






1、caffe使用的是float运算,NNIE使用int8\16,转换时精度会有损失,若量化精度损失不可接受的情况下,需要带量化去重新训练以降低量化误差。
2、NNIE包含Convolution、Deconvolution(逆卷积)、DepthwiseConv、pooling、InnerProduct。
Deconvolution(逆卷积):一般和转置卷积(transposed conv)、微步卷积(fractionally strided conv)的叫法等价。deconv最大的作用是对feature map进行升采样。顾名思义,Deconvolution(逆卷积、去卷积)似乎应该是卷积(conv)的逆过程,然而实际上除了shape层面之外,二者在数值上没有任何可逆关系。deconv仅仅是一个普通的卷积层,在神经网络中也是需要通过梯度下降去学习的。所以,对于每个deconv层,我们实际上也能用另外一个deconv层去做恢复。(如果用conv+deconv进行穿插排列组合是不是也能创造出许多新的网络架构emmm)。
正向卷积过程(蓝色为输入x,阴影为卷积核C,绿色为输出)
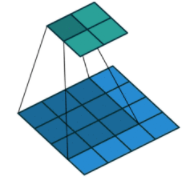
对于No zero padding, unit strides, 的卷积来说,转置卷积:

其对应关系可以理解为正向卷积为0 padding,那么转置卷积就是full padding。
DepthwiseConv:Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。合起来被称作Depthwise Separable Convolution(参见Google的Xception),该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。所以在一些轻量级网络中会碰到这种结构如MobileNet。
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。如下图:

Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。

全连接层InnerProductLayer的原理:说白了就是矩阵乘法运算。
正向传导时输出数据等于输入数据乘上权重,如果有偏置项就再加上偏置项。写成公式就是:

矩阵乘法在CPU端采用OpenBLAS实现,在GPU端则采用NVIDIA cuBLAS实现加速。















 2435
2435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









