






这篇文章发表于2022年,获取网站:https://arxiv.org/abs/2212.07081v1。
发表机构:Rakuten Institute of Technology。
本篇文章主要使用KNN算法对用户轨迹采样分类,得到了一个比深度学习方法更好的匿名用户轨迹分类结果。
文章贡献:
作者证明了签到模式的独特性。即每个用户对应一个独特的签到场所。
采用了简单的方法k-nn。
大规模轨迹分类。
作者采用了两种方式实验,一是用欧氏距离+设置k值采样签到轨迹进行轨迹分类。二是利用jaccard距离替换欧氏距离,直接用于原始轨迹轨迹分类。二者实验结果近似。
5.分类性能与轨迹点维度d取值负相关,d越小,分类性能越好。时间间隔(天,周,月)对分类也有影响。时间间隔越短,分类性能越差。
感悟:
作者已经将匿名用户轨迹分类达到了一个很高的水平,并且利用的是很简单的方法。或许在未来的研究中,可以将此方法代替深度学习的方法,用于一些更细致的工作中。如果有更多的数据集以及更细致的平均指标,更多的轨迹特征与数据采样或许会有不同结果。
Abstract
Trajectory-User Linking (TUL) 是一项相对较新的移动分类任务,其中将匿名轨迹链接到生成它们的用户。 随着从个性化推荐到犯罪活动检测的应用,TUL 在过去五年中受到越来越多的关注。 虽然研究主要集中在学习捕获个人用户独有的复杂时空移动模式的深度表示,但我们证明访问模式在用户之间是高度独特的,因此直接应用于原始数据的简单启发式方法足以解决 TUL。 更具体地说,我们证明了每个轨迹的一次签到足以在高达 85% 的时间内正确预测用户的身份。 此外,通过使用非参数分类器,我们将 TUL 扩展到超过 100k 用户,这比最先进的增加了三个数量级。 对四个真实世界数据集(Brightkite、Foursquare、Gowalla 和 Weeplaces)的广泛实证分析将我们的发现与最先进的结果进行了比较,更重要的是验证了我们关于 TUL 比普遍认为的更容易的说法。
keywords: LBSNs, mobility classification
Introduction
Trajectory-User Linking (TUL) 应用于移动数据聚合、个性化推荐、消费者定位、异常检测、犯罪/恐怖行为检测、防疫,以及用于量化隐私保护移动轨迹合成算法的性能。以前关于 TUL的工作主要集中在学习端到端的深度表示,这些表示捕获个人用户独有的复杂时空移动模式。 学习到的表示用于训练分类器,该分类器为输入轨迹分配一个标签,该标签指示其所属用户的身份。 由于最多 800 个目标用户,可扩展性是 TUL 现有工作的一个主要限制。 更重要的是,以前的工作忽略了人类移动数据的两个特征:1)用户移动模式的独特性,以及 2)人类移动模式在足够长的时间段内的高度可预测性。
在本文中,我们认为由于移动模式在用户中是高度独特的,TUL 可以通过直接应用于原始轨迹数据本身的简单启发式方法来解决。 更具体地说,我们证明了每个轨迹的一次签到足以在高达 85% 的时间内正确预测用户的身份。此外,使用非参数分类器,我们将 TUL 扩展到属于超过 100k 唯一用户的 270 万条轨迹,这比最先进的方法增加了三个数量级。
Contributions:
经验证明签到模式在用户中是高度独特的。具体地说,每个轨迹的一次签到足以在高达 85% 的时间内正确预测用户的身份。
凭经验证明,应用于原始轨迹数据的简单启发式方法不仅足以解决 TUL,而且优于最先进的方法。
将 TUL 扩展到超过 10 万用户,这比最先进的增加了三个数量级。
Previous works
TUL 引入后,子轨迹首先嵌入到类似于 Word2Vec的低维空间中。 然后,馈送到循环神经网络 (RNN),该网络学习捕获个人用户独有的时空模式。 学习到的表示最终被馈送到 Softmax 层,其输出数量等于目标用户的数量。 网络被端到端地训练,在此期间推理轨迹被分配有最高概率的标签。在后来的发展中,变分自动编码器 (VAE)与不同深度的 RNN 相结合可以捕获用户轨迹的层次语义,这反映在性能略有提高上。 之后发现中,使用简单的三步架构报告了对最先进技术的重大改进。后来,对抗生成网络 (GAN)与注意力机制相结合,用于捕获用户行为的复杂模式。后来,历史注意层被纳入 RNN 以学习高阶和多周期模式。 相似用户的轨迹。 学习到的表示用于使用 k 最近邻 (kNN) 分类器对轨迹进行分类。 后来,具有注意机制的 RNN 后跟带有 Softmax 分类器的多层感知器 (MLP)用于将轨迹链接到用户。 也有使用对比学习来解决 TUL的。 最后,在某篇论文中提出了一个相互蒸馏学习框架来学习表示,这些表示使用 RNN 和时间感知转换器捕获丰富的上下文签入模式。
以前的工作仅限于对几百个用户的轨迹进行分类。 原因在于使用了一个分类层,每个目标用户都有一个硬编码输出。 训练具有大量输出的 Softmax 层具有挑战性且计算量大。 更不用说每次添加新用户时都需要从头开始重新训练模型。 这使得大多数现有作品不切实际,尤其是在用户数量不断增加的现实场景中。
Trajectory user linking
A. Problem definition
三元组 (u, t, v) 表示用户 u 在地点 v 和时间 t 签到的记录。用户 u 在时间间隔 τ 内生成的 n 个按时间顺序排列的签到记录序列称为轨迹。详见论文。
B. Trajectory segmentation
为了降低计算复杂性并捕捉有意义的时间模式,我们将每个轨迹分割成跨越较短时间间隔 τ 的 k 个连续子轨迹。 分割间隔τ可以设置为任何时间段,例如一天或一小时。 在我们的例子中,我们使用三个时间间隔,即日、周和月。详见论文。
C. Trajectory encoding
由于子轨迹的长度(签入次数)不同,首先我们需要将输入子轨迹转换为统一维度 d 的向量。 这样的向量可以通过将签到投射到维度 d 的空间中以无监督的方式学习。这个维度d的向量是由一串用户所经过所有的地点组成的ID,这些地点的选择是d个最大地点ID的串联编码。详见论文。
D. Trajectory classification
为了对轨迹进行分类,我们使用 k-最近邻分类器。 k-NN 是一种非参数监督分类算法,其中未标记的对象根据其 k 个最近邻居的多数类成员资格分配一个类标签。 邻居是从一组已知标签的对象中提取的。 这可以被认为是算法的训练数据集,尽管不需要明确的训练步骤。 对象之间的接近度是使用距离度量确定的,例如欧氏距离。输入 x 被分配了欧几里德空间中其 k 个最近邻居的多数类标签。详见论文。在我们的例子中,k-NN 分类器将轨迹的 d 维编码作为输入,并生成一个指示用户身份的标签作为输出。
Experiments
datasets
我们使用了四个广泛用于 TUL 的签到数据集:Brightkite、Foursquare、Gowalla和 Weeplaces。
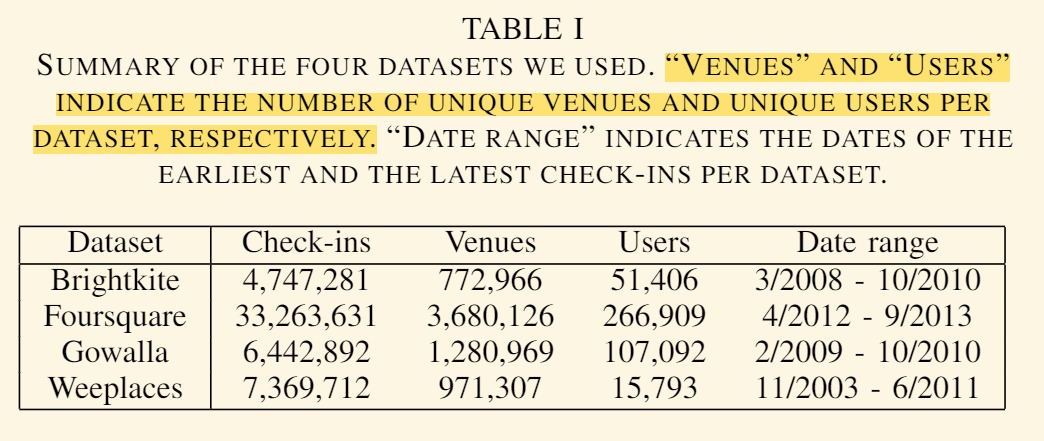
我们在 3 个不同的时间尺度(日、周和月)处理每个数据集,总共生成 12 个数据集。 我们保持每天、每周和每月至少签到 3、5 和 10 次的轨迹。我们只让用户每个人至少有 10 个轨迹。 我们将用户 ID 和场地 ID 替换为从 0 开始的序列号。最后,我们按用户 ID 和时间戳对数据集进行升序排序。获得的数据集在时间尺度、用户数、场地数和签到数方面各不相同。
evaluation
对于评估,我们使用了 k 处的准确性 (ACC@k)、Macro F1 分数 (Macro-F1)、Macro 精度 (Macro-P) 和 Macro recall (Macro-R),因为它们是 TUL 最常用的评估指标。详见论文。
hyperparameter tuning
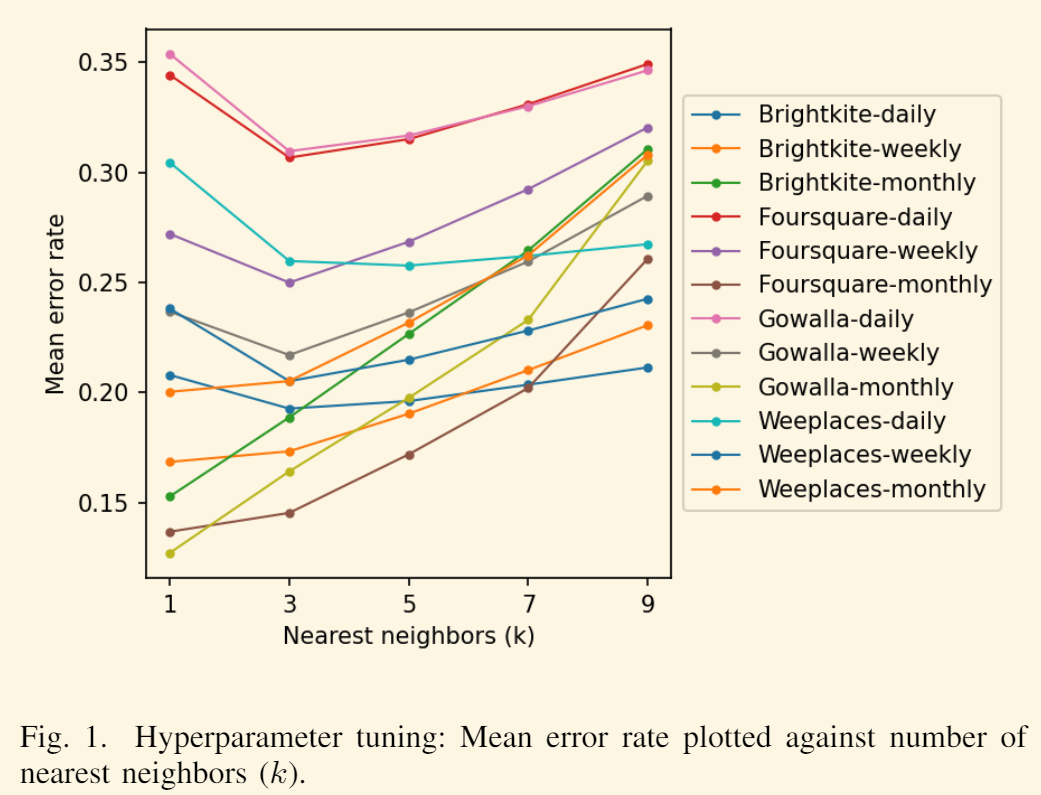
在图 1 中,我们将平均错误率绘制为最近邻 (k) 数量增加的函数。 我们观察到 k = {1, 3} 时的错误率最低。 由于 k = 1 分类对异常值和噪声敏感,因此每当使用 k-NN 时,我们在下文中将 k 设置为 3。
uniqueness of visit patterns
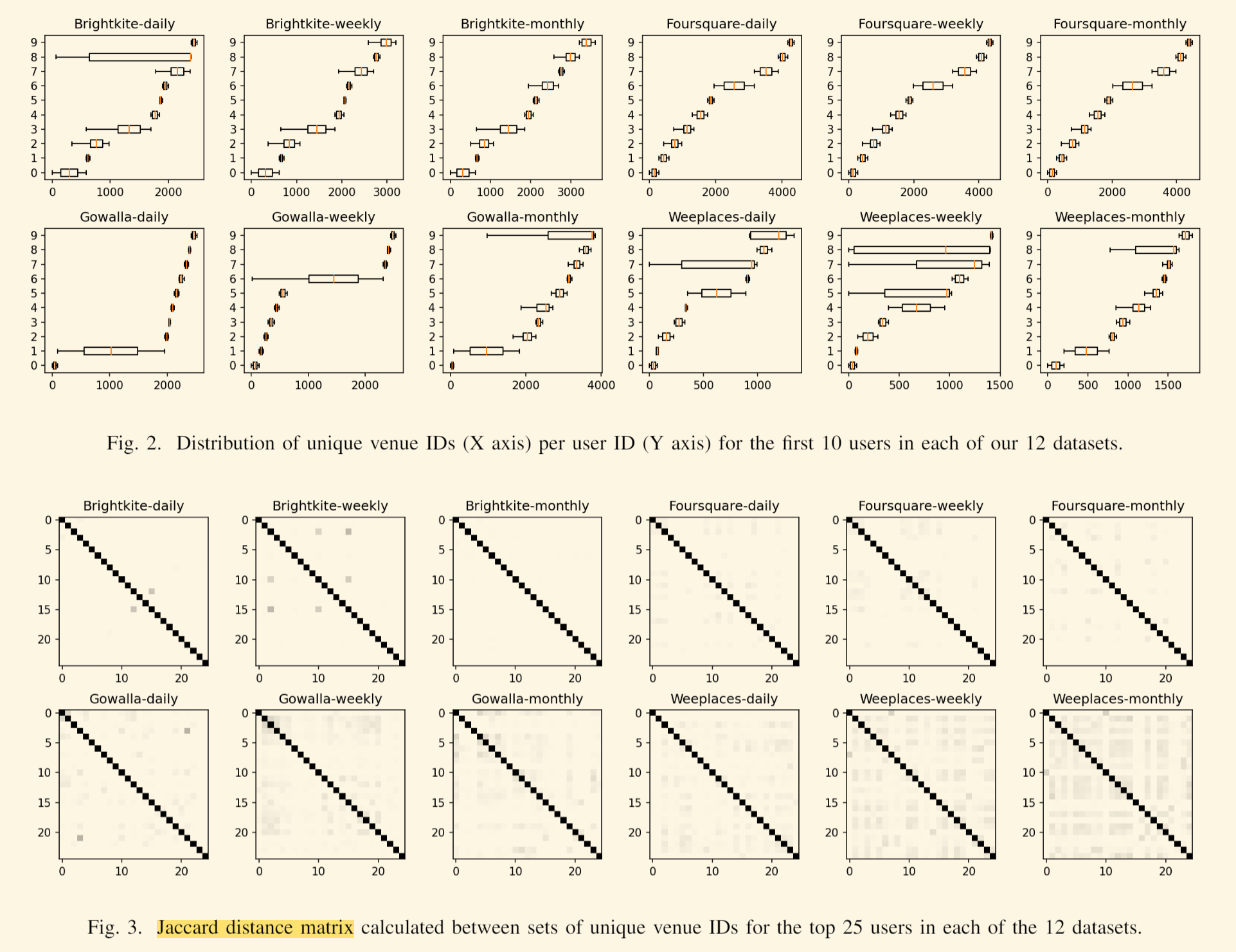
我们着手回答以下问题:不同用户的访问模式有多独特? 我们首先计算所有数据集的场地与用户比率(表 II)。 我们发现平均每个用户每天、每周和每月数据集分别有 47、60 和 124 个独特的场所。 接下来,我们在图 2 中绘制了 12 个数据集中每个数据集中的前 10 个用户的每个用户访问的唯一场所 ID 的分布。 从箱线图中可以清楚地看出,用户在 X 轴(场地 ID)上是分开的,即不同的用户访问不同的场地。 我们对不同的用户子集进行了实验,并获得了相似的结果。 最后,为了凭经验量化用户访问模式的独特性,我们在图 3 中绘制了每个数据集中前 25 名用户的 Jaccard 距离矩阵。 很明显,没有两个用户访问同一组场地。 事实上,前 25 名用户的平均 Jaccard 距离分别超过 0.996、0.991 和 0.992 的日轨迹、周轨迹和月轨迹,即用户访问的场所中超过 99% 是他们自己唯一的。获得的结果表明访问模式在用户中是高度独特的,这促使我们调查启发式是否足以解决 TUL。
Are heuristics sufficient to solve TUL?
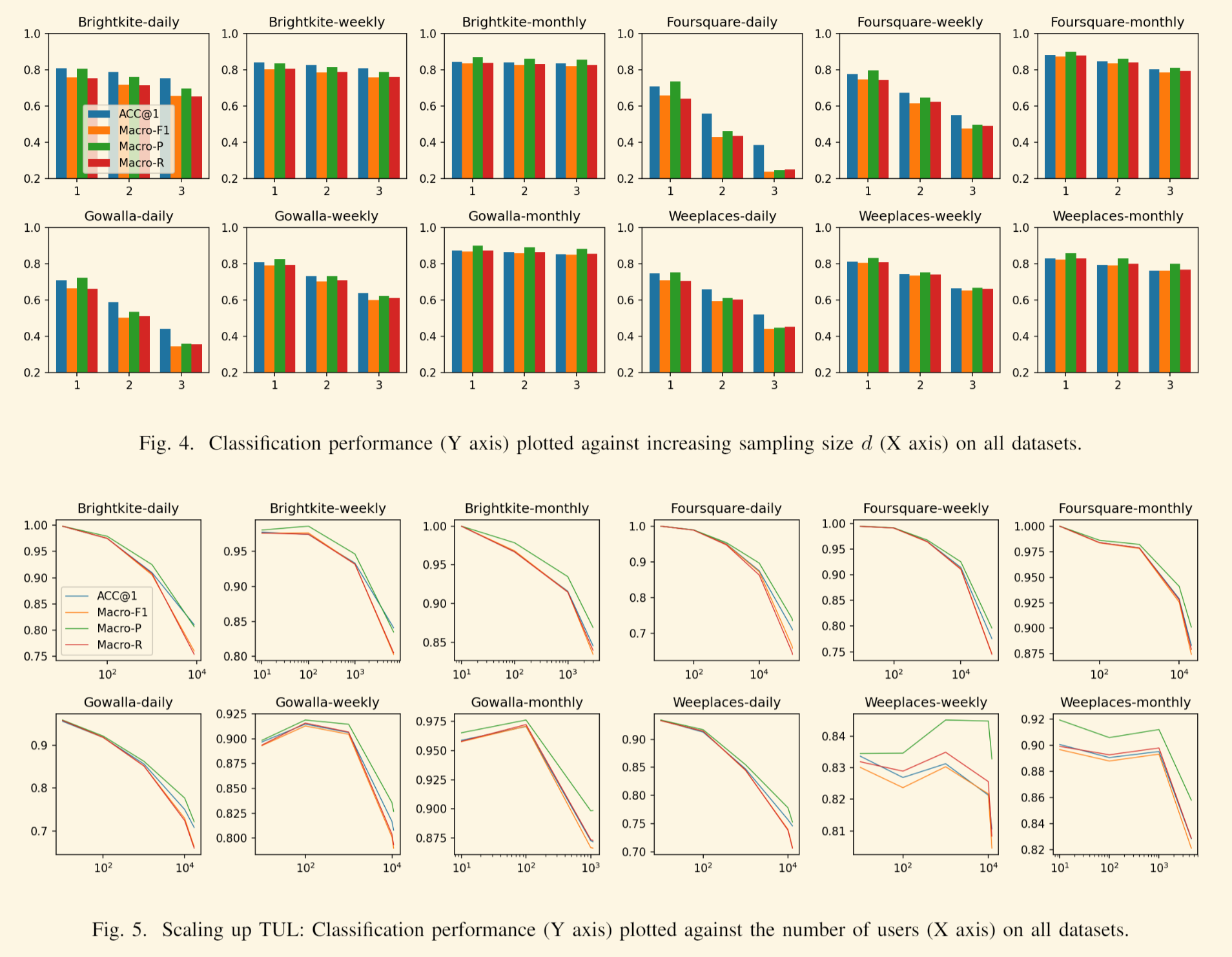
受上述结果的启发,我们评估了上一节中介绍的基于简单启发式的 TUL 方法的性能。 图 4 总结了获得的结果,绘制为分类性能与 d 值增加的关系。 我们将 d 限制为 3,因为它是跨不同时间间隔的每个轨迹保证的最小签到次数。 在所有数据集上,较小的 d 会产生更好的分类结果。 事实上,对于 d = 1,每日、每周和每月轨迹的平均 F1 分数分别为 74.4%、80.9%、85.7%。 这很重要,因为这意味着每个轨迹的一次签到足以在高达 85% 的时间内正确预测用户的身份。 请记住,对于 d = 1,欧氏距离变为减法,因此 k-NN 分类类似于应用于场地 ID 的简单阈值操作。同样清楚的是,性能随着 d 的增加而降低的程度与时间间隔反向相关。 此外,时间间隔越短,分类性能越差。 这一观察结果适用于所有数据集。 我们认为这种行为可能是由于在足够长的时间段内,人类流动模式是高度可预测的。
最后,值得一提的是,除了上一节中提出的方法之外,我们还尝试了启发式方法。 更具体地说,由于我们已经证明不同的用户访问不同的地点,因此根据轨迹之间的共同地点对轨迹进行分类更加直接,即在 k-NN 分类器中用 Jaccard 距离替换欧几里德距离并使用原始 轨迹而不是样本。 我们获得的结果与我们在图 4 中报告的结果非常相似,但是以更高的计算成本为代价。 这可以归因于这样一个事实,即在某些情况下,轨迹可能会变得很长,达到数百个地点。 此外,我们还尝试了 max 以外的不同轨迹采样方法,例如 min 和 median。 然而,max 始终优于其他数据,这是数据预处理方式所固有的,这自然导致 max 场地 ID 很可能成为用户的唯一标识符,如图所示。总之,所获得的结果证实了我们的说法,即由于场地在用户中是高度独特的,因此对原始数据应用简单的启发式方法足以在高达 85% 的时间内解决 TUL。
Performance vs. time interval
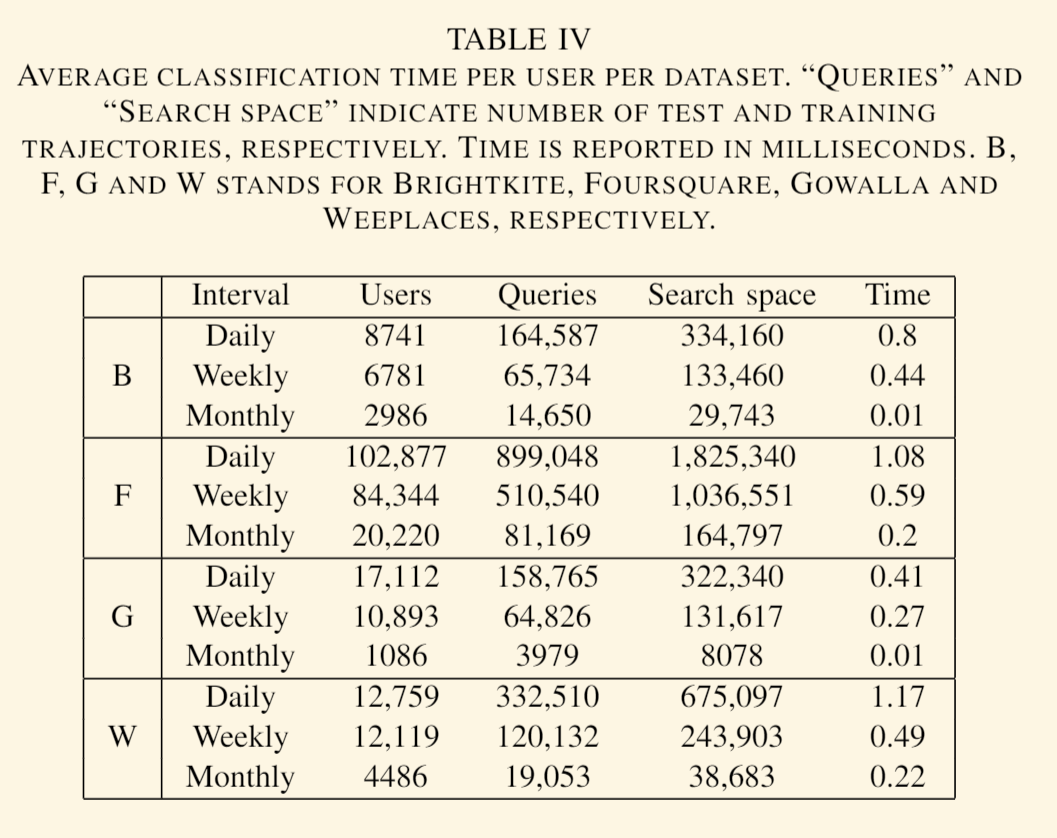
在图 6 中,我们绘制了所有数据集上的分类性能与时间间隔的关系图。 为了隔离时间间隔对性能的影响,我们将用户数固定为每个数据集所有时间间隔中最小的用户数。 获得的结果主要支持先前实验的结果,因为性能和时间间隔长度直接相关。
Scaling up TUL
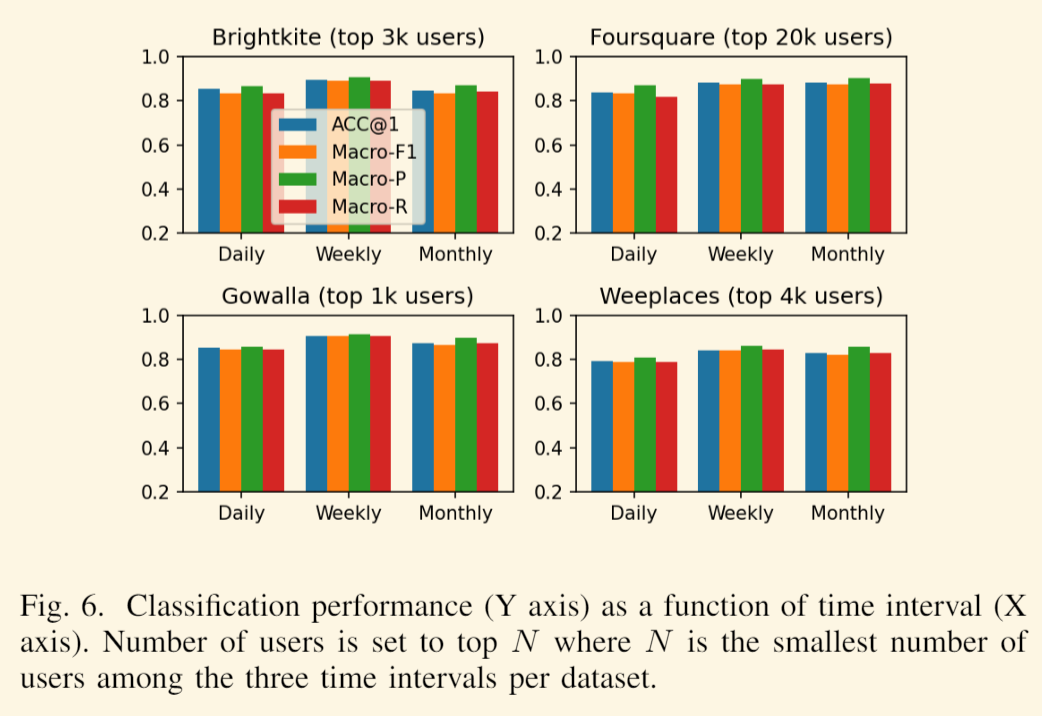
在图 5 中,我们绘制了针对越来越多的用户的分类性能。 用户数量从 10 开始增加一个数量级。值得注意的是,增加用户数量意味着增加轨迹数量,从而增加 k-NN 算法的搜索空间。 因此,预计分类性能会随着用户数量的增加而下降,如图 5 所示。此外,在表 IV 中,我们报告了具有 2.4 GHz 处理能力和 32 GB RAM 的单台机器的平均分类时间。 对于最大的数据集(Foursquare daily),平均而言,每个用户的分类大约需要 1.1 毫秒(三个运行的平均值)。 请记住,时间在很大程度上取决于查询数量和搜索空间,在本例中分别为≈900k 和 1.8M。值得注意的是,据我们所知,我们是第一个将 TUL 扩展到超过 10 万用户的公司。 详见图7。

Comparison with state-of-the-art
从角度来看,我们在表 III 中将我们的结果与所有四个数据集上的最新结果进行了比较。 我们引用了各自出版物中报告的结果。 为了公平比较,我们比较时使用每周轨迹,否则使用每日轨迹。 此外,我们保留了顶部 |U| 的轨迹 以前作品中报告的用户。 平均而言,我们的结果 (Macro-F1) 在 Brightkite、Foursquare、Gowalla 和 Weeplaces 上分别比最先进的结果好 2.6%、1.2%、4.7% 和 42%。总之,所获得的结果表明,简单的启发式方法不仅足以解决 TUL,而且优于使用复杂深度学习模型的最先进作品。

Discussion
虽然乍一看简单的启发式算法胜过深度模型似乎有违直觉,但我们已经清楚地证明了访问模式在用户中是高度独特的,即不同的用户访问几乎完全不同的场所,通过广泛采用的 TUL 评估设置进行放大,其中轨迹是从随机选择的用户(通常是最活跃的用户)中使用从活跃在不同城市和/或国家的用户的社交媒体帐户中收集的签到数据集绘制的。 不同城市的用户访问完全不同的地点,因此他们的轨迹很容易使用简单的启发式方法区分,正如我们在实验部分所展示的那样。
仍未完全回答的问题是:为什么每个子轨迹的最大场地 ID 是一个有效的特征? 换句话说,为什么具有最大 ID 值的场所(在同一用户在同一子轨迹中访问过的场所中)是用户身份的有效指标? 答案很简单,在于数据预处理的方式,即首先对所有用户的签到记录进行匿名处理(用户 ID 和场地 ID 替换为序列号)。 然后,按用户 ID、场地 ID 和时间戳排序。 这意味着,给定一个用户,他们唯一的场所(例如,家)被分配的 ID(序列号)的价值高于其他用户访问过的场所(例如,餐馆)。 因此,通过将最大算子应用于给定子轨迹中用户访问过的所有场地ID,等于在所有用户中找到该用户唯一的单个场地。 这样的地点可以是家(除非两个或多个用户共享同一所房子,否则这对用户来说是唯一的),在给定足够长的时间间隔的情况下,它很可能包含在给定用户的大多数子轨迹中。 事实上,这并不总是正确的,否则我们的分类结果将是完美的。
我们认为,鉴于当前的 TUL 评估设置,将匿名轨迹链接到他们的用户类似于对不同颜色阴影的图像块进行分类。 色度分类是一项简单的任务,可以通过像素阈值处理来完成,而不需要具有数百万学习参数的复杂视觉模型。 同样,由于不同的用户访问不同的场所,解决 TUL 不需要学习捕获单个用户独有的复杂时空移动模式的表示。 而是找到每个用户唯一的场所(例如,家)。
值得注意的是,我们知道之前的少数作品对仅限于单个城市(东京和/或纽约)的数据进行了实验。 然而,在这些相同的工作中,在某些情况下,在从不同城市甚至国家收集的其他签到数据集上评估了所提出的算法。
Summary
在本文中,我们认为由于访问模式在用户中是高度独特的 ,TUL 可以通过直接应用于原始数据的简单启发式方法来解决。 我们通过对四个真实世界的数据集(Brightkite、Foursquare、Gowalla 和 Weeplaces)进行广泛分析,从经验上验证了我们的论点,并证明启发式方法不仅足以解决 TUL,而且优于使用复杂模型的最新方法。 此外,使用非参数分类器,我们将 TUL 扩展到超过 100k 用户,这比最先进的增加了三个数量级。
虽然需要将我们的结果与最先进的方法进行比较,但重要的是要提醒读者,我们在本文中的目的不是提出一种新算法来解决 TUL,而是邀请研究界重新思考现有的解决方案 、数据集和评估设置,同时更好地关注一般人类流动数据和特定社会签到数据的统计和性质。















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









