






一、什么是文档视觉问答(DOC-VQA)
VQA指视觉问答,主要针对图像内容进行提问和回答,DOC- VQA是VQA任务中的一种,DOC-VQA主要针对文本图像的文字内容提出问题。
PaddleOCR里的DOC- VQA算法基于Paddle NLP自然语言处理算法库进行开发,支持基于多模态方法对的语义实体识别(Semantic Entity Recognition, SER)以及关系抽取(Relation Extration, RE)任务。
主要特性如下:
- 集成LayoutXLM模型以及PP-OCR预测引擎。
- 支持基于多模态方法的语义实体识别 (Semantic Entity Recognition, SER) 以及关系抽取 (Relation Extraction, RE) 任务。基于 SER 任务,可以完成对图像中的文本识别与分类;基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair)。
- 支持SER任务和RE任务的自定义训练。
- 支持OCR+SER的端到端系统预测与评估。
- 支持OCR+SER+RE的端到端系统预测。
二、数据准备
这里使用XFUN数据集做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
分别为:ZH(中文)、JA(日语)、ES(西班牙)、FR(法语)、IT(意大利)、DE(德语)、PT(葡萄牙)
处理好的XFUN中文数据集下载地址:XFUND数据集下载,可以运行如下指令完成中文数据集的下载和解压。
# 准备XFUND数据集,这里主要是为了获得字典文件class_list_xfun.txt
# PaddleOCR/ppstructure/vqa
curl https://paddleocr.bj.bcebos.com/ppstructure/dataset/XFUND.tar -o XFUND.tar
tar -xvf XFUND.tar处理好的数据集如下图所示:
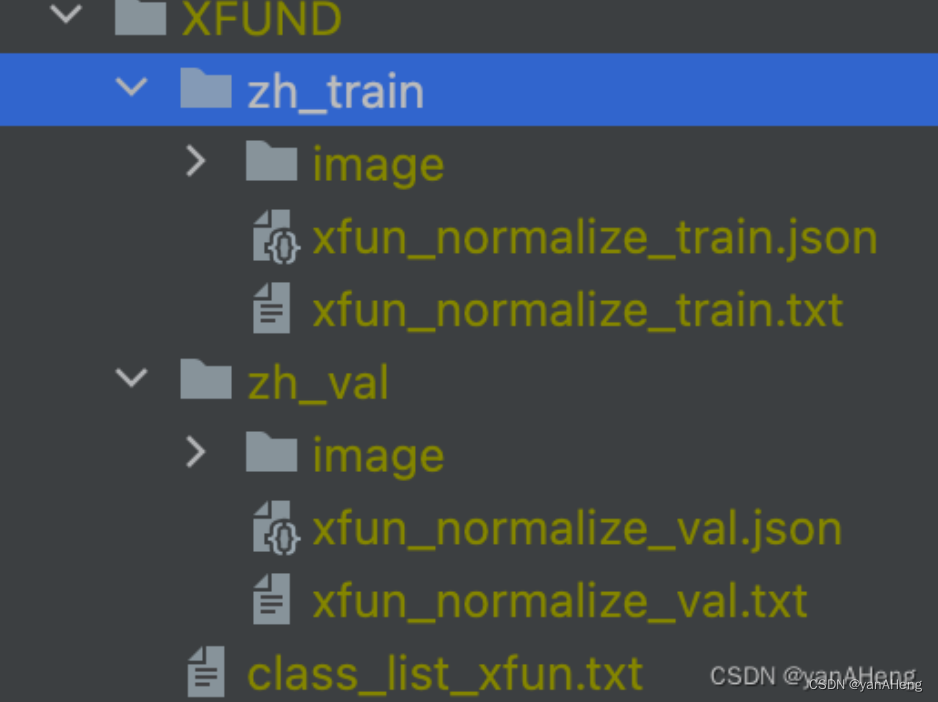
处理好的标注文件格式如下,txt文件中需将图片路径和图片标签用“\t"分割,其他分割方式将造成训练报错。

未处理的标注文件可使用转换脚本trans_xfund_data.py进行转换:
# PaddleOCR/ppstructure/kie/tools/trans_xfund_data.py
import json
def transfer_xfun_data(json_path=None, output_file=None):
with open(json_path, "r", encoding='utf-8') as fin:
lines = fin.readlines()
json_info = json.loads(lines[0])
documents = json_info["documents"]
label_info = {}
with open(output_file, "w", encoding='utf-8') as fout:
for idx, document in enumerate(documents):
img_info = document["img"]
document = document["document"]
image_path = img_info["fname"]
label_info["height"] = img_info["height"]
label_info["width"] = img_info["width"]
label_info["ocr_info"] = []
for doc in document:
label_info["ocr_info"].append({
"text": doc["text"],
"label": doc["label"],
"bbox": doc["box"],
"id": doc["id"],
"linking": doc["linking"],
"words": doc["words"]
})
fout.write(image_path + "\t" + json.dumps(
label_info, ensure_ascii=False) + "\n")
print("===ok====")
transfer_xfun_data("../train_data/vqa/XFUND_ori/zh.train.json", "../train_data/vqa/XFUND_ori/xfun_normalize_train.txt")三、VI-LayoutXLM模型准备
1、下载VI-LayoutXLM模型
# PaddleOCR/train_models
curl https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_infer.tar -o ser_vi_layoutxlm_xfund_infer.tar
tar -xvf ser_vi_layoutxlm_xfund_infer.tar# PaddleOCR/train_models
curl https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_infer.tar -o re_vi_layoutxlm_xfund_infer.tar
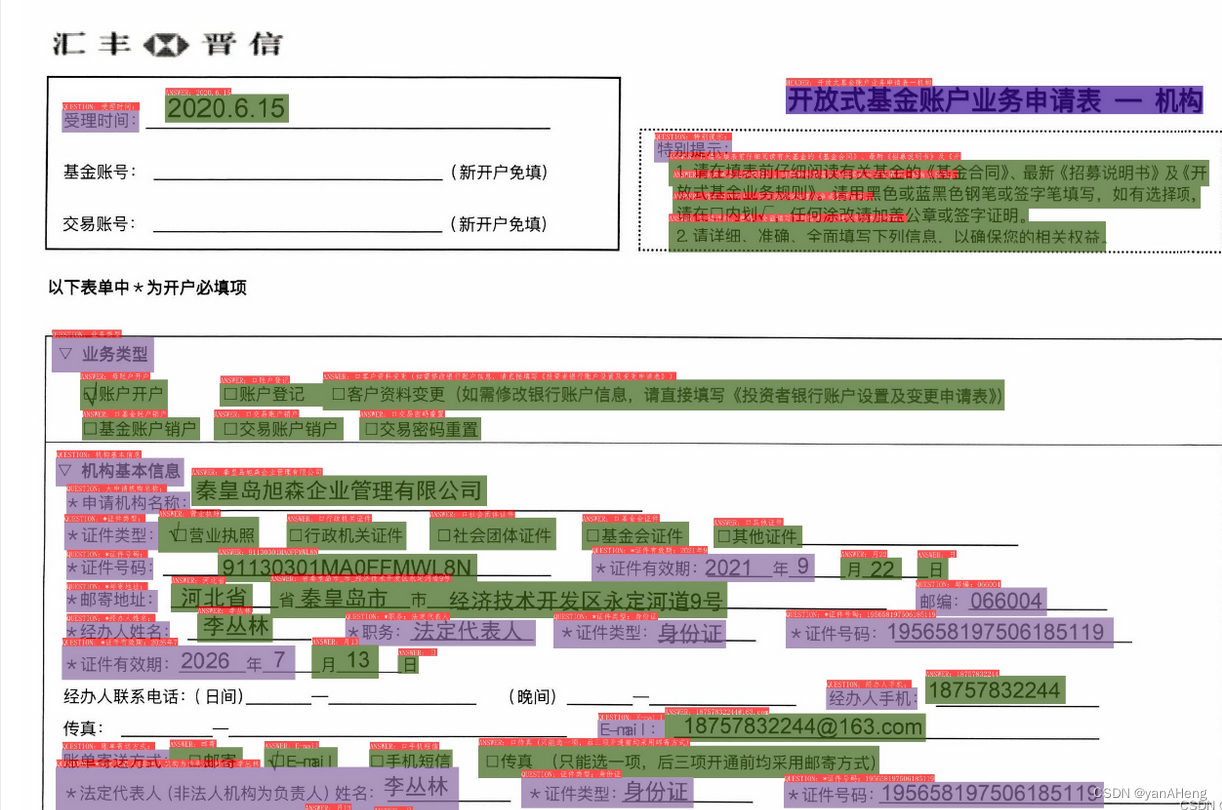
tar -xvf re_vi_layoutxlm_xfund_infer.tar2、SER(Semantic Entity Recognition, 语义实体识别)
可以完成对图像中的文本识别与分类。
直接体验预测过程:
# PaddleOCR/ppstructure
python kie/predict_kie_token_ser.py --kie_algorithm=LayoutXLM --ser_model_dir=../train_models/ser_vi_layoutxlm_xfund_infer --ser_dict_path=./vqa/XFUND/class_list_xfun.txt --vis_font_path=../doc/fonts/simfang.ttf --ocr_order_method="tb-yx" --output=./output/ser_vi_layoutxlm_xfund_zh/ --image_dir=./vqa/pjtzs 结果如下:

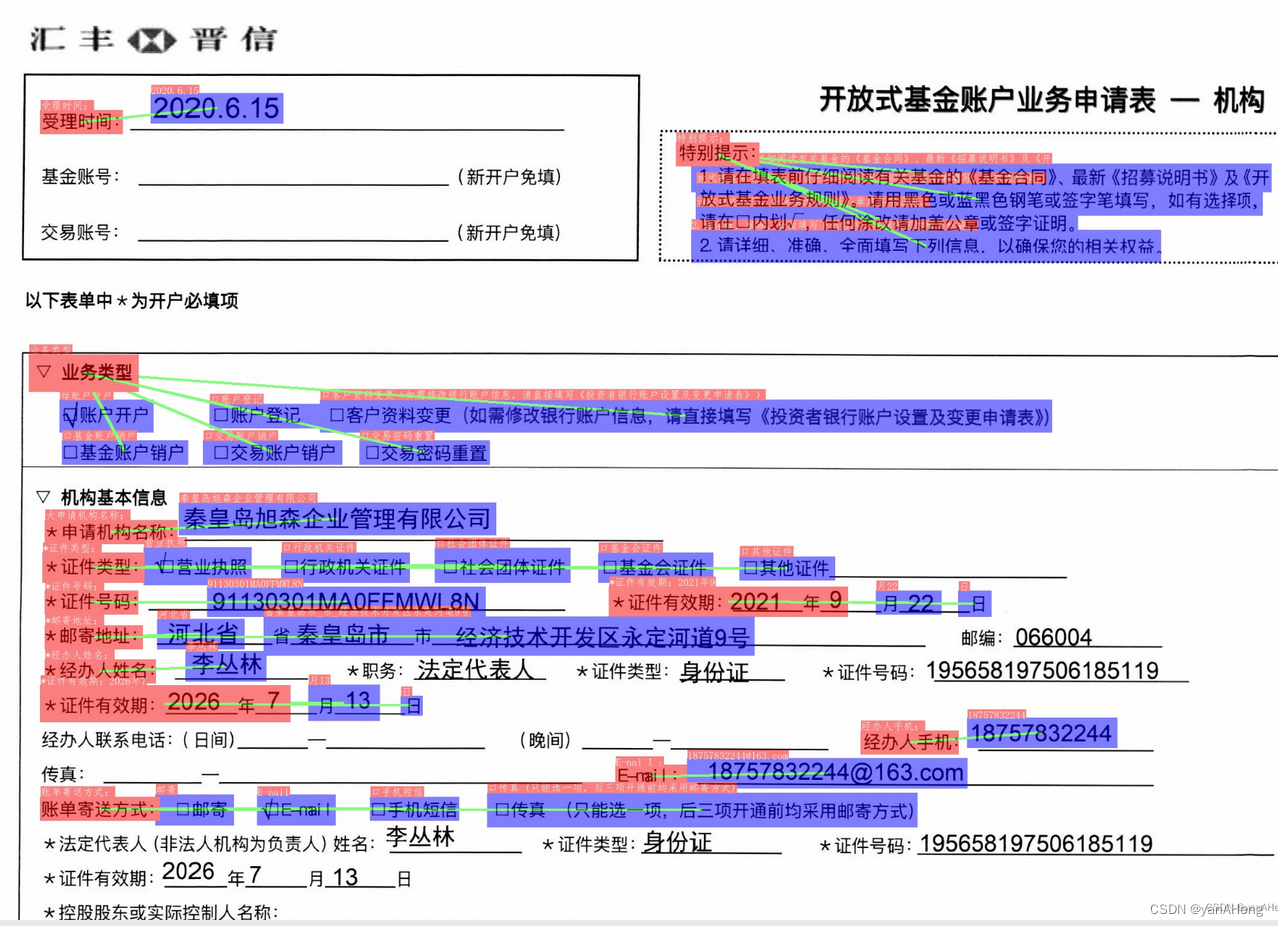
3、RE(Relation Extration, 关系抽取)
可以完成对图像中的文本内容的关系提取,如判断问题对(pair)
直接体验预测过程:
# PaddleOCR/ppstructure
python kie/predict_kie_token_ser_re.py --kie_algorithm=LayoutXLM --re_model_dir=../train_models/re_vi_layoutxlm_xfund_infer --ser_model_dir=../train_models/ser_vi_layoutxlm_xfund_infer --use_visual_backbone=False --vis_font_path=../doc/fonts/simfang.ttf --ocr_order_method="tb-yx" --ser_dict_path=./vqa/XFUND/class_list_xfun.txt --output=./output/ser_re_vi_layoutxlm_xfund_zh/ --image_dir=./vqa/XFUND/zh_train/image/zh_train_0.jpg结果如下:


















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









