







目录
历史:GPT-1 2018年6月发布,直到2023年3月gpt-4发布并应用于chatgpt活跃进入大部分人的视野。
上面的任务怎么做到有条理地进行呢?interlm开源了一条龙的全链条开源体系:
历史:GPT-1 2018年6月发布,直到2023年3月gpt-4发布并应用于chatgpt活跃进入大部分人的视野。
概念区分:
专用模型---语音识别、人脸识别、imagenet分类检测等下游任务场景应用
通用大模型---一个模型应对多种任务、多种模态,例如chatgpt作为nlp领域的大模型,能够以一个模型完成情绪识别、QA任务、命名实体识别等以文本作为输入输出的任务,GPT-4更是从文本模态拓展到了视觉模态,进一步增加了通用性。
InternLM大模型
InternLM大模型于2023年6月7日发布。InternLM设计分为三种参数级:

从模型到应用:

选型:针对目标任务选择参数级别的模型
应用场景判断:由lora之类的办法进行模型微调
环境交互---调用外部api,与已有数据库进行数据交互,要为模型设计智能体。
模型评测当然是看看是否能完成自己的目的了,能够达成目的则进行到下一步的部署。
上面的任务怎么做到有条理地进行呢?interlm开源了一条龙的全链条开源体系:

书生万卷:提供数据:模态包括文本、图像、视频,内容包括科技、文学、教育等领域。
internlm-train:模型训练框架支持从8卡到千卡的训练,同时高度优化以提升了训练性能。
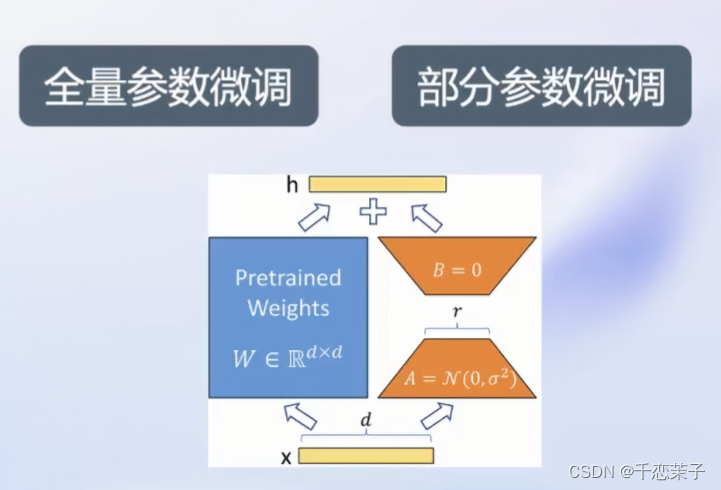
XTuner: 成体系的框架兼容多种微调算法,适配多样计算加速硬件,最低8G显存即可微调7B模型,训练引擎延续mmengine体系,同时支持hugging face体系。
微调分类:
增量续训:
目的:让基座模型学习到一些新知识,例如某个垂类领域知识
方法:增加文章、书籍、代码的数据
有监督微调:
目的:让模型理解与遵循指令,注入少量知识
方法:增加高质量的对话、问答数据
opencompass:评测工具,更适合中国大模型宝宝的评测集。

opencompass评测架构:
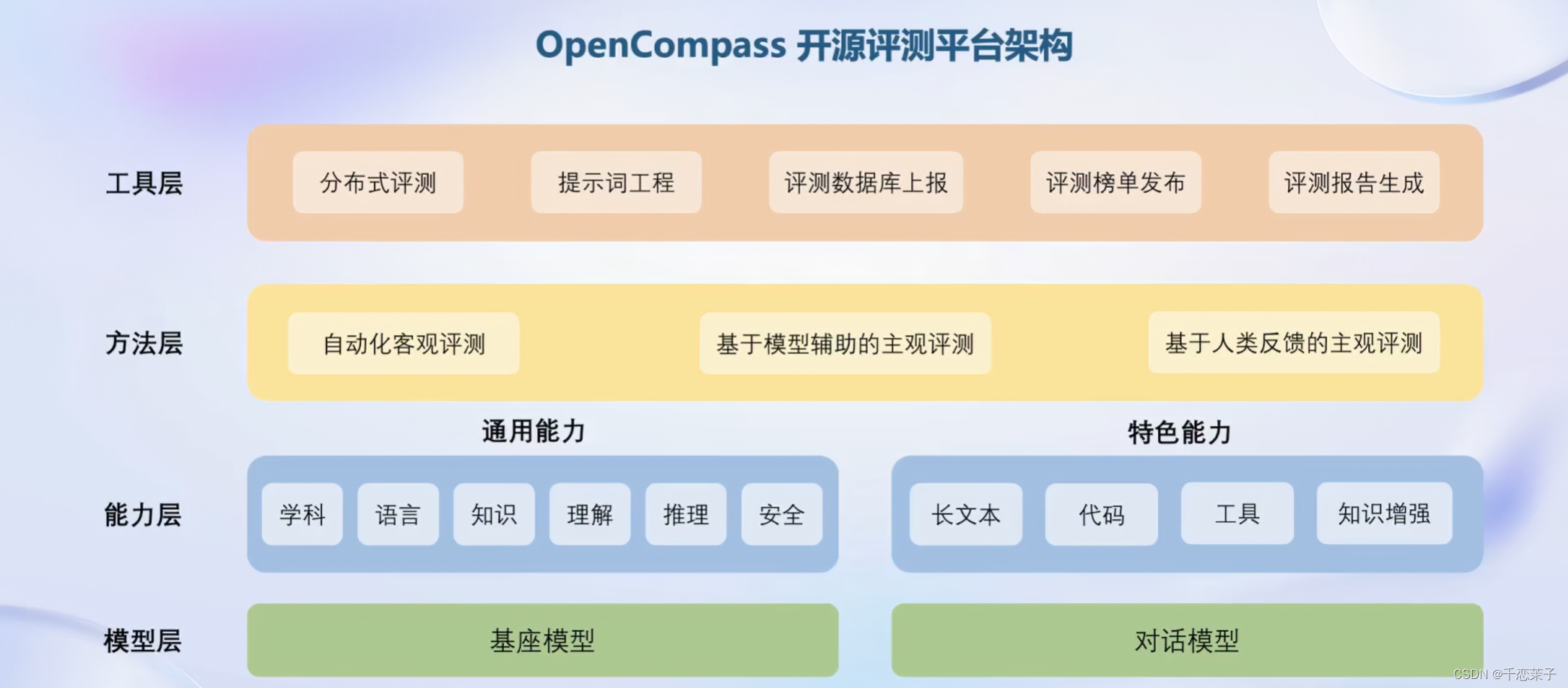
作为曾经非常火热,如今也是经常被提起的模型道德问题,适合对应社会的评测同样是一项很重要的任务。
大模型特点与部署技术挑战:

值得注意的几点摘录:
基于transformer结构下却采用自回归生成token带来所需要的key,value大量缓存,导致巨大内存开销;(好理解)
动态shape请求(可能是由不同模态的数据输入导致的,对于多模态数据的embed我也不是很懂,正想通过本次学习了解)
lmdeploy部署框架:


重点:基于fast-transformer的turbomind推理引擎支持
智能体与大模型局限性:
局限性:新消息的获取,回复的可靠性,数学计算,外部api工具使用交互
lagent智能体框架:
支持大量外部api工具,成体系的智能体能力。

agentlego智能体集成工具箱,区别于上面lagent的智能体创建框架。














 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









