







1.项目背景
注意该数据为人工合成数据,结论与认知可能不符,仅供学习分析的方法。
睡眠质量作为人类健康的重要指标,受到多种复杂因素的共同影响,包括生理状况、生活习惯、环境因素以及心理状态等多个方面。这些因素在不同的情境下对个体的睡眠质量产生直接或间接的作用,而理解这些因素的交互关系对于改善整体睡眠健康至关重要。通过深入分析这些影响因素,健康专业人士可以更有效地识别出关键的干预点,从而设计出有针对性的改善策略。同时,政策制定者也可以依据数据驱动的证据,为优化公共健康资源分配和改进生活质量提供科学依据。
本研究旨在综合运用多种数据分析方法,包括描述性统计、相关性分析、聚类分析和机器学习模型,全面探讨影响睡眠质量的潜在因素。为了更精确地评估每个特征的重要性,特别关注了机器学习模型中的特征重要度分析,深入研究了模型中各因素对预测睡眠质量的贡献。这一系统化的分析框架有助于揭示影响个体睡眠质量的关键因素。
2.数据说明
| 字段名 | 说明 |
|---|---|
| Heart Rate Variability | 心率变异性:模拟的心跳间隔时间的变化 |
| Body Temperature | 体温:人工生成的体温数据,单位为摄氏度 |
| Movement During Sleep | 睡眠期间身体动了多少次:合成数据,表示人在睡觉时身体不自觉地动了多少,比如翻身、微微挪动胳膊或者腿,这些动作都会被记录下来。 |
| Sleep Duration Hours | 睡眠时长(小时):模拟生成的总睡眠时间,单位为小时 |
| Sleep Quality Score | 睡眠质量评分:合成的评分,代表睡眠的质量 |
| Caffeine Intake (mg) | 咖啡因摄入量(毫克):模拟的咖啡因摄入量,单位为毫克 |
| Stress Level | 压力水平:模拟的压力水平指数 |
| Bedtime Consistency | 就寝时间一致性:模拟的就寝习惯一致性 |
| Light Exposure Hours | 光照时长(小时):模拟的每天白天接触光照的时间,单位为小时 |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import spearmanr
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score
from concurrent.futures import ProcessPoolExecutor, as_completed
data = pd.read_csv('/home/mw/input/09134300/wearable_tech_sleep_quality.csv')
4.数据预览及预处理
# 查看数据信息
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Heart_Rate_Variability 1000 non-null float64
1 Body_Temperature 1000 non-null float64
2 Movement_During_Sleep 1000 non-null float64
3 Sleep_Duration_Hours 1000 non-null float64
4 Sleep_Quality_Score 1000 non-null float64
5 Caffeine_Intake_mg 1000 non-null float64
6 Stress_Level 1000 non-null float64
7 Bedtime_Consistency 1000 non-null float64
8 Light_Exposure_hours 1000 non-null float64
dtypes: float64(9)
memory usage: 70.4 KB
# 查看重复值
data.duplicated().sum()
0
feature_map = {
'Heart_Rate_Variability': '心率变异性',
'Body_Temperature': '体温',
'Movement_During_Sleep': '睡眠期间身体动了多少次',
'Sleep_Duration_Hours': '睡眠时长(小时)',
'Sleep_Quality_Score': '睡眠质量评分',
'Caffeine_Intake_mg': '咖啡因摄入量(毫克)',
'Stress_Level':'压力水平',
'Bedtime_Consistency':'就寝时间一致性',
'Light_Exposure_hours':'光照时长(小时)'
}
plt.figure(figsize=(15, 15))
for i, (col, col_name) in enumerate(feature_map.items(), 1):
plt.subplot(3, 3, i)
sns.boxplot(y=data[col])
plt.title(f'{col_name}的箱线图', fontsize=14)
plt.ylabel('数值', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()

# 检查睡眠时长 + 光照时长的时间是否异常
abnormal_data_direct = data[data['Sleep_Duration_Hours'] + data['Light_Exposure_hours'] > 24]
# 返回异常记录数量及查看部分异常数据
abnormal_count_direct = abnormal_data_direct.shape[0]
abnormal_count_direct
0
大多数异常值似乎反映了真实可能发生的情况,并且不存在睡眠时长和光照时长的时间之和超过24小时的情况,但是在睡眠期间身体动的次数,不应该是负数,所以这里采取将所有负值替换为0。
# 将负值替换为 0
data['Movement_During_Sleep'] = data['Movement_During_Sleep'].apply(lambda x: max(x, 0))
5.描述性分析
data.describe(include='all')
| Heart_Rate_Variability | Body_Temperature | Movement_During_Sleep | Sleep_Duration_Hours | Sleep_Quality_Score | Caffeine_Intake_mg | Stress_Level | Bedtime_Consistency | Light_Exposure_hours | |
|---|---|---|---|---|---|---|---|---|---|
| count | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 |
| mean | 70.386641 | 36.535418 | 2.013461 | 7.471921 | 2.592946 | 148.260148 | 4.940956 | 0.504222 | 8.036684 |
| std | 19.584319 | 0.498727 | 0.965368 | 1.540699 | 2.979500 | 94.031760 | 2.032708 | 0.204137 | 2.023371 |
| min | 5.174653 | 35.029806 | 0.000000 | 3.105827 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.326689 |
| 25% | 57.048194 | 36.196879 | 1.352000 | 6.393869 | 1.000000 | 80.630719 | 3.489725 | 0.361569 | 6.726291 |
| 50% | 70.506012 | 36.531539 | 1.999749 | 7.500277 | 1.000000 | 145.717293 | 4.890507 | 0.500996 | 8.038248 |
| 75% | 82.958878 | 36.864441 | 2.660915 | 8.500418 | 2.537789 | 211.244685 | 6.399490 | 0.644680 | 9.354408 |
| max | 147.054630 | 38.096554 | 5.926238 | 12.364639 | 10.000000 | 400.000000 | 10.000000 | 1.000000 | 14.754766 |
- Heart Rate Variability(心率变异性):平均 70.39,标准差 19.58,最小 5.17,部分个体心率变异性较大。
- Body Temperature(体温):平均 36.53°C,标准差 0.50°C,最小 35.03°C,体温波动在正常范围内。
- Movement During Sleep(睡眠期间身体动了多少次):平均 2.01,标准差 0.97,最小值 0,表明多数人在睡眠时有轻微的活动。
- Sleep Duration Hours(睡眠时长):平均 7.47 小时,标准差 1.54 小时,大部分人的睡眠时长为 6-9 小时。
- Sleep Quality Score(睡眠质量评分):平均 2.59,标准差 2.98,评分范围为 1-9,反映出睡眠质量差异较大。
- Caffeine Intake (mg)(咖啡因摄入量):平均 148.26 mg,标准差 94.03 mg,部分人完全不摄入咖啡因。
- Stress Level(压力水平):平均 4.94,标准差 2.03,压力水平在不同个体间差异显著。
- Bedtime Consistency(就寝时间一致性):平均 0.50,标准差 0.20,显示就寝时间规律性分布较广。
- Light Exposure Hours(光照时长):平均 8.04 小时,标准差 2.02 小时,光照时长大多集中在 6-10 小时之间。
6.相关性分析
6.1数据检验
# 绘制散点图矩阵
sns.pairplot(data)
plt.show()
通过观察散点图矩阵,发现有些变量之间不存在线性关系,而且某些特征不满足正态分布(如:Sleep_Quality_Score),所以这里使用斯皮尔曼相关性分析,而不采用皮尔逊相关性分析。
6.2斯皮尔曼相关性分析
def plot_spearmanr(data,title,wide,height):
# 计算斯皮尔曼相关性矩阵和p值矩阵
spearman_corr_matrix = data.corr(method='spearman')
pvals = data.corr(method=lambda x, y: spearmanr(x, y)[1]) - np.eye(len(data.columns))
# 转换 p 值为星号
def convert_pvalue_to_asterisks(pvalue):
if pvalue <= 0.001:
return "***"
elif pvalue <= 0.01:
return "**"
elif pvalue <= 0.05:
return "*"
return ""
# 应用转换函数
pval_star = pvals.applymap(lambda x: convert_pvalue_to_asterisks(x))
# 转换成 numpy 类型
corr_star_annot = pval_star.to_numpy()
# 定制 labels
corr_labels = spearman_corr_matrix.to_numpy()
p_labels = corr_star_annot
shape = corr_labels.shape
# 合并 labels
labels = (np.asarray(["{0:.2f}\n{1}".format(data, p) for data, p in zip(corr_labels.flatten(), p_labels.flatten())])).reshape(shape)
# 绘制热力图
fig, ax = plt.subplots(figsize=(height, wide), dpi=100, facecolor="w")
sns.heatmap(spearman_corr_matrix, annot=labels, fmt='', cmap='coolwarm',
vmin=-1, vmax=1, annot_kws={"size":10, "fontweight":"bold"},
linecolor="k", linewidths=.2, cbar_kws={"aspect":13}, ax=ax)
ax.tick_params(bottom=False, labelbottom=True, labeltop=False,
left=False, pad=1, labelsize=12)
ax.yaxis.set_tick_params(labelrotation=0)
# 自定义 colorbar 标签格式
cbar = ax.collections[0].colorbar
cbar.ax.tick_params(direction="in", width=.5, labelsize=10)
cbar.set_ticks([-1, -0.5, 0, 0.5, 1])
cbar.set_ticklabels(["-1.00", "-0.50", "0.00", "0.50", "1.00"])
cbar.outline.set_visible(True)
cbar.outline.set_linewidth(.5)
plt.title(title)
plt.show()
plot_spearmanr(data,'各变量之间的斯皮尔曼相关系数热力图',12,15)
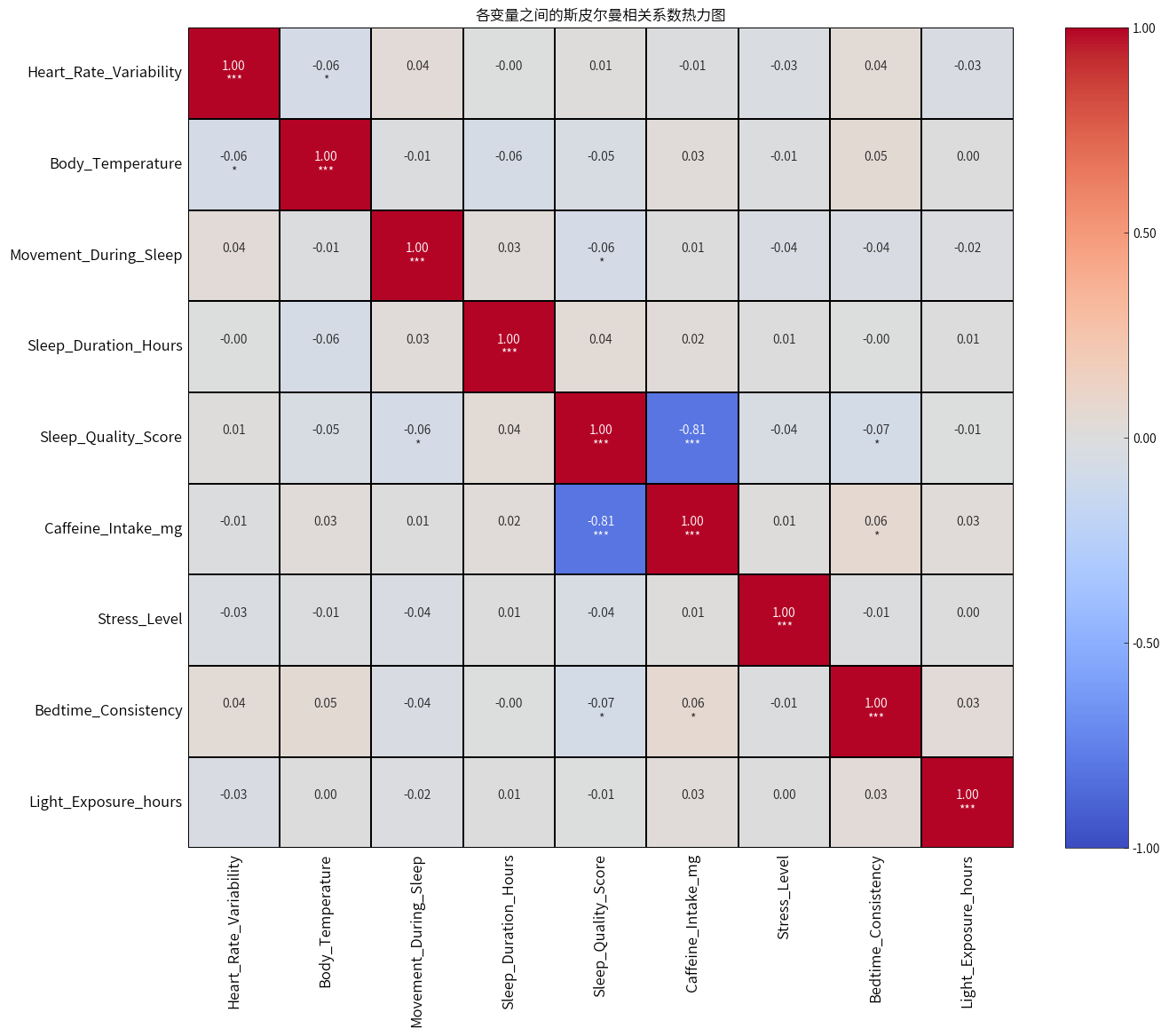
睡眠质量评分与咖啡因摄入量 的相关性较强,相关系数为 -0.81,表明咖啡因摄入量越高,睡眠质量越低。其他变量之间的相关性是弱相关,甚至是不显著的。
其实通过相关性分析,可以断定模拟生成的数据在某些变量上的相关性与现实不符,例如,压力水平与睡眠质量之间的相关性仅为 -0.04,并且是不显著的,而根据医学研究,压力大是会导致睡眠质量不好。这个数据大家就当学习方法得了,得到的结论不必当真。
7.K-Means聚类
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# 使用肘部法则来确定最佳聚类数
inertia = []
silhouette_scores = []
k_range = range(2, 11)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=15).fit(data_scaled)
inertia.append(kmeans.inertia_)
silhouette_scores.append(silhouette_score(data_scaled, kmeans.labels_))
plt.figure(figsize=(15,5))
plt.subplot(1, 2, 1)
plt.plot(k_range, inertia, marker='o')
plt.xlabel('聚类中心数目')
plt.ylabel('惯性')
plt.title('肘部法则图')
plt.subplot(1, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o')
plt.xlabel('聚类中心数目')
plt.ylabel('轮廓系数')
plt.title('轮廓系数图')
plt.tight_layout()
plt.show()
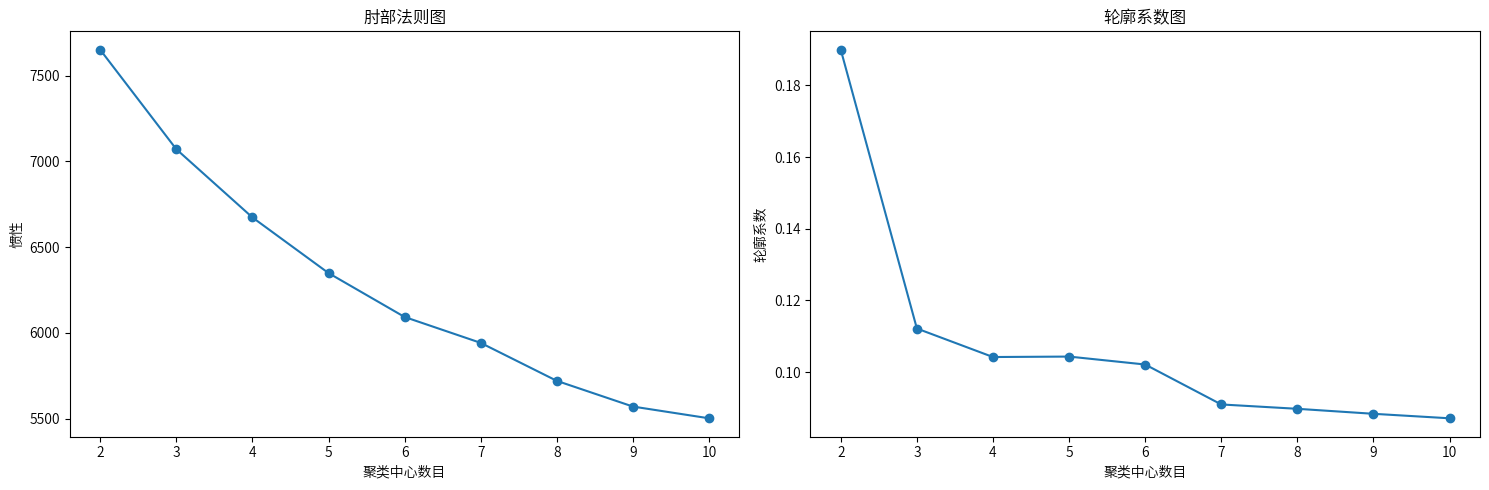
- 肘部法则(左图 - 射部法则图):这个图显示了随着聚类数量的增加,聚类内误差平方和的变化。需要寻找图中的"肘部",即曲线开始平缓的点。在这个图中,肘部似乎出现在 4 或 5 个聚类处。在 4 或 5 之后,误差减少的速度明显变缓。
- 轮廓系数图(右图 - 轮廓系数图):这个图显示了不同聚类数下的轮廓系数。通常选择轮廓系数最高的点。从图中可以看出,虽然2个聚类的轮廓系数最高,但这可能过于笼统,无法捕捉数据的复杂性,可以考虑 3 和 5。
综上所述,选择5作为聚类数。
kmeans = KMeans(n_clusters=5, random_state=15)
kmeans.fit(data_scaled)
# 获取聚类标签
cluster_labels = kmeans.labels_
# 将聚类标签添加到原始数据中以进行分析
data['Cluster'] = cluster_labels
# 聚类中心热力图
cluster_centers = scaler.inverse_transform(kmeans.cluster_centers_) # scaler.inverse_transform() 是撤销之前的标准化操作。
center_df = pd.DataFrame(cluster_centers, columns=data.drop(['Cluster'],axis=1).columns.tolist())
plt.figure(figsize=(15,10))
sns.heatmap(center_df, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('聚类中心热力图')
plt.xlabel('特征')
plt.ylabel('聚类')
plt.show()
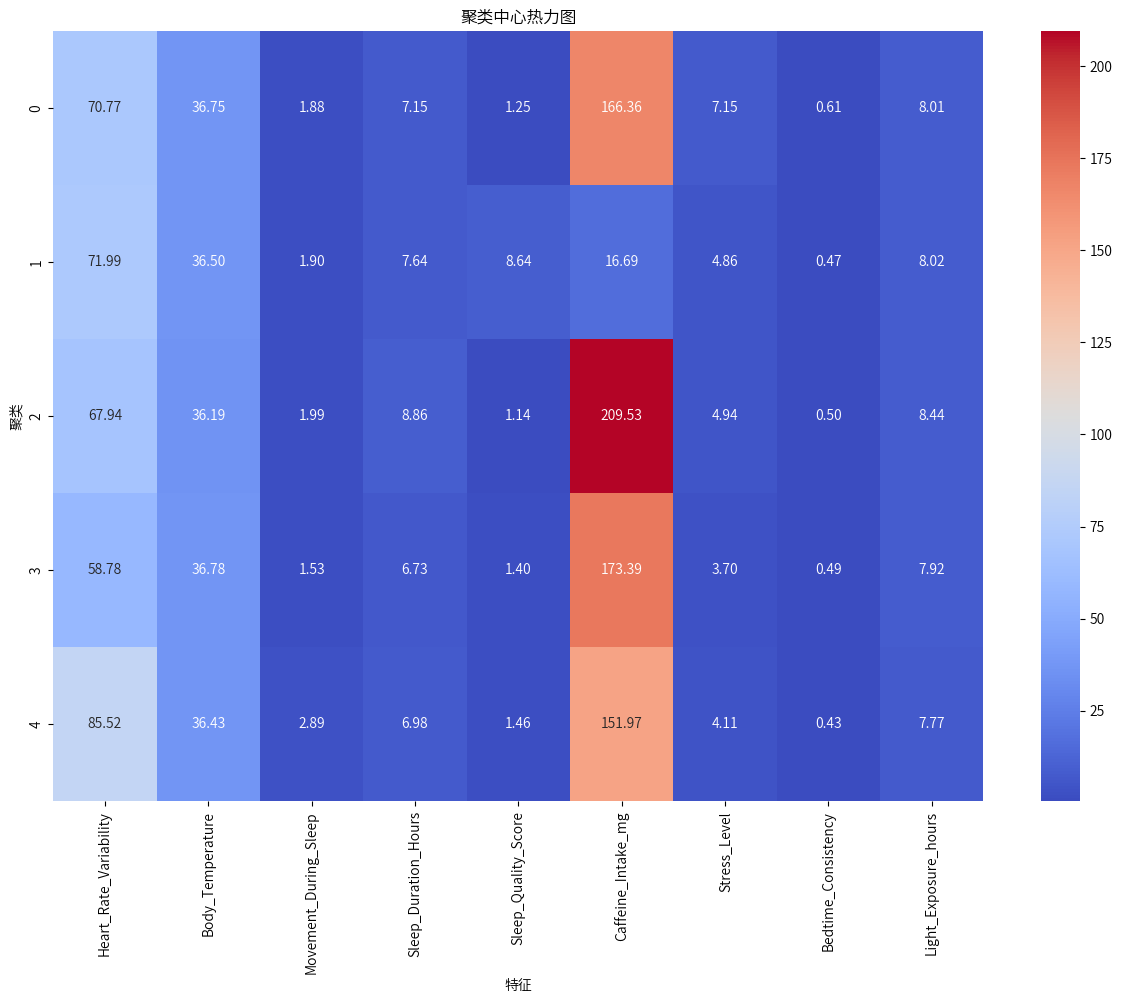
聚类0:中等咖啡因摄入(166.36mg),较高的心率变异性(70.77),平均睡眠质量(1.25)。
聚类1:最低咖啡因摄入(16.69mg),最高睡眠质量得分(8.64),适中的压力水平(4.86)。
聚类2:最高咖啡因摄入(209.53mg),最长睡眠时间(8.86小时),但睡眠质量较低(1.14)。
聚类3:较高咖啡因摄入(173.39mg),最短睡眠时间(6.73小时),较低的压力水平(3.70)。
聚类4:最高心率变异性(85.52),中等咖啡因摄入(151.97mg),最高的睡眠中身体活动(2.89)。
8.预测睡眠质量情况
8.1数据预处理
这里先划分数据,然后对划分后的数据进行标准化。
x = data.drop(['Sleep_Quality_Score','Cluster'],axis=1)
y = data['Sleep_Quality_Score']
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=15) #37分
# 标准化特征
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
8.2多类模型对比
LinearRegression: 普通最小二乘线性回归。
Ridge: 岭回归,使用L2正则化。
Lasso: Lasso回归,使用L1正则化。
ElasticNet: 弹性网络回归,结合了L1和L2正则化。
DecisionTreeRegressor: 决策树回归器。
RandomForestRegressor: 随机森林回归器,基于多个决策树。
GradientBoostingRegressor: 梯度提升回归器。
SVR: 支持向量回归。
# 定义要比较的模型
models = {
'Linear Regression': LinearRegression(),
'Ridge': Ridge(),
'Lasso': Lasso(),
'ElasticNet': ElasticNet(),
'Decision Tree': DecisionTreeRegressor(),
'Random Forest': RandomForestRegressor(),
'Gradient Boosting': GradientBoostingRegressor(),
'SVR': SVR()
}
def evaluate_model(name, model, x_train, y_train, x_test, y_test):
# 确保在每个进程中数据都是可写的
x_train = np.array(x_train, copy=True)
y_train = np.array(y_train, copy=True)
x_test = np.array(x_test, copy=True)
y_test = np.array(y_test, copy=True)
# 训练模型
model.fit(x_train, y_train)
# 预测
y_pred = model.predict(x_test)
# 计算性能指标
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 进行交叉验证
cv_scores = cross_val_score(model, x_train, y_train, cv=5, scoring='r2')
return {
'Model': name,
'MSE': mse,
'R2': r2,
'CV R2 Mean': cv_scores.mean(),
'CV R2 Std': cv_scores.std()
}
# 并行比较模型
results = []
with ProcessPoolExecutor() as executor:
future_to_model = {executor.submit(evaluate_model, name, model, x_train_scaled, y_train,x_test_scaled, y_test): name
for name, model in models.items()}
for future in as_completed(future_to_model):
results.append(future.result())
# 将结果转换为DataFrame并排序
results_df = pd.DataFrame(results)
results_df = results_df.sort_values('R2', ascending=False).reset_index(drop=True)
results_df
| Model | MSE | R2 | CV R2 Mean | CV R2 Std | |
|---|---|---|---|---|---|
| 0 | Gradient Boosting | 0.071456 | 0.992029 | 0.993121 | 0.004540 |
| 1 | Random Forest | 0.096973 | 0.989183 | 0.990418 | 0.006201 |
| 2 | Decision Tree | 0.173508 | 0.980645 | 0.986661 | 0.005627 |
| 3 | SVR | 2.611040 | 0.708742 | 0.714067 | 0.020412 |
| 4 | Ridge | 4.254570 | 0.525409 | 0.523051 | 0.028100 |
| 5 | Linear Regression | 4.254754 | 0.525388 | 0.523042 | 0.028175 |
| 6 | Lasso | 5.281707 | 0.410833 | 0.406346 | 0.010150 |
| 7 | ElasticNet | 5.382337 | 0.399608 | 0.395257 | 0.009843 |
- 最佳模型:Gradient Boosting 是表现最好的模型,其 CV R2 Mean 为 0.9931,这表明它在预测睡眠质量分数方面非常出色。
- 树基模型表现优异:前三名(Gradient Boosting、Random Forest 和 Decision Tree)都是树基模型,这表明数据可能存在非线性关系或复杂的特征交互。
- 线性模型表现一般:线性模型(如Linear Regression、Ridge、Lasso 和 ElasticNet)表现相对较差,这进一步证实了数据中可能存在非线性关系。
- SVR 表现中等:支持向量回归(SVR)的表现介于树基模型和线性模型之间,这可能是因为它能够捕捉一些非线性关系,但不如树基模型灵活。
- 模型稳定性:所有模型的 CV R2 Std 都相对较小,这表明模型性能在不同的交叉验证折上都比较稳定。
8.3模型特征重要度分析
# 训练 Gradient Boosting 模型
gb_model = GradientBoostingRegressor(random_state=15)
gb_model.fit(x_train_scaled, y_train)
# 获取特征重要性
feature_importance = gb_model.feature_importances_
feature_names = x.columns
# 创建特征重要性 DataFrame
feature_importance_df = pd.DataFrame({
'feature': feature_names,
'importance': feature_importance
}).sort_values('importance', ascending=False)
feature_importance_df
| feature | importance | |
|---|---|---|
| 4 | Caffeine_Intake_mg | 0.990874 |
| 5 | Stress_Level | 0.003470 |
| 2 | Movement_During_Sleep | 0.003008 |
| 3 | Sleep_Duration_Hours | 0.002455 |
| 6 | Bedtime_Consistency | 0.000082 |
| 1 | Body_Temperature | 0.000049 |
| 0 | Heart_Rate_Variability | 0.000035 |
| 7 | Light_Exposure_hours | 0.000026 |
# 可视化特征重要性
plt.figure(figsize=(12, 8))
sns.barplot(x=feature_importance_df['importance'],y=feature_importance_df['feature'])
plt.title('梯度提升回归特征图')
plt.xlabel('重要性')
plt.ylabel('特征')
plt.show()
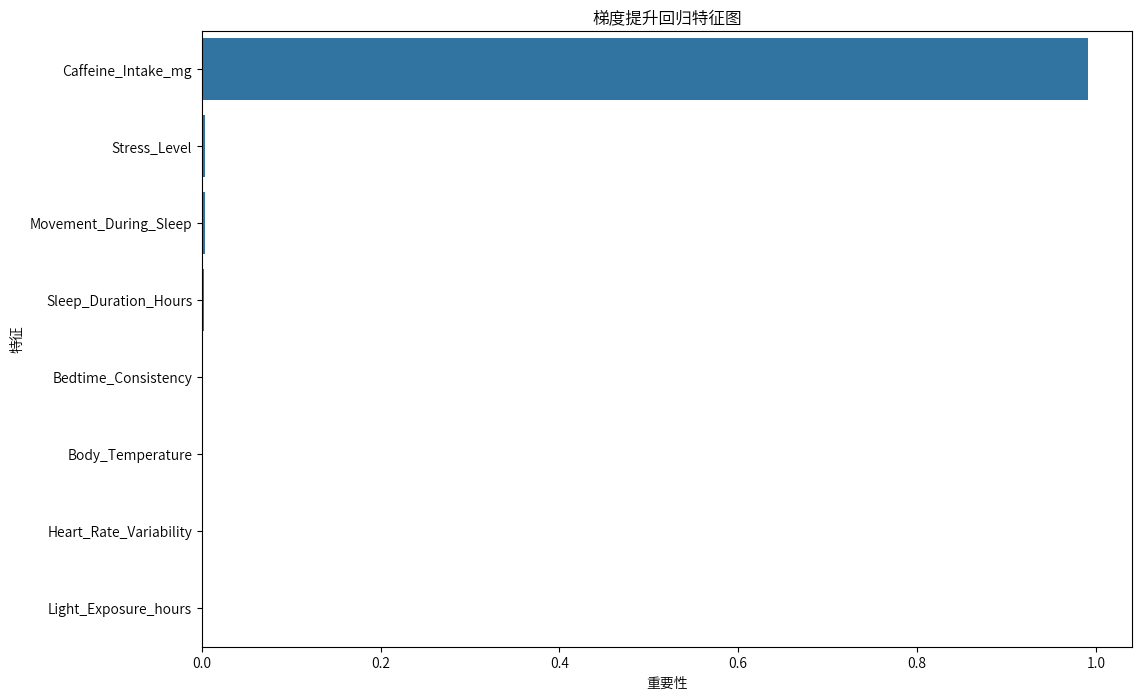
咖啡因摄入量(Caffeine_Intake_mg)是对睡眠质量影响最大的因素,其重要性分数接近1。这表明咖啡因摄入量在预测睡眠质量时起着决定性作用,与之前斯皮尔曼相关性分析结果一致,只有这个因素与睡眠质量有显著的负相关,其他因素基本上都是不显著的。
9.结论
本项目通过描述性统计、相关性分析、聚类分析和机器学习模型四个主要维度,深入探讨了影响睡眠质量的多种因素。研究得出以下关键结论:
- 描述性统计分析
- 心率变异性(HRV):平均值70.39,标准差19.58,最小值5.17,显示部分个体HRV波动较大。
- 体温:平均36.53°C,标准差0.50°C,最低35.03°C,总体波动在正常范围内。
- 睡眠中动作次数:平均2.01次,标准差0.97,最小值0,表明大多数人睡眠中存在轻微活动。
- 睡眠时长:平均7.47小时,标准差1.54小时,多数人睡眠时间在6-9小时之间。
- 睡眠质量评分:平均2.59分,标准差2.98,评分范围1-9分,反映睡眠质量个体差异显著。
- 咖啡因摄入量:平均148.26mg,标准差94.03mg,部分受试者完全不摄入咖啡因。
- 压力水平:平均4.94,标准差2.03,个体间压力水平差异明显。
- 就寝时间一致性:平均0.50,标准差0.20,表明就寝时间规律性分布广泛。
- 光照时长:平均8.04小时,标准差2.02小时,大多数人光照时间集中在6-10小时区间。
- 相关性分析
斯皮尔曼相关性分析揭示,睡眠质量评分与咖啡因摄入量呈强烈负相关(相关系数-0.81),表明咖啡因摄入量越高,睡眠质量倾向于越低。其他变量间关联性较弱或不显著。
- 聚类分析
K-Means聚类将数据分为5类,各类特征如下:
- 聚类0:中等咖啡因摄入(166.36mg),较高HRV(70.77),平均睡眠质量(1.25分)。
- 聚类1:最低咖啡因摄入(16.69mg),最高睡眠质量(8.64分),中等压力水平(4.86)。
- 聚类2:最高咖啡因摄入(209.53mg),最长睡眠时间(8.86小时),但睡眠质量较低(1.14分)。
- 聚类3:较高咖啡因摄入(173.39mg),最短睡眠时间(6.73小时),较低压力水平(3.70)。
- 聚类4:最高HRV(85.52),中等咖啡因摄入(151.97mg),睡眠中活动最频繁(2.89次)。
- 机器学习模型比较
- Gradient Boosting模型表现最优,CV R2 Mean达0.9931,预测睡眠质量分数准确度极高。
- 树基模型(Gradient Boosting、Random Forest、Decision Tree)整体表现优异,暗示数据可能存在复杂的非线性关系或特征交互。
- 支持向量回归(SVR)性能介于树基模型和线性模型之间,能捕捉部分非线性关系。
- 线性模型(Linear Regression、Ridge、Lasso、ElasticNet)表现相对欠佳,进一步证实数据中可能存在显著非线性关系。
- 特征重要度分析
Gradient Boosting模型分析显示,咖啡因摄入量是影响睡眠质量的最关键因素,其重要性分数接近1。这一发现与先前的相关性分析结果高度一致,再次确认了咖啡因摄入量与睡眠质量之间的显著负相关关系。















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









