







1.项目背景
在当今社会,随着人们对健康和营养的日益关注,深入了解食品的营养成分及其对人体的影响变得越来越重要,本研究采用了多维度的分析方法,包括营养成分比较分析、统计检验、营养密度分析和高斯混合模型(GMM)聚类分析,揭示了不同食品类别在营养成分上的显著差异,以及各种营养素之间复杂的相互关系。
2.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import ipywidgets as widgets
from IPython.display import display, clear_output
from pyecharts import options as opts
from pyecharts.charts import Radar
from pyecharts.globals import ThemeType
from scipy.stats import spearmanr
from scipy import stats
from sklearn.preprocessing import StandardScaler
from sklearn.mixture import GaussianMixture
from sklearn.decomposition import PCA
data = pd.read_csv('/home/mw/project/翻译后的食品营养成分数据.csv')
3.数据预览及预处理
# 查看数据信息
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1171 entries, 0 to 1170
Data columns (total 59 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 食品名称 1171 non-null object
1 类别名称 1171 non-null object
2 钙 1146 non-null float64
3 热量 1171 non-null int64
4 碳水化合物 1171 non-null int64
5 胆固醇 1116 non-null float64
6 铜 1092 non-null float64
7 脂肪 1171 non-null int64
8 纤维 1073 non-null float64
9 叶酸 1069 non-null float64
10 铁 1151 non-null float64
11 镁 1111 non-null float64
12 单不饱和脂肪 1063 non-null float64
13 净碳水化合物 1170 non-null float64
14 Omega-3 DHA(二十二碳六烯酸) 900 non-null float64
15 Omega-3 DPA(二十二碳五烯酸) 893 non-null float64
16 Omega-3 EPA(二十碳五烯酸) 901 non-null float64
17 磷 1124 non-null float64
18 多不饱和脂肪 1063 non-null float64
19 钾 1127 non-null float64
20 蛋白质 1171 non-null int64
21 饱和脂肪 1091 non-null float64
22 硒 1018 non-null float64
23 钠 1150 non-null float64
24 反式脂肪 630 non-null float64
25 维生素A 1115 non-null float64
26 维生素A RAE(视黄醇活性当量) 1054 non-null float64
27 维生素B1(硫胺素) 1113 non-null float64
28 维生素B12 1081 non-null float64
29 维生素B2(核黄素) 1114 non-null float64
30 维生素B3(烟酸) 1113 non-null float64
31 维生素B5(泛酸) 975 non-null float64
32 维生素B6(吡哆醇) 1089 non-null float64
33 维生素C 1121 non-null float64
34 锌 1106 non-null float64
35 胆碱 730 non-null float64
36 果糖 301 non-null float64
37 组氨酸 709 non-null float64
38 异亮氨酸 713 non-null float64
39 亮氨酸 713 non-null float64
40 赖氨酸 721 non-null float64
41 锰 1012 non-null float64
42 甲硫氨酸 718 non-null float64
43 苯丙氨酸 710 non-null float64
44 淀粉 198 non-null float64
45 糖 871 non-null float64
46 苏氨酸 712 non-null float64
47 色氨酸 710 non-null float64
48 缬氨酸 713 non-null float64
49 维生素D 826 non-null float64
50 维生素E 814 non-null float64
51 维生素K 789 non-null float64
52 Omega-3 ALA(α-亚麻酸) 176 non-null float64
53 Omega-6 二十碳二烯酸 264 non-null float64
54 Omega-6 γ-亚麻酸 170 non-null float64
55 Omega-3 二十碳三烯酸 113 non-null float64
56 Omega-6 二十碳四烯酸 118 non-null float64
57 Omega-6 亚油酸 140 non-null float64
58 Omega-6 花生四烯酸 1 non-null float64
dtypes: float64(53), int64(4), object(2)
memory usage: 539.9+ KB
数据集包含1171条记录和59个字段,有些字段存在缺失值,数据纬度是比较大的,结合“该营养素是否为人类必需”、“该营养素是否提供能量”对数据集统计的营养素进行了分类,重新构建新的数据。
| 分类 | 必需且供给充足 | 必需但不供给充足 | 非必需且供给充足 | 非必需但不供给充足 |
|---|---|---|---|---|
| 宏量营养素 | ||||
| 蛋白质 (含氨基酸: Histidine, Isoleucine, Leucine, Lysine, Methionine, Phenylalanine, Threonine, Tryptophan, Valine) | √ | |||
| 碳水化合物 (Carbs, Fiber, Starch, Sugar, Fructose, Net carbs) | √ | |||
| 脂肪 (Fats, Monounsaturated Fat, Polyunsaturated fat, Saturated Fat, Omega-3 - ALA, Omega-6 - Linoleic acid) | √ | |||
| 反式脂肪 (Trans Fat) | √ | |||
| 微量营养素 | ||||
| 钙 (Calcium) | √ | |||
| 铜 (Copper) | √ | |||
| 铁 (Iron) | √ | |||
| 镁 (Magnesium) | √ | |||
| 锰 (Manganese) | √ | |||
| 磷 (Phosphorus) | √ | |||
| 钾 (Potassium) | √ | |||
| 硒 (Selenium) | √ | |||
| 锌 (Zinc) | √ | |||
| 维生素A (Vitamin A, Vitamin A RAE) | √ | |||
| 维生素B群 (Vitamin B1, Vitamin B2, Vitamin B3, Vitamin B5, Vitamin B6, Vitamin B12, Folate, Choline) | √ | |||
| 维生素C (Vitamin C) | √ | |||
| 维生素D (Vitamin D) | √ | |||
| 维生素E (Vitamin E) | √ | |||
| 维生素K (Vitamin K) | √ | |||
| Omega-3 (DHA, DPA, EPA) | √ | |||
| Omega-3 (ALA) | √ | |||
| Omega-6 (Linoleic acid) | √ | |||
| Omega-6 (其他) | √ | |||
| 胆固醇 (Cholesterol) | √ | |||
| 钠 (Sodium) | √ |
说明:
-
宏量营养素: 这些是人体需要大量摄入的营养素, 用于提供能量和构建身体组织。
- 蛋白质
- 碳水化合物(包括纤维、淀粉、糖)
- 脂肪(包括饱和脂肪、单不饱和脂肪、多不饱和脂肪、反式脂肪、Omega-3 和 Omega-6 脂肪酸等)
-
微量营养素: 这些是人体只需要少量的营养素,主要用于调节生理过程。
- 维生素(如维生素 A、B群、C、D、E、K 等)
- 矿物质(如钙、镁、锌、铁、锰等)
-
宏量营养素的主要目的是提供能量。碳水化合物、蛋白质和脂肪是三种主要提供能量的营养素。
-
微量营养素的维生素和矿物质则主要用于促进生理过程。
-
反式脂肪被认为是有害的脂肪类型,应该尽量避免摄入。
-
胆固醇: 虽然人体自我调节胆固醇, 但胆固醇摄入量过多时可能会提高血胆固醇水平。对某些人群(如有高胆固醇血症风险的人)仍然需要关注摄入量。
-
钠: 钠是必需的电解质, 对维持正常的生理功能至关重要。然而, 由于现代饮食中钠摄入量通常过高,导致高血压问题,钠应视为微量营养素并限制摄入量。
combined_nutrition_data = pd.DataFrame()
combined_nutrition_data['食品名称'] = data['食品名称']
combined_nutrition_data['类别名称'] = data['类别名称']
combined_nutrition_data['热量'] = data['热量']
# 蛋白质 (含氨基酸)
amino_acids = ['组氨酸', '异亮氨酸', '亮氨酸', '赖氨酸', '甲硫氨酸',
'苯丙氨酸', '苏氨酸', '色氨酸', '缬氨酸']
combined_nutrition_data['蛋白质'] = data[['蛋白质'] + amino_acids].sum(axis=1, min_count=1)
# 碳水化合物
carbs = ['碳水化合物', '纤维', '淀粉', '糖', '果糖', '净碳水化合物']
combined_nutrition_data['碳水化合物'] = data[carbs].sum(axis=1, min_count=1)
# 脂肪
fats = ['脂肪', '单不饱和脂肪', '多不饱和脂肪', '饱和脂肪',
'Omega-3 ALA(α-亚麻酸)', 'Omega-6 亚油酸']
combined_nutrition_data['脂肪'] = data[fats].sum(axis=1, min_count=1)
# 反式脂肪
combined_nutrition_data['反式脂肪'] = data['反式脂肪']
# 矿物质
minerals = ['钙', '铜', '铁', '镁', '锰', '磷',
'钾', '硒', '锌', '钠']
for mineral in minerals:
combined_nutrition_data[mineral] = data[mineral]
# 维生素A
combined_nutrition_data['维生素A'] = data[['维生素A', '维生素A RAE(视黄醇活性当量)']].sum(axis=1, min_count=1)
# 维生素B群
vitamin_b = ['维生素B1(硫胺素)', '维生素B2(核黄素)', '维生素B3(烟酸)', '维生素B5(泛酸)',
'维生素B6(吡哆醇)', '维生素B12', '叶酸', '胆碱']
combined_nutrition_data['维生素B'] = data[vitamin_b].sum(axis=1, min_count=1)
# 其他维生素
for vit in ['维生素C', '维生素D', '维生素E', '维生素K']:
combined_nutrition_data[vit] = data[vit]
# Omega-3
combined_nutrition_data['Omega-3 (DHA, DPA, EPA)'] = data[['Omega-3 DHA(二十二碳六烯酸)', 'Omega-3 DPA(二十二碳五烯酸)', 'Omega-3 EPA(二十碳五烯酸)']].sum(axis=1, min_count=1)
combined_nutrition_data['Omega-3 (ALA)'] = data['Omega-3 ALA(α-亚麻酸)']
# Omega-6
combined_nutrition_data['Omega-6 (亚油酸)'] = data['Omega-6 亚油酸']
omega6_other = ['Omega-6 花生四烯酸', 'Omega-6 γ-亚麻酸',
'Omega-3 二十碳三烯酸', 'Omega-6 二十碳二烯酸']
combined_nutrition_data['Omega-6 (其他)'] = data[omega6_other].sum(axis=1, min_count=1)
# 胆固醇
combined_nutrition_data['胆固醇'] = data['胆固醇']
combined_nutrition_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1171 entries, 0 to 1170
Data columns (total 28 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 食品名称 1171 non-null object
1 类别名称 1171 non-null object
2 热量 1171 non-null int64
3 蛋白质 1171 non-null float64
4 碳水化合物 1171 non-null float64
5 脂肪 1171 non-null float64
6 反式脂肪 630 non-null float64
7 钙 1146 non-null float64
8 铜 1092 non-null float64
9 铁 1151 non-null float64
10 镁 1111 non-null float64
11 锰 1012 non-null float64
12 磷 1124 non-null float64
13 钾 1127 non-null float64
14 硒 1018 non-null float64
15 锌 1106 non-null float64
16 钠 1150 non-null float64
17 维生素A 1116 non-null float64
18 维生素B 1117 non-null float64
19 维生素C 1121 non-null float64
20 维生素D 826 non-null float64
21 维生素E 814 non-null float64
22 维生素K 789 non-null float64
23 Omega-3 (DHA, DPA, EPA) 901 non-null float64
24 Omega-3 (ALA) 176 non-null float64
25 Omega-6 (亚油酸) 140 non-null float64
26 Omega-6 (其他) 265 non-null float64
27 胆固醇 1116 non-null float64
dtypes: float64(25), int64(1), object(2)
memory usage: 256.3+ KB
考虑有些食品可能由于书写不同,实际是同一种食品,如 Gewürztraminer 和 Gewurztraminer,在ChatGPT给出的翻译都是琼瑶浆,而且初步观测发现所含元素也相同,因此考虑可能还存在其他类似的食品,对新数据检查重复值情况。
# 查看重复值
combined_nutrition_data.duplicated().sum()
2
存在两条重复值,直接删除处理。
combined_nutrition_data = combined_nutrition_data.drop_duplicates()
plt.figure(figsize=(20,12))
# 绘制热图显示缺失值的分布
sns.heatmap(combined_nutrition_data.isna(), cbar=False, cmap='viridis', yticklabels=False)
plt.title('缺失值热图')
plt.xlabel('字段名')
plt.ylabel('样本索引')
plt.xticks(rotation=30)
plt.show()
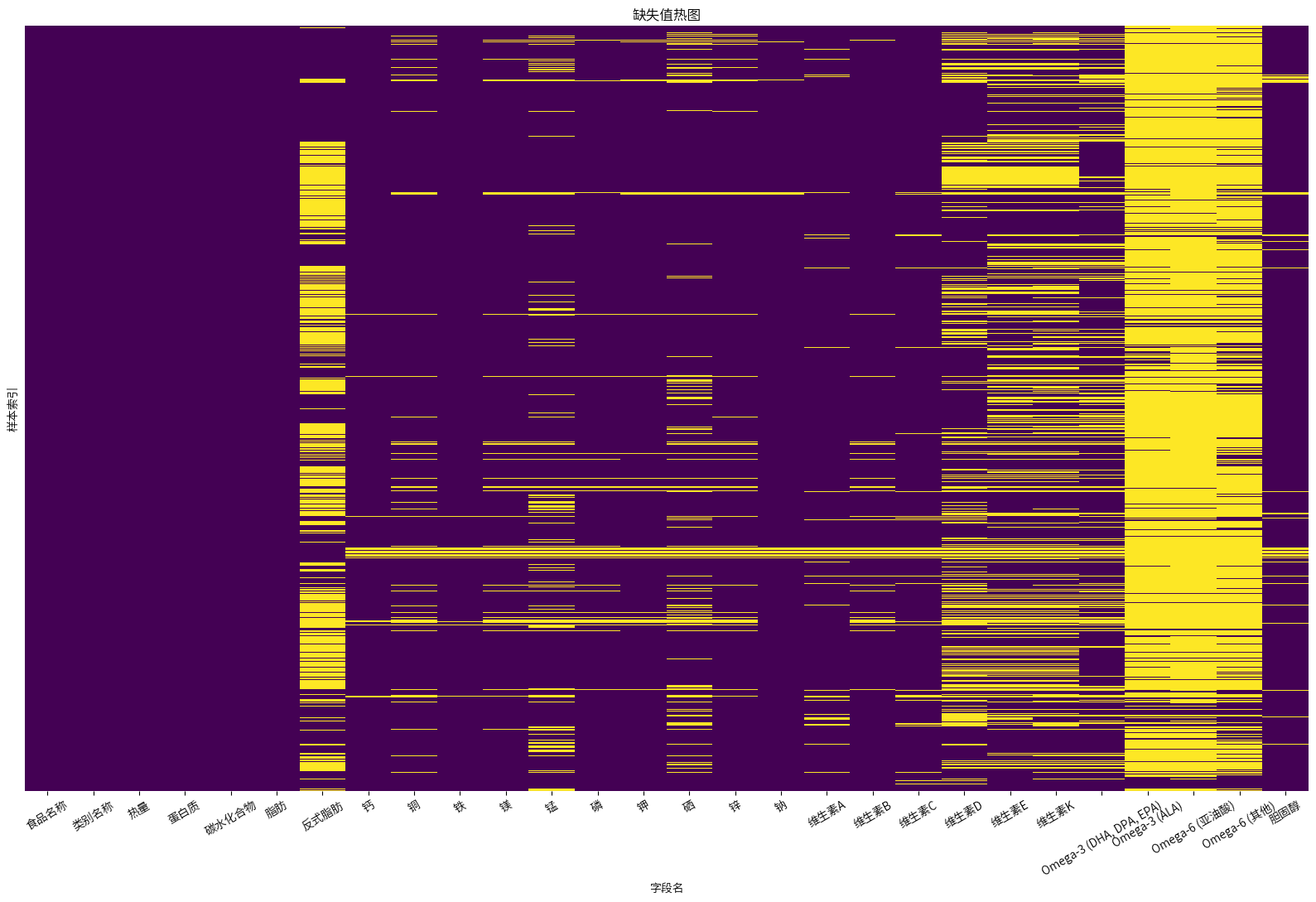
通过缺失值热力图可以发现,有些行缺失值比较多,有些列缺失值比较多,现在一步步来分析,先看行缺失值的情况。
new_data = combined_nutrition_data.copy()
# 计算每行的缺失比例
row_missing_proportions = new_data.isnull().mean(axis=1)
# 将缺失比例添加到数据框中以供后续分析
new_data['缺失比例'] = row_missing_proportions
row_missing_proportions_summary = new_data[['缺失比例']].describe()
row_missing_proportions_summary
| 缺失比例 | |
|---|---|
| count | 1169.000000 |
| mean | 0.173805 |
| std | 0.130635 |
| min | 0.000000 |
| 25% | 0.107143 |
| 50% | 0.142857 |
| 75% | 0.250000 |
| max | 0.750000 |
缺失比例统计:
- 样本数:1169
- 平均缺失比例:约17.38%
- 最大缺失比例:75%
# 按照缺失比例从高到低进行排序,并展示前5行信息
sorted_new_data = new_data.sort_values(by='缺失比例', ascending=False)
sorted_new_data.head()
| 食品名称 | 类别名称 | 热量 | 蛋白质 | 碳水化合物 | 脂肪 | 反式脂肪 | 钙 | 铜 | 铁 | ... | 维生素C | 维生素D | 维生素E | 维生素K | Omega-3 (DHA, DPA, EPA) | Omega-3 (ALA) | Omega-6 (亚油酸) | Omega-6 (其他) | 胆固醇 | 缺失比例 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 814 | 麝香葡萄酒 | 饮料 | 82 | 7.0 | 104.0 | 0.0 | 0.0 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.75 |
| 817 | 法国葡萄酒 | 饮料 | 86 | 7.0 | 74.0 | 0.0 | 0.0 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.75 |
| 810 | 雷司令 | 饮料 | 80 | 7.0 | 74.0 | 0.0 | 0.0 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.75 |
| 809 | 赛美蓉葡萄酒 | 饮料 | 82 | 7.0 | 62.0 | 0.0 | 0.0 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.75 |
| 804 | 灰皮诺葡萄酒 | 饮料 | 83 | 7.0 | 42.0 | 0.0 | 0.0 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.75 |
5 rows × 29 columns
以下内容由ChatGPT 4o 提供:
根据查阅的资料,像 灰皮诺葡萄酒(Pinot Noir) 和 麝香葡萄酒(Muscat Wine) 这类酒类饮品中,维生素和矿物质的含量通常极低,甚至可以忽略不计。这些饮品在营养成分表中,诸如维生素A、C、D、E和K,以及钙、铁、锌等矿物质,基本上都是“0”或者“非常低”。
参考文献
因此大胆假设,所有的缺失值均视为该元素含量极低或者未检测出这个元素,因此用0来代替缺失值。
combined_nutrition_data = combined_nutrition_data.fillna(0)
# 查看食品类别情况
print('食品类别情况:')
print(combined_nutrition_data['类别名称'].unique())
食品类别情况:
['水果' '蔬菜' '海鲜' '乳制品' '蘑菇' '谷物' '肉类' '香料' '坚果' '绿叶蔬菜' '甜食' '油和酱料' '饮料'
'汤类' '烘焙食品' '快餐' '主菜和配菜' '婴儿食品']
# 选择所有连续变量
continuous_columns = combined_nutrition_data.select_dtypes(include=['float64', 'int64']).columns
plt.figure(figsize=(20, 20))
# 使用计数器来标识子图位置
for idx, column in enumerate(continuous_columns, 1): # enumerate 从1开始计数
plt.subplot(4, 7, idx) # 定义4行7列的布局
sns.boxplot(y=combined_nutrition_data[column])
plt.title(f'{column}的箱线图', fontsize=14)
plt.ylabel('数值', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()

输出一些极端异常值,看看凭啥那么高。
# 找到“钙”列中最大值的索引
max_calcium_index = combined_nutrition_data['钙'].idxmax()
combined_nutrition_data.loc[[max_calcium_index]]
| 食品名称 | 类别名称 | 热量 | 蛋白质 | 碳水化合物 | 脂肪 | 反式脂肪 | 钙 | 铜 | 铁 | ... | 维生素B | 维生素C | 维生素D | 维生素E | 维生素K | Omega-3 (DHA, DPA, EPA) | Omega-3 (ALA) | Omega-6 (亚油酸) | Omega-6 (其他) | 胆固醇 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1003 | 泡打粉 | 烘焙食品 | 53 | 0.0 | 58.0 | 0.0 | 0.0 | 5876.0 | 1.0 | 11.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
1 rows × 28 columns
在食安通上面查看,发现确实没啥问题,甚至食安通上面给的钙含量还更高。
# 找到“磷”列中最大值的索引
max_phosphorus_index = combined_nutrition_data['磷'].idxmax()
combined_nutrition_data.loc[[max_phosphorus_index]]
| 食品名称 | 类别名称 | 热量 | 蛋白质 | 碳水化合物 | 脂肪 | 反式脂肪 | 钙 | 铜 | 铁 | ... | 维生素B | 维生素C | 维生素D | 维生素E | 维生素K | Omega-3 (DHA, DPA, EPA) | Omega-3 (ALA) | Omega-6 (亚油酸) | Omega-6 (其他) | 胆固醇 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1003 | 泡打粉 | 烘焙食品 | 53 | 0.0 | 58.0 | 0.0 | 0.0 | 5876.0 | 1.0 | 11.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
1 rows × 28 columns
还是泡打粉,同样在食安通上查看,发现没啥问题。。
# 找到“钾”列中最大值的索引
max_potassium_index = combined_nutrition_data['钾'].idxmax()
combined_nutrition_data.loc[[max_potassium_index]]
| 食品名称 | 类别名称 | 热量 | 蛋白质 | 碳水化合物 | 脂肪 | 反式脂肪 | 钙 | 铜 | 铁 | ... | 维生素B | 维生素C | 维生素D | 维生素E | 维生素K | Omega-3 (DHA, DPA, EPA) | Omega-3 (ALA) | Omega-6 (亚油酸) | Omega-6 (其他) | 胆固醇 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1004 | 塔塔粉 | 烘焙食品 | 258 | 0.0 | 125.0 | 0.0 | 0.0 | 8.0 | 2.0 | 37.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
1 rows × 28 columns
同样塔塔粉在食安通上没问题,其他元素也不查了,再检查一下维生素A,如果没问题,就当数据没异常了。
# 找到维生素A含量最大的行
max_vitamin_a_index = combined_nutrition_data['维生素A'].idxmax()
combined_nutrition_data.loc[[max_vitamin_a_index]]
| 食品名称 | 类别名称 | 热量 | 蛋白质 | 碳水化合物 | 脂肪 | 反式脂肪 | 钙 | 铜 | 铁 | ... | 维生素B | 维生素C | 维生素D | 维生素E | 维生素K | Omega-3 (DHA, DPA, EPA) | Omega-3 (ALA) | Omega-6 (亚油酸) | Omega-6 (其他) | 胆固醇 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 178 | 鳕鱼肝油 | 海鲜 | 902 | 0.0 | 0.0 | 193.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 250.0 | 0.0 | 0.0 | 174.0 | 0.0 | 0.0 | 0.0 | 570.0 |
1 rows × 28 columns
确实,鱼肝油中含有大量的维生素A,其他元素都不查了,说明这个数据,确实比较严谨,但是,在后续分析的时候,由于数据是100g食物,量变会导致质变,在日常饮食摄入中,像调料这些,根本不可能食用这么多。
4.营养成分比较分析
4.1宏量营养素对比
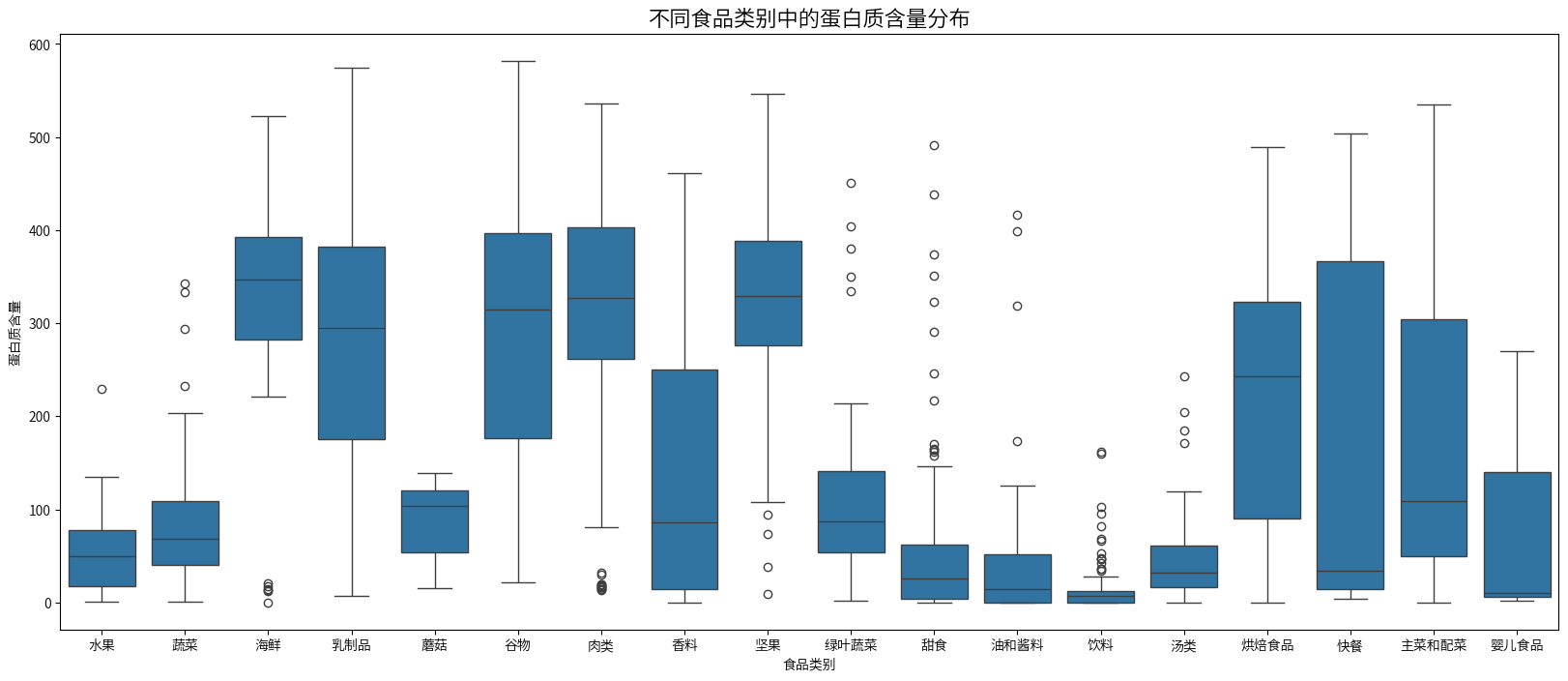
plt.figure(figsize=(20,8))
sns.boxplot(x=combined_nutrition_data['类别名称'],y=combined_nutrition_data['蛋白质'])
plt.title('不同食品类别中的蛋白质含量分布', fontsize=16)
plt.xlabel('食品类别')
plt.ylabel('蛋白质含量')
plt.show()
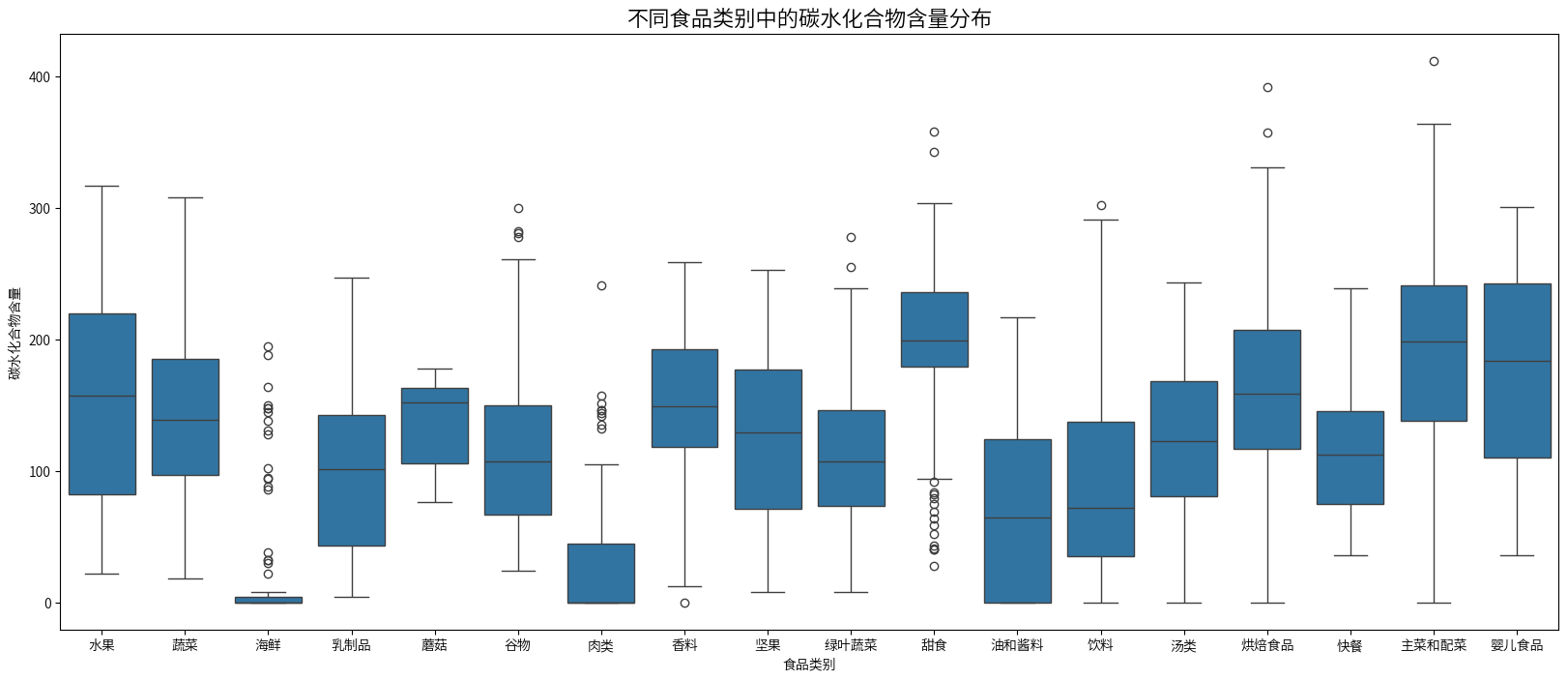
plt.figure(figsize=(20,8))
sns.boxplot(x=combined_nutrition_data['类别名称'],y=combined_nutrition_data['碳水化合物'])
plt.title('不同食品类别中的碳水化合物含量分布', fontsize=16)
plt.xlabel('食品类别')
plt.ylabel('碳水化合物含量')
plt.show()
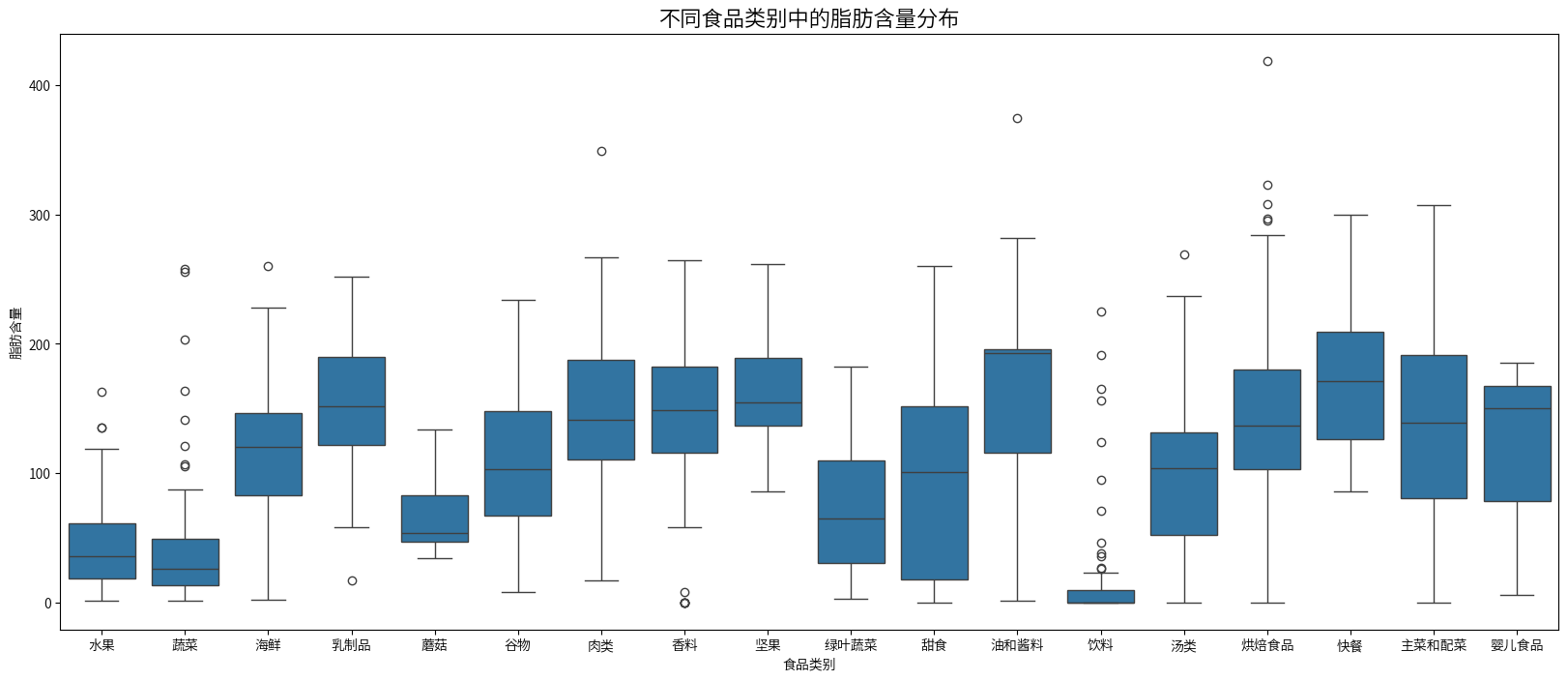
plt.figure(figsize=(20,8))
sns.boxplot(x=combined_nutrition_data['类别名称'],y=combined_nutrition_data['脂肪'])
plt.title('不同食品类别中的脂肪含量分布', fontsize=16)
plt.xlabel('食品类别')
plt.ylabel('脂肪含量')
plt.show()
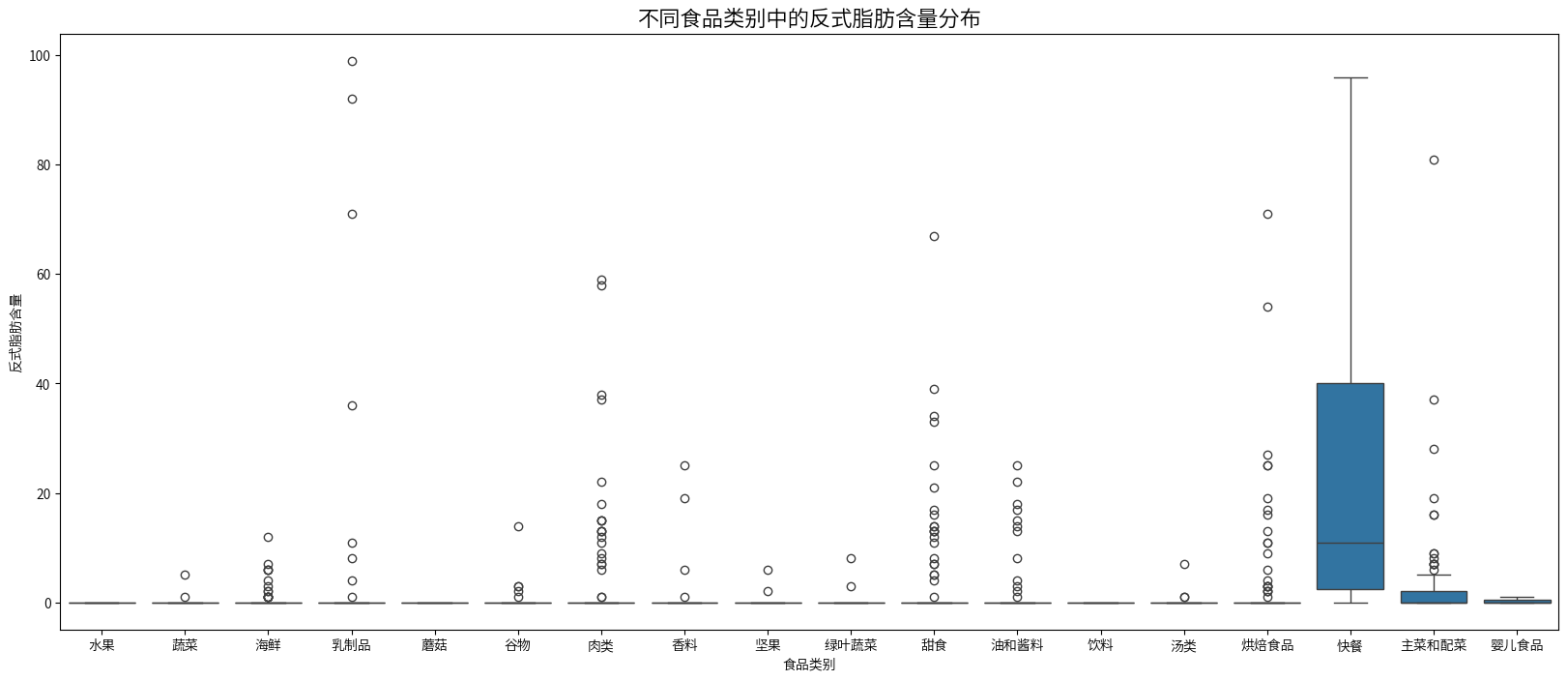
plt.figure(figsize=(20,8))
sns.boxplot(x=combined_nutrition_data['类别名称'],y=combined_nutrition_data['反式脂肪'])
plt.title('不同食品类别中的反式脂肪含量分布', fontsize=16)
plt.xlabel('食品类别')
plt.ylabel('反式脂肪含量')
plt.show()
蛋白质含量分布
- 海鲜、肉类和坚果类食品的蛋白质含量最高,中位数大约在300-400之间。
- 水果、蔬菜和饮料的蛋白质含量最低,中位数接近0。
- 乳制品和谷物类食品的蛋白质含量居中,中位数约为100-200。
碳水化合物含量分布
- 谷物类、甜食和烘焙制品的碳水化合物含量最高,中位数在200左右。
- 海鲜和肉类的碳水化合物含量最低,中位数接近0。
- 水果和蔬菜的碳水化合物含量适中,中位数约为100-150。
脂肪含量分布
- 坚果类、油和酱料以及快餐食品的脂肪含量最高,中位数在150-200左右。
- 水果、蔬菜和饮料的脂肪含量最低,中位数接近0。
- 乳制品、肉类和海鲜的脂肪含量中等,中位数约为50-150。
反式脂肪含量分布
- 大多数食品类别的反式脂肪含量都很低,中位数接近0。
- 快餐食品和烘焙制品的反式脂肪含量相对较高,尤其是快餐食品,有较大的离群值。
- 乳制品也显示出一些反式脂肪含量,但大多数样本仍然很低。
4.2热量对比
plt.figure(figsize=(20,8))
sns.boxplot(x=combined_nutrition_data['类别名称'],y=combined_nutrition_data['热量'])
plt.title('不同食品类别中的热量分布', fontsize=16)
plt.xlabel('食品类别')
plt.ylabel('热量')
plt.show()
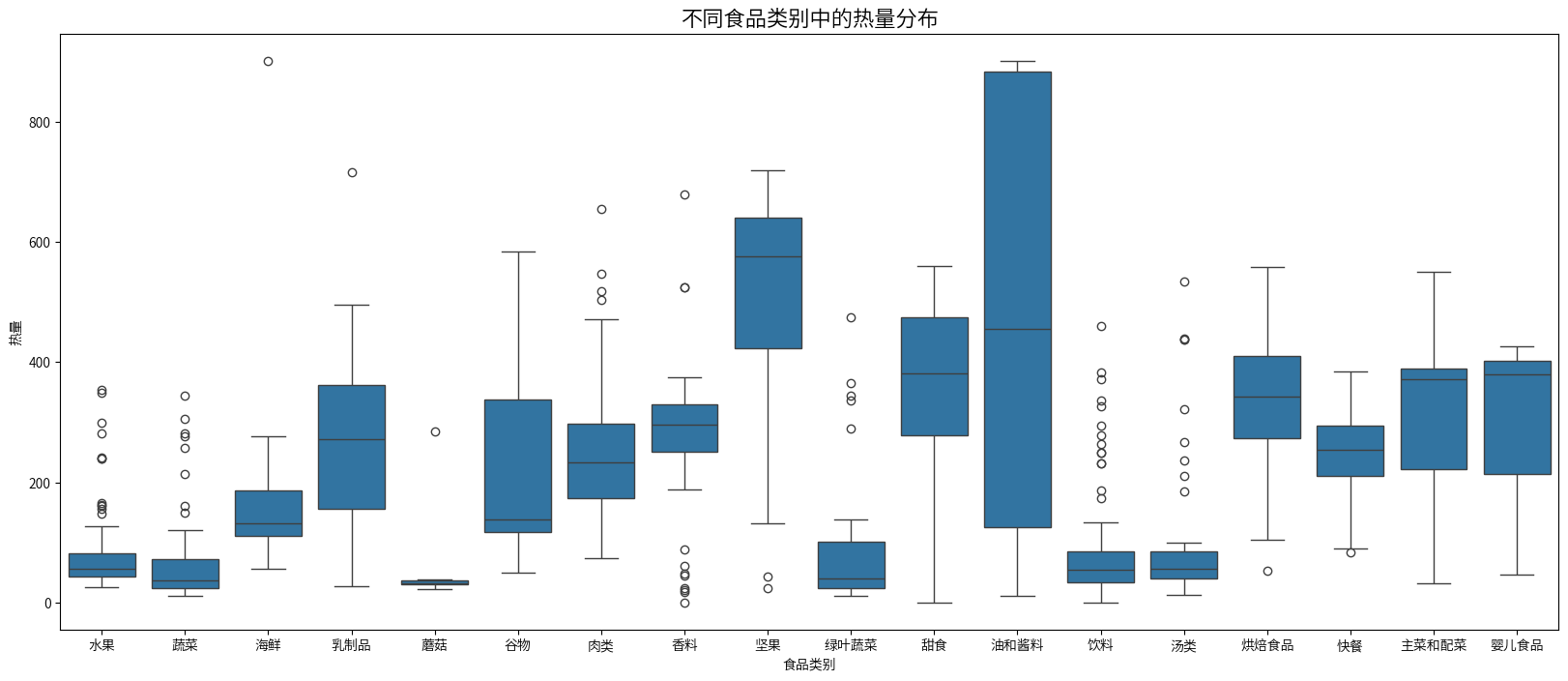
高热量食品类别
- 坚果类食品热量最高,中位数约为550-600,分布相对集中。
- 油和酱料类食品的热量次之,中位数约为500-600,且分布范围较广,上限最高。
- 甜食类热量分布范围大,中位数约为350-400。
- 快餐食品、烘焙产品和一些主菜及配菜的热量也较高,中位数大约在300-400之间。
中等热量食品类别
- 乳制品、肉类和海鲜的热量处于中等水平,中位数约为200-300。
- 谷物类食品热量分布较广,从低到高都有,中位数约为150-200。
低热量食品类别
- 水果、蔬菜和蘑菇类食品的热量最低,中位数都在100以下。
- 绿叶蔬菜的热量尤其低,中位数接近50或更低。
4.3同类食品的对比分析
这里食品选择了麦当劳的巨无霸和麦当劳的芝士汉堡,然后元素选择了热量、脂肪、蛋白质、碳水化合物、反式脂肪,读者感兴趣的话,可以自寻选择其他品类的食物或者元素进行对比,选择元素的话,多选按住ctrl加鼠标左键即可。
def create_food_radar_chart(food_name1, food_name2, features):
"""
创建两个食物营养成分对比雷达图
参数:
food_name1 (str): 第一个选择的食物名称
food_name2 (str): 第二个选择的食物名称
features (list): 选择的营养特征列表
返回:
Radar: 生成的雷达图对象
"""
# 获取食物类别
food_category = combined_nutrition_data[combined_nutrition_data['食品名称'] == food_name1]['类别名称'].values[0]
# 验证所选特征是否有效
valid_features = [f for f in features if f in combined_nutrition_data.columns]
# 获取两个食物的数据和类别平均值
food_data1 = combined_nutrition_data[combined_nutrition_data['食品名称'] == food_name1][valid_features].values[0].tolist()
food_data2 = combined_nutrition_data[combined_nutrition_data['食品名称'] == food_name2][valid_features].values[0].tolist()
category_avg = combined_nutrition_data[combined_nutrition_data['类别名称'] == food_category][valid_features].mean().round().astype(int).tolist()
# 计算每个特征的最大值
max_values = combined_nutrition_data[valid_features].max().round().astype(int).tolist()
# 创建雷达图的指示器
indicators = [opts.RadarIndicatorItem(name=feature, max_=max_value)
for feature, max_value in zip(valid_features, max_values)]
# 初始化雷达图
radar = Radar(init_opts=opts.InitOpts(width="800px", height="600px", theme=ThemeType.LIGHT))
radar.add_schema(schema=indicators)
# 添加两个食物的数据和类别平均值到雷达图
radar.add(food_name1, [food_data1], color="#FF0000", symbol="circle", label_opts=opts.LabelOpts(is_show=False))
radar.add(food_name2, [food_data2], color="#00FF00", symbol="rect", label_opts=opts.LabelOpts(is_show=False))
radar.add(f"{food_category} 平均", [category_avg], color="#0000FF", symbol="diamond", label_opts=opts.LabelOpts(is_show=False))
# 设置全局选项
radar.set_global_opts(
title_opts=opts.TitleOpts(
title=f"{food_name1}与{food_name2}营养成分对比雷达图",
pos_top="0%",
pos_left="center"
),
legend_opts=opts.LegendOpts(selected_mode="multiple", pos_bottom="5%")
)
return radar
def update_chart(food1, food2, features):
"""
更新并显示雷达图
参数:
food1 (str): 第一个选择的食物名称
food2 (str): 第二个选择的食物名称
features (list): 选择的营养特征列表
"""
clear_output(wait=True)
chart = create_food_radar_chart(food1, food2, features)
display(chart.render_notebook())
# 创建食物类别选择下拉菜单
category_dropdown = widgets.Dropdown(
options=sorted(combined_nutrition_data['类别名称'].unique()),
description='选择食物类别:',
style={'description_width': 'initial'}
)
# 创建两个食物选择下拉菜单(初始为空)
food_dropdown1 = widgets.Dropdown(
options=[],
description='选择食物1:',
style={'description_width': 'initial'}
)
food_dropdown2 = widgets.Dropdown(
options=[],
description='选择食物2:',
style={'description_width': 'initial'}
)
# 创建特征选择多选框
all_features = [col for col in combined_nutrition_data.columns if col not in ['食品名称', '类别名称']]
feature_checkbox = widgets.SelectMultiple(
options=all_features,
value=all_features[:5] if len(all_features) >= 5 else all_features,
description='选择特征:',
disabled=False,
style={'description_width': 'initial'}
)
# 创建更新按钮
update_button = widgets.Button(description="更新图表")
# 定义类别选择变化时的处理函数
def on_category_change(change):
category = change.new if hasattr(change, 'new') else change
food_options = sorted(combined_nutrition_data[combined_nutrition_data['类别名称'] == category]['食品名称'].unique())
food_dropdown1.options = food_options
food_dropdown2.options = food_options
if food_options:
food_dropdown1.value = food_options[0]
food_dropdown2.value = food_options[1] if len(food_options) > 1 else food_options[0]
# 绑定类别选择变化事件
category_dropdown.observe(on_category_change, names='value')
# 定义按钮点击事件处理函数
def on_button_clicked(b):
update_chart(food_dropdown1.value, food_dropdown2.value, feature_checkbox.value)
# 绑定按钮点击事件
update_button.on_click(on_button_clicked)
# 显示交互控件
display(widgets.VBox([category_dropdown, food_dropdown1, food_dropdown2, feature_checkbox, update_button]))
# 初始化类别选择
on_category_change(category_dropdown.options[0])
# 初始化显示
update_chart(food_dropdown1.value, food_dropdown2.value, feature_checkbox.value)
<div id="e206d7a13597403989b06370fa3e970a" style="width:800px; height:600px;"></div>
5.统计检验
5.1Shapiro-Wilk检验
# 创建一个字典来存储每个变量的正态性检验结果
normality_test_results = {}
# 对每个连续变量进行Shapiro-Wilk正态性检验
for column in continuous_columns:
stat, p_value = stats.shapiro(combined_nutrition_data[column].dropna())
normality_test_results[column] = p_value
# 将结果转换为DataFrame
normality_results_df = pd.DataFrame(list(normality_test_results.items()), columns=['变量', 'p值'])
normality_results_df
| 变量 | p值 | |
|---|---|---|
| 0 | 热量 | 6.170575e-28 |
| 1 | 蛋白质 | 1.147125e-30 |
| 2 | 碳水化合物 | 3.141569e-16 |
| 3 | 脂肪 | 1.917447e-17 |
| 4 | 反式脂肪 | 3.373801e-55 |
| 5 | 钙 | 3.768889e-54 |
| 6 | 铜 | 1.010723e-40 |
| 7 | 铁 | 2.930072e-29 |
| 8 | 镁 | 3.449308e-48 |
| 9 | 锰 | 1.848650e-38 |
| 10 | 磷 | 2.547430e-39 |
| 11 | 钾 | 1.032824e-54 |
| 12 | 硒 | 5.586455e-57 |
| 13 | 锌 | 6.897210e-28 |
| 14 | 钠 | 6.160968e-58 |
| 15 | 维生素A | 1.587604e-57 |
| 16 | 维生素B | 2.994721e-41 |
| 17 | 维生素C | 9.374602e-57 |
| 18 | 维生素D | 1.177952e-56 |
| 19 | 维生素E | 2.072728e-38 |
| 20 | 维生素K | 1.543556e-56 |
| 21 | Omega-3 (DHA, DPA, EPA) | 2.160020e-56 |
| 22 | Omega-3 (ALA) | 5.922090e-55 |
| 23 | Omega-6 (亚油酸) | 3.331552e-54 |
| 24 | Omega-6 (其他) | 8.499532e-56 |
| 25 | 胆固醇 | 2.689589e-53 |
由于所有变量的p值都非常小(远小于0.05),这些连续变量的数据可以认为是非正态分布的,在后续分析中,需要考虑非参数统计方法。
5.2斯皮尔曼相关性分析
def plot_spearmanr(data,features,title,wide,height):
# 计算斯皮尔曼相关性矩阵和p值矩阵
spearman_corr_matrix = data[features].corr(method='spearman')
pvals = data[features].corr(method=lambda x, y: spearmanr(x, y)[1]) - np.eye(len(data[features].columns))
# 转换 p 值为星号
def convert_pvalue_to_asterisks(pvalue):
if pvalue <= 0.001:
return "***"
elif pvalue <= 0.01:
return "**"
elif pvalue <= 0.05:
return "*"
return ""
# 应用转换函数
pval_star = pvals.applymap(lambda x: convert_pvalue_to_asterisks(x))
# 转换成 numpy 类型
corr_star_annot = pval_star.to_numpy()
# 定制 labels
corr_labels = spearman_corr_matrix.to_numpy()
p_labels = corr_star_annot
shape = corr_labels.shape
# 合并 labels
labels = (np.asarray(["{0:.2f}\n{1}".format(data, p) for data, p in zip(corr_labels.flatten(), p_labels.flatten())])).reshape(shape)
# 绘制热力图
fig, ax = plt.subplots(figsize=(height, wide), dpi=100, facecolor="w")
sns.heatmap(spearman_corr_matrix, annot=labels, fmt='', cmap='coolwarm',
vmin=-1, vmax=1, annot_kws={"size":10, "fontweight":"bold"},
linecolor="k", linewidths=.2, cbar_kws={"aspect":13}, ax=ax)
ax.tick_params(bottom=False, labelbottom=True, labeltop=False,
left=False, pad=1, labelsize=12)
ax.yaxis.set_tick_params(labelrotation=0)
# 自定义 colorbar 标签格式
cbar = ax.collections[0].colorbar
cbar.ax.tick_params(direction="in", width=.5, labelsize=10)
cbar.set_ticks([-1, -0.5, 0, 0.5, 1])
cbar.set_ticklabels(["-1.00", "-0.50", "0.00", "0.50", "1.00"])
cbar.outline.set_visible(True)
cbar.outline.set_linewidth(.5)
plt.title(title)
plt.show()
plot_spearmanr(combined_nutrition_data,continuous_columns,'各元素之间的斯皮尔曼相关系数热力图',18,20)
/tmp/ipykernel_214/1940800490.py:17: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
pval_star = pvals.applymap(lambda x: convert_pvalue_to_asterisks(x))
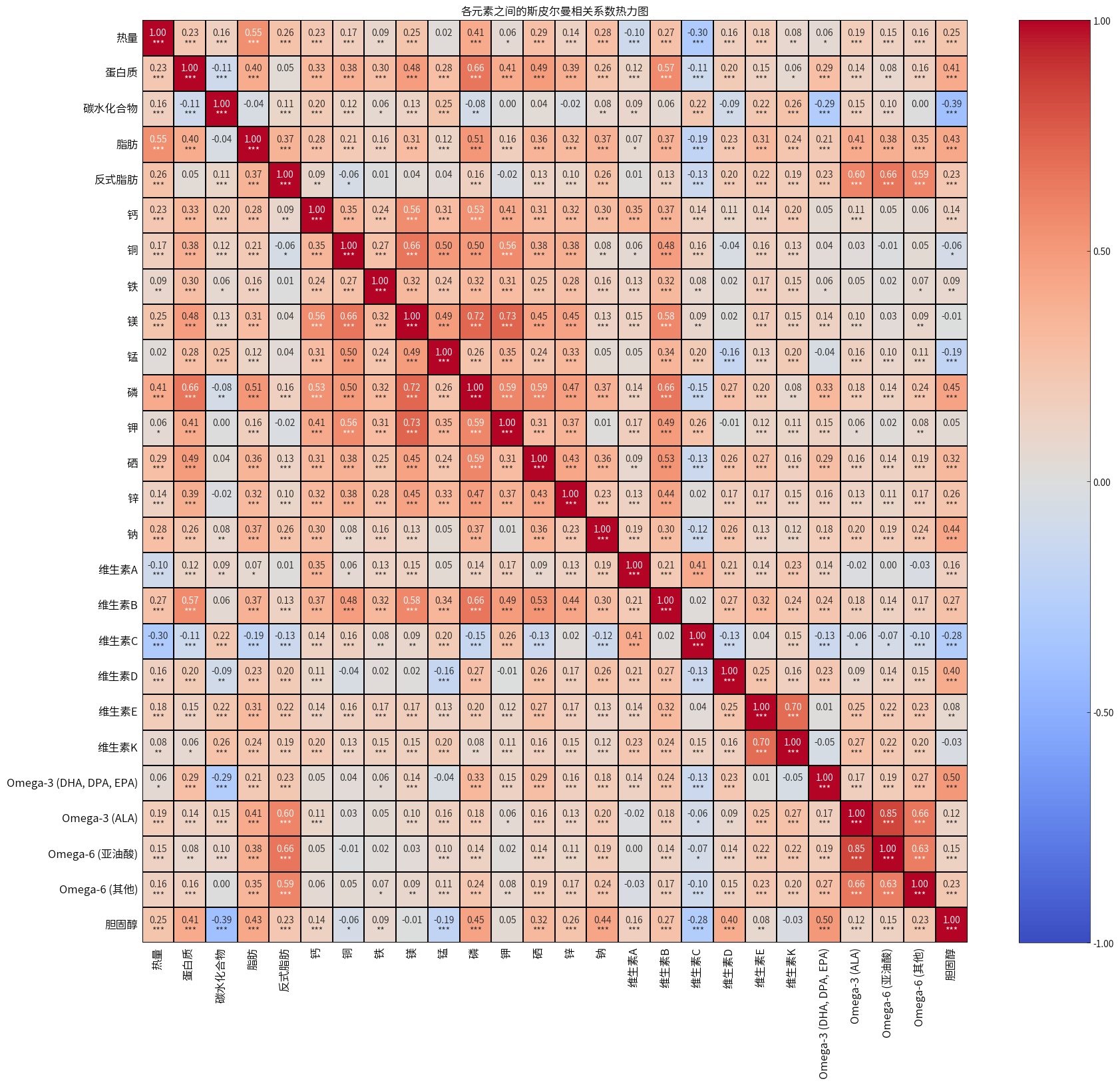
- 热量主要与脂肪含量正相关,其次是蛋白质和碳水化合物。这反映了脂肪是主要的热量来源。
- 矿物质之间普遍存在中等到强的正相关,特别是镁、磷和钾。这可能反映了它们在食物中的共同存在模式。
- 维生素E和K高度相关,表明它们可能常见于相同的食物来源,特别是在某些植物性食品中。
- Omega-3和Omega-6脂肪酸之间存在强相关,这可能反映了它们在某些食物(如某些鱼类和植物油)中的共同存在。
- 蛋白质含量与多种矿物质(如磷、硒、锌)正相关,表明高蛋白食品往往也富含这些矿物质。
- 维生素C与多数其他营养素的相关性较弱或为负,这可能反映了其在新鲜水果和蔬菜中的独特分布。
- 胆固醇与碳水化合物的负相关性可能反映了动物性食品(高胆固醇)和植物性食品(高碳水)的区别。
5.3Kruskal-Wallis H检验
results = {}
for continuous_column in continuous_columns:
groups = [group[continuous_column].values for name, group in combined_nutrition_data.groupby('类别名称')]
h_statistic, p_value = stats.kruskal(*groups)
results[continuous_column] = {'H-statistic': h_statistic, 'p-value': p_value}
# 将结果转换为DataFrame以便于查看
results_df = pd.DataFrame.from_dict(results, orient='index')
results_df = results_df.sort_values('p-value')
results_df
| H-statistic | p-value | |
|---|---|---|
| 胆固醇 | 777.270914 | 3.166506e-154 |
| 磷 | 629.953022 | 6.423379e-123 |
| 热量 | 627.431747 | 2.199030e-122 |
| 钠 | 624.925263 | 7.473284e-122 |
| 蛋白质 | 540.562124 | 5.272590e-104 |
| Omega-3 (DHA, DPA, EPA) | 506.918152 | 6.595206e-97 |
| 脂肪 | 474.025224 | 5.549142e-90 |
| 维生素B | 464.035552 | 6.988470e-88 |
| 碳水化合物 | 460.850473 | 3.263461e-87 |
| 镁 | 453.711093 | 1.031212e-85 |
| 钙 | 424.324126 | 1.505061e-79 |
| 硒 | 415.737001 | 9.461438e-78 |
| 钾 | 400.228864 | 1.660746e-74 |
| 维生素C | 385.781843 | 1.731056e-71 |
| 维生素D | 364.112497 | 5.708058e-67 |
| 锰 | 363.755806 | 6.772804e-67 |
| 铜 | 316.465576 | 4.455027e-57 |
| 维生素A | 291.669411 | 5.879180e-52 |
| 锌 | 251.419676 | 1.070220e-43 |
| 反式脂肪 | 240.558678 | 1.759120e-41 |
| Omega-3 (ALA) | 191.373493 | 1.541729e-31 |
| Omega-6 (亚油酸) | 171.719457 | 1.279386e-27 |
| Omega-6 (其他) | 157.952462 | 6.726730e-25 |
| 维生素K | 150.019353 | 2.426367e-23 |
| 铁 | 138.598303 | 4.082712e-21 |
| 维生素E | 120.500082 | 1.238336e-17 |
根据Kruskal-Wallis H检验的结果,所有营养成分都显示出在不同食品类别之间存在显著差异(所有p值都远小于0.05)。
6.营养密度分析
热量密度:单位质量食物所含的热量值 (kcal/100g)
营养密度 (ND):单位热量食物所含的营养素质量 (NM)
营养密度指数 (NDI):描述食物中特定营养素相对于其热量的含量
NDI 计算公式:
N
D
I
=
N
M
E
n
e
r
g
y
(
100
k
c
a
l
)
NDI = {NM \over Energy (100kcal)}
NDI=Energy(100kcal)NM
其中:
- NM: 营养素质量
- Energy: 食物热量
因为数据存在热量为0的食物(可能是四舍五入导致的),如一部分香料和饮料,所以对热量为0的食品赋予非常小的值(0.1),以防止计算营养密度时出现inf(无穷大)值,并且考虑到香料食用量比较少,如果兑换成100热量的话,远远超过其他食物的摄入量了,直接剔除吧,同样的,婴儿食品只有3个样本,可能会影响分析,这里也是直接剔除。
nutrition_density = combined_nutrition_data.copy()
nutrition_density['热量'] = nutrition_density['热量'].replace(0, 0.1)
# 去除"香料"和"婴儿食品"类别
filtered_nutrition_density = combined_nutrition_data[['食品名称', '类别名称']].copy()
filtered_nutrition_density = filtered_nutrition_density[~filtered_nutrition_density['类别名称'].isin(['香料', '婴儿食品'])]
# 计算营养密度(每100卡路里的营养素含量)
for continuous_column in continuous_columns.drop('热量'):
filtered_nutrition_density[f'{continuous_column}密度'] = nutrition_density[continuous_column] / nutrition_density['热量'] * 100
# 按食品类别计算平均营养密度
nutrient_density = filtered_nutrition_density.groupby('类别名称')[[f'{continuous_column}密度' for continuous_column in continuous_columns.drop('热量')]].mean()
plt.figure(figsize=(20,18))
sns.heatmap(nutrient_density, annot=True, cmap='YlGnBu', fmt='.2f')
plt.title('不同食品类别的平均营养密度(每100卡路里)')
plt.yticks(rotation=0)
plt.show()

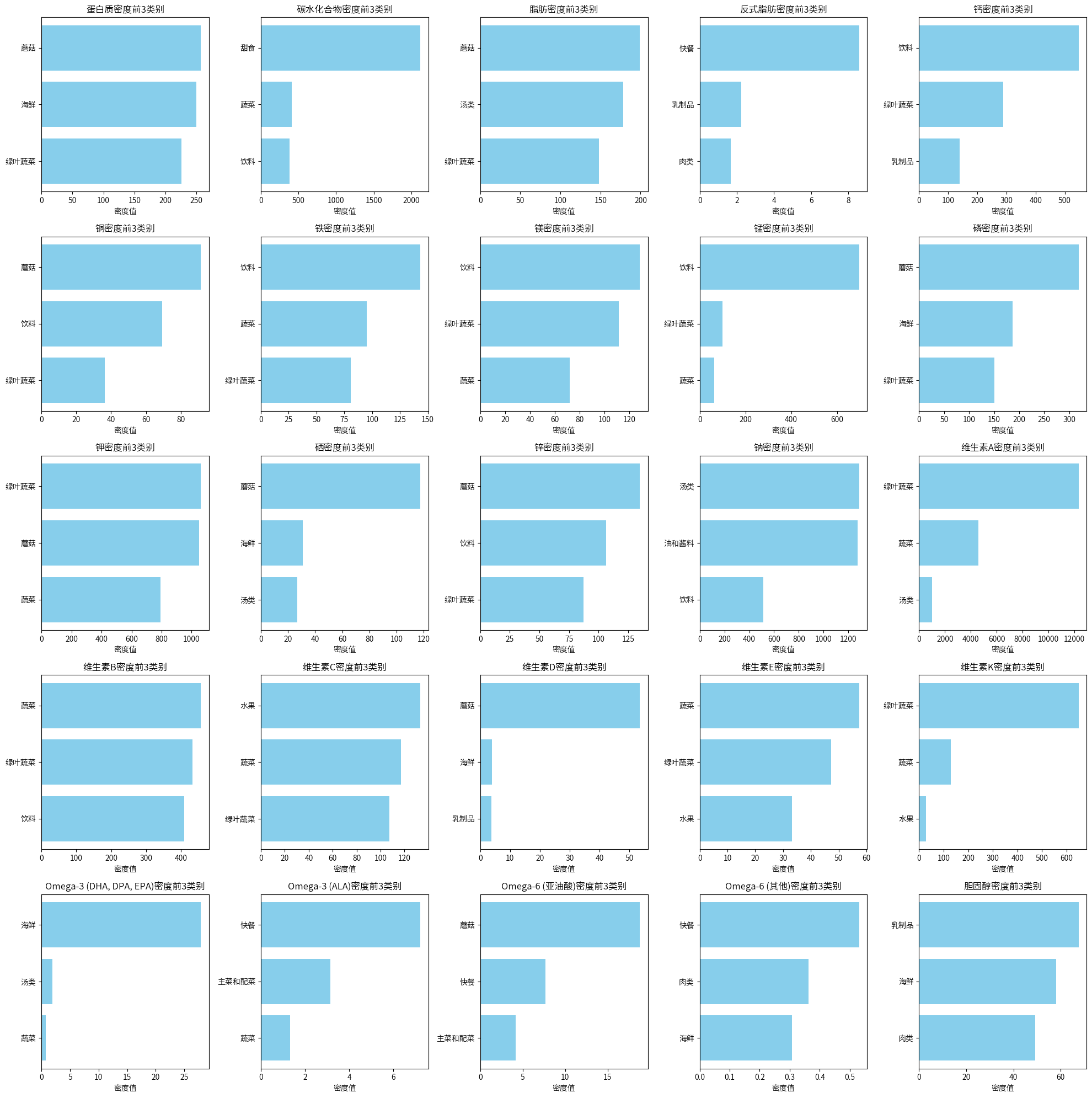
top_categories = {}
# 对每一列(每种营养元素),找出排名前3的类别
for column in nutrient_density.columns:
top_categories[column] = nutrient_density[column].nlargest(3).index
fig, axes = plt.subplots(nrows=5, ncols=5, figsize=(20, 20)) # 25种元素,5x5网格
for i, (element, categories) in enumerate(top_categories.items()):
ax = axes[i // 5, i % 5]
scores = nutrient_density.loc[categories, element]
sorted_scores = scores.sort_values(ascending=True)
ax.barh(sorted_scores.index, sorted_scores.values, color='skyblue')
ax.set_title(f'{element}前3类别')
ax.set_xlabel('密度值')
plt.tight_layout()
plt.show()
top_food = {}
# 对每一列(每种营养元素),找出排名前3的食品
for column in filtered_nutrition_density.columns[2:]:
top_indices = filtered_nutrition_density[column].nlargest(3).index
top_food[column] = filtered_nutrition_density.loc[top_indices, '食品名称'] # 使用索引获取食品名称
fig, axes = plt.subplots(nrows=5, ncols=5, figsize=(20, 20)) # 25种元素,5x5网格
for i, (element, foods) in enumerate(top_food.items()):
ax = axes[i // 5, i % 5]
scores = filtered_nutrition_density.loc[foods.index, element]
sorted_scores = scores.sort_values(ascending=True)
ax.barh(foods.values, sorted_scores.values, color='skyblue')
ax.set_title(f'{element}前3的食物')
ax.set_xlabel('密度值')
plt.tight_layout()
plt.show()
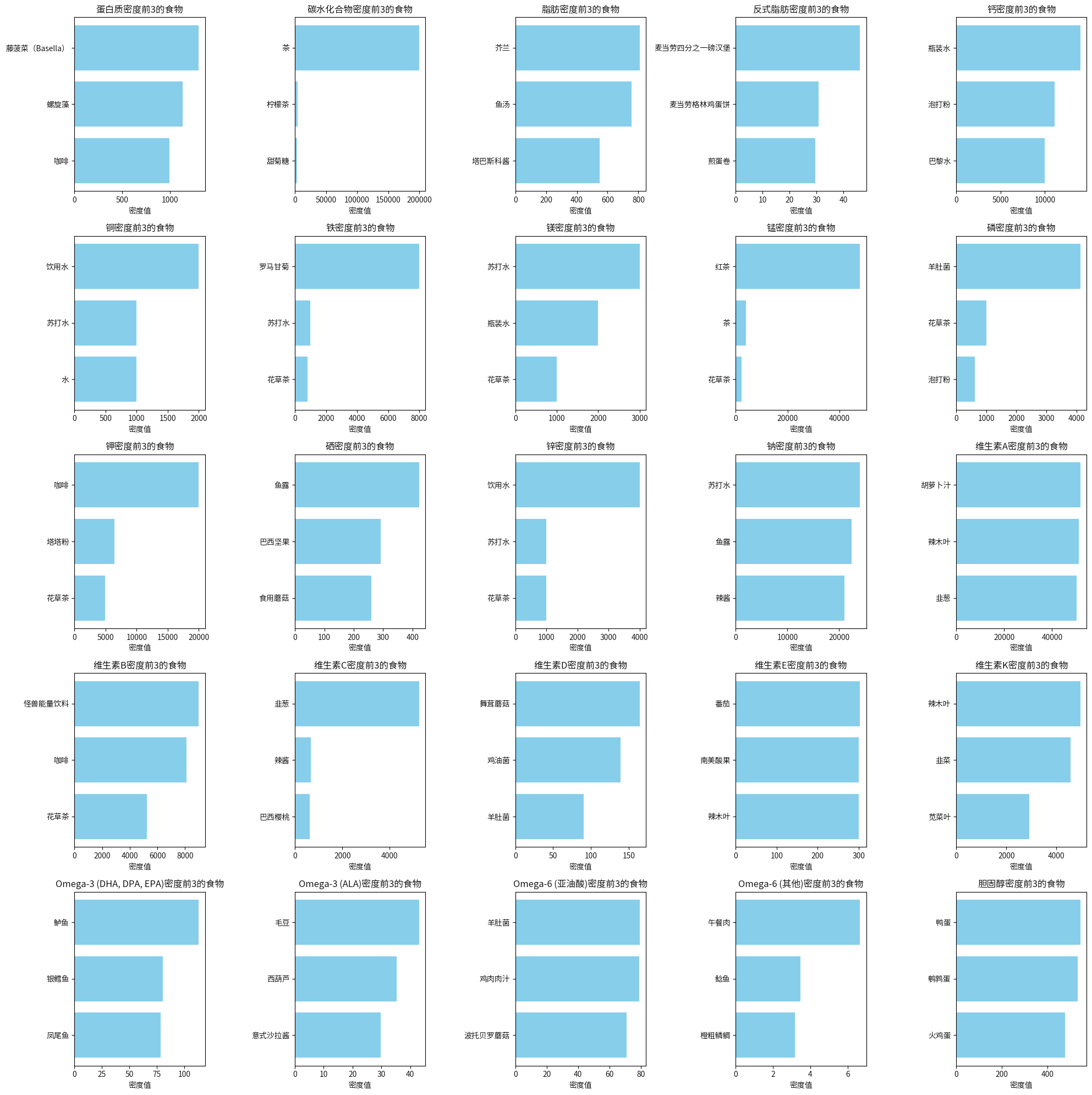
营养密度只能做一个参考指标,像这个数据中,藤菠菜的蛋白质密度特别高,比一些优质肉类都高,这种情况是由于热量差异,因为藤菠菜的热量特别低,而优质肉(如牛肉)的热量比较高,就会导致藤菠菜的蛋白质含量相对其热量来说显得特别高,虽然藤菠菜的蛋白质密度高于牛肉,但在实际食用时,人们通常会吃更多的牛肉(按重量计),从而摄入更多的蛋白质总量,因为要获得相同量的蛋白质,需要吃大量的藤菠菜,而只需少量的牛肉。
7.聚类分析
7.1数据预处理
nutrition_data = combined_nutrition_data[continuous_columns]
# 标准化数
scaler = StandardScaler()
scaled_nutrition_data = scaler.fit_transform(nutrition_data)
7.2确定聚类数
n_components = range(1, 11) # 尝试 1 到 10 个聚类
aic_scores = []
bic_scores = []
# 计算每个聚类数的 AIC 和 BIC
for n in n_components:
gmm = GaussianMixture(n_components=n, random_state=15)
gmm.fit(scaled_nutrition_data) # 训练 GMM 模型
aic_scores.append(gmm.aic(scaled_nutrition_data)) # 计算 AIC
bic_scores.append(gmm.bic(scaled_nutrition_data)) # 计算 BIC
# 绘制 AIC 和 BIC 曲线
plt.figure(figsize=(8, 6))
plt.plot(n_components, aic_scores, label='AIC', marker='o')
plt.plot(n_components, bic_scores, label='BIC', marker='s')
plt.xlabel('聚类数')
plt.ylabel('得分')
plt.title('AIC 和 BIC 分数对比')
plt.legend()
plt.grid(True)
plt.show()
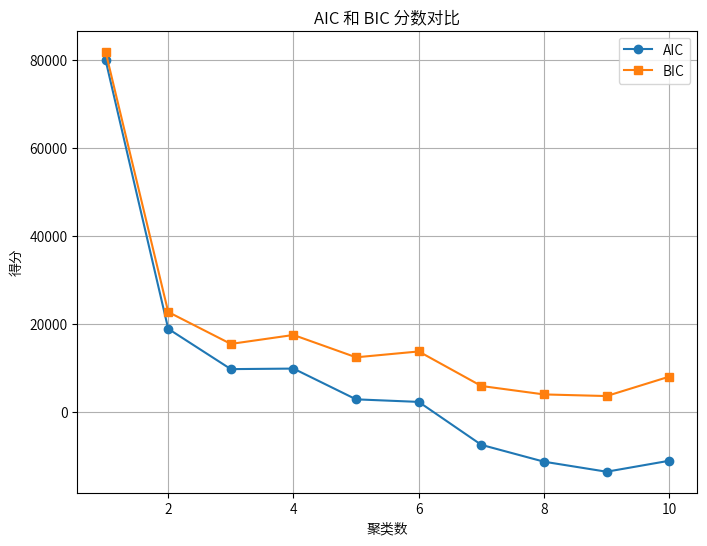
- AIC值随聚类数增加总体呈下降趋势,在聚类数为9时达到最小值。根据AIC准则,应选择使AIC值最小的模型,因此AIC建议的最佳聚类数为9。
- BIC值先急剧下降,然后在聚类数为9时达到最小值3593.45,之后又开始上升。根据BIC准则,应选择使BIC值最小的模型,因此BIC也建议最佳聚类数为9。
- 但是AIC和BIC曲线在聚类数为2到4之间有一个明显的拐点,之后下降速度变缓。这可能表明从2个聚类到3或4个聚类时模型改进显著,之后改进幅度减小。
- 虽然AIC和BIC都指向9个聚类,但考虑到模型复杂度和解释性,需要在拐点处和最优值之间做出平衡。聚类数在4到6之间可能是一个较好的折中选择,既能捕捉数据的主要结构,又不会过于复杂,因此选择聚类数5,此时是极小值点。
7.3高斯混合模型聚类
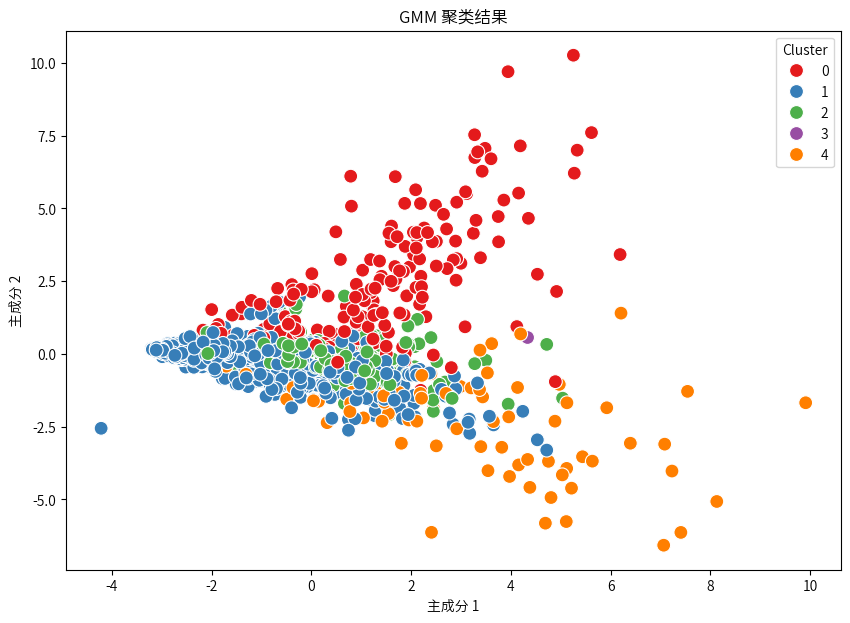
gmm = GaussianMixture(n_components=5, random_state=15)
gmm_labels = gmm.fit_predict(scaled_nutrition_data)
combined_nutrition_data['Cluster'] = gmm_labels
# 使用PCA将数据降维至2个主成分
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(scaled_nutrition_data)
# 可视化GMM聚类结果
plt.figure(figsize=(10, 7))
sns.scatterplot(x=reduced_data[:, 0], y=reduced_data[:, 1], hue=combined_nutrition_data['Cluster'], palette='Set1', s=100)
plt.title('GMM 聚类结果')
plt.xlabel('主成分 1')
plt.ylabel('主成分 2')
plt.show()
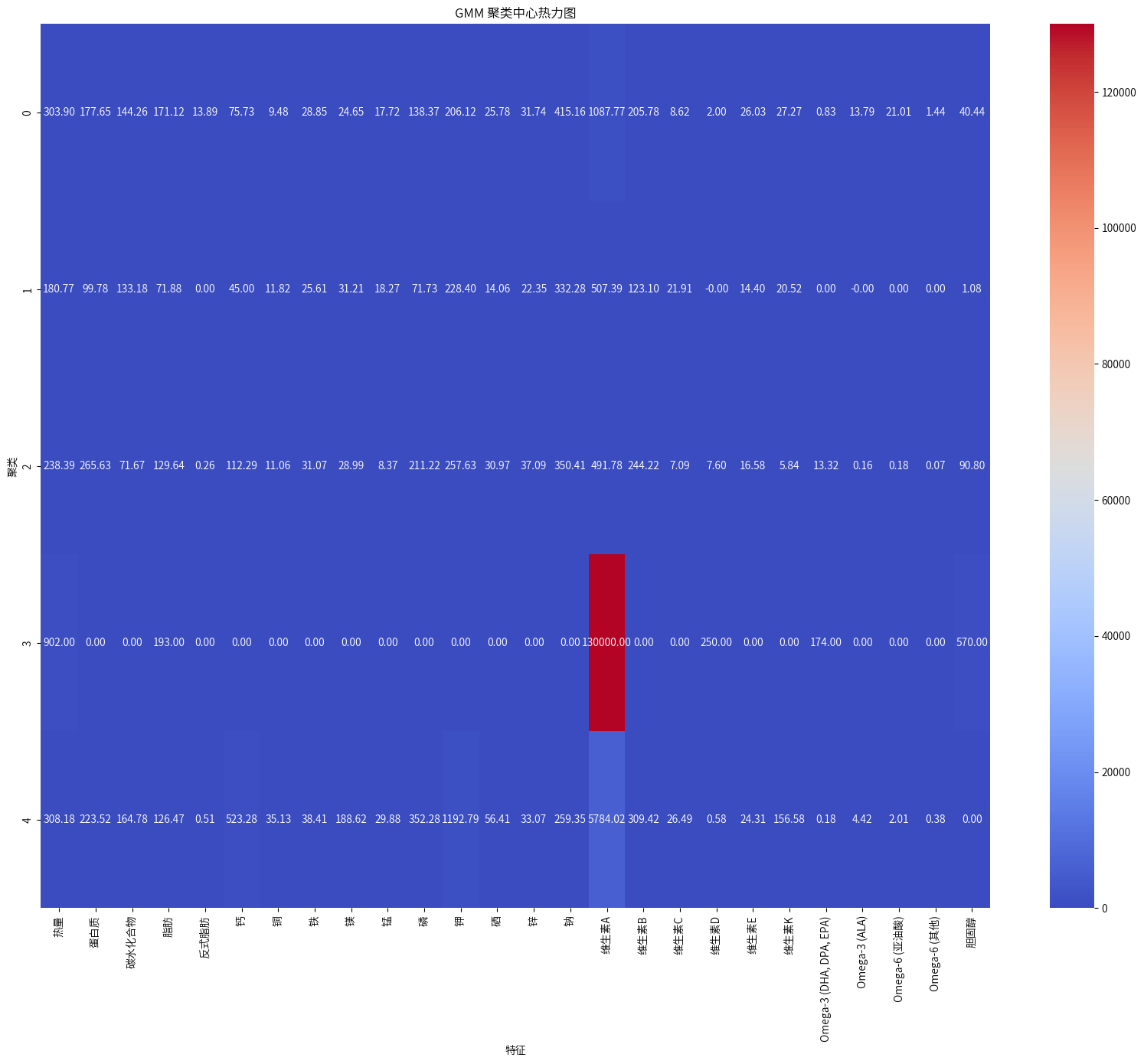
# 获取 GMM 的聚类中心(基于标准化数据)
gmm_cluster_centers = gmm.means_
# 将聚类中心逆标准化回原始数据空间
original_cluster_centers = scaler.inverse_transform(gmm_cluster_centers)
# 确保传递的列名数量与聚类中心的列数一致
center_df = pd.DataFrame(original_cluster_centers, columns=nutrition_data.columns)
# 绘制热力图
plt.figure(figsize=(20, 15))
sns.heatmap(center_df, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('GMM 聚类中心热力图')
plt.xlabel('特征')
plt.ylabel('聚类')
plt.show()
# 计算每个聚类中各类别的数量
cluster_category_counts = combined_nutrition_data.groupby(['Cluster', '类别名称']).size().unstack(fill_value=0)
cluster_category_counts
| 类别名称 | 主菜和配菜 | 乳制品 | 坚果 | 婴儿食品 | 快餐 | 水果 | 汤类 | 油和酱料 | 海鲜 | 烘焙食品 | 甜食 | 绿叶蔬菜 | 肉类 | 蔬菜 | 蘑菇 | 谷物 | 饮料 | 香料 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cluster | ||||||||||||||||||
| 0 | 26 | 11 | 0 | 0 | 36 | 4 | 9 | 13 | 4 | 29 | 25 | 1 | 35 | 5 | 1 | 4 | 2 | 3 |
| 1 | 27 | 5 | 19 | 1 | 5 | 82 | 54 | 35 | 4 | 53 | 58 | 47 | 0 | 78 | 1 | 51 | 78 | 13 |
| 2 | 33 | 42 | 0 | 1 | 3 | 0 | 4 | 5 | 74 | 19 | 11 | 3 | 65 | 1 | 6 | 4 | 2 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | 0 | 8 | 1 | 0 | 2 | 0 | 1 | 0 | 5 | 3 | 8 | 0 | 6 | 0 | 7 | 1 | 30 |
聚类0:多样化主食和配菜
- 主要营养特点:
- 热量适中(303.90)
- 蛋白质(177.65)、碳水化合物(144.26)和脂肪(171.12)含量均衡
- 钠含量较高(415.16)
- 维生素A含量高(1087.77)
- 主要食品类别:
- 主菜和配菜(26)
- 快餐(36)
- 烘焙食品(29)
- 肉类(35)
- 甜食(25)
聚类1:水果、谷物和饮料
- 主要营养特点:
- 热量较低(180.77)
- 碳水化合物含量最高(133.18)
- 蛋白质(99.78)和脂肪(71.88)含量较低
- 钾含量较高(228.40)
- 维生素A(507.39)和维生素C(123.10)含量适中
- 主要食品类别:
- 水果(82)
- 饮料(78)
- 谷物(51)
- 蔬菜(58)
聚类2:高蛋白食品
- 主要营养特点:
- 热量适中(238.39)
- 蛋白质含量最高(265.63)
- 钙含量高(112.29)
- 磷含量高(211.22)
- 维生素B含量最高(244.22)
- 主要食品类别:
- 乳制品(42)
- 肉类(74)
- 海鲜(19)
聚类3:高脂肪特殊食品
- 主要营养特点:
- 热量极高(902.00)
- 脂肪含量极高(193.00)
- 维生素A含量极高(130000.00)
- 维生素D含量高(250.00)
- Omega-3 (DHA, DPA, EPA) 含量高(174.00)
- 胆固醇含量高(570.00)
- 主要食品类别:
- 油和酱料(1)
- 根据之前查看的,应该是鳕鱼肝油。
聚类4:富含矿物质的食品
- 主要营养特点:
- 热量适中(308.18)
- 碳水化合物含量高(164.78)
- 钙含量最高(523.28)
- 铁含量极高(38.41)
- 钾含量最高(1192.79)
- 维生素A含量极高(5784.02)
- 维生素K含量高(156.58)
- 主要食品类别:
- 坚果(8)
- 香料(30)
- 绿叶蔬菜(5)
8.结论
本项目结合“该营养素是否为人类必需”、“该营养素是否提供能量”对数据集统计的营养素进行了分类,重新构建新的数据,并且对新数据进行营养成分比较分析、统计检验、营养密度分析、高斯混合模型聚类分析,得到如下结论:
- 海鲜、肉类和坚果类食品的蛋白质含量最高;谷物类、甜食和烘焙制品的碳水化合物含量最高;坚果类、油和酱料以及快餐食品的脂肪含量最高;快餐食品和烘焙制品的反式脂肪含量相对较高,尤其是快餐食品,有较大的离群值。
- 坚果类食品热量最高,油和酱料类食品的热量次之,甜食类热量分布范围大,快餐食品、烘焙产品和一些主菜及配菜的热量也较高;乳制品、肉类和海鲜的热量处于中等水平,谷物类食品热量分布较广,从低到高都有;水果、蔬菜和蘑菇类食品的热量最低。
- 热量主要与脂肪含量正相关,其次是蛋白质和碳水化合物,这反映了脂肪是主要的热量来源。
- 矿物质之间普遍存在中等到强的正相关,特别是镁、磷和钾。这可能反映了它们在食物中的共同存在模式。
- 维生素E和K高度相关,表明它们可能常见于相同的食物来源,特别是在某些植物性食品中。
- Omega-3和Omega-6脂肪酸之间存在强相关,这可能反映了它们在某些食物(如某些鱼类和植物油)中的共同存在。
- 蛋白质含量与多种矿物质(如磷、硒、锌)正相关,表明高蛋白食品往往也富含这些矿物质。
- 维生素C与多数其他营养素的相关性较弱或为负,这可能反映了其在新鲜水果和蔬菜中的独特分布。
- 胆固醇与碳水化合物的负相关性可能反映了动物性食品(高胆固醇)和植物性食品(高碳水)的区别。
- 根据Kruskal-Wallis H检验的结果,所有营养成分都显示出在不同食品类别之间存在显著差异(所有p值都远小于0.05)。
- GMM聚类把数据分为5类,其中类0是多样化主食和配菜,类1是水果、谷物和饮料,类2是高蛋白食品,类3是鳕鱼肝油,由于维A的含量极高,导致单独为一类,类4是富含矿物质的食品。















 7370
7370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









