






目录
一 赛题理解
1 数据集
赛题链接为2023 iFLYTEK A.I.开发者大赛-讯飞开放平台。
本次比赛提供的数据集包括train.csv和test.csv两个csv格式文件。train.csv内包含62万个样本,每个样本除uuid外有11个特征,也给出了用户样本的标签即target参数。test.csv内包含20万个样本,每个样本仅提供除uuid以外的11个特征,我们需要从这些特征来预测该用户样本的target参数,判断是否为新增用户,因此该问题为有监督二分类问题。
初步肉眼观察数据集,下面简单说说我对各个特征的理解和思考:
- uuid:为用户样本的序号,表中按顺序排列,肯定与用户标签无关,数据预处理时直接删除
- eid:基本无序的数值类型,需要后续使用热力图进行数据分析才能观察到蕴含的规律
- udmap:字典类型,可以考虑内部分析各个key的数值分布和关联以及各个key出现的频次,也可以考虑外部分析,将字典拆成几条特征,用热力图分析与其他特征的关联性。此外要注意该特征有部分数据缺失,在特征分析时注意调整
- common_ts:是个数值相当大的特征,感觉很像对时间的表述,后续一定要进行特征工程将其化为数据较小且分布较为合理的特征
- x1~x8:为匿名处理的字段,需要分清为类别特征(如x1)还是数值特征(如x4),数值类型可以绘制箱线图进行可视化,类别类型可以绘制直方图进行可视化,通过可视化进行深入分析
- target:为用户样本的标签,非0即1,是二分类问题,数据分析时可以绘制热力图分析其他特征与标签的关联性,并执行相应的数据预处理工作。另外通过排序发现,target=0的样本占53万条,target=1的样本仅占11万条,稍有分布不均,可以考虑进行采样上的优化
2 评价指标
本次比赛的评价指标采用F1_score,下面简单说明我对F1_score的理解。
首先要说明的是混淆矩阵,即Confusion Matrix,下图是简单的二分类问题混淆矩阵,对比预测值和真实值,可以分为四种情况,分别是TP、TN、FP、FN,四个关键概念关注的是不同的情况,记忆时可以从后往前,如TP表示True Positives,即预测为正例(Positives),实际也为正例,说明预测正确(True)。
- TP:True Positives,预测为正样本,实际也为正样本,预测正确
- TN:True Negatives,预测为负样本,实际也是负样本,预测正确
- FP:False Positives,预测为正样本,实际却为负样本,预测错误
- FN:False Negatives,预测为负样本,实际却为正样本,预测错误

了解完上述概念后,下面引出常用的两个简单评价指标,并以识别犯人为例说明(假设犯人为正样本):
- Precision(P):精确率,
,关注的是预测为正样本中预测正确的百分比,即我说你是犯人,你就一定是犯人,宁缺毋滥。
- Recall(R):召回率,
这两个指标往往是相互矛盾的,举两个极端例子:
- 宁缺毋滥:仅将最自信的正样本预测为正样本,其他统统认为是负样本(只指认最像犯人的人,其他全认为是好人),此时Precision达到1,但Recall几乎接近0。
- 宁滥勿缺:所有样本都预测为正样本(所有人都指认成犯人),此时正样本确实全给识别出来了,Recall达到1,但Precision往往就不高了。
因此需要引入其他指标进行评价,即F1_score,F1_score为P、R的调和平均数,二者有一个小F1_score就小,只有二者均大时才大,公式如下:
二 解题过程
1 Baseline
Baseline代码请参考AI夏令营第三期 - 用户新增预测挑战赛教程 - 飞书云文档 (feishu.cn)
整体思路如下,这也是数据分析问题的简单思路:
- 导入库并读取数据:常用pandas库和numpy库进行数据的导入
- 特征工程:由上述分析,至少也需要对udmap特征和common_ts特征进行处理,以转换成合理的可以用于训练的数值类型数据。对于udmap特征,最直接的方法就是将9个键(key1-key9)拆成9个特征,即人为地进行onehot编码;对于common_ts特征,考虑将其转换成日期或者小时等的特征再进行分析
- 模型训练与预测:在该Baseline中采用的是决策树的模型,忽略具体数学原理,只用调用sklearn库进行训练和预测即可,当然训练时注意舍去特征工程处理之前的udmap和common_ts特征,加上经过特征工程初步处理的其他特征
将该Baseline进行运行和提交,得到的分数大约在0.62670左右。
2 基本准备
在所有工程正式进行之前,需要先导入相关的库,并读取训练集和测试集的数据,为划分测试集做好准备。机器学习问题中常用且通用的库有以下几个:
- pandas库:用于数据导入、分析和处理
- numpy库:用于科学计算和数据多维操作
- matplotlib库:用于可视化和数据分析
- 其他算法库:如sklearn库及imblearn库等后续需要用到相关函数或算法时再进行导入。
读取数据直接使用pandas库的read_csv()函数即可,代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
print('相关库导入完毕')
train_data = pd.read_csv(r'..\数据\train.csv')
test_data = pd.read_csv(r'..\数据\test.csv')
vali_data = None3 数据可视化与分析
在进行特征工程之前需要进行数据可视化,以判断各个特征的分布规律、特征和特征之间的联系以及特征和标签之间的联系。Python中可供可视化的库和函数都比较丰富,常用的库主要包括有matplotlib库和seaborn库,可视化的方法也多种多样,应该视具体特征特性而定,根据赛题理解部分对特征特性的分析,我们依次进行了以下数据可视化的操作。
- 相关性分析:相关性分析采用的是seaborn库的heatmap()函数,该函数返回热力图表示特征与特征的相关性以及特征和标签的相关性,可以为后期特征工程中的特征融合和降维提供灵感和方案,该部分的代码和成果示例如下:
import matplotlib.pyplot as plt import seaborn as sns train_data = pd.read_csv(r'..\数据\train.csv', index_col=0) test_data = pd.read_csv(r'..\数据\test.csv', index_col=0) sns.heatmap(train_data.drop(['udmap', 'common_ts', 'uuid'], axis=1).corr().abs(), cmap='YlOrRd')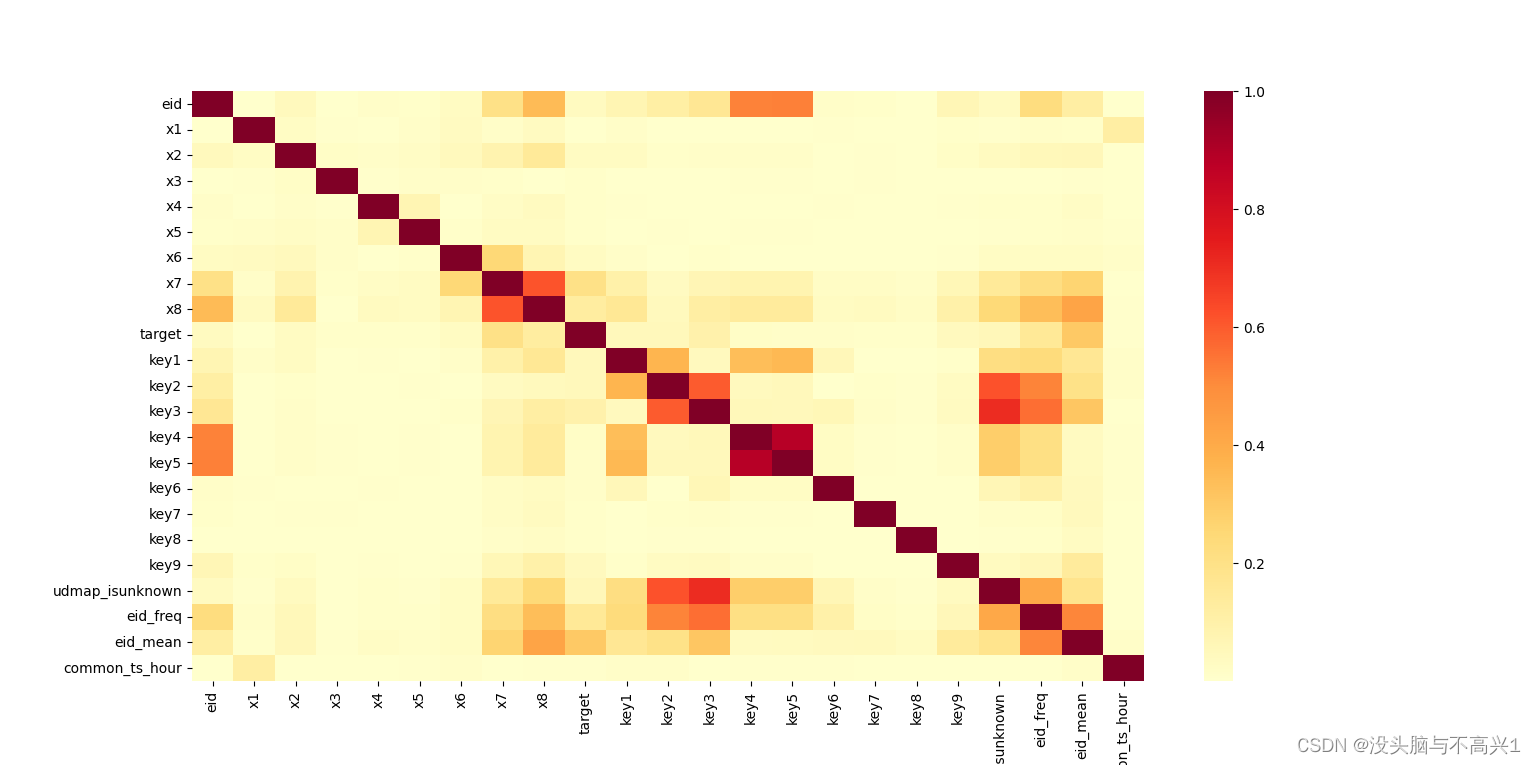
- 类别型变量:对于类别型变量,我们采用的是seaborn库的barplot()函数,该函数返回的是横坐标为特征类别,纵坐标为该特征类别对应标签的均值和可靠性。通过观察柱状图的高度分布,可以提取出分段的特征,如下图中x1=2时对应target的均值较高,且可靠性也较强,因此可以设置新的特征,当x1=2时对应特征值为1,x1≠2时对应特征值为0,此部分特征工程代码在第5节展示,下面以x1为例展示数据分析的代码和成果,类似的eid、x2、x6、x7、x8等变量也可以采取相同的处理方案:
sns.barplot(x='x1', y='target', data=train_data)
- 数值型变量:对于数值型变量,由于特征值特别多,如果仍然采样类别型变量的柱状图表示会使可视化结果冗余且提取不出关键信息,因此换用seaborn库的boxplot()函数。该函数展示的是横坐标为target类别,纵坐标为该特征分布规律的箱线图,从上至下五条线分别表示绝大多数样本范围上限、75%范围界限、50%范围界限、25%范围界限和绝大多数样本范围下限,上下限之外的样本点可以视作异常数据,在特征工程中进行排除。除此之外,通过箱线图可以直观看出特征分布规律以及不同target下的特征值范围,为后续建立新的特征提供思路,下面以x5特征为例展示代码和成果,类似的x3、x4、x5、各个key特征均可以采用类似的处理思路:sns.boxplot(x = 'target', y = 'x5', data = train_data)
-

4 异常样本处理
特征工程的第一步往往是进行数据清洗,其中很重要的一项就是进行异常样本的处理,因为对于某些算法,受异常值或离群值的影响,模型性能会大幅下降。目前我们处理异常值主要是根据上述数据可视化的分析结果,对类别型变量则剔除特征值特别少的样本类别,对数值型变量则剔除特征值特别离群的样本。
下面以eid特征为例,通过对柱状图的观察,我们可以发现eid特征值在列表[6,7,16,17,18,22,23,24]内时,target均值达到了很极端的0,使用value_counts()函数进行统计发现这些特征值对应的样本均在100条以下,不仅对模型训练起不到太大帮助,甚至可能会导致极端的影响,因此我们将其进行索引并剔除,以最大可能地消除异常样本的影响。其余特征也可以根据数据可视化的结果进行适当的异常处理。

eid_error = [6,7,16,17,18,22,23,24]
train_data = train_data[(True^train_data['eid'].isin(eid_error))]
test_data = test_data[(True^test_data['eid'].isin(eid_error))]
train_data.fillna(0)
test_data.fillna(0)5 特征工程
特征工程是整个机器学习问题中最重要的一项工程,如果不能很好地提取特征之间的内在规律,即使选取的算法特别契合特别优秀,超参数调节也特别完善,最终也不能达到理想的结果,而且也具有较大的过拟合和欠拟合的风险。特征工程指的是把原始数据转变为模型训练数据的过程,目的是获取更好的训练数据特征,特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。目前我们进行的特征工程除了第4节所说的异常样本处理和第6节说的采样,主要可以分为以下三种:
- 针对非常规特征的特征提取:本竞赛中非常规特征有两个,第一个是udmap特征,该特征表示为字典,需要通过编程提取出key1~key9作为新的特征,提取方式在Baseline中已经详细叙述,可以参考Baseline部分提供的链接,此处不再赘述。第二个是common_ts特征,该特征虽然是以数字形式表示的,但是数量级过大不便作为训练用的特征,需要提取出其中的内在逻辑,通过经验可以判断出这是时间特征,使用pandas库的to_datatime()即可转换为直观的时间戳,再通过.dt.year等属性即可以提取出年月日时分秒作为新的特征,由于年月秒三者对target标签的预测几乎没有帮助,下面代码中直接进行了注释。
##udmap特征: #提取9个key并添加为9个特征 def udmap_onethot(d): v = np.zeros(9) if d == 'unknown': return v d = eval(d) for i in range(1, 10): if 'key' + str(i) in d: v[i-1] = d['key' + str(i)] return v train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot))) test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot))) train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)] test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)] train_data = pd.concat([train_data, train_udmap_df], axis=1) test_data = pd.concat([test_data, test_udmap_df], axis=1) #添加关于udmap是否为unknow的特征 train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int) test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int) ##common_ts特征: #提取并替换特征为时间戳 train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms') test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms') #添加年特征 ''' train_data['year'] = train_data['common_ts'].dt.year test_data['year'] = test_data['common_ts'].dt.year ''' #添加月特征 ''' train_data['month'] = train_data['common_ts'].dt.month test_data['month'] = test_data['common_ts'].dt.month ''' #添加日特征 train_data['day'] = train_data['common_ts'].dt.day test_data['day'] = test_data['common_ts'].dt.day #添加时特征 train_data['hour'] = train_data['common_ts'].dt.hour test_data['hour'] = test_data['common_ts'].dt.hour #添加分特征 train_data['minute'] = train_data['common_ts'].dt.minute test_data['minute'] = test_data['common_ts'].dt.minute #添加秒特征 ''' train_data['second'] = train_data['common_ts'].dt.second test_data['second'] = test_data['common_ts'].dt.second - 特征频次和对应标签均值提取:对于eid、x1-x8这些特征,原始数据分布比较不规律,不能展现出其与target之间的内在逻辑,可以通过value_counts()方法统计各个特征值出现的频次,再使用groupby()函数计算每个特征值对应的target标签均值即预测target=1的概率,这样可以稍微提取出其中的内在逻辑,实践证明分数稍有提升,以x1为例代码展示如下:
#添加频次特征 train_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts()) test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts()) #添加不同值对应标签平均值的特征 train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean()) test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean()) - 特征分段处理:同样以x1为例,正如上述数据分析所观察到,x1=2时对应target的均值较高,且可靠性也较强,因此可以设置新的特征,当x1=2时对应特征值为1,x1≠2时对应特征值为0,类似的eid特征、时间特征等也可以用同样的方法进行处理,可视化与代码示例如下:

train_data['x1=2'] = (train_data['x1'] == 2).astype(int)
test_data['x1=2'] = (test_data['x1'] == 2).astype(int)
6 数据整理与采样
6.1 验证集划分
使用sklearn的交叉验证相关函数如cross_val_predict()自然可以方便观察到模型的预测结果和模型性能,但是考虑到交叉验证前可能进行上采样以平衡数据集,这时候交叉验证时验证集内的样本可能大部分都是训练集样本经过上采样生成的,交叉验证得到的结果可能会失去可靠性。因此有必要提前就划分开验证集,并且将此部分验证集视为独立的部分,不再因为采样或其他原因而变动,下面是验证集划分的代码。此时train_data为训练集,vali_data为验证集。
from sklearn.model_selection import train_test_split
train_features, vali_features, train_target, vali_target = train_test_split(
train_data.drop(['target'], axis=1), train_data['target'], test_size = 0.2)
train_data = pd.concat([train_features, train_target], axis=1)
vali_data = pd.concat([vali_features, vali_target], axis=1)6.2 提取特征和标签
一般而言,可以使用train_data.drop(...)函数来抛弃不希望参与训练的特征或标签,但是如果后续需要更改特征工程,有新的特征被建立或抛弃,就需要逐一更改drop()函数内的列表,难免会有所缺漏。此时可以先用两个变量train_features和train_target分别储存需要参与训练的特征和标签,方便后续直接调用,使程序更加简洁,代码如下。
train_features = train_data.drop(['uuid', 'udmap', 'common_ts', 'target'], axis=1)
train_target = train_data['target']
test_features = test_data.drop(['uuid', 'udmap', 'common_ts'], axis=1)
if not vali_data is None:
vali_features = vali_data.drop(['uuid', 'udmap', 'common_ts', 'target'], axis=1)
vali_target = vali_data['target']6.3 采样平衡数据集
正如上述分析所说,本案例中样本是非常不均衡的,训练集中标签为0的和标签为1的样本大致占比已经到了5:1,如果不进行适当的采样处理,最终模型会更加倾向于预测样本为标签0,此时标签1的样本预测召回率会大大降低,导致F1_score也会较低。同时不均衡的样本可能会对后续的模型调优和交叉验证等造成较大影响,会造成较大过拟合风险和优化不明显现象,因此必须选用合适的采样方式对数据集进行平衡。
本案例中待采样对象为train_data即训练集,选择的采样方法较为多样,需要一一测试以选择较优较合适的算法。imblearn库提供了非常丰富的不平衡数据集采样器和采样函数,主要包括上采样、下采样和混合采样三大类。上采样简单理解就是将较少数类别样本数提升,本案例中为标签1,库中提供的类有RandomOverSampler()、SMOTE()、BorderlineSMOTE()、 SVMSMOTE()、ADASYN()等等;下采样简单理解就是将较多数类别样本数减少,本案例中为标签0,库中提供的类有RandomUnderSampler()、NearMiss()、TomekLinks()、ENN()、RENN()、CondensedNearestNeighbour()、OneSidedSelection()、NeighbourhoodCleaningRule()、InstanceHardnessThreshold()等等;混合采样即为上采样和下采样的结合,库中提供的类有SMOTETomek()、SMOTEENN()等等。由于算法过多,原理也较为复杂,此处不对原理做过多介绍,可以参考文章:
Python sklearn 实现过采样和欠采样_sklearn 过采样_WANG_DDD的博客-CSDN博客
在本次竞赛中,我们考虑到后续采用的模型性能(召回率较高但是精确率过低)选取了能够提升精确率的采样方式,即随机上采样RandomUnderSampler(),结果证明精确率有较大提高,召回率稍有下降,采样算法的选取可以看第7.3小节,代码如下:
from imblearn.over_sampling import RandomOverSampler
reSampler = RandomOverSampler()
train_features, train_target = reSampler.fit_resample(train_features, train_target)
7 交叉验证与模型调优
7.1 模型选择
本次赛题为机器学习中有监督学习二分类任务,因此模型可以选用相关的分类模型,例如决策树、KNN、SVM、随机森林等等。在Python中调用这些模型也相当容易,直接使用sklearn库进行导入即可,以决策树为例,代码示例如下:
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()7.2 超参数确定
好的模型固然重要,但是模型选取后超参数才是模型的核心,例如随机森林,经过我们对1680组参数的试验,超参数组合优秀时,F1_score可以达到0.764,但是超参数组合糟糕时,F1_score也能低到惊人的0.392。下面就以随机森林为例说明调参方法,当然要说明的是,调参(炼金)过程需要大量的时间和耐心,建议在程序跑完之前不要乱动,否则报错了哭都来不及。
随机森林里比较重要的几个参数有n_estimators、max_depth、min_samples_leaf、min_samples_split和max_features,这些参数各自代表的含义也各不相同,实际意义以及对模型的影响也有所偏差,具体内涵和算法原理可以参考博客:sklearn 随机森林(分类器、回归器)的重要参数、属性、方法理解_sklearn 随机森林 分类器参数_VariableX的博客-CSDN博客
如果要在Python里实现调参,一种方法是直接使用sklearn的GridSearchCV()函数,但是和第6.1节说的理由一样,考虑到采样,使用交叉验证反而不能够正确显示结果,因此我们选择直接用for循环的嵌套暴力求解,原理也比较简单,下面直接展示代码:
from sklearn.ensemble import RandomForestClassifier
n_estimators_list = [50, 60, 70, 80]
max_depth_list = [3, 5, 8, 15, 25, 30, None]
min_samples_leaf_list = [1, 2, 5, 10]
min_samples_split_list = [2, 5, 10, 15, 100]
max_features_list = ['log2', 'sqrt', None]
for n_estimators in n_estimators_list:
for max_depth in max_depth_list:
for min_samples_leaf in min_samples_leaf_list:
for min_samples_split in min_samples_split_list:
for max_features in max_features_list:
clf = RandomForestClassifier(n_estimators=n_estimators,criterion='gini',
max_depth=max_depth,min_samples_leaf=min_samples_leaf,
min_samples_split=min_samples_split,max_features=max_features,
class_weight='balanced',oob_score=True)
clf.fit(train_features,train_target)
vali_pred = clf.predict(vali_features)
print(str(clf))
print(classification_report(vali_target, vali_pred, digits=3))7.3 采样与模型结合
在模型以及模型在本案例中的最优超参数选择完毕后,我们通过遍历采样方法和模型,选取出二者最合适的结合方法,将模型的性能进行最大化的提升。所测试的采样方式即为第6.3节中提及的imblearn库中的相关采样函数,所测试的模型即为第7.1节中提及的几个模型,测试的评价方法采用了sklearn库中的classification_report()函数,对每一种组合方式中标签为0和标签为1样本的精确率、召回率和F1_score进行观察。由于本次竞赛采取的评价指标为F1_score,本案例的样本又相当不均衡即标签为1的样本数很少,因此选取的主要评价参数还是标签为1样本的F1_score,下面是代码示例:
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
from imblearn.ensemble import EasyEnsembleClassifier
from imblearn.ensemble import BalancedBaggingClassifier
model_list = [SGDClassifier(max_iter=10), DecisionTreeClassifier(),
MultinomialNB(), RandomForestClassifier(n_estimators=5),
EasyEnsembleClassifier(n_estimators=5, estimator = DecisionTreeClassifier()),
EasyEnsembleClassifier(n_estimators=10, estimator = DecisionTreeClassifier()),
EasyEnsembleClassifier(n_estimators=15, estimator = DecisionTreeClassifier()),
EasyEnsembleClassifier(n_estimators=20, estimator = DecisionTreeClassifier()),
BalancedBaggingClassifier(n_estimators=5, estimator = DecisionTreeClassifier()),
BalancedBaggingClassifier(n_estimators=10, estimator = DecisionTreeClassifier()),
BalancedBaggingClassifier(n_estimators=15, estimator = DecisionTreeClassifier()),
BalancedBaggingClassifier(n_estimators=20, estimator = DecisionTreeClassifier())]
#采样方式
from imblearn.over_sampling import ADASYN
from imblearn.over_sampling import BorderlineSMOTE
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import InstanceHardnessThreshold
from imblearn.under_sampling import NearMiss
from imblearn.under_sampling import RandomUnderSampler
reSampler_list = [ADASYN(), BorderlineSMOTE(), RandomOverSampler(),
InstanceHardnessThreshold(estimator=DecisionTreeClassifier()),
NearMiss(version = 3), RandomUnderSampler()]
#依次遍历寻优
for reSampler in reSampler_list:
for model in model_list:
print('{}--{}:'.format(str(reSampler), str(model)))
train_features0, train_target0 = reSampler.fit_resample(train_features, train_target)
model.fit(train_features0,train_target0)
vali_pred = model.predict(vali_features)
print(classification_report(vali_target, vali_pred, digits=3))从运行结果可以看出,采样算法reSampler为RandomOverSampler(),分类模型model为BalancedBaggingClassifier(estimator=DecisionTreeClassifier(), n_estimators=20)时标签为1样本的F1_score较高,因此可以将此策略对应到上面的第6.3节和第7.1节的描述中。
8 模型应用与数据保存
上述工程完毕后,最后要进行的就是简单的模型训练和预测过程了,此过程相对简单,调用sklearn库中的fit()函数和predict()函数即可,模型则采用第7小节验证出的最优模型,此处不再赘述。最后使用to_csv()函数将预测结果导出为csv文件,顺便导出train_data和test_data以便于观察,代码如下:
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(train_features,train_target)
pd.DataFrame({
'uuid': test_data['uuid'],
'target': clf.predict(test_features)
}).to_csv(r'submit.csv', index=None)
train_data.to_csv(r'..\数据\train1.csv')
test_data.to_csv(r'..\数据\test1.csv')













 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









