







《Learning by Applying: A General Framework for Mathematical Reasoning via Enhancing Explicit Knowledge Learning》
代码地址:https://github.com/bigdata-ustc/LeAp 没开源
摘要
数学推理是通用人工智能的关键能力之一,它要求机器从解决问题中掌握数学逻辑和知识。然而,就在推理过程中学习和应用了哪些知识而言,现有方法并不透明(因此不可解释)。
在本文中,我们提出了一个通用的学习应用(LeAp)框架,通过显性知识学习以原则性的方式增强现有模型(backbone)。在LeAp中,我们以一种新的问题-知识-表达范式进行知识学习,知识编码器从问题数据中获取知识,知识解码器将知识应用于表达推理。所学习的数学知识,包括词与词的关系和词与算子的关系,形成了一个显性的知识图,将知识的“学”与“用”有机地连接起来。
此外,对于问题的解决,我们设计了一个语义增强模块和推理增强模块,分别应用知识来提高任何backbone的问题理解和符号推理能力。从理论上证明了LeAp自主学习机制的优越性。在三个真实数据集上的实验表明,LeAp提高了所有backbone的性能,学习到更准确的知识,实现了更可解释的推理过程。
1. 引言
数学推理是通用人工智能的核心能力和智能水平的标志之一(张、王等人)。2020)。它需要机器从解决几个数学问题中掌握数学知识和逻辑思维(Loukowycz等人)。2022年;Seo等人。2015年)。其中,本文专门研究了数学应用题(MWP),这是自20世纪60年代以来一直备受关注的一项基本推理任务(Feigbaum,Feldman等人)。1963年)。图1展示了一个示例。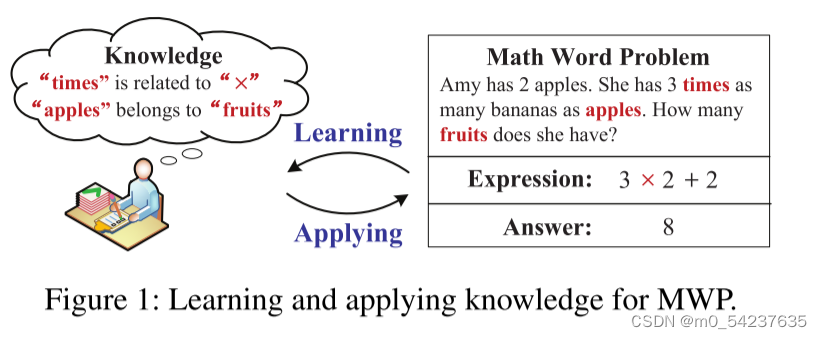
一般来说,一个数学应用题被表示为一个问题句(“Amy has…Have ?”),这就提出了一个要求未知数量的问题。要解决这个问题,机器需要理解包含单词(如’Amy‘)和数字(如‘2’)的口头描述,然后推理出一个数学表达式(如'3x2+2),最后基于这个表达式得到答案(如‘8’)。
在文献中,传统的MWP求解器包括基于规则的,基于语法的和基于语义解析的(Zhang,Wang et al. 2020)。近年来,序列到序列(Seq 2Seq)框架在MWP任务中蓬勃发展(Wang,Liu和Shi 2017; Lan等人2022),遵循问题-表达范式将问题转化为表达式,现有工作侧重于以两种方式改进MWP,包括促进问题理解(Lin et al. 2021; Kim et al. 2022)和改进表达推理(Zhang et al. 2020 a; Cao et al. 2021)。然而,这种问题-表达范式仍然远远不能涵盖人类的数学推理能力,因为它缺乏学习和应用显性知识的过程。一方面,根据认知主义的教育理论(Mowrer 1960;Muhajirah 2020),人类从解决问题中获得显性的数学知识(Liu et al.2019年),例如,单词“Times”与运算符“×”有关,而“Apple”属于图1中问题的“水果”。另一方面,人类通过在逻辑思维中应用这一知识来产生MWP的解决方案(梁等人。2018年)。有必要将这两个过程有机地集成到机器中,以建立更强大的人工智能(Tsatsou等人。2021年;De Penning等人。2011年)。
从这个角度来看,现有的MWP求解器有一些改进的空间。首先,他们忽视了显示知识的学习过程。具体来说,现有求解器的学习知识隐含在参数和网络架构中,这对人类来说是不透明的。其次,缺乏应用显式知识(例如,图1中的“时间”与“×”有关)阻碍了他们的推理能力和推理答案的可解释性。更重要的是,本文强调知识学习和应用都是人类的一般能力(Huang et al. 2020a),可以使不同的MWP求解器受益。为此,本文旨在构建一个通用框架,使不同的MWP求解器可以在其中学习和应用显式知识,以实现更好的推理能力。
但仍面临许多挑战。首先,没有明确的方案来形式化对MWP有用的、适用于不同求解器的显式知识。其次,探索一种(模拟人类如何从求解MWP中获取知识的)学习机制是具有挑战性的,同时需要具有通用性,能够适用于不同的求解器。第三,我们需要设计一种基于不同求解器架构的通用知识应用机制,目前这方面的研究还未得到充分的探索。
为应对这些挑战,我们提出了一种新的MWP 框架----LeAp,采用问题-知识-表达架构。在LeAp中,我们定义了两类明确通用的数学知识,包括词-词关系和词-运算符关系。然后,通过一个变分自动编码器VAE(VAE编码器包括一个知识编码器和一个知识解码器)来实现LeAp。
具体地说,知识编码器从问题句中获取知识,知识解码器将学习到的知识应用于推理相应的表达式。这两个部分的结合构成了我们新的“学以致用”机制。学习到的知识在中间显式地形成知识图谱,并作为连接两个组件的桥梁,这是透明的。此外,对于MWP求解,本文在知识解码器中提出了语义增强模块和推理增强模块,分别利用知识促进问题理解和符号推理。
LeAp是一个通用框架,通过提高现有MWP求解器的推理能力来受益。通过在LeAp中实例化几个backbone求解器进行了广泛的实验。在3个数据集上的实验结果表明,LeAp在答案推理、知识学习效果和推理可解释性方面都有一定的改善。
本文的贡献如下:
提出了一个通用的应用学习(LeAp)框架来学习和应用显式知识,现有的MWP求解器可以作为其backbone,并从中受益,以提高推理能力。
设计了一个新的语义增强模块和一个新的推理增强模块的知识应用,提高现有的MWP求解器的答案的准确性和推理的可解释性。
从理论上分析了自主知识学习机制在LeAp中的优势,并通过实验验证了该机制的有效性。
2. 相关工作
数学应用题
解决MWP早期工作包括基于规则的方法(Bakman, 2007;Fletcher 1985),基于统计的方法(Hosseini et al. 2014;Mitra和Baral 2016),到基于语义解析的方法(Koncel-Kedziorski等人2015;Shi et al. 2015)。它们的特点是分别依赖于手工制作的规则、机器学习模型和问题的语义结构。最近,Wang et al.(2017)首次提出了一种seq2seq模型,该模型遵循问题-表达式范式,将问题句子转化为表达式。基于这种方式,我们总结了两类先进的方法:语义为中心的和推理为中心的。具体来说,以语义为中心的方法旨在促进使用高级网络(例如图神经网络(Zhang et al. 2020b)、预训练语言模型(Liang et al. 2021;Shen等。2021;Kim等人,2022;Yu等。2021;Huang et al. 2021)),或其他信息(Lin et al. 2021;吴、张、魏2021;Huang et al. 2020b)。例如,Zhang等人(2020b)提出了Graph2Tree来捕获数量之间的关系和顺序信息。以推理为中心的方法旨在改进表达式推理过程(Wang et al. 2019;申晋2020;Cao等。2021;Jie、Li和Lu 2022),如应用目标驱动分解机制来推理表达式树的GTS (Xie和Sun 2019)。此外,Shen等人(2020)产生了多个编码器和解码器的集成,结合了它们在语义理解和推理方面的优势。
知识学习和应用
我们最重要的目标之一是,LeAp可以学习和应用MWP的显性知识。因此,本文分别从知识学习和知识应用两方面对相关工作进行了总结。对于知识学习,它期望机器从数据中获取知识(de Penning et al. 2011;Labhishetty et al. 2022)。由于LeAp中的知识形成了一个显式的知识图谱,因此一个相关的任务是链接预测(Chen等人2021;Cai和Ji 2020)(或知识图谱补全(Bansal et al. 2019;Cheng et al. 2021)),它通常使用现有的边在知识图谱中学习未知的知识(边)。例如,Bordes等人(2013)考虑了知识的语义,并将其解释为翻译操作。Pei等人(2019)通过一种新的几何视角捕获了结构信息和长程依赖性。一些研究人员还研究学习其他类型的知识,例如,背景知识,逻辑知识,以及预训练语言模型中的隐式知识。对于知识应用,各种类型的知识已经应用于许多机器学习任务中,例如会话生成,问答和推荐系统。一些特殊形式的知识(例如,逻辑规则、数学性质)也在许多研究中发挥了重要作用。我们建议读者参考Laura von Rueden等人(2021)进行的更详细的调查。特别是,Wu等人(2020)进行了一项基本尝试,将外部手动构建的知识库纳入MWP任务。
与以往关于知识学习的研究不同,LeAp通过将数学知识应用于推理答案来获得数学知识。与MWP的现有工作相比,它是一种通用的框架,使不同的求解者能够通过显性知识学习,并应用于一种新的问题-知识-表达范式,进一步提高他们的推理能力。此外,文中还提出了一个语义增强模块和一个推理增强模块,用于将知识应用于MWP求解,从而带来更好的答案精度和推理可解释性。
3. LeAp:从应用中学习
3.1 问题定义
MWP数据集记为D=(X,Y),X是问题句子的集合,Y是对应表达式的集合。具体来讲,是由n个单词token和问题P的数值组成的序列,
要么是单词token(如图一中“Amy”)或数值(如“2”)。
是m个符号的序列。每个符号
来自一个目标词表
(
由运算符集合
(如+,-,
),数值常数集合
(如π),和
中的数值
),即
。注意,由于
随p的变化而变化,不同的问题可能有不同的
。MWP的目标是训啦一个求解器,它读取问题语句
,生成一个有效的的数学表达式
,并基于
得到一个数值答案
。
知识Z被明确地表示为数学知识图谱。它的顶点包括单词和操作符,我们关注的知识是它的边是否存在。具体地,我们将Z形式化为单词-单词关系和单词-运算符关系
,即
,其中N和C是MWP任务中的单词和运算符的数量。
描述了单词
和
之间的关系(如“苹果”属于“水果”),
捕捉了单词
和运算符
之间的关系(如“倍数”与“X”有关)。
和
都是二值变量,如果单词
和单词
(或操作符
)之间存在知识,则值为1,否则值为0。注意,公式可以很容易地扩展到包含单词和操作符之间的多种关系(边),例如上下位关系和反义关系(Shehata 2009)。
我们的目标是建立一个框架:(1)从解决MWP学习数学知识Z;(2)应用知识Z推理MWP的答案。这两个目标是相互联系的,是协同实现的。
3.2 LeAp 架构
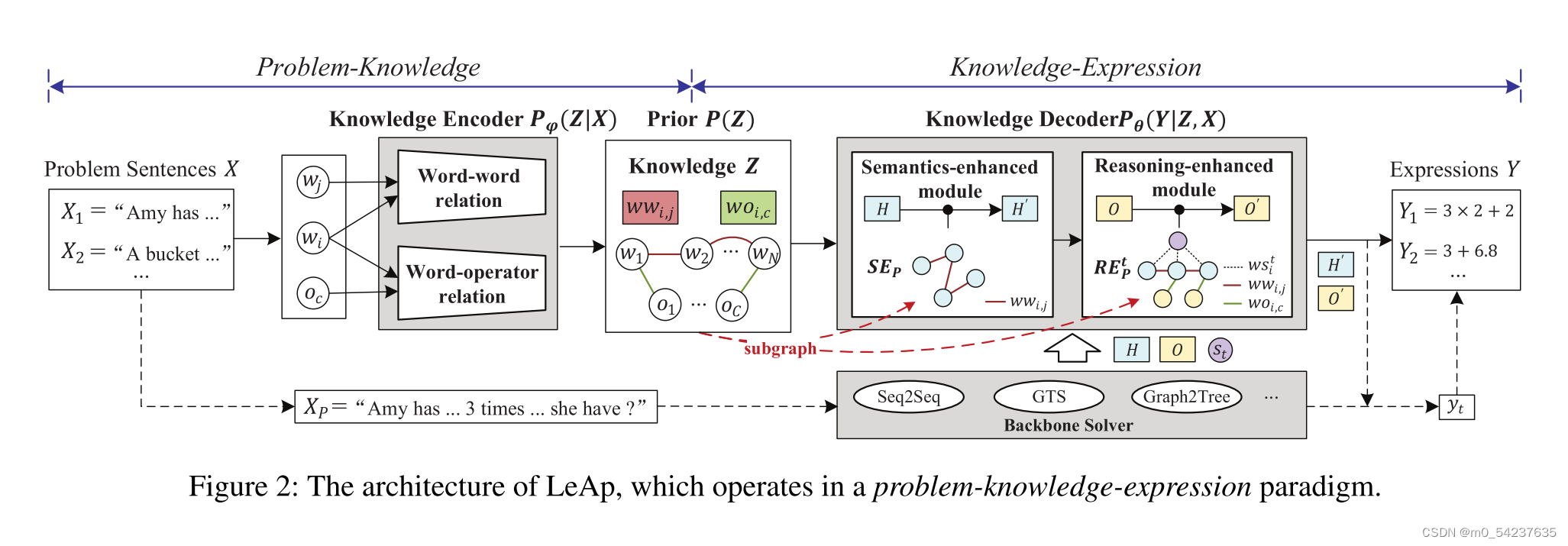
直观地说,认知主义教育理论(Mowrer 1960;Muhajirah 2020)表明,学习者通过直接应用知识(如解决图1中的问题)来培养与知识的强联系(如“时间”与“×”有关)。根据这一观点,我们用一种新的问题-知识-表达式架构构建了LeAp框架,以实现“通过应用学习知识”的机制。具体而言,问题-知识过程从问题数据中获取知识,知识表达过程将这些知识应用到答案的推理表达中,进而指导自主学习合理的知识。为此,我们将LeAp转换为变分自编码器(VAE) ,如图2所示。它由三个主要部分组成:(1)一个知识编码器Pφ(Z|X):从问题句X = {} 中获取知识Z(问题- 知识);(2)一个知识解码器Pθ(Y|Z,X),根据X和Z推理出表达式Y = {
}(知识-表达);(3)关于Z的先验知识P(Z)。LeAp的训练目标是最大化ELBO:
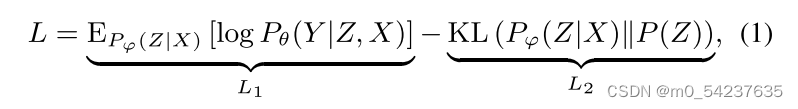
其中第一项L1优化了MWP求解的性能,第二项L2正则化了知识学习的结果。接下来,我们将依次介绍知识编码器Pφ(Z|X)、知识解码器Pθ(Y|Z,X)和知识先验P(Z)的细节。
知识编码器
知识编码器Pφ(Z|X)旨在从问题句集合X中获取显性知识Z(如图2所示),对问题-知识过程进行操作。由于和
是二值的,我们将每个单词
和运算符
分别映射到向量
(d是维数),并将
输入到不同的网络中以编码他们的伯努利分布。形式上,将知识编码器建模为:

其中σ是sigmoid函数,f1和f2是神经网络,分别转换和
的级联[·]。注意,f1, f2可以实现从MLP到预训练语言模型(Petroni et al. 2019)。由于更关注从MWP中学习知识,因此不强调它们的区别,为了简单起见,采用了MLP (Kipf et al. 2018)。
在训练过程中,知识编码器Pφ(Z|X)需要对Z采样以估计,即等式(1)中的L1。然而,使用重参数化来反向传播导数很难,因为
是二值的。因此我们在优化等式(1)时采用了等式(2)的连续近似:
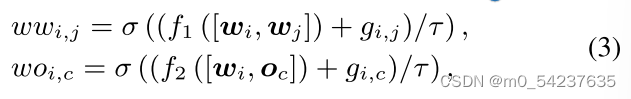
{}是i.i.d。采样自Gumbel(0,1)分布(Jang, Gu, and Poole 2016)。
是一个控制近似度的温度参数。
知识解码器
知识解码器将知识编码器获得的知识Z应用于推理表达式Y,对知识-表达过程进行操作(如图2所示)。本文旨在设计一种通用的知识应用机制,其有利于不同的求解器(如Seq2Seq,GTS),而不是提出一种特殊的求解器架构。具体而言,在知识解码器中构建了一个语义增强模块和一个推理增强模块,分别应用知识来提高问题理解和符号推理。接下来,首先将大多数现有求解器的架构统一为“Backbone求解器”。然后解释所提出模块的细节。
Backbone Solver
给定问题P,Backbone求解器首先读取问题句,然后生成单词表示
和初始推理状态
:
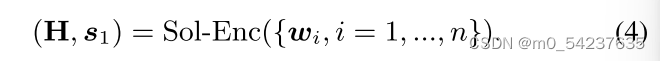
Sol-Enc进行问题理解,并在不同的求解器中捕获许多现有模型。它可以被形式化,从RNN(例如,GTS, TSN-MD), BERT(例如,MWP-BERT),到特定的MWP编码器(例如,Graph2Tree)。然后,backbone求解器为P逐步生成表达式。具体来说,在步骤t (t = 1,…,m)处,将符号
推理为:

在Sol-Dec中,是步骤t的推理状态(步骤1中的s1来自式(4))。
是符号
的嵌入向量,如果
是运算符
,则
等于
;如果
是一个数字
,则
等于
。options是一些可选的术语。具体来说,Sol-Dec、st和options的含义因不同的求解器而异。例如,在Seq2Seq中,Sol-Dec表示LSTM的输出门,
是隐藏状态,options =∅。
在生成符号之后,骨干求解器与另一个特定于求解器网络f3(如Seq2Seq中的遗忘门)推导出下一个推理状态
。
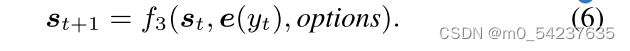
读者可以参考原始论文,了解不同Backbone求解器的更多细节。
语义增强模块
LeAp通过一个语义增强的模块提高了问题理解,用于应用单词-单词知识(例如,通过“苹果”属于“水果”的知识理解图1中的“多少水果”),这独立于特定的Backbone求解器。具体来说,对于问题P:(1)将问题P中的单词作为顶点,将它们的知识
从Z开始作为边,构建图
(如图2所示)。因此,
可以被视为整体显性知识Z的子图;(2)根据公式(4),通过原始Backbone得到单词表示
;(3)我们利用GCN在
上传递消息,以获得融合关系的知识
:
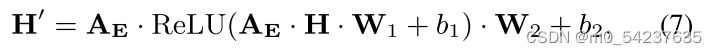
是
的邻接矩阵,
是可训练参数。
推理增强模块
介绍LeAp如何使用提出的推理增强模块来改进符号推理,该模块应用单词-单词和单词-运算符知识。直观地说,问题句中的单词“times”可以促使求解者通过“times”与“×”之间的关系知识
正确推理出符号“×”,而“×”在表达式中的位置可以根据求解者对“times”的关注程度来细化。因此,为了指导第t步的推理,首先建立当前推理状态
与P 中所有单词之间的临时关系
:
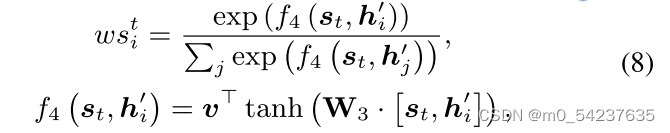
是可学习参数。
然后,结合和知识Z,为问题P构造了另一个图
。如图2所示,它的顶点集包含推理状态
,P的单词表示
,所有运算符
。边集由
和知识
组成。在
上,我们从
传播信息以增强运算符表示:

是
的邻接矩阵,
是权重矩阵和偏差。
在公式(5)中的推理符号时,如果
是运算符
,则取等式(9)中的
为
,如果
是数字
,则取等式(7)中的
。最后,利用知识Z增强后的符号表示
通过公式(6)生成下一个推理状态
,并将
演化为
。
先验知识
先验P(Z)控制LeAp的已知信息。由于知识是二值的,自然可以将以下伯努利分布作为Z的先验,并设置δ1 = 0.1作为稀疏性。
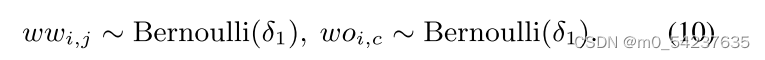
设计先验P(Z)来模拟真实的学习者。在实际应用中,学习者在不同的知识背景下可能获得不同的MWP推理性能。例如,初中生比 小学生有更好的推理能力。因此,我们可以为学习者已掌握的知识设置一个较高的δ1 = 0.5,我们可以通过引入外部知识库的部分边(例如α = 20%)来模拟这一过程。有了这种先验,LeAp也可以被引导去学习相似的知识,从而缓解捕捉虚假关联的问题。
总而言之,LeAp框架有以下优点。首先,LeAp一般将不同的MWP求解器作为骨干,使它们在学习合理知识的同时获得更好的推理能力;其次,LeAp采用问题-知识-表示架构,其中知识Z显式地形成知识图谱;因此,与以往遵循问题-表达范式的方法相比,该方法的学习结果和应用方法更具可解释性。第三,在知识Z的先验中,我们可以设置不同的α来考察不同背景下学习者的问题解决效果,这在5.3节中进一步可视化。
4. 理论分析
简而言之,LeAp从问题中学习数学知识,并将其应用于解决MWP,自然地构建了一个显式知识图(KG),如图2所示。相比之下,学习KG的一种简单方法是链接预测任务(LP)(Chen et al. 2021; Cai and Ji 2020),它直接预测每对顶点之间的边。在本节中,我们将深入研究LeAp在自主学习机制方面与LP相比的优越性。在这里,我们统一了一些重要的符号,不失一般性。具体地说,我们用来表示KG中顶点i和j之间的知识,包括词-词关系
和词-运算关系
。X表示顶点的嵌入,包括字{
}和运算符{
}。\
在详细推导之前,我们首先假设知识Z有助于解决MWP,因为我们不能期望从解决数学问题中获取与数学推理知识无关的知识(如化学知识)。因此给出以下定义:
定义1:有效知识Z:
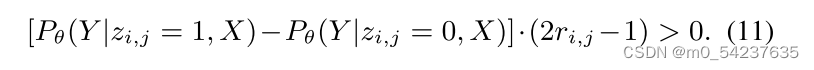
是
的真实标签,如果 i 和 j 之间存在真知识(有边),
=1,否则为0。
是LeAp的知识解码器。在定义1中,如果 i 和 j 之间存在知识(即
=1),知识解码器应用
=1比
=0能更好地推理表达式Y。相反,如果我们将假知识(即
= 0)视为真知识(即
= 1),则会引入冗余,因此此时
。
在“有效知识”假设的基础上,分析了LeAp和LP之间的差异。LP通过模型学习知识,该模型从贝叶斯的角度计算Z给定X的后验概率。相比之下,LeAp从基于x的推理表达式Y中学习知识。因此我们研究调查:
1. 等式(1)中的LeAp优化目标是否优化了后验
2. 如果等式(1)成立,是否比
更大(即更准确)
本文考虑一个简化的设置来训练LeAp,参数用从一个训练好的LP模型中初始化。在这种情况下,我们有两个定理分别回答上述两个问题。
定理1:假设在(
)的邻域U上成立,知识Z是有效的。然后,对于每个
,最大化等式(1)中的MWP求解的目标,即
,等价于最大化
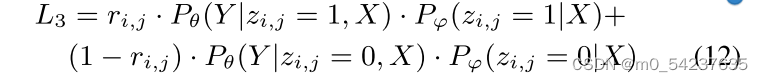
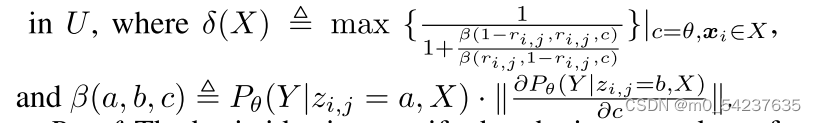
证明:基本思想是验证LeAp中的每个参数的L1和L3导数的内积都是正的。因此,在一阶泰勒近似下,L1的梯度方向隐式优化了L3。在此基础上,整个证明包括三个部分,分别对知识编码器φ、知识解码器θ和顶点嵌入X进行验证。在这里〈,〉表示两个向量的内积。
1)知识编码器中的φ
![]()
根据等式11“有效知识”定义,永远成立。
2)知识解码器中的θ
当时,可以推导出
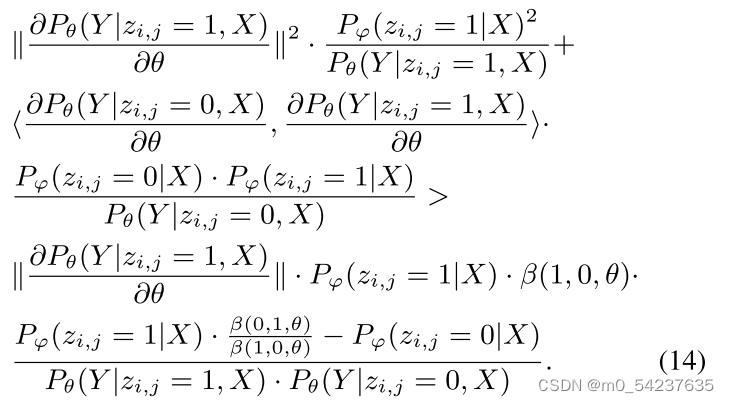
给定条件,很容易证实
![]() ,因此
,因此,
的证明是相似的。
3)对于,我们也报道了
的结果。由于LeAp是用训练的LP模型初始化的,因此
可以被视为
的局部最优解,因此
成立。基于此可以推导出
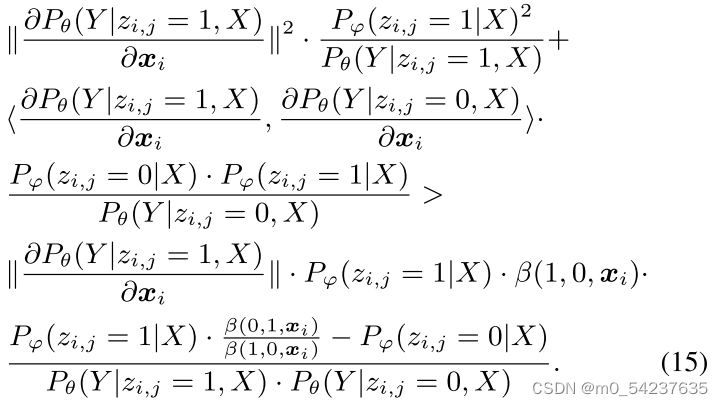
类似于等式14,很容易证实等式15大于0,因此。
在定理1中,我们注意到L3可以重写为,如果
和
重建真实分布
和
在数据集D之后。因此L3等价于下面的后验,回答了问题(1):
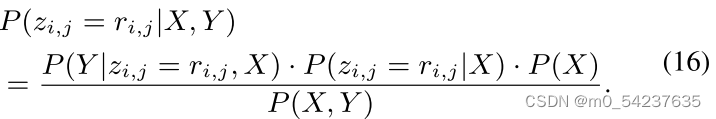
定理2:在“有效知识”假设下,以下不等式成立:
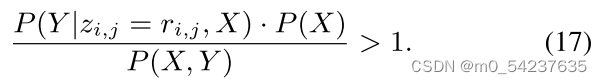
证明:P(X,Y)可以被重写为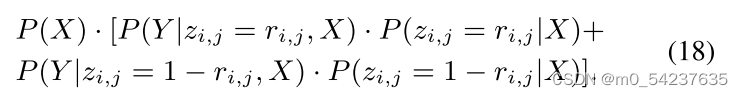
根据“有效知识”假设,![]() ,因此等式18小于
,因此等式18小于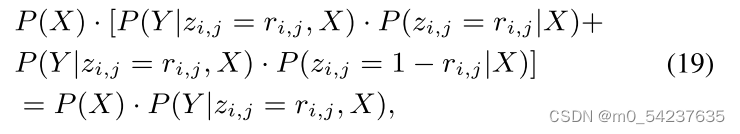
即不等式17成立。
基于定理2和等式16,,支持问题(2)。综上所述,我们得出结论:根据定理1,在LeAp中,从求解器MWP中学习知识的自主机制是通过等式1中的L1去优化先验
。这样的机制比直接链接预测的模型
更准确,因为根据定理2 ,它达到了更高的概率。值得注意的是,LeAp的优势在于基于求解MWP提供的信息(Y)计算后验概率的机制,而不是获得更好的参数φ,X。
5. 实验
5.1 实验设置
数据集
在实验中使用了三个数据集:Math23K、MAWP和SVAMP。具体来说,Math23K (Wang, Liu, and Shi 2017)是一个中文数据集,包含23162个只有一个变量的问题。我们使用其发布的数据集划分进行实验。MAWPS (Roy and Roth 2017)是一个英文数据集。我们选择了2 373个只有一个未知变量的问题,并进行了5折交叉验证。SVAMP (Patel、Bhattamishra和Goyal 2021)是一个测试数据集,包含比MAWPS多1000个困难问题。在Patel等人(2021)之后,在MAWPS和另一个ASDiv-A数据集的组合上训练模型,并在SVAMP中的问题上进行测试。
Baselines
以SOTA模型为基线,即基本的Seq2Seq、以语义为中心的方法(Graph2Tree, HMS)、以推理为中心的方法(GTS, TSN-MD)和基于集成的方法(Multi-E/D)。LeAp是一个通用框架,因此以它们为骨干来评估其有效性和通用性。
Seq2Seq (Luong, Pham, and Manning 2015)采用带注意力的BiLSTM编码器和LSTM解码器将问题句子翻译成表达式。
Graph2Tree (Zhang et al. 2020b)构建并编码两个与数量相关的图,以使用数量信息丰富问题理解。
HMS (Lin et al. 2021)根据词-子句-问题层次结构捕获问题语义。
GTS (Xie和Sun 2019)提出了一种目标驱动的分解机制来推理表达式树。
TSN-MD (Zhang et al. 2020a)通过多解码器网络生成不同的候选表达式。
Multi-E/D (Shen and Jin 2020)是一种基于序列的编码器/解码器与基于图的编码器/解码器的集成,以获得更好的语义和推理。
实现细节
对于知识编码器Pφ,其嵌入向量d的维数为128。
在训练过程中,方程(3)中的温度参数从0.5下降到0.1。
对于知识解码器Pθ,所有骨干求解器都按照其原始参数设置进行优化。其他参数随机初始化并使用Adam (Kingma and Ba 2014)进行训练,dropout概率为0.5。出现次数少于5次的单词被转换为特殊标记“UNK”。
硬件:Linux服务器,4个2.30GHz的Intel Xeon Gold 5218 cpu和一个Tesla V100 GPU。
5.2 答案推理性能
验证LeAp在提高MWP Backbone的推理能力方面的有效性,使用答案准确度作为衡量标准,因为同一个问题可能有许多正确的表达式。如果预测的表达式的计算值等于正确答案,则认为该表达式是正确的。
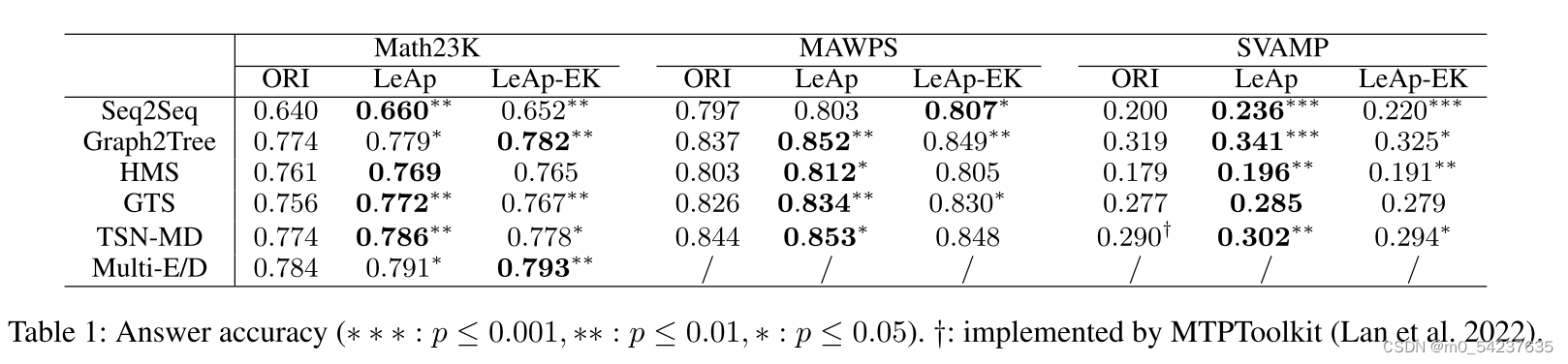
表1中,首先报告了所有骨干在其原始版本(" ORI ")和LeAp框架(" LeAp ")中的性能。从表1中可以观察到LeAp提高了所有骨干答案的准确性,通过应用配对t检验,改进具有统计学意义,p≤0.001 ~ 0.05。这表明LeAp可以增强MWP求解器的数学推理能力,使它们能够从问题求解中自主学习显性知识并将其应用于生成答案。
其次,为了评估知识应用的效果,设计了LeAp的变种“LeAp- EK”,将外部知识库中的知识Z直接应用到知识解码器中。我们选择HowNet (Dong和Dong 2006)作为Math23K的知识库,而ConceptNet(Speer、Chin和Havasi 2017)作为MAWPS和SVAMP的知识库。可以看出,LeAp-EK的性能也显著优于ORI。展示了将知识应用于不同求解器的知识解码器的适用性,进一步验证了第4节中“有效知识”假设的合理性。
第三,“LeAp”在几乎所有情况下都优于“LeAp- ek”。这可能是因为LeAp学习了额外的单词-运算符知识,而我们的理论结果保证了可以获得MWP的有效知识。由此反映了LeAp学习机制对自主获取知识的重要性和益处。
消融实验
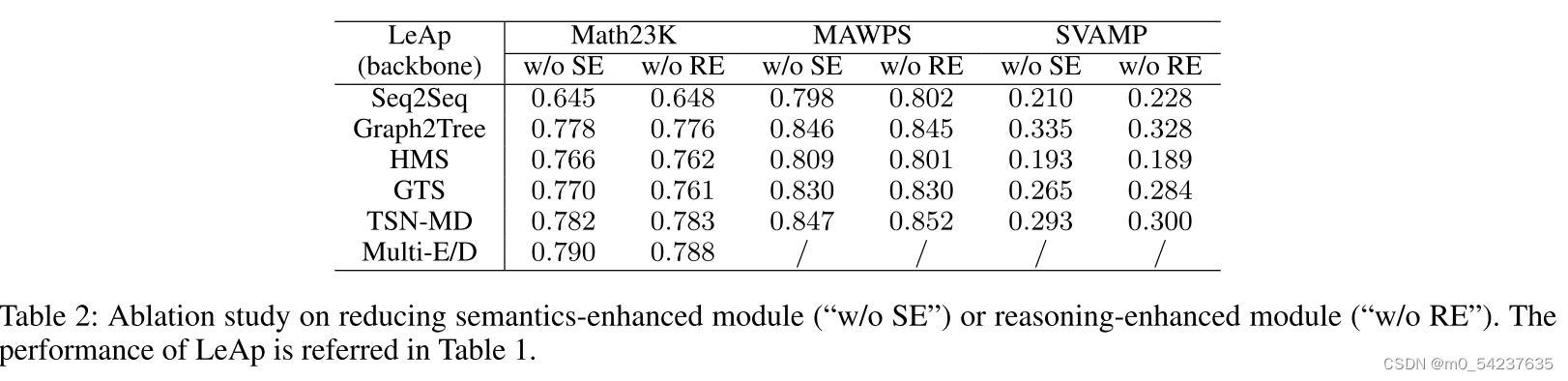
本文强调Eq(7)中的语义增强模块和Eq(9)中的推理增强模块在知识应用方面的优势。结合表1和表2,所有模型的归约语义增强(“w/o SE”)或推理增强(“w/o RE”)的准确性都有所下降,证明了它们对于LeAp解决MWP是必要的,同时也具有更好的通用性。此外,对于面向语义的方法(如Graph2Tree), LeAp " w/o SE "的性能要高于" w/o RE "。这表明,学习到的知识可能对捕获强语义的方法进行符号推理更有用。专注于推理的求解器(例如TSN-MD)出现了相反的结果。因此这两个模块适用于不同类型的Backbone。
5.3 LeAp 分析
知识学习
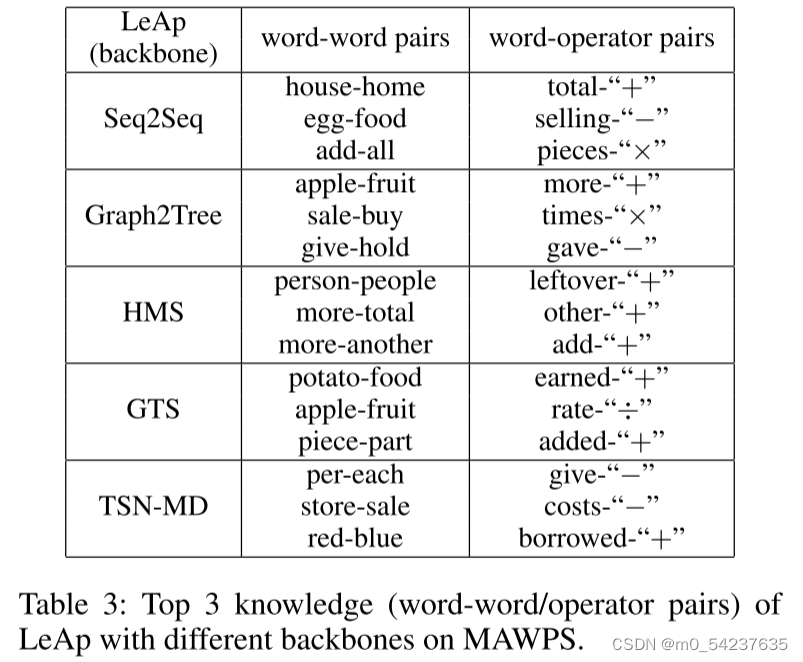
评估LeAp学习的外显知识Z的质量。我们的想法实在训练后对进行排序,期望合理的一个位于顶部。在表3中可视化前3个 单词-单词/单词-运算符对,可以清楚的看到LeAp通过不同的主干获得了合理的知识(如:LeAp(seq2seq)学习到“house”与“home”相关,“total”与“+”相关)
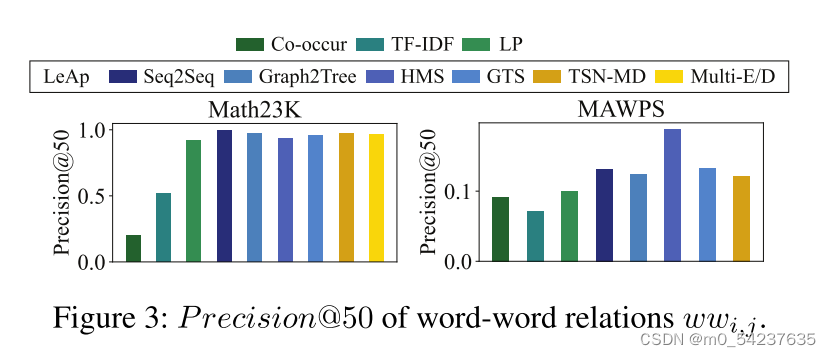
我们引入外部知识库(HowNet和ConceptNet)的α = 20%作为单词-单词知识的先验知识(没有外部知识库),并在剩余80%的基础上计算Precision@50。因为我们更关注指示的准确性。这里,我们介绍三个经典的基线。" co-occur "通过两个词在所有问题中的共现频率来确定它们之间的权重。"TF-IDF"通过单词的TF-IDF值计算单词之间的余弦相似度。“LP”是一个与知识编码器具有相同架构的模型。它在LeAp之前基于相同的20%的知识进行训练。
从图3中可以看出,无论使用哪种骨干求解器,我们的LeAp性能都优于所有基线。这体现了LeAp自主学习机制的优越性和鲁棒性。特别是,LeAp的性能优于LP,证明了我们在第4节中理论分析的合理性。
知识先验
为了模拟不同学习背景的学习者,在先验P(Z)中选取α = 0%、20%、40%、60%的外部知识库,以Seq2Seq、Graph2Tree和GTS为Backbone,评估LeAp在MWP求解上的性能。
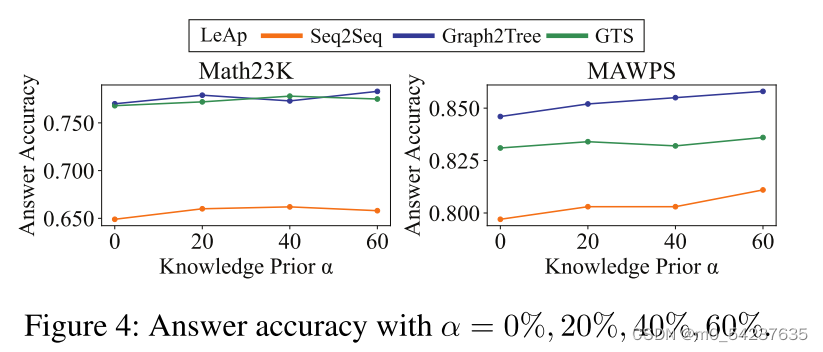
从图4可以看出,随着α的增加,LeAp的答案准确率呈现出增加的趋势,正如人类学习者拥有更丰富的知识基础可以更好地进行数学推理。此外,当α = 0%时,LeAp在表1中仍然优于原始Backbone(“ORI”)。它展示了我们从零开始学习知识的灵活性。
案例学习
在此基础上,通过案例研究说明了LeAp (Graph2Tree为主干)的可解释推理过程。
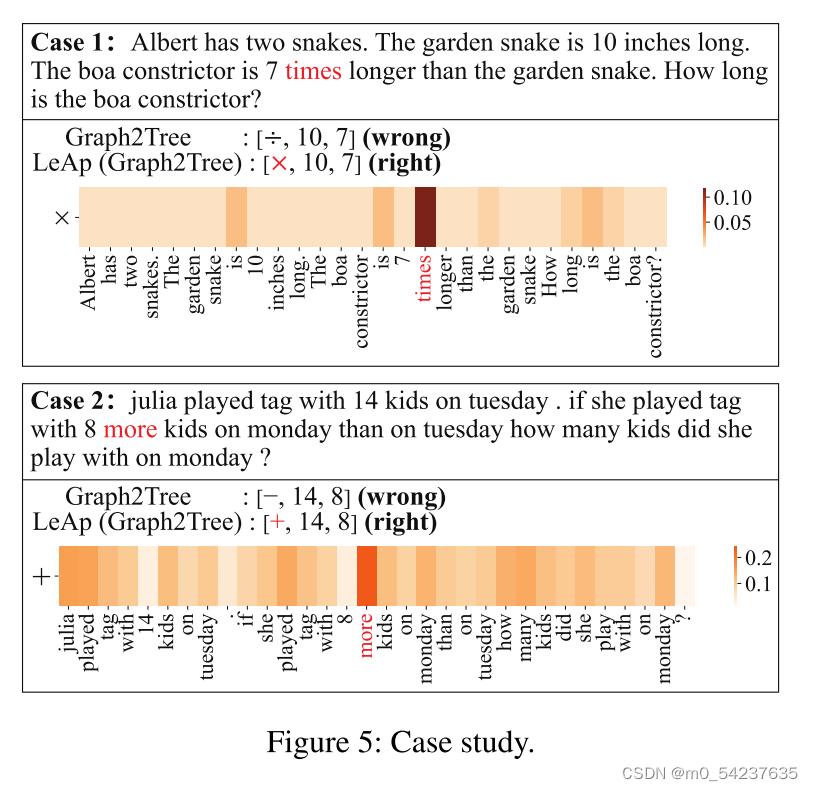
在图5中,我们报告了问题句子,Graph2Tree和LeAp (Graph2Tree)推理出的前缀表达式,以及LeAp学习到的单词-运算符知识。对于这两种情况,我们可以看到原始的Graph2Tree在推理步骤t = 1时出错。相比之下,LeAp运用所学知识
,将“times”与“×”、“more”与“+”联系起来,准确纠正了这种错误,并给出了“×”与“+”的原因。值得注意的是,知识
在推理过程中是固定的。何时使用此知识由对" times "和" more "这两个词的关注程度控制,由我们提出的推理增强模块中的
测量(第3.2节中的等式(8))。由此可见,在LeAp中,学习到的显式知识不仅使现有的MWP求解器在答案精度上受益,而且知识应用机制还可以解释如何推理相应的答案,表现出优越的可解释性。
6. 结论和未来工作
在本文中,我们提出了一个学习应用(LeAp)框架显式知识学习和应用在一个新的一般问题的知识表达范式,可以添加到现有的解决方案,以提高他们的推理能力。我们还在LeAp中设计了语义/推理增强模块,通过有效地应用知识来加强问题理解和符号推理。我们从贝叶斯的角度从理论上证明了LeAp的自主学习机制的优越性。实验表明,LeAp在答案推理,知识学习和可解释性方面的有效性。未来,我们将把LeAp扩展到其他类型的知识/问题,并探索其丰富外部知识库的潜力。















 4855
4855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









