







论文:《UReader: Universal OCR-free Visually-situated Language Understanding with Multimodal Large Language Model》
论文地址:https://arxiv.org/abs/2310.05126
代码地址:https://github.com/LukeForeverYoung/UReader.
摘要
文本在我们的视觉世界中无处不在,传递着重要的信息,如文档、网站和日常照片。本文提出UReader,首次探索基于多模态大型语言模型(MLLM)的通用无ocr视觉情境语言理解。利用MLLM的浅层文本识别能力,我们只微调了1.2%的参数,训练成本远低于之前遵循特定领域预训练和微调范式的工作。具体来说,UReader通过统一的指令格式在广泛的视觉情境语言理解任务上进行联合微调。为了增强视觉文本和语义理解,我们进一步应用了两个具有相同格式的辅助任务,即文本阅读和关键点生成任务。我们在MLLM的编解码器架构之前设计了一个形状自适应裁剪模块,以利用冻结的低分辨率视觉编码器来处理高分辨率图像。在没有下游任务微调情况下,该单一模型在10个视觉情景语言理解任务中,有8个表现出色,设计5个领域:文档、表格、图标、自然图像和网页截图。
1.引言
利用强大的大型语言模型作为语言解码器,一些最近的工作提出了多模态大型语言模型(MLLMs),并实现有前途的视觉和语言理解性能。令人惊讶的是,在没有域内训练的情况下,MLLM在被输入具有显著文本信息的低分辨率图像时表现出浅零样本视觉文本识别能力。然而,由于图像类型的多样性和图像大小的广泛性,它们还远远不能实现通用的视觉情景语言理解,例如从文本中提取信息,从网页中阅读文本,视觉表格问答等,如图1所示。
现有的视觉情境语言理解工作根据是否依赖于现成的OCR模型或API可以分为两个阶段(Xu et al.,2021; Huang et al., 2022; Yang et al., 2021)和端到端(Davis等人2022年;Kim等人2022;Lee等人2022)的方法。这些工作都遵循特定领域的预训练和微调范例,从而导致高训练成本,例如端到端模型Donut(Kim等人,2022年)花费超过192 A100天。
受现有MLLM的浅文本识别能力的启发,在这项工作中,我们提出了用于通用无OCR视觉定位语言理解的UReader,其通过低成本指令调整来利用多模态大型语言模型(Dai et al.,2023年)。与以往的工作不同,本文通过利用现有的MLLM放弃预训练任务,并通过充分利用各种视觉位置的语言理解数据集直接对MLLM进行微调。为了充分利用MLLM强大的语言理解能力,我们将所有任务转换为视觉语言指令调优格式。此外,为了提高不同领域的文本识别和语义理解能力,我们在同一教学格式中设计了辅助文本阅读和关键点生成任务。为了利用MLLM的低分辨率编码器来处理高分辨率图像,并避免由于缩放而导致的模糊和失真问题,我们提出了一个形状自适应裁剪模块,将高分辨率图像切割成多个局部图像。每个图像首先独立地用冻结视觉编码器和可训练视觉抽象器编码,然后连接到语言解码器中。此外,我们添加了可学习的裁剪位置编码,以帮助模型关联局部图像,并添加了调整大小的全局图像,以减轻由于裁剪而导致的显著信息丢失。
我们在这项工作中的贡献有四个方面:
1.我们首先提出了多模态大语言模型的指令调优,用于无OCR的视觉情境语言理解。
2.我们构建了一个包含视觉语言理解的5个领域的自动调整数据集:文档,表格,图表,自然图像和网页截图。
3.我们设计了一个形状自适应裁剪模块,利用冻结的低分辨率视觉编码器处理高分辨率图像。
4.UReader在5个领域的10个任务中有8个实现了最先进的无OCR性能。
2.相关工作
Visually-situated Language Understanding(视觉情景语言理解)旨在理解包含丰富文本信息的图像。图像类型相当多样,包括文档、表格、图表、自然图像和网页截图。视觉情境语言理解的任务范围从视觉问答、图像字幕、信息提取到自然语言推理。
根据是否使用现成的OCR模型或API来从图像中识别文本,现有的工作可以分为两个阶段的模型(Xu et al.,2021; Huang等人,2022年; Tang等人,2023; Yang等人,2021)和端到端模型(Kim等人,2022; Davis等人,2022; Lee等人,2022年)。两阶段工作总是设计预训练任务,学习视觉输入和文本输入之间的跨通道对齐。例如,对于文档理解,UDOP(Tang等人,2023)设计联合文本布局重构任务以在给定视觉输入和保留的文本输入的情况下恢复掩蔽的文本和布局信息。LayoutLMv3应用掩码图像建模任务来恢复掩码图像标记及其周围文本和图像标记的上下文。在没有现成OCR模型的帮助下,端到端模型需要在预训练阶段使用高分辨率图像编码器学习文本识别。例如,Pix2Struct提出了一个Screenshot Parsing预训练任务,其中模型需要生成完整的HTML DOM树,只有一个掩码网页截图作为输入。Dount设计了一个预训练任务来生成文档图像中的所有文本。这些工作都遵循特定领域的预训练和微调范式,因此要求很高的训练成本,例如Donut的训练时间超过192 A100天。本文利用多模态大型语言模型的文本识别能力较低的特点,提出直接在各种类型的图像上进行指令调优,大大降低通用视觉情景语言理解的训练成本。
多模态大型语言模型是为了增强大语言模型的多模态理解能力,特别是对视觉信息的理解能力而开发的。这些工作(Huang2023; Zhu2023; Liu2023 ; Ye2023; Li2023; Dai2023)主要将预训练视觉编码器(通常为CLIP VIT-L/14(Radford2021))与强大的大语言模型(如LLaMA(Touvron2023)。)连接起来。这些MLLM显示出一些新兴的能力,包括浅零样本文本识别能力。然而,它们离普遍的视觉情景语言理解还很远。首先,由于视觉编码器的预训练数据大多是自然图像,MLLM在自然图像上显示出几乎不可接受的文本理解性能,但在其他类型(例如文档)上显示出较差的性能。其次,大多数用于视觉语言理解的图像都是高分辨率的。将它们重新调整为低分辨率以适应视觉编码器可能会导致文本模糊和失真。在这项工作中,我们建议充分利用MLLM的浅文本识别能力,并进行指令调整,以提高其跨5个领域的通用理解能力。此外,我们设计了一个形状自适应裁剪模块,以减轻文本模糊和失真的问题。
3.UReader
UReader的主要目标是有效地利用现有的MLLM来完成视觉情景语言理解任务。在这项工作中,我们利用但不限于mPLUG-Owl(Ye等人,2023)作为我们的基本MLLM。图2展示了UReader的整体架构。输入图像首先由形状自适应裁剪模块进行预处理(见第3.1节)。然后,所得到的子图像同时通过视觉编码器和视觉抽象器。为了使大型语言模型能够关联多个裁剪的子图像,我们应用裁剪位置编码模块来跨子图像引入空间信息。(in第3.2节)。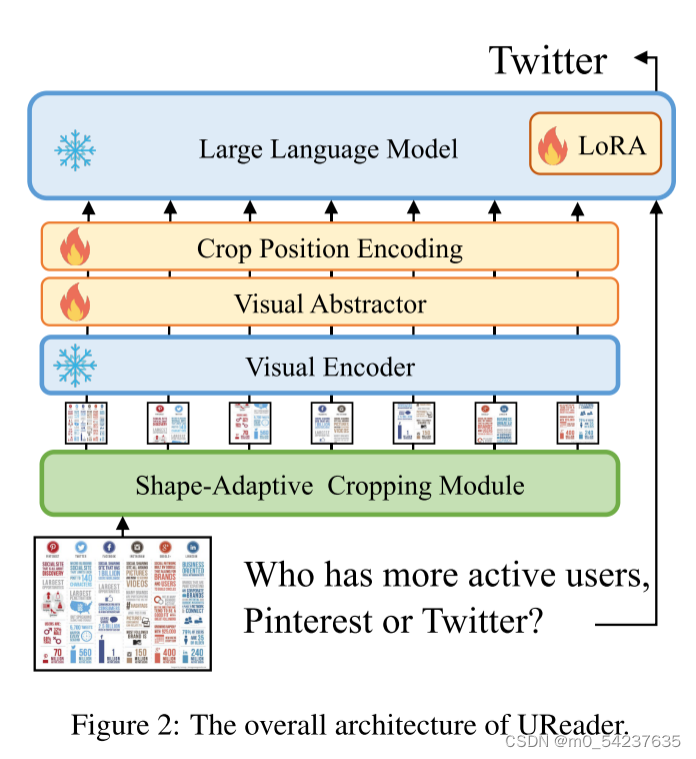
3.1形状自适应裁剪模块
带有文本的图像具有各种宽高比和各种分辨率。简单地将图像缩放到Hv、Wv(MLLM的原始分辨率)可能会导致文本模糊、失真和无法识别。因此,我们提出了一种形状自适应的裁剪模块。具体而言,如图3所示,
我们预定义了各种形状的网格,,其中
和
表示网格的行数和列数,g,和Nc表示单元格(子图像)的最大数量。为H×W形状的图像 I 选择合适的网格,应遵循两个规则:(1)网格应尽可能保持图像的分辨率,(2)网格应适合输入图像的宽高比。为了测量图像和每个网格之间的分辨率一致性和形状相似性,我们在联合Srr和Sra上计算分辨率相关和分辨率不可知的切割,如下所示:

其中IoU表示以两个矩形为中心并对齐的并集上的截面。通过最大化匹配分数来选择匹配网格:
是选定的网格。然后将输入图像调整为(
),并将其裁剪成
个局部图像。为了保持图像的全局结构信息,我们还将输入图像调整为(Hv,Wv)作为全局图像。所有的图像然后被并行地传递到视觉编码器和视觉抽象器。
视觉编码器从输入图像 I() 中提取视觉特征
,其中
,
和
分别表示所提取的视觉特征的数量和维度。视觉抽象器通过一些可学习的queries进一步总结视觉信息,在语言特征空间获得更高语义的视觉表示
,其中
表示语义特征空间的维数,Nq表示可学习的queries数量。
3.2基于LLM的裁剪图像建模
MLLM大多是用单个图像作为输入进行训练的。由于裁剪模块,我们需要将多个图像的视觉特征输入到语言模型中。LLM的一维位置嵌入不能反映每个子图像的空间位置,这对局部图像的相关至关重要。因此,我们结合了二维裁剪位置编码,以帮助语言模型理解裁剪图像之间的空间关系。具体来说,我们为所选网格的每个单元分配位置索引(i,j),并通过两个辅助嵌入层获得它们的行嵌入和列嵌入,如下所示: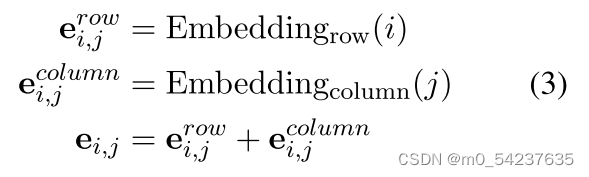
其中表示(
)的裁剪位置嵌入。通过沿着可学习查询的维度广播,将嵌入到语言空间中每个单元格的视觉特征中:
。然后将视觉特征重塑整形为
。由此产生的空间感知视觉特征和输入句子的词嵌入在序列维度上连接起来,并发送到大型语言模型。
为了增强语言模型对多幅图像的有效建模能力,同时保持较低的训练成本,我们冻结了源语言模型,并采用了低秩自适应方法(LoRA)(Hu et al.,2022)。
4.指令微调
为了开发一个(通用的,可以处理各种类型的图像,并执行不同的理解任务的)视觉情景语言理解模型,我们用一个多模态大语言模型进行了低成本的指令调整。在不引入任何大规模预训练数据集的情况下,我们直接集成多个下游数据集并进行联合训练。不同的下游任务都被重新组织为统一的指令格式(Dai 儿童案例., 2023)。除此外,设计了辅助文本阅读和关键点生成任务,以提高文本识别和语义理解能力。
4.1微调任务
统一下游任务
视觉情境语言理解的下游任务包括视觉问答、信息抽取、自然语言推理和图像字幕。为了开发一个通用的模型,我们将所有任务重新组织成指令调优格式。具体地,对于视觉问答任务,问题直接用作指令:“Human: {question} AI: {answer}"。对于信息提取任务,每个类别和值对都用一个提示表示为“Human: What is the value for the {category}? AI: {value}"。如果图像中不存在某些类别,则值为“None”。在自然语言推理任务的原始注释中,“1”表示“Entailed”,“0”表示“Refu”。我们通过构建指令"Human: {statement}, Yes or No? AI: {answer}"来重构NLI任务,其中‘Yes’表示‘Entailed’。对于图像字幕任务,参考了来自LLaVa的11个提示,以指导模型简要描述图像,并为每个描述随机选择1个提示,如"Human: Provide a brief resize crop description of the given image. AI: {caption}"。
文本阅读任务
文本识别是无OCR视觉情境语言理解的基本能力。因此,我们应用一个辅助的文本阅读任务,以加强跨不同领域的文本识别能力。利用图像中的文本和位置信息,我们按照常见的阅读顺序组织文本:从上到下,从左到右。直接利用所有文本作为目标(Kim et at.,2022)将导致模型专注于生成起始文本,忽略其他文本以降低损失。相反,我们从中随机选择一个分割位置,其中L是文本序列长度。左半部分用作输入,右半部分用作目标。p = 0意味着生成所有文本,而其他情况要求模型继续阅读输入文本。这样的设计可以强制模型根据上下文阅读文本的不同部分。起始文本始终传达有关图像的关键信息,例如图表标题。因此,我们对“0”位置应用更大的采样率(0.5),对其他位置应用0.1。为了区分阅读时从头开始阅读还是继续阅读,我们设计了两组提示语,并为每个样本随机选择1个提示语。例如,从头开始阅读的指令可以是“Human: Rec-
ognize text in the image. AI: {all texts}”,继续阅读的指令可以是“Human: The words on this picture are {left texts}. Continue reading the text. AI: {right texts}"。
关键点生成任务
大型语言模型从艰巨的语言建模任务中学习强大的理解能力。因此,为了更强的视觉和语言语义理解能力,我们提出设计一个辅助关键点生成任务,它要求模型给出一些关于图像的关键点。为了支持这项任务,我们收集了每个图像的QA对,并使用Vicuna将它们转述为陈述句(Vicuna 2023)。这些陈述句最后被视为图像的关键点。我们还构建了一组模板来指导这项任务,例如“Human: Identify some key points in this picture. AI: {key points}”。
文本阅读和关键点生成任务的所有模板参见附录D
4.2指令数据资源
文档
DocVQA (Mathew et al.,2021)包含UCSF行业文档库中12k文档图像上的50k问答对。
InfographicsVQA(InfoVQA)从互联网上收集了5k个不同的信息图并注释了30k个问答对。
DeepForm和Kleister Charity(KLC)是两个信息抽取数据集。DeepForm包含1.1k个与选举支出有关的文件。KLC的2.7k个文件来自慈善组织的公开报告。
表格
WikiTableQuestion(WTQ*)包含来自维基百科的2.1k个表格图像,并标注了23k个需要比较和算术运算的问答对。
TabFact*是一个自然语言推理数据集,其中包含关于16k个维基百科表格的112k个‘Entailed’和‘Refuted’语句。
图标
ChartQA从四个来源收集各种主题和类型的图表:Statista (statista.com), The Pew research
(pewresearch.org), OWID (ourworldindata.org) and OECD (oecd.org)。一共包含21k图标图像和32k问答对。
自然图像
TextVQA用Open Images V3中的文本过滤出28k自然图像,并注释了45k问答对。为了支持阅读理解的图像字母生成,TextCaps基于TextVAQ进一步收集了145k标题。
网页截图
VisualMRC从35个网站收集了5k个完整的网页截图。有30k个带注释的QA对,其中答案用流利的句子表达(avg.9.53单词),并且比上面提到的QA数据集长得多。
5.实验
5.1实现细节
在最近提出的名为mPLUG-Owl的MLLM上进行实验但不修改其超参数。视觉抽象器可学习的queries的数量是65。隐藏状态和
是1024。对于形状自适应裁剪模块,默认将最大单元数Nc设置为20。指令调优期间,最大序列长度被限制为2048,Hv和Hw设置为224,以匹配视觉编码器的预训练分辨率。对于LoRA,设置秩r=8,学习率调度使用36步到1e-4的线性预热,余弦衰减到0。batchsize设为256。为了提高每个数据集的手收敛性,对Doc VQA进行了3次采样,对Info VQA,WTQ,Deep Form和KLC进行2次采样。包含文本阅读和关键点生成的训练样本总数为514764。
5.2评估
使用官方的训练划分作为调优数据,并在测试划分上评估模型。根据先前的工作DocVQA和InfoVQA由ANLS评估,DeepForm和KLC通过F1评分进行评估。WTQ、TabFact和TextVQA通过准确性进行评估。ChartQA用放松的准确度进行评估。TextCaps和VisualMRC由CIDER测量。通过官方挑战网站进行TextVQA和TextCaps评价。
5.3主要结果
首先在10个数据集上将UReader与最先进的ocrfree模型进行比较。为了在所有数据集之间进行公平和一致的比较,在未报告数据集上微调了强大和可访问的基线数量。如表1所示,UReader在5个领域的8个任务中实现了最先进的性能,包括视觉问答,信息提取,自然语言推理和图像字幕任务。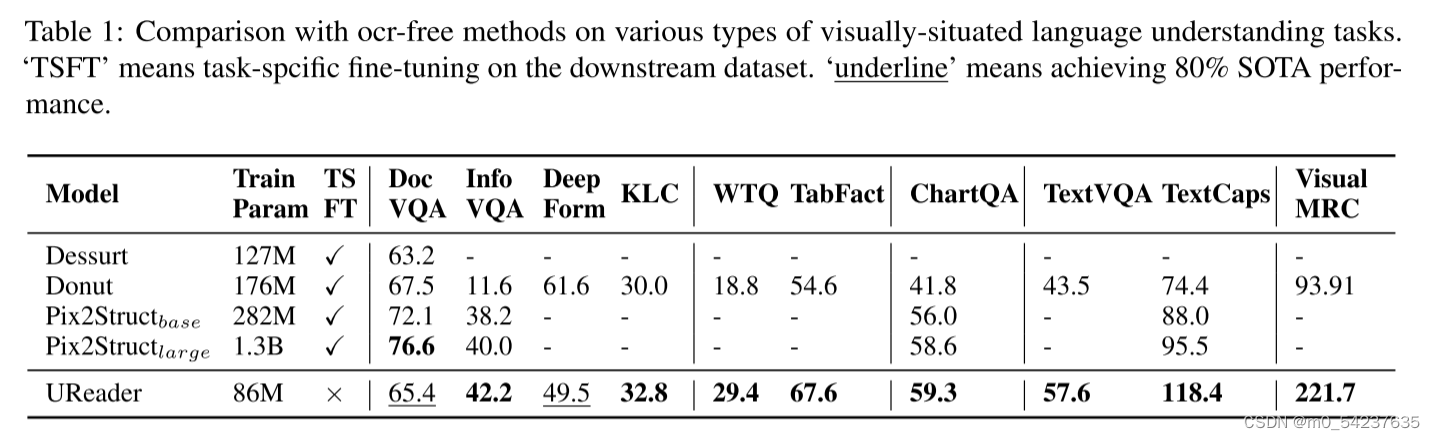
由于可训练参数少得多(86M vs 1.3B),并且没有特定的微调阶段,UReader在InfoVQA、ChartQA和TextCaps方面的表现优于强预训练模型Pix2Struct large。考虑到Pix2Struct large在128个TPU上训练了超过17万步,批量大小为1024,这验证了在开放域多模态大型语言模型的帮助下,通用视觉语言理解的学习成本可以大大降低。更详细的分析见附录B。
5.4消融实验
我们进行了全面的消融实验,以验证两个辅助任务,可训练的架构,跨域联合训练和形状自适应裁剪模块的设计的贡献。
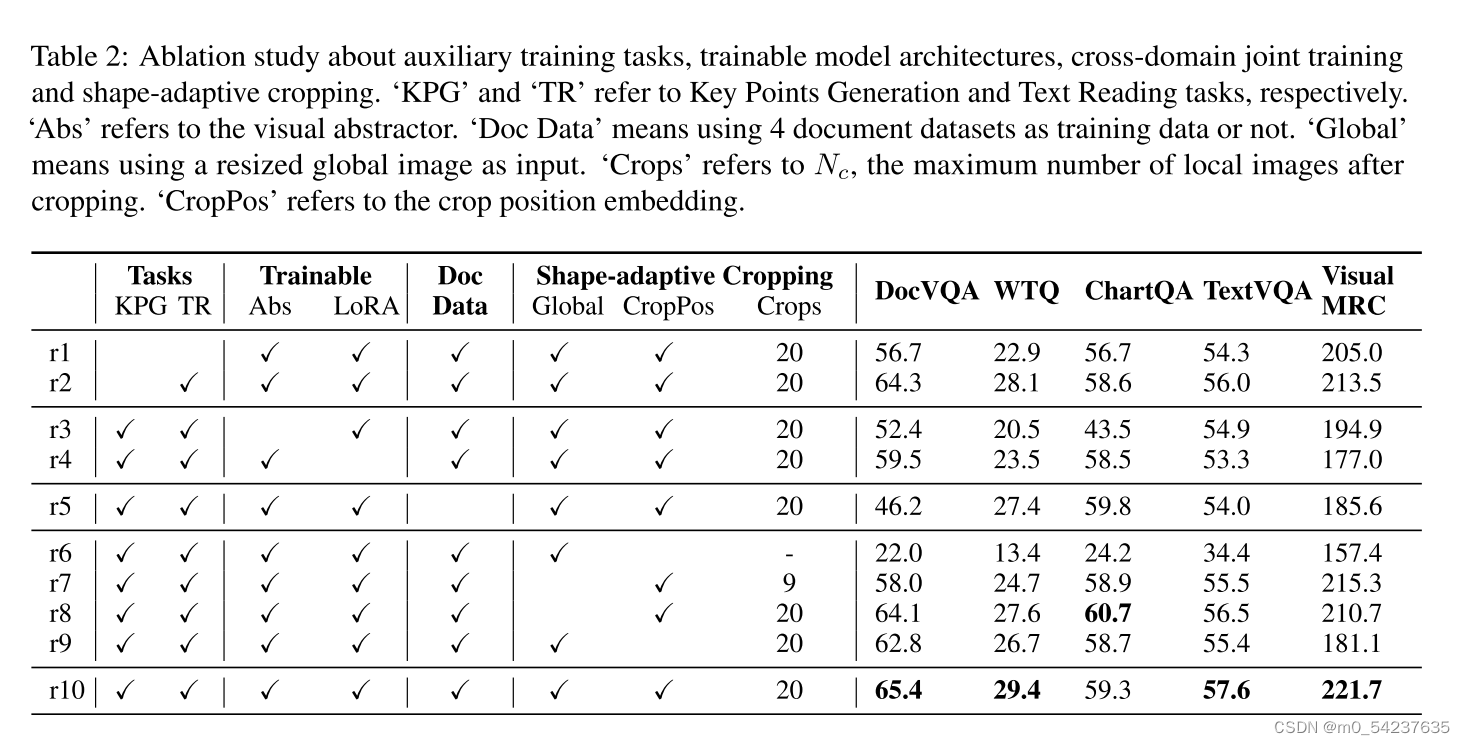
辅助任务
如表2所示,删除关键点生成任务(r10 vs r2)会导致所有数据集域的性能下降,这表明该任务有助于模型更好地理解视觉和语言语义。进一步删除文本阅读任务(r2 vs r1)会导致更显著的性能下降,这验证了在不同领域增强文本识别能力的重要性。
可训练的架构
LLM中的视觉抽象器和LoRA都在UReader(r10)中进行了微调。冻结视觉抽象器(r3)或LoRA(r4)会导致性能下降,这表明视觉和语言部分都应该进行微调,以适应视觉情景语言理解。
跨域联合训练
从训练数据中删除4个文档数据集后,UReader在表格、自然图像和网页领域的性能较差(r10 vs r5),验证了不同领域的图像具有一些共同特征,跨领域联合训练提高了通用性能。尽管在没有文档数据的情况下进行训练,所提出模型在DocVQA数据集上取得了46.2分,显示了所提出训练范式的潜在的域外理解能力。
形状自适应裁剪
表2中的r6表示直接调整mPLUG-Owl而无需任何模型修订。通过形状自适应裁剪,UReader实现了更好的性能(r7 vs r6),这表明我们的裁剪模块对于利用预训练的低分辨率视觉编码器进行通用视觉语言理解是不可或缺的。此外,增加裁剪次数(r8 vs r7)可以提高模型的性能。由于每个局部图像的分辨率都是恒定的(224x224),因此更多的裁剪意味着更高的整体分辨率,从而实现更好的性能。此外,添加调整大小的全局图像在大多数数据集中带来了轻微的改善(r10 vs r8),验证了完整的图像可以减轻由于图像裁剪而可能导致的信息丢失。最后,放弃裁剪位置编码也会损害模型的性能(r10 vs r9),证明了裁剪位置编码对相关局部图像的有效性。
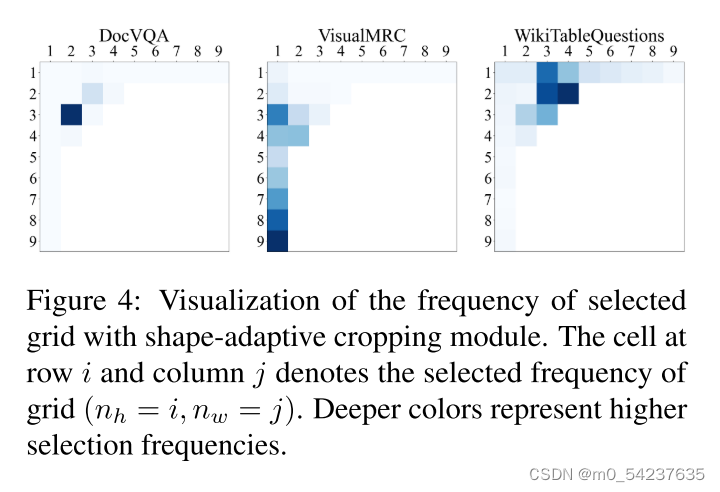
为了减缓缩放问题带来的失真问题,本文提出根据原始图像的宽高比进行裁剪。图4显示了形状自适应裁剪模块在Doc VQA,Visual MRC和WikiTableQUestion上选择的网格频率分布。(附录A:更多数据集的网格分布)处于美学目的,将分布呈现为Nc=9。显然,不同的图像具有不同的形状分布。对于DocVQA中的大多数文档图像,它们的高度大于宽度,而表格图像则相反。由于网页是可滚动的,它们的屏幕截图总是以长矩形的形式出现。通过形状自适应裁剪设计,我们的模型可以很容易地适应各种图像形状,而无需进行特定领域的微调。

文本失真对视觉问答的影响很小,因为它们通常是关于部分文本信息的。但这对阅读图像中的文本是有害的,因为每一个文本都很重要。为了定量分析形状自适应设计的影响,我们直接评估阅读所有文本的性能。我们选择Bleu作为度量,因为它直接测量真实情况和预测文本序列之间的n-gram重叠。通过从每个数据集中随机选择100个测试图像来构建评估集。如表3所示,与用固定的网格裁剪所有图像相比,由于我们的形状自适应设计缓解了文本失真问题,UReader可以更好地识别图像中的文本。
5.5定性结果

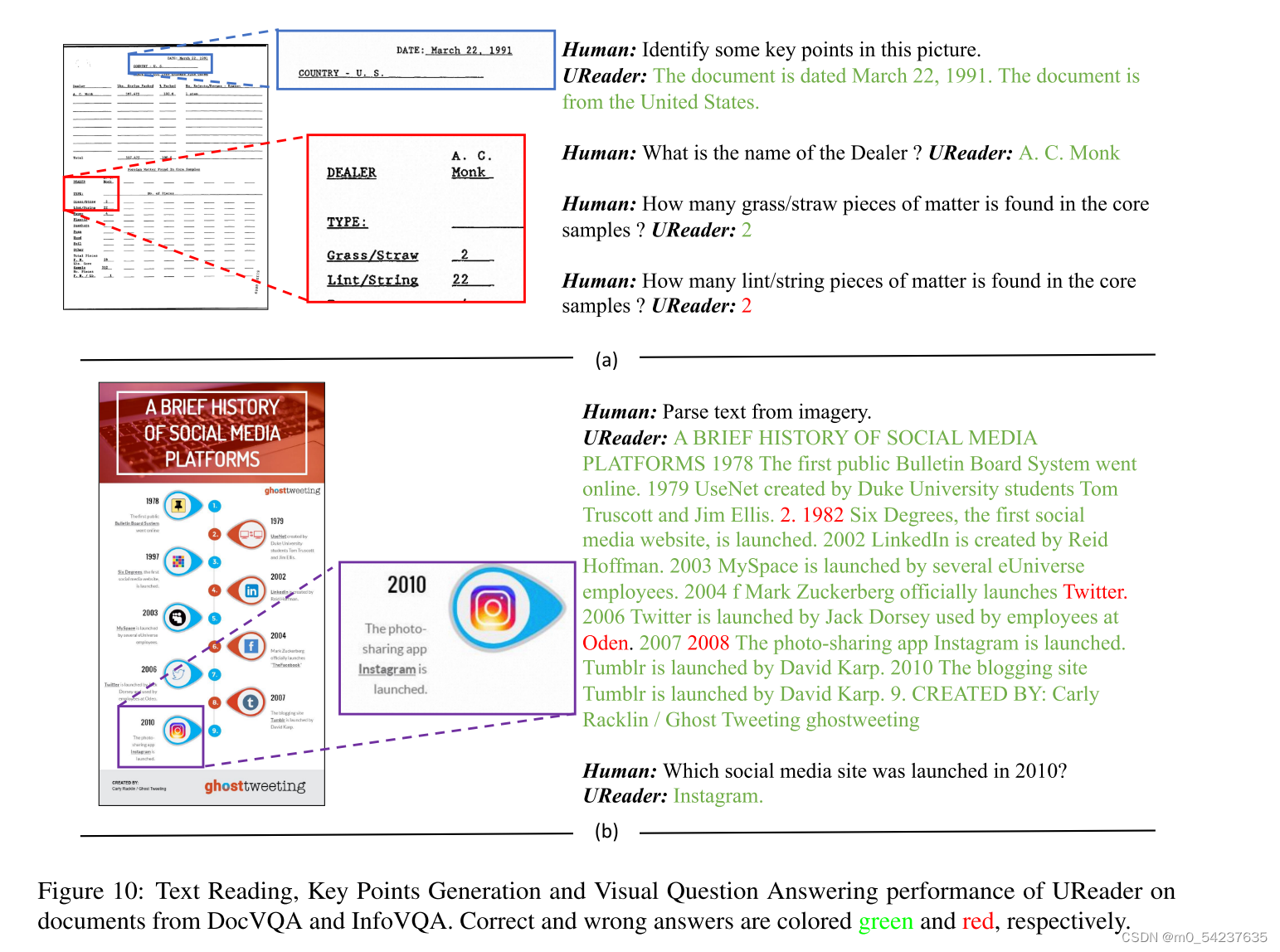
图5显示了我们的UReader在不同类型的图像上产生的一些定性结果。UReader不仅可以从文档中提取信息(情况a),还可以通过关注不同区域来理解不同的指令并提供相应的答案(情况b)。对表格的理解总是涉及到对布局的理解和统计。如案例c所示,给定一个表图像,UReader可以很好地将不同的列关联起来,以回答“第一部电影”,并执行关于“总数”的简单统计。对于包含多段文字的图像,例如案例e中的网页截图,UReader也可以定位相关段落,理解文本并准确回答问题。案例d示出了文本阅读性能。在文本阅读任务的帮助下,UReader能够从左上角到右下角阅读文本。但是,由于语言解码方式,当给定一个包含丰富文本的图像时,例如一页书,模型通常会阅读开始的文本,然后在没有观察图像的情况下继续写作。更多定性结果见附录C。最后,如案例f所示,UReader能够通过结合标题和行信息列出图表的一些关键点。在这项工作中列出关键点只是对开放式生成的一种肤浅尝试,其性能远远没有被看好,例如,UReader在最低行上出错。需要更多的努力来全面理解富文本图像。
6.结论
我们首先建议利用现有的多模态大型语言模型,通过低成本的指令调整,实现通用的无OCR的视觉语言理解。所有下游任务都被重新组织为统一的预防-调优格式。此外,我们还设计了文本阅读任务和关键点生成任务,以提高文本识别和视觉语言语义理解能力。为了利用预训练的视觉编码器处理高分辨率图像,我们设计了一个形状自适应裁剪模块,该模块根据图像的原始长宽比和分辨率将图像切割成多个局部图像。UReader在10个数据集中有8个实现了最先进的无OCR性能,从文档,表格,图表和自然图像到网页截图。
局限
我们的实验验证了UReader能够在裁剪高分辨率图像后关联局部图像。然而,UReader难以理解多页文档(例如书籍和论文),因为它缺乏将不同页面关联起来的能力,而且解码器的序列长度有限。此外,UReader为每个局部图像提供相同数量的特征到语言解码器中。但是,并不是所有的局部图像都包含丰富的视觉或文本信息。在未来,我们将探索一种更有效的方法来编码不同的裁剪方法。此外,关于视觉情境语言理解的开放式生成还远未得到很好的研究。在这项工作中,我们尝试开发关键点生成能力,但目前还没有考虑更困难的生成任务,例如给出答案的思想链。如何通过教学调优来模拟这些能力是一个值得研究的课题。最后,文本阅读任务帮助模型识别文本,但是由于幻觉问题,使用LLM作为解码器的文本阅读性能远不能令人满意。指导LLM严格按照图像阅读文本是一个具有挑战性的课题。
附录A
图6:可视化了形状自适应裁剪模块在所有十个数据集上选择的网格的频率分布。下游任务中各种各样的图像形状突出了形状自适应裁剪模块的关键作用。
附录B:模型性能详细分析
B.1在DocVQA和DeepForm上表现低于无Ocr-Free
可以看出,UReader在DocVQA和DeepForm上表现不佳。主要有两个因素:
(1)Donut对大规模文档数据集IIT-CDIP(11 M文档图像)进行预训练,这与DocVQA和DeepForm是同一领域。但是UReader没有预训练过程,只是在集成数据集(少于0.5M的分类图像)上进行指令微调。使用更多文档图像进行训练可带来更好的性能。
(2)Pix2struct的预训练任务是预测一个被屏蔽的网页截图的HTML dom树,这需要模型充分理解图像的布局信息。但UReader被训练成从上到下、从左到右阅读文本,这需要较弱的布局理解能力。对布局理解的预训练也提高了DocVQA的性能。
该结论也可以通过对其他两个数据集的观察来证实(InfoVQA和KLC)。对于InfoVQA数据集,图像是海报风格,布局不像DocVQA和DeepForm那么重要,但文本和视觉对象之间的关系更重要,如自然图像和图表图像。至于KLC数据集,无OCR模型只在第一页(总是报告的封面)提供,其中布局比DocVQA和DeepForm简单得多。因此,UReader在这两个文档数据集上的表现优于基线。
综上所述,与无OCR模型Donut和Pix2Struct相比,由于MLMM在开放域数据集上的预训练,UReader在理解图像中的跨模态关系方面更好,但在理解文本布局信息方面较弱,而无需大规模文档预训练和特定布局理解任务。
B.2与Pipeline方法相比
表4中列出了最先进的管道模型的性能。我们可以从结果中总结出两个不同的方面:
首先,与TextVQA、ChartQA、InfoVQA、TextCaps和TabFact上的管道方法相比,我们的模型实现了相当或略差的结果。
其次,我们的模型与DocVQA,DeepForm,KLC,WTQ和VisualMRC上的管道方法之间存在明显的差距。
对于第一个方面,性能相似有两个原因:
(1)建模视觉对象和文本之间的不同关系,对基于Pipeline的方法和OCR的方法都具有挑战性。TextVQA、TextCaps和InfoVQA要求理解文本和视觉对象(即徽标、图标和常见对象)之间的关系。ChartQA要求对线条进行趋势理解。理解这种复杂的跨模态关系对于ocr-free和管道方法都是具有挑战性的。
(2)任务格式的简单性可以减少性能差距。Tabfact是一个简单的二进制分类任务,导致性能差距很小。
对于第二个方面,主要的性能差距出现在三类数据集中:文档,表格和网页截图。原因有二:
(1)文本识别和布局提取方面的差距。在文档、表格和网站中,文本是占主导地位的信息源,其布局(例如表格中的行和列布局)相对于图表和自然图像而言相对统一。因此,通过预提取的文本和布局信息,更容易理解图像。但是对于OCR-Free模型,如我们的UReader和Donut,完整识别所有文本仍然具有挑战性。
(2)多页文档输入建模能力方面的差距。对于多页文档数据集KLC(98% > 4页)和DeepForm(75% > 1页),OCR Free模型只输入第一页,丢失了很多信息。
B.3零样本性能
在未知域的数据集OCR-VQA上测试了UReader的零样本性能。在相同的评估指标下,UReader在布局预测训练方面优于mPLUG-Owl(41.1 vs 28.6)和最近的工作UniDoc(41.1 vs 34.5)。结果表明,我们的方法在未知域上的零样本性能是可接受的。
附录C:更多定性结果
C.1下游任务结果
更多关于自然图像、图表、表格、文档和网页截图的定性结果见图7-11。
图11显示了一个关于VisualMRC网页屏幕截图的文本阅读和视觉问答的示例。如第5.5节所述,当给出关于阅读图像中所有文本的指令时,UReader可以阅读开始的文本,但有时很容易继续生成与视觉无关的文本。通过适当的指令,UReader确实可以识别其他区域的文本,例如“运动增加细胞循环”。因此,文本阅读过程中的幻觉问题并不是因为UReader无法识别文本,而是LLM解码器的生成方式。当从图像读取开始文本时,解码器可以根据更接近的文本上下文而不是图像来生成随后的文本。




C.2开放域结果
图12展示了开放域的例子。我们使用随机收集的图像,并根据这些图像的内容自由地向模型提问。原始的mPLUG-owl用于比较。

在图12(a)中,UReader能够准确地识别和回答关于自然图像中的小文本的问题(“乘客姓名”和“莫里斯/卡拉”)。相比之下,mPLUG-Owl在第一轮中不响应名称,即使在第二轮中有提示也会给出错误的答案。

在图12(b)中,我们提出了一个由两个级联问题组成的query,这需要模型同时理解查询所引用的非文本对象的空间位置并定位相应的字段。可以看出,UReader很好地完成了这个任务,而mPLUG-Owl在物体识别和价格提取两个方面都回答错误。
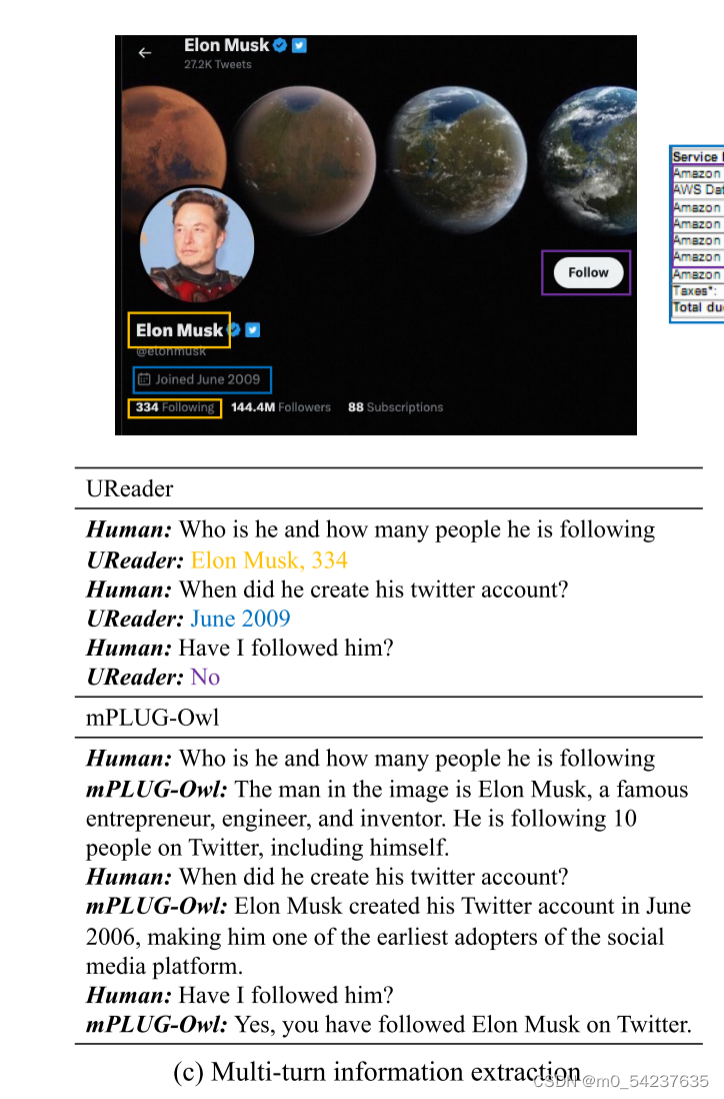
在图12(c)中,我们在屏幕截图上使用UReader进行多轮转换。这些问题包括对对话历史的引用。有些问题还需要一定的常识。比如,账号创建的时间相当于加入Twitter的时间,关注按钮的非活动状态表明用户没有关注过Iron Musk。UReader很好地回答了这些问题。mPLUG-Owl可以正确识别Iron Mush,但是否容易生成与图像无关的内容,导致一些错误的陈述。
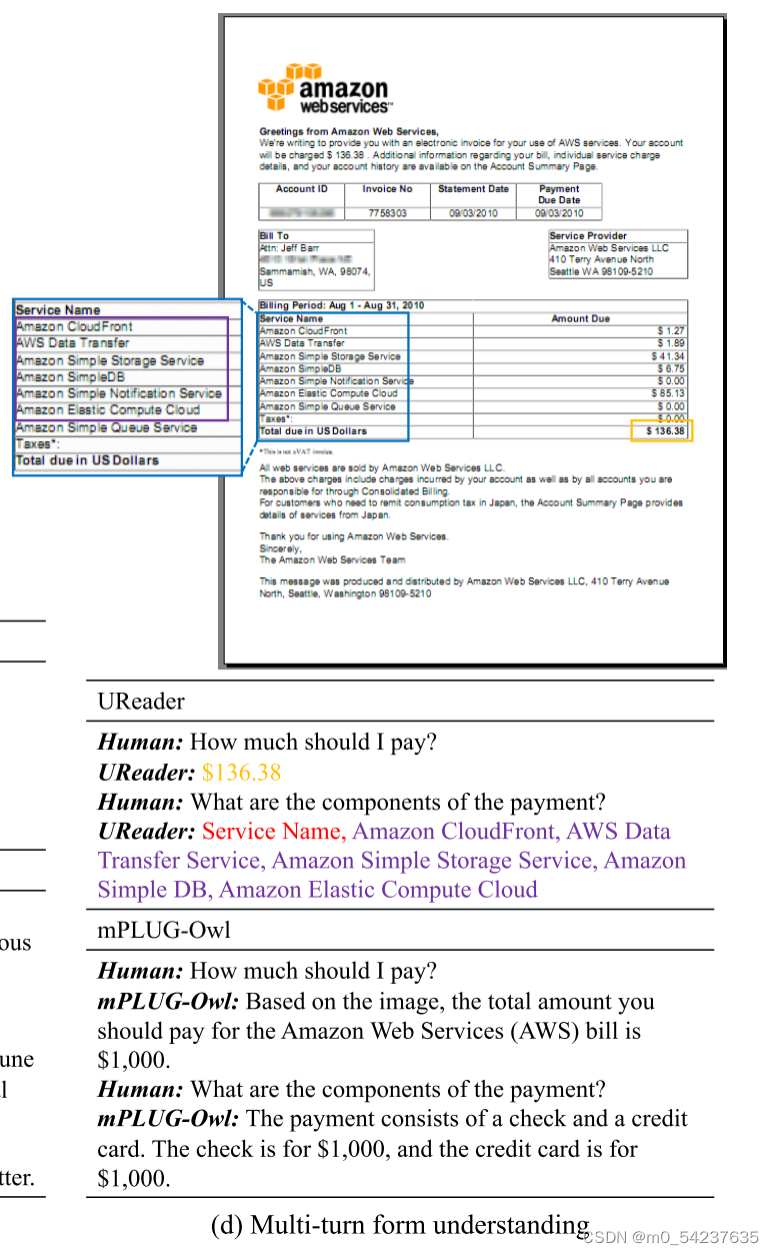
在图12(d)中,我们根据由多个表单组成的图像向UReader询问价格及其组成部分。虽然UReader错误地将标题包含在答案中,并且没有列出每个组件的价格,但我们注意到它主动过滤了价格为0美元的组件,使答案更符合用户的意图。说明UReader可以找到与问题相关的表单,全面了解表单中各个字段的含义。相比之下,由于图像中文本信息的丢失,mPLUG-owl产生的响应充满了幻觉。
这些结果表明,UReader在开放域中保持了MLMM的一些交互能力,并表现出更强的视觉情境语言理解能力。
附录D:指令模板
















 1127
1127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









