小时。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5hp1BWCN-1682670142758)(C:\Users\Yan\AppData\Roaming\Typora\typora-user-images\image-20230428131917033.png)]](https://img-blog.csdnimg.cn/0f7b39728d9b4c43b752d280cfbf10d3.png)
图1C:当我们通过空间和时间聚合降低数据集的分辨率时,同一个人的轨迹。 天线聚集在大小为 2 的集群中,并且它们的相关区域被合并。 用户的交互以两个小时的精度记录。 这种空间和时间聚合使得上午 8 点 32 分和上午 9 点 15 分的交互无法区分。
本文测试了估计了唯一识别个人移动轨迹所需的点数 p p p。 所需的点越少,痕迹就越独特,使用外部信息重新识别它们就越容易。 出于重新识别的目的,外部观察可以来自任何公开可用的信息,例如个人的家庭住址、工作场所地址或本地的推文或图片。 本文第一次在一个小国家规模的稀疏、简单匿名的流动性数据集中使用随机点对人类流动性痕迹的独特性进行量化。
下面是本文的标识:
v v v 空间分辨率(天线数量);
h h h 时间分辨率(小时);
I p I_p Ip 一组时空节点,由 p p p个点组成;
D D D 一份简单的匿名移动数据集;
ε \varepsilon ε 轨迹的独特性;
S ( I p ) S(I_p) S(Ip) 从 D D D 中提取的与构成 I p I_p Ip 的 p p p 个点相匹配的轨迹集。
通过从 D D D 中提取 S ( I p ) S(I_p) S(Ip) 的子集来评估 ε \varepsilon ε 。如果 ∣ S ( I p ) ∣ = 1 |S(I_p)|=1 ∣S(Ip)∣=1 , 则一个轨迹是独特的,并且只包含一个轨迹。
这里作者举了一个例子:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J2jROSqh-1682670142759)(C:\Users\Yan\AppData\Roaming\Typora\typora-user-images\image-20230428125055747.png)]](https://img-blog.csdnimg.cn/667869217a82430c960d38bdc334ee18.png)
图2A: I p = 2 I_{p=2} Ip=2 意味着攻击者可用的信息由两个 7 a m − 8 a m 7am-8am 7am−8am 时空点( I I I 和 I I II II)组成。 在这种情况下,目标在上午 9 点到 10 点之间位于 I I I 区,在中午 12 点到 1 点之间位于 I I II II 区。 在此示例中,两个匿名用户(红色和绿色)的痕迹与 I p = 2 I_{p=2} Ip=2 定义的约束兼容。 子集 S ( I p = 2 ) S(I_{p=2}) S(Ip=2) 包含不止一条轨迹,因此不是唯一的。 但是,如果添加第三个点,即下午 3 点到 4 点之间的区域 I I I III III,则绿色迹线将具有独特的特征 I p = 3 I_{p=3} Ip=3。
在A图中,我们评估了在给定 I p = 2 I_{p=2} Ip=2下的一个轨迹图特性。 I p = 2 I_{p=2} Ip=2的两个时空点在区域 I I I 的 9 a m − 10 a m 9am-10am 9am−10am 时间段中和区域 I I II II的 12 p m − 1 p m 12pm-1pm 12pm−1pm 时间段中。图中红色和绿色的轨迹都满足 I p = 2 I_{p=2} Ip=2,所以他们不是唯一的。但是,我们还可以评估已知 I p = 3 I_{p=3} Ip=3 的轨迹的唯一性,在下午 3 点到 4 点之间添加第三个点区域 I I I III III。 在这种情况下 ∣ S ( I p = 3 ) ∣ = 1 |S(I_{p=3})|=1 ∣S(Ip=3)∣=1 唯一地表示了绿色的轨迹。
用户身份的隐私泄露风险的下限是由他的移动轨迹的独特性决定的,这种特征会很容易让用户的隐私暴露,即使是匿名的情况下。
数据集:包含 150 万人的 15 个月的移动数据,这是一个欧洲小国人口的重要且具有代表性的部分,并且与基于定位的服务 Foursquare 的用户数量大致相同。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xo3SpqGa-1682670142759)(C:\Users\Yan\AppData\Roaming\Typora\typora-user-images\image-20230428130112166.png)]](https://img-blog.csdnimg.cn/cd46129241064b9c87788ca9e09fea0c.png)
图2B:轨迹相对于给定时空点 I p I_p Ip 的数量 p p p 的唯一独特性。 绿色条代表独特轨迹的分数,即 ∣ S ( I p ) ∣ = 1 |S(I_p)|=1 ∣S(Ip)∣=1 。蓝色条代表的分数 S ( I p ) ≤ 2 S(I_p)\le 2 S(Ip)≤2。因此,只知道随机获取的四个时空点 I p = 4 I_{p=4} Ip=4 就足以唯一地表征 150 万用户中 95% 的轨迹。
图B显示了作为可用节点数 p p p 的函数的唯一轨迹 ε \varepsilon ε 的分数。 四个随机选择的点足以唯一地表征 95% 的用户 ( ε > . 95 \varepsilon > .95 ε>.95),而两个随机选择的点仍然可以唯一地表征超过 50% 的用户 ( ε > . 5 \varepsilon > .5 ε>.5)。 这表明移动轨迹非常独特,因此可以使用很少的外部信息重新识别。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-urwPFsJR-1682670142760)(C:\Users\Yan\AppData\Roaming\Typora\typora-user-images\image-20230428161626595.png)]](https://img-blog.csdnimg.cn/1ff075eccf8741bebd451c76e9b9f001.png)
图2C:唯一表征非聚合数据集上每条轨迹所需的最少时空点数 p p p 的箱线图。 最多 11 个点足以唯一地表征所有考虑的迹线。评估了唯一表征给定集合中每条迹线所需的最小 p p p。
尽管如此, ε \varepsilon ε 取决于数据集的空间和时间分辨率。 在这里,我们通过空间和时间聚合降低数据集的分辨率来确定这种依赖性 (图1C)。 我们通过增加一个区域的大小,将相邻单元格聚集成 v v v 个单元格集合,或通过降低数据集的时间分辨率,将观察时间窗口的长度增加到 h h h 小时来实现这一点(这部分作者在写在方法中)。 这两种聚合都必然会降低 ε \varepsilon ε,因此会使重新识别变得更加困难。
下面先了解一些图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u04RrqFh-1682670142760)(C:\Users\Yan\AppData\Roaming\Typora\typora-user-images\image-20230428133009324.png)]](https://img-blog.csdnimg.cn/0fc1d5d6cb3d4601bbfb44da71671521.png)
图4A :显示了移动轨迹 ε \varepsilon ε 的唯一性如何取决于数据的空间和时间分辨率。 然而,这种减少是相当渐进的。 给定四个点 ( p = 4 p=4 p=4),我们发现当使用时间分辨率 h = 5 h = 5 h=5 小时,空间分辨率为 v = 5 v = 5 v=5 个天线时 ε > . 5 \varepsilon >.5 ε>.5 。从统计上讲,我们发现当在一个维度上粗糙而在另一个维度上精细时,轨迹比在两个维度上都是中等粒度时更独特。事实上,给定四点, ε > . 6 \varepsilon >.6 ε>.6 在时间分辨率为 h = 15 h = 15 h=15 小时或空间分辨率为 v = 15 v = 15 v=15 天线的数据集中,而 ε > . 4 \varepsilon >.4 ε>.4 在时间分辨率为 h = 7 h = 7 h=7 小时和空间分辨率为 v = 7 v = 7 v=7 天线的数据集中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iVPMvsAq-1682670142760)(C:\Users\Yan\AppData\Roaming\Typora\typora-user-images\image-20230428143804878.png)]](https://img-blog.csdnimg.cn/ee6156a48d344fb2b4755c10a6aedefd.png)
图4D:当我们用 (图4A) p = 4 p=4 p=4 和 (图4D) p = 10 p=10 p=10 点降低数据集的分辨率时,轨迹 $\varepsilon $ 的唯一性。 攻击一个维度粗糙而另一个维度精细的数据集比攻击两个维度的中粒度数据集更容易。 给定四个时空点,超过 60% 的轨迹在时间分辨率为 h = 15 h = 15 h=15 小时的数据集中具有独特特征,而时间分辨率为 h = 7 h=7 h=7和 空间分辨率为$v = 7 $天线个数 的数据集中只有不到 40% 的轨迹具有独特特征。 天线覆盖范围从城市地区的0.15平方公里到农村地区的15平方公里。
接下来,我们表明可以找到一个公式来估计给定数据的空间和时间分辨率以及外部观察者可用的点数的轨迹的唯一性。
下面介绍图4BC:当降低数据集的时间或空间分辨率时,轨迹的唯一性会以幂函数 ε = α − x β \varepsilon = \alpha - {x^\beta } ε=α−xβ 的形式降低。
作者还考虑不同轨迹点 p p p 的取值情况,得出人类的流动性的独特性可以用一个公式表达: ε = α − ( v h ) β \varepsilon = \alpha - {(vh)^\beta } ε=α−(vh)β。
并且作者发现这个指数函数比两个参数的函数能够更好的拟合数据。
ε \varepsilon ε 的幂律依赖性意味着,平均而言,每次轨迹的空间或时间分辨率除以二时,它们的唯一性都会降低一个常数因子 2 − β {2^{ - \beta }} 2−β。 这意味着通过降低数据集的分辨率越来越难以获得隐私。
回顾图2B, ε \varepsilon ε 随着 p p p 的增加而增加。 p p p 对 ε \varepsilon ε 的线性衰减是由指数 β \beta β 调节的: β = 0.157 − 0.007 p \beta = 0.157 - 0.007p β=0.157−0.007p [图4E]。 β \beta β 对 p p p 的依赖性意味着可能只需要几个额外的点就可以识别具有较低分辨率的数据集中的个体。 事实上,给定 4 个点,空间或时间分辨率降低两倍会使识别个人的可能性降低 9.3%,而给定 10 个点,同样的两倍降低导致仅减少 6.2%。
由于 ε \varepsilon ε 通过指数 β \beta β 对 p p p 的函数依赖性,移动数据集很可能仅使用少数外部位置的信息即可重新识别。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NVJja9vi-1682670142761)(C:\Users\Yan\AppData\Roaming\Typora\typora-user-images\image-20230428144602289.png)]](https://img-blog.csdnimg.cn/450859f3205f494ba283083646ae45ff.png)
图4B:随着时间分辨率 h h h的增大,不同单元格数的轨迹独特性降低的速度不同。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CnbnQPq1-1682670142761)(C:\Users\Yan\AppData\Roaming\Typora\typora-user-images\image-20230428144618560.png)]](https://img-blog.csdnimg.cn/cfc46b806693449faa3a9d6f6a374276.png)
图4C:随着空间分辨率 v v v的增大,不同时间段的轨迹独特性降低的速度不同。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xmP691kN-1682670142761)(C:\Users\Yan\AppData\Roaming\Typora\typora-user-images\image-20230428151024887.png)]](https://img-blog.csdnimg.cn/dc57f20bda354aacb5c3fe4e11ee096c.png)
图4E:当 ε \varepsilon ε 根据幂函数减小时,其指数 β \beta β 随点数 p p p 线性减小。 因此,可能只需要几个额外的点就可以识别具有较低分辨率的数据集中的个体。
讨论
我们将这些结果推广到其他流动性数据集的能力取决于我们对将数据扩展到更大的人口或地理区域的分析的敏感性。 人口密度的增加将趋于降低 ε \varepsilon ε。 然而,它也将伴随着用于本地化的天线、企业或 WiFi 热点数量的增加。 这些影响彼此相反,因此表明我们的结果应该推广到更高的人口密度。
观察地理范围的扩展也不太可能影响结果,因为众所周知,人类流动性受到高度限制。 事实上,94% 的个体在平均半径小于 100 公里的范围内移动。 这意味着数据集的地理扩展将在当地与我们的观察保持一致,从而使结果对地理范围的变化具有鲁棒性。
从推理的角度来看,值得注意的是时空点并没有同样增加唯一识别轨迹的可能性。 此外,一个点添加的信息高度依赖于已知的点。 通过多了解一个点而获得的信息量可以定义为与该额外点相关联的 S ( I p ) S(I_p) S(Ip) 的基数的减少。 减少的幅度越大,这条信息就越有用。 就是说,凌晨 3 点在麻省理工学院校园内的一个点比周五晚上在波士顿市中心的一个点更有可能使迹线独一无二。
这项研究可能低估了 ε \varepsilon ε,因此也低估了重新识别的难易程度,因为时空点是从用户的移动轨迹中随机抽取的。 因此,我们的 I p I_p Ip 受制于用户的空间和时间分布。 在空间上,已经表明,由其熵测量的典型用户行踪的不确定性为 1.74,小于两个位置。 这使得我们随机选择的点可能会选择用户最喜欢的位置(通常是“家”和“办公室”)。 从时间上看,一周内的呼叫分布远非均匀,这使得我们的随机选择更有可能在下午 4 点而不是凌晨 3 点选择一个点。 然而,即使在这种情况下,我们认为最难识别的轨迹也可以在仅知道 11 个位置的情况下被唯一识别。
为了重新识别的目的,更复杂的方法可以收集更有可能减少不确定性的点,利用个人行为中的违规行为,或者隐含地考虑家庭和工作场所或出国旅行等信息。 相对于轨迹的平均唯一性,此类方法可能会减少识别个人所需的位置数量。
我们证明了人类移动轨迹的独特性很高,从而强调了人类运动的特质对个人隐私的重要性。 事实上,这种独特性意味着即使在稀疏、大规模和粗略的移动数据集中,也需要很少的外部信息来重新识别目标个体的踪迹。 考虑到可以从移动数据中推断出的信息量,以及可能存在的大量简单匿名移动数据集,这是一个日益受到关注的问题。 我们进一步表明, 这个两个相关性 ε ∼ ( v h ) β , β ∼ − p / 100 \varepsilon \sim {(vh)^\beta },\beta \sim - p/100 ε∼(vh)β,β∼−p/100。 鉴于轨迹的分辨率和可用的外部信息,这些共同决定了人类移动轨迹的独特性。 这些结果应该为未来在收集、使用和保护移动数据方面的思考提供信息。 展望未来,位置数据的重要性只会增加,了解个人隐私的界限对于未来政策和信息技术的设计至关重要。
方法
数据集:这项工作是使用匿名手机数据集执行的,该数据集包含移动电话运营商 150 万用户的呼叫信息。 数据收集于 2006 年 4 月至 2007 年 6 月在一个西方国家进行。 每次用户通过发起或接收呼叫或短信与移动电话运营商网络交互时,连接天线的位置都会被记录下来 [图1A]。 因此,数据集的固有空间分辨率是天线之间的最大半距离。 数据集的固有时间分辨率是一小时[图1B]。
单一性测试和隐私泄露的可能性:所考虑的数据集包含每个用户的一个轨迹 T T T。轨迹时空点包含用户所在的区域和交互时间。我们在给定 p p p 个随机选择的时空点的集合 I p I_p Ip 的情况下评估轨迹的唯一性。如果 I p ∈ T I_p \in T Ip∈T [图 2A],则称轨迹与 I p I_p Ip 兼容。请注意,这种兼容性的概念可以很容易地扩展到更嘈杂或更丰富的数据。通过从 150万个用户 S ( I p ) S(I_p) S(Ip) 的整个数据集中提取移动轨迹 T T T 与 I p I_p Ip 兼容的用户集来得到强力特征信息。数据集 $ T $ 中的所有移动轨迹都连续测试与 I p I_p Ip 的兼容性。如果一个节点与兼容的轨迹集最多包含 x x x 个用户( ∣ S ( I p ) ∣ ≤ x |S(I_p)| \le x ∣S(Ip)∣≤x),则轨迹的特征是 out of x x x 的。 如果集合恰好包含一条轨迹,则轨迹具有唯一特征: ∣ S ( I p ) ∣ = 1 |S(I_p)|=1 ∣S(Ip)∣=1。轨迹的唯一性估计为给定 p p p 个时空点唯一的 2500 个随机轨迹的百分比。 组成 I p I_p Ip 的 p p p 个点是在用户与服务进行的所有交互中随机抽取的。 如前所述,我们不对 I p I_p Ip 的选择施加任何限制。
唯一表征每条轨迹所需的最少时空位置数:图2B显示,给定 I p = 4 I_{p=4} Ip=4 , . 95 < ε < 1 .95<\varepsilon<1 .95<ε<1。 图 2C 评估了唯一表征给定集合中每条迹线所需的最小 p p p。 该集合包含 1000 个超级喜欢用手机的用户的随机样本,即每月至少使用手机 75 次的用户,因为他们随机选择的点可能会使他们的轨迹不那么独特。
空间聚合:空间聚合是通过增加已知用户在与服务交互期间所在区域的大小来实现的。 在离散数据的情况下,天线(在这种情况下称为质心)和
V
o
r
o
n
o
i
Voronoi
Voronoi 晶体形状的单元格之间存在双射关系。 单元格被定义为使得一个区域中的每个点都更接近该区域的天线而不是任何其他天线。 为了增加区域的面积,应该将天线分组为给定大小
v
v
v 的簇。虽然将 2D 空间中的位置最佳分组为给定大小
v
v
v 的组的问题并不简单,但可以通过聚类方法来近似。 规范聚类方法侧重于最小化簇内平方和,而不是生成平衡的簇。 这个缺点可以通过使用频率敏感竞争性学习方案来控制。一旦天线被聚合成组,它们的相关区域就会合并。
何其他天线。 为了增加区域的面积,应该将天线分组为给定大小
v
v
v 的簇。虽然将 2D 空间中的位置最佳分组为给定大小
v
v
v 的组的问题并不简单,但可以通过聚类方法来近似。 规范聚类方法侧重于最小化簇内平方和,而不是生成平衡的簇。 这个缺点可以通过使用频率敏感竞争性学习方案来控制。一旦天线被聚合成组,它们的相关区域就会合并。















 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









