







本文内容转载自:Informer:高效长序列时间序列预测模型(更新中)
文章目录

1. 简介:
Informer是一种专为 长序列时间序列预测(LSTF) 设计的Transformer模型。相较于传统的Transformer,Informer具备了三个独特特点。首先,他采用 ProbSparse自注意力机制,具有O(LlogL)的时间复杂度和内存使用。能够有效捕获序列中的长期依赖关系。其次,通过 自注意力蒸馏技术,Informer能够高效处理极长的输入序列。最后,Informer的 生成式解码器 可以一次性预测整个长时间序列,在预测过程中大幅提高了效率。经过大规模数据集的实验验证,Informer在LSTF问题上表现优秀,为长序列时间序列预测提供了一种高效准确的解决方案,克服了传统Transformer模型的限制。
2.传统Transformer在时序预测方面缺点和Informer改进方法:

3.Informer整体架构:
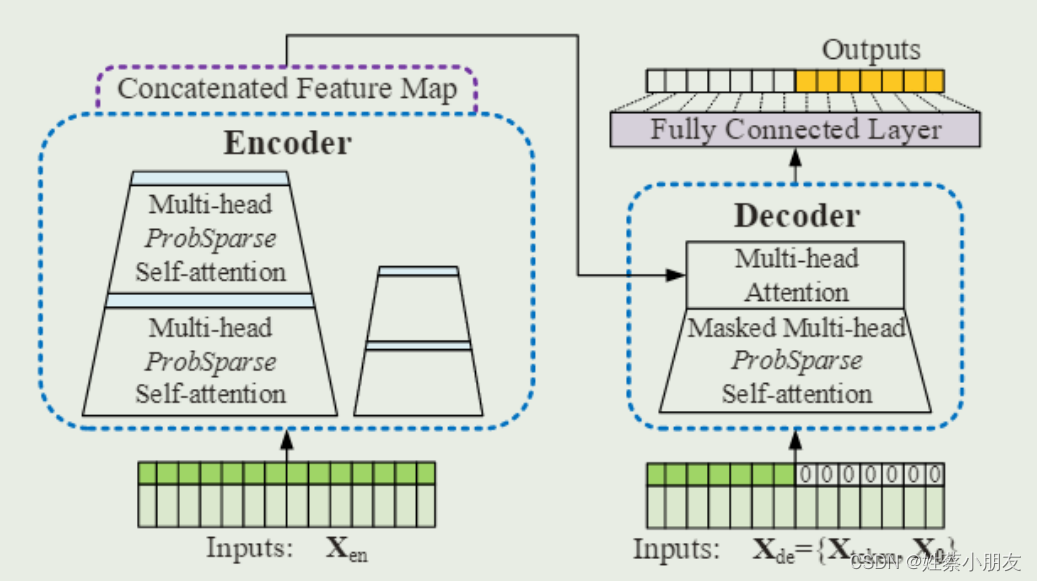
4.Informer优化详解:
4.1 ProbSparse Self-attention:
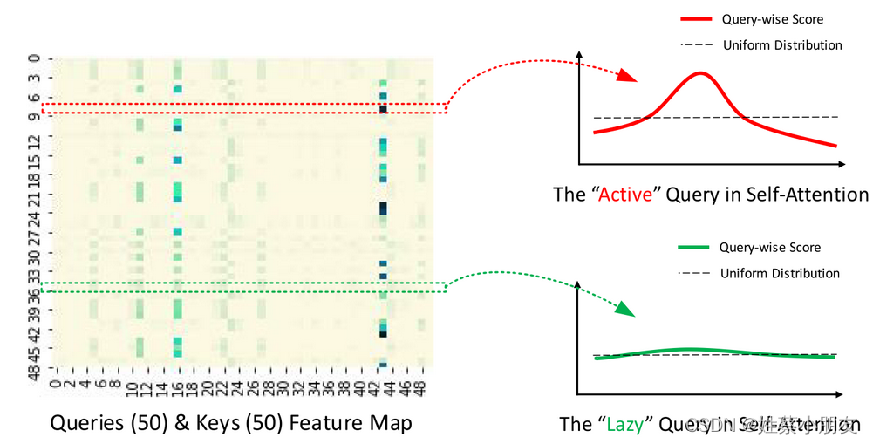
通过以上图可以看到,并不是每个q与k之间都具有很高的 相关性(内积),即 不是所有q都具有很高的活跃度,我们不需要花很多时间在处理这些弱活跃度的q上,因为这些q提取不出数据间的相关性和好的特征。这就是该算法改进的突破口。
改进算法如下:
(1)输入序列长度为96,首先在K中进行采样,随机选取25个k。
(2)计算每个q与25个k的内积,现在一个q一共有25个得分。
(3)每个q在25个得分中,选取最高分的与均值算差异。
(4)这样我们输入的96个q都有对应的差异得分,我们将差异从大到小排列,选出差异前25大的q。
(5)其他淘汰掉的q使用V向量的平均来代替。
4.2 Self-attention Distilling:
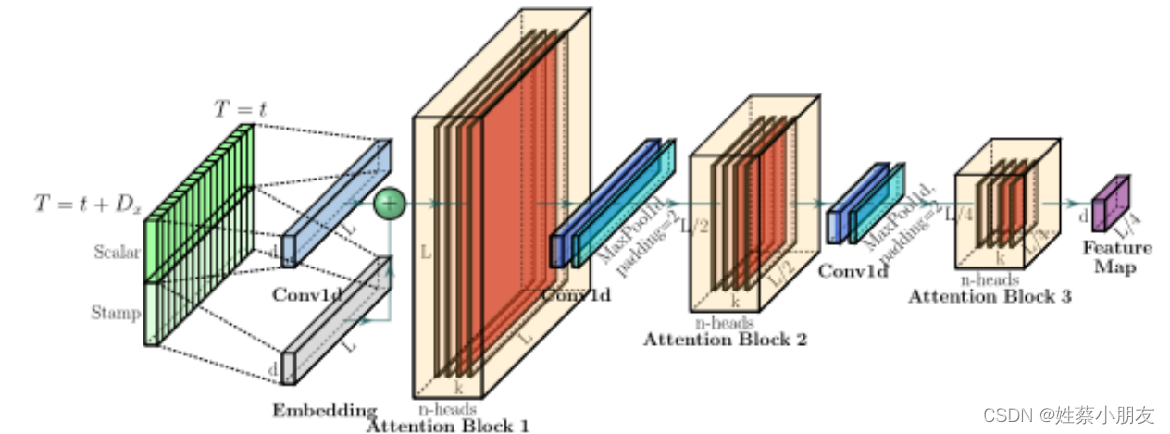
在相邻的Attention Block之间加入卷积池化操作,来对特征进行降采样。对输入维度进行修剪,堆叠n层,每层输入序列长度减半,从而将空间复杂度降低到O(nlogn)。
4.3 Generative Style Decoder:
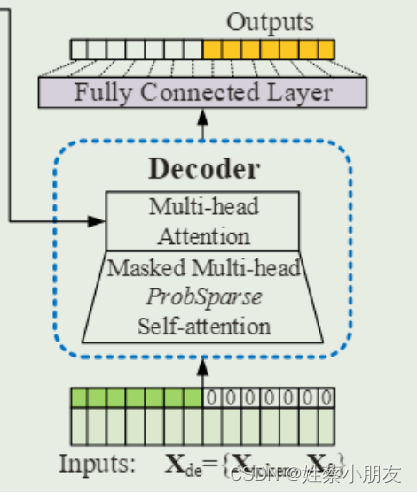
源码中的decoder输入长度为72,其中前48是真实值,后24是预测值。我们可以理解为一段有效的标签值(48个真实值)带着一群预测值(24个待预测值)进行学习,这种方法可以一步到位生成目标序列,不需要再使用动态解码。
4.4 Positional Encoding:
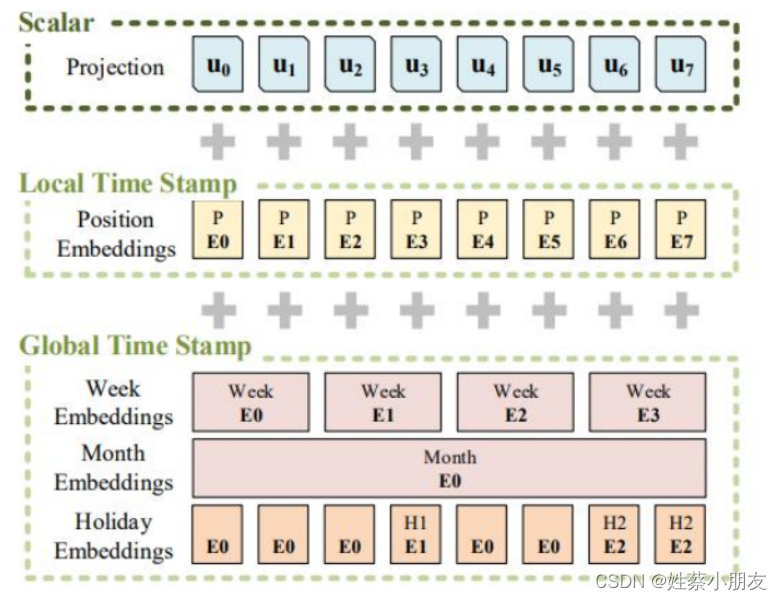
Informer在Transformer位置编码(Local Time Stamp)的基础上,加入了Global Time Stamp,可以更好的提取输入序列中的时间特征。
Encoder输入改进如下:
- Scalar:Embedding升维
- Local Time Stamp:位置编码
- Global Time Stamp:提取时间特征
5.模型输入输出角度理解Informer训练和预测过程:
数据集:BDG2
(小时维度的数据) 数据规格:17420 * 320
Batch_size:32
5.1 Encoder Embedding输入:
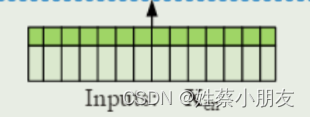
Xenc = 32 × 96 × 320
- 32为batch大小,一个batch有32个样本,一个样本代表96个时间点的数据。
- 320为每个数据的维度,表示每个时间点数据(每行)有320列。
Xmark = 32 × 96 × 4
- 32 × 96同上,表示每个时间点的数据都要有一个位置编码,Xmark与Xenc每行一一对应。
- 4为时间戳,例如我们用小时维度的数据,那么4分别代表年、月、日、小时,
5.2 Decoder Embedding输入:
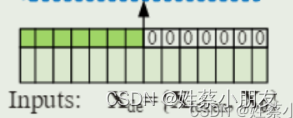
Xdec = 32 × 72 × 320
Xmark = 32 × 72 × 4
- 72=48+24,其中48为Encoder96的后48个时间点数据,用这些真实值来带一带预测值,24为待预测值。
- 48为绿色部分,24为白色部分填充0(mask机制)
5.3 Embedding输入输出:
将维度为320/7的一个时间点的数据投影成维度为512的数据。
5.31 输入:
32 × 96/72 × 320
32 × 96/72 × 4
5.32 输出:
32 × 96/72 × 512
5.4 ProbSparse Self-attention输入输出:
5.41 输入:
32 × 8 × 96 × 64 (8 × 64 = 512,这也是多头的原理,即8个头)
5.42 Active输出:
32 × 8 × 25 × 64 (只取25个活跃q)
5.43 Active+Lazy输出:
32 × 8 × 96 × 64 (除了25个活跃q,其余q用V向量的平均来代替)
5.43 多头注意力合并:
32 × 96 × 512
5.5 Encoder输入输出:多个Encoder和蒸馏层的组合
5.51 输入:
32 × 96 × 512(来自上面embedding 长度为96的部分)
5.52 输出:
32 × 51 × 512(这里的51应该是conv1d卷积取整导致的,因为源码要自行调整,所以是这样的)
5.6 Decoder输入输出:
5.61 输入:
32 × 51 × 512 & 32 × 72 × 512(32 × 51 × 512是Encoder输出,32 × 72 × 512是Decoder Embedding后的输入)
5.62 输出:
32 × 72 × 512
6. Informer代码介绍:
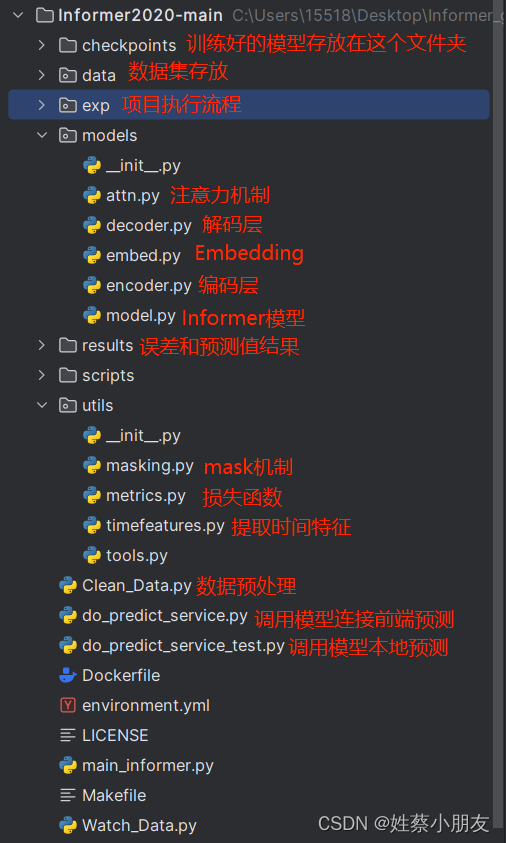
6.1 项目结构:
6.2 参数讲解:
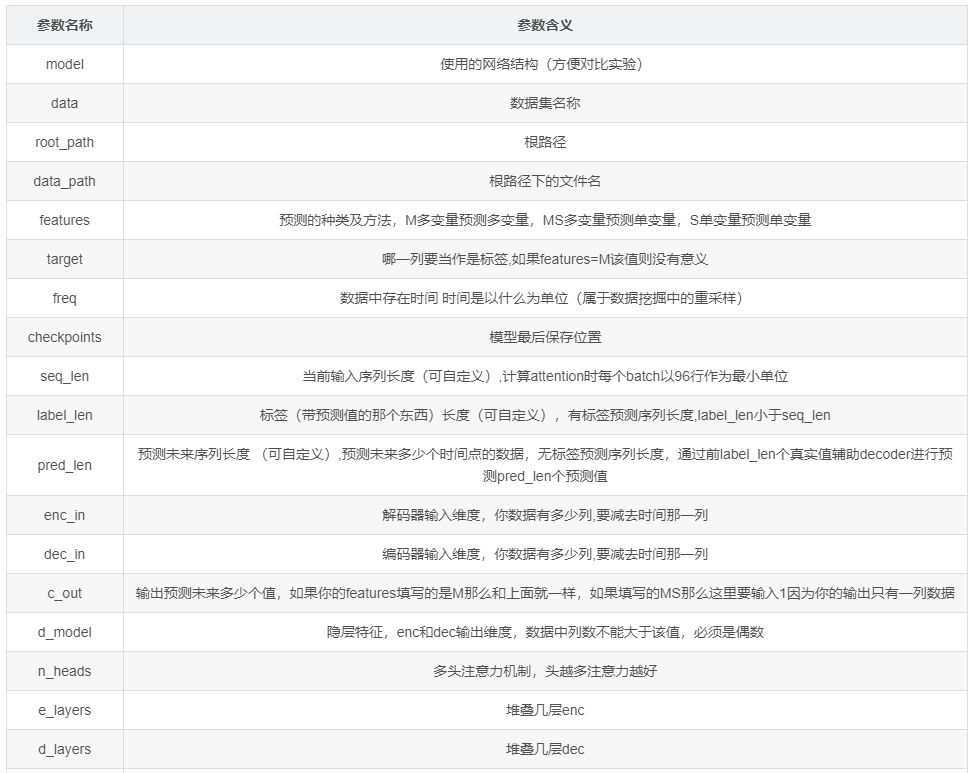
6.3 替换自己的数据集并调优:
3.1固定参数调整:
# 读的数据是什么(类型 路径)
parser.add_argument('--data', type=str, default='ECL_Rat', help='data')
parser.add_argument('--root_path', type=str, default='./data/ETT/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ECL_Rat.csv', help='data file')
# 预测的种类及方法,M多变量预测多变量,MS多变量预测单变量,S单变量预测单变量
parser.add_argument('--features', type=str, default='MS', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
# 哪一列要当作是标签,如果features=M该值则没有意义
parser.add_argument('--target', type=str, default='Rat_lodging_Christine', help='target feature in S or MS task')
# 数据中存在时间 时间是以什么为单位(属于数据挖掘中的重采样)
parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
# 编码器、解码器输入维度,你数据有多少列,要减去时间那一列。!!!注意!!!:数据中列数不能太多
parser.add_argument('--enc_in', type=int, default=269, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=269, help='decoder input size')
# 输出预测未来多少个值,如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据
parser.add_argument('--c_out', type=int, default=1, help='output size')
3.2数据字典中增加数据集信息:
#定义数据文件字典
data_parser = {
'ETTh1': {'data': 'ETTh1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTh2': {'data': 'ETTh2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTm1': {'data': 'ETTm1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTm2': {'data': 'ETTm2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'WTH': {'data': 'WTH.csv', 'T': 'WetBulbCelsius', 'M': [12, 12, 12], 'S': [1, 1, 1], 'MS': [12, 12, 1]},
'ECL': {'data': 'ECL.csv', 'T': 'MT_320', 'M': [321, 321, 321], 'S': [1, 1, 1], 'MS': [321, 321, 1]},
'electricity_cleaned': {'data': 'electricity_cleaned.csv', 'T': 'Hog_office_Denita', 'M': [270, 270, 270], 'S': [1, 1, 1], 'MS': [270, 270, 1]},#逗号不能去?
'ECL_Rat': {'data': 'ECL_Rat.csv', 'T': 'Rat_lodging_Christine', 'M': [269, 269, 269], 'S': [1, 1, 1], 'MS': [269, 269, 1]},
'ECL_Fox': {'data': 'ECL_Fox.csv', 'T': 'Fox_education_Jaclyn', 'M': [7, 7, 1], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
}
#配置每个文件处理数据的方式,有三种处理方式可选:data_loader类下{Dataset_ETT_hour,Dataset_ETT_minute,Dataset_Custom}
data_dict = {
'electricity_cleaned': Dataset_Custom,
'ETTh1':Dataset_ETT_hour,
'ETTh2':Dataset_ETT_hour,
'ETTm1':Dataset_ETT_minute,
'ETTm2':Dataset_ETT_minute,
'WTH':Dataset_Custom,
'ECL':Dataset_Custom,
'ECL_Rat': Dataset_Custom,
'ECL_Rat_UsePredict': Dataset_Custom,
'ECL_Fox': Dataset_Custom,
'ECL_Fox_UsePredict': Dataset_Custom,
}
3.3用于调优的参数:
在大概了解模型原理的基础上,采用控制变量法逐一对各个参数值调整+对比实验结果,找到一组最优参数。
# 当前输入序列长度(可自定义),计算attention时每个batch以96行作为最小单位
parser.add_argument('--seq_len', type=int, default=72, help='input sequence length of Informer encoder')
# 标签(带预测值的那个东西)长度(可自定义),有标签预测序列长度,label_len小于seq_len
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
# 预测未来序列长度 (可自定义),预测未来多少个时间点的数据,无标签预测序列长度,通过前label_len个真实值辅助decoder进行预测pred_len个预测值
parser.add_argument('--pred_len', type=int, default=168, help='prediction sequence length')
# 隐层特征,enc和dec输出维度,数据中列数不能大于该值,必须是偶数 初始512,最优912,但是内存占用过高,选择次优624
parser.add_argument('--d_model', type=int, default=624, help='dimension of model')
# 多头注意力机制,头越多注意力越好 初始8,最优14
parser.add_argument('--n_heads', type=int, default=10, help='num of heads')
# 堆叠几层enc和dec 初始2,1 ,整体最优2,1, 2,2在一开始拟合效果特别好,最差4,2
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
# 堆叠几层encoder
parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers')
#全连接层(多层感知机)输出维度 初始2048(512*4),越大后面拟合度越小
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
# 对Q进行采样,对Q采样的因子数,factor=5最优
parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor')
# 数据填充
parser.add_argument('--padding', type=int, default=0, help='padding type')
# 防止过拟合数据丢弃的概率
parser.add_argument('--dropout', type=float, default=0, help='dropout')
# 训练轮数epoch,一次epoch即为完整的数据集通过一次神经网络训练 初始6,比8,10优,在训练集上过拟合
parser.add_argument('--train_epochs', type=int, default=6, help='train epochs')
# 将完整的数据集分成若干个batch,一次输入样本的数量就是batch_size,越大梯度越准确 初始32,比24,48优
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
# 停止策略,如果多少个epoch损失没有改变就停止训练
parser.add_argument('--patience', type=int, default=3, help='early stopping patience')
# 学习率
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
略。。。。。。

















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









