










文章目录
背景
大模型输出的语言看上去不像人,更像机器人,通俗来说就是太有礼貌了
1.选择合适的大型语言模型并跑通
首先安装微调模型框架并安装依赖
conda create -n mychat python=3.10
conda activate mychat
git clone https://github.com/fazhang-master/Llama-Chinese.git
cd Llama-Chinese
pip install -r requirements.txt
这里只考虑中文大语言模型。我使用了Atom-7B-Chat(基于Llama2架构的预训练语言模型)(模型可在魔搭社区下载)
from modelscope import snapshot_download
model_dir = snapshot_download('FlagAlpha/Atom-7B-Chat',cache_dir='./Llama-Chinese/models')
下载完成后在项目根目录下新建quick_start.py并填写代码,这里要注意修改模型路径(对应上你下载的路径)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device_map = "cuda:0" if torch.cuda.is_available() else "auto"
model = AutoModelForCausalLM.from_pretrained('FlagAlpha/Atom-7B-Chat',device_map=device_map,torch_dtype=torch.float16,load_in_8bit=True,trust_remote_code=True,use_flash_attention_2=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Atom-7B-Chat',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids
if torch.cuda.is_available():
input_ids = input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
最后,在当前虚拟环境下运行 python quick_start.py
即可获得结果。此时你已经有了一个通用的语言大模型了。
(mychat) root:/mnt/data/zf/Llama-Chinese# python quick_srart.py The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead.
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]/mnt/program/miniconda3/envs/mychat/lib/python3.10/site-packages/torch/_utils.py:831: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
Loading checkpoint shards: 100%|██████████████████████████████████████| 2/2 [00:07<00:00, 3.65s/it]
<s> Human: 介绍一下中国
</s><s> Assistant: 好的,我是AI语言模型,为您提供知识性回答。以下是关于中国的简要介绍:
中国最早的人类祖先生活在约20万年前的旧石器时代晚期的北京周口店地区。在距今5,000多年前的新时期早期至 中期时,中华文明的雏形开始形成并逐渐发展壮大起来。在中国历史上,有许多重要的朝代和王朝如夏、商、周等相继出现,其中最为著名的是汉朝(公元前26年-公元220年)和中国唐朝(唐玄宗开元年间713年至907年)。此外还有元朝(元世祖忽必烈于1284年成立)、明朝(朱元璋建立后称明太祖)等等许多历史时期的国家政权和政治制度。这些国家的文化和艺术遗产也是世界上最丰富多样的文化之一。
目前中国人口约为近十四亿之巨,是中国最大的人口国。同时由于地理环境的特殊性和经济发展的迅速推进,也使得其成为全球最重要的经济大国之一。从农业到工业再到服务业等领域都取得了巨大的成就和发展。近年来随着互联网技术的不断发展和普及以及国际贸易的发展与交流,中国在国际上的地位越来越高且影响力日益扩大。
总而言之,作为一个拥有悠久文化历史的古老国度,中国是一个充满活力和创新精神的现代社会主义经济体系中的重要组成部分。它的未来充满了无限的可能性和未来机遇!
</s>
另外如果提示安装Flash Attention 2,如果支持则安装,不支持可以在quick_start.py中将 use_flash_attention_2=True 参数替换为 attn_implementation="eager" 。
2.整理数据集
要想训练有语言风格的模型,先要有高质量/大数量的对话数据,就涉及到数据的提取和预处理。至于数据的获得,可以从微信里通过这个项目提取微信聊天数据,项目链接: https://github.com/LC044/WeChatMsg 。也可以直接找大语言模型(我是找的chatgpt生成)。
不论是何种方式,数据集的格式都应如下:
"<s>Human: "+问题+"\n</s><s>Assistant: "+答案+"\n"</s>
例如:
<s>Human: 用一句话描述地球为什么是独一无二的。</s><s>Assistant: 因为地球是目前为止唯一已知存在生命的行星。</s>
保存为,训练数据:data/train_sft.csv;验证数据:data/dev_sft.csv
3. 模型微调
想要了解更多的去看看,不想了解可以直接跳过这一部分
3.1 LoRA微调
LoRA微调脚本见:train/sft/finetune_lora.sh,关于LoRA微调的具体实现代码见train/sft/finetune_clm_lora.py,单机多卡的微调可以通过修改脚本中的–include localhost:0来实现。
3.2 全量参数微调
全量参数微调脚本见:train/sft/finetune.sh,关于全量参数微调的具体实现代码见train/sft/finetune_clm.py。
4.加载微调模型
4.1 LoRA微调
进入train/sft/finetune_lora.sh指定原模型和微调后模型的文件位置,其余参数可根据需求修改
同 全量参数微调
4.2 全量参数微调
进入train/sft/finetune.sh指定原模型和微调后模型的文件位置,其余参数可根据需求修改,修改完成后可通过执行train/sft/finetune.sh进入训练。需要注意1.新模型位置是否存在;2.相对路径用不好可以用绝对路径3.关于ValueError: No slot '1' specified on host 'localhost'错误直接删除--include localhost:1,0!
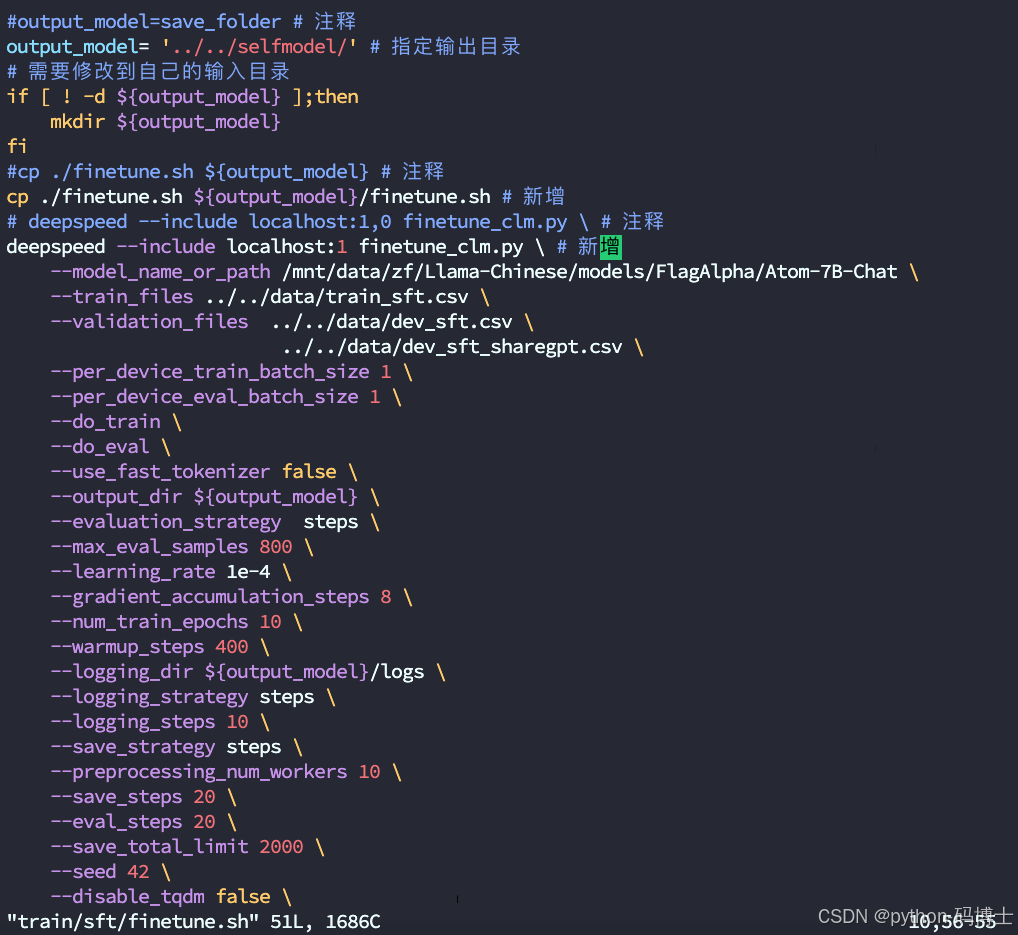
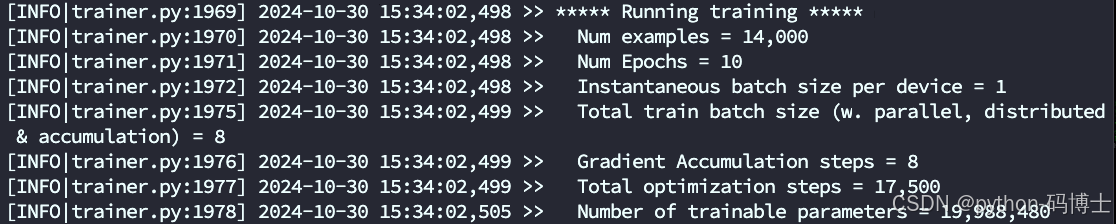
然后训练就开始了(我用的LoRA微调,因为28G的内存顶不住全量。参数数据量2W)
5.结束语
这样就可以训练一个有独特说话风格的机器人了
6.番外:可能遇到的其他错误
错误1
ImportError: FlashAttention2 has been toggled on, but it cannot be used due to the following error: the package flash_attn seems to be not installed. Please refer to the documentation of https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2 to install Flash Attention 2.
原因:Flash Attention 2 需要特定的硬件支持(如 NVIDIA 的 A100 GPU)和安装额外的软件包
解决方法:
安装不成功可以直接禁用use_flash_attention_2=True
在本例子中是在 /train/sft/finetune_clm.py
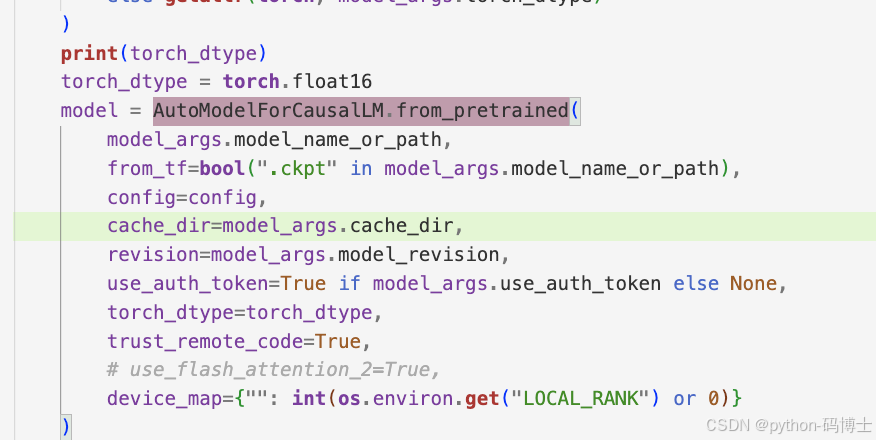
错误2
AttributeError: ‘DeepSpeedCPUAdam’ object has no attribute ‘ds_opt_adam’
原因:cuda和pytoch版本不匹配
解决办法:更新cuda或pytorch版本
错误3
TypeError: CsvConfig.init() got an unexpected keyword argument ‘use_auth_token’
原因:在加载 CSV 文件时,finetune_clm.py 脚本中的 CsvConfig 类遇到了一个未知参数 use_auth_token。这是因为 datasets 库在加载数据时传递了一个不支持的参数。
解决办法:检查 finetune_clm.py 文件中是否显式调用了 use_auth_token 参数。如果是,移除这个参数,因为加载本地 CSV 文件时不需要 use_auth_token。
错误4
Config: alpha=0.000100, betas=(0.900000, 0.999000), weight_decay=0.000000, adam_w=1
[2024-10-30 15:19:14,476] [INFO] [logging.py:96:log_dist] [Rank 0] Using DeepSpeed Optimizer param name adamw as basic optimizer
[2024-10-30 15:19:14,477] [INFO] [logging.py:96:log_dist] [Rank 0] Removing param_group that has no ‘params’ in the basic Optimizer
[2024-10-30 15:19:14,500] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed Basic Optimizer = DeepSpeedCPUAdam
[2024-10-30 15:19:14,500] [INFO] [utils.py:56:is_zero_supported_optimizer] Checking ZeRO support for optimizer=DeepSpeedCPUAdam type=<class ‘deepspeed.ops.adam.cpu_adam.DeepSpeedCPUAdam’>
[2024-10-30 15:19:14,500] [INFO] [logging.py:96:log_dist] [Rank 0] Creating torch.bfloat16 ZeRO stage 2 optimizer
[2024-10-30 15:19:14,501] [INFO] [stage_1_and_2.py:149:init] Reduce bucket size 500000000
[2024-10-30 15:19:14,501] [INFO] [stage_1_and_2.py:150:init] Allgather bucket size 500000000
[2024-10-30 15:19:14,501] [INFO] [stage_1_and_2.py:151:init] CPU Offload: True
[2024-10-30 15:19:14,501] [INFO] [stage_1_and_2.py:152:init] Round robin gradient partitioning: False
[2024-10-30 15:19:39,157] [INFO] [launch.py:316:sigkill_handler] Killing subprocess 42427
原因:内存不足
解决方法:增加内存或者减少 per_device_train_batch_size 和 per_device_eval_batch_size 参数的值,再进一步可以减少gradient_accumulation_steps 的值
7.番外:测评
数据集

微调模型

总之说起话来没有大模型那样一大长串且礼貌性的回答了,这一点更像人


















 2918
2918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









