







什么是正则表达式:简单地说,正则表达式就是处理字符串的方法,它以行为单位来进行字符串的处理操作,正则表达式通过一些特殊符号的辅助,可以让用户轻易的完成查找、删除、替换某特定字符串的处理过程。
正则表达式的字符串表示方法依照不同的严谨度分为:基础正则表达式、扩展正则表达式。
注:正则表达式与通配符是完全不一样的东西,通配符代表的是bash操作接口的一个功能,但正则表达式是一种字符串处理的表示方式。
基础正则表达式
既然正则表达式是一种字符串处理的表示方式,那么对字符排序有影响的语系就会对正则表达式的结果有影响,举例来说,在英文大小写的编码顺序中,zh_CN及C这两种语系的输出结果如下:
- LANG=zh_CN时: 0 1 2 3 4 ... a A b B c C ... z Z
- LANG=C时:0 1 2 3 4 ... A B C D ... Z a b c d ... z
所以,使用正则表达式时,需要特别留意当时环境的语系,否则可能会发现和别人不同的选取结果。
为了要避免这些编码所造成的英文与数字选取问题,下面是一些特殊符号的意义:
| 特 殊 符 号 | 代 表 意 义 |
|---|---|
| [:alnum:] | 代表英文大小写字符及数字,0~9、A~Z、a~z |
| [:alpha:] | 任何英文大小写字符,A~Z、a~z |
| [:blank:] | 空格键或[Tab]按键 |
| [:cntrl:] | 键盘上的控制按键,包括CR、LF、Tab、Del等 |
| [:digit:] | 数字,0~9 |
| [:graph:] | 除了空格符(空格键和[Tab]按键)外的其它所有按键 |
| [:lower:] | 小写字符,a~z |
| [:print:] | 任何可以被打印出来的字符 |
| [:punct:] | 标点符号 |
| [:upper:] | 大写字符,A~Z |
| [:space:] | 任何会产生空白的字符 |
| [:xdigit:] | 十六进制的数字类型 |
以下面这个文件内容为例来练习:
"Open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn't fit me.
However, this dress is about $ 3183 dollars.^M
GNU is free air not free beer.^M
Her hair is very beauty.^M
I can't finish the test.^M
Oh! The soup taste good.^M
motorcycle is cheap than car.
This window is clear.
the symbol '*' is represented as start.
Oh! My god!
The gd software is a library for drafting programs.^M
You are the best is mean you are the no. 1.
The world <Happy> is the same with "glad".
I like dog.
google is the best tools for search keyword.
goooooogle yes!
go! go! Let's go.
# I am VBird
保存为regular_express.txt文件
- 查找文件中the这个特定字符
[root@linux ~]# grep -n 'the' regular_express.txt
- 反向选择,显示没有the这个字符的行
[root@linux ~]# grep -vn 'the' regular_express.txt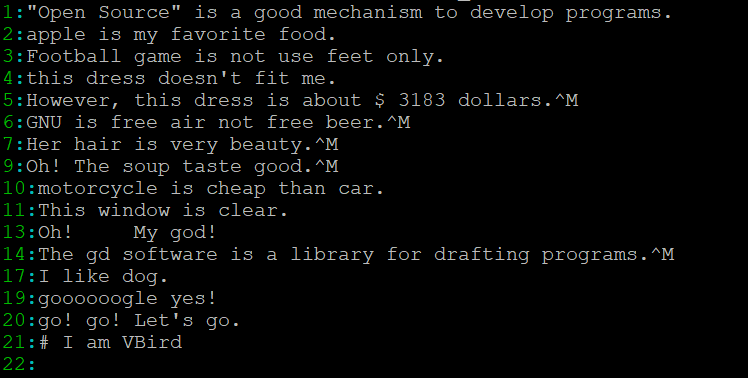
- 取得不论the大小的行
[root@linux ~]# grep -in 'the' regular_express.txt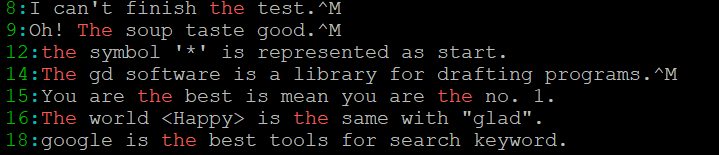
- 查找test或taste这两个关键字所在行
[root@linux ~]# grep -n 't[ea]' regular_express.txt

- 查找oo前面没有g所在行
[root@linux ~]# grep -n '[^g]oo' regular_express.txt
- oo前面不能有小写字符
[root@linux ~]# grep -n '[^a-z]oo' regular_express.txt
或
[root@linux ~]# grep -n '[^[:lower:]]oo' regular_express.txt ![]()
- 只要the在行首的
[root@linux ~]# grep -n '^the' regular_express.txt![]()
- 只要行尾结束为小数点.的
[root@linux ~]# grep -n '\.$' regular_express.txt 注:. 小数点具有其他意义,必须使用转义符号来解除其特殊意义
注:. 小数点具有其他意义,必须使用转义符号来解除其特殊意义
- 找出空白行
[root@linux ~]# grep -n '^$' regular_express.txt ![]()
- 找出g??d的字符串
[root@linux ~]# grep -n 'g..d' regular_express.txt
- 找出至少两个o以上的字符串
[root@linux ~]# grep -n 'g..d' regular_express.txt
- 找出任意数字的行列
[root@linux ~]# grep -n '[0-9][0-9]*' regular_express.txt ![]()
- 找出两个o的字符串
[root@linux ~]# grep -n 'o\{2\}' regular_express.txt
- 找出g后面接2到5个o,再接一个g的字符串
[root@linux ~]# grep -n 'go\{2,5\}g' regular_express.txt![]()
基础正则表达式字符集合:
| RE字符 | 意义 |
|---|---|
| ^word | 待查找的字符串在行首 |
| word$ | 待查找的字符串在行尾 |
| . | 代表一定有一个任意字符的字符 |
| \ | 转义符,将特殊符号的特殊意义去掉 |
| * | 重复0个到无穷多个的前一个RE字符 |
| [list] | 字符集合的RE字符,里面列出想要选取的字符 |
| [n1-n2] | 字符集合的RE字符,里面列出想要选取的字符范围 |
| [^list] | 字符集合的RE字符,里面列出不要的字符串或范围 |
| \{n,m\} | 连续n到m个的前一个RE字符 若为\{n\}则是连续n个前一个RE字符 若为\{n,\}连续n个以上的前一个RE字符 |
注:通配符中的*代表的是0~无限多个字符,在正则表达式中,*表示重复0到无穷多个的前一个RE字符
扩展正则表达式
| RE字符 | 意义 |
|---|---|
| + | 重复一个或一个以上的前一个RE字符 |
| ? | 0个或一个的前一个RE字符 |
| | | 用或的方式找出数个字符串 |
| () | 找出群组字符串 |
| ()+ | 多个重复群组的判别 |
grep默认仅支持基础正则表达式,如果要使用扩展正则表达式,可以使用grep -E或者直接使用egrep。
1、查找god、good、goood等的字符串
[root@linux ~]# egrep -n 'go+d' regular_express.txt2、查找gd,god这两个字符串
[root@linux ~]# egrep -n 'go?d' regular_express.txt3、查找gd或god这两个字符串
[root@linux ~]# egrep -n 'gd|god' regular_express.txt4、查找glad或good这两个字符串
[root@linux ~]# egrep -n 'g(la|oo)d' regular_express.txt5、将【AxyzxyzxyzxyzxyzC】用echo打印,找开头是A结尾是CC,中间有一个以上的"xyz"字符串
[root@linux ~]# echo AxyzxyzxyzxyzxyzC | egrep 'A(xyz)+C'sed的使用
sed是一个管道命令,可以分析标准输入,还可以将数据进行替换、删除、新增、选取特定行等功能。
语法:
sed [-nefri] [操作]
-n:使用安静模式,在一般sed的用法中,所有来自stdin的数据一般都会被列出到屏幕上,但如果加上-n参数后,则只有经过sed特殊处理的那一行(或操作)才会被列出来
-e:直接在命令行模式上进行sed的操作编辑
-f:直接将sed的操作写在一个人间内, -f filename 则可以执行filename内的sed操作
-r:sed的操作使用的是扩展型正则表达式的语法
-i:直接修改读取的文件内容,而不是由屏幕输出
操作说明:[n1,[n2]] function
n1,n2:不见得会存在,一般代表【选择进行操作的行数】,举例来说,如果操作是需要在10到20行之间进行的,则【10,20[操作行为]】
function有下面这些东西:
a:新增,a的后面可以接字符,而这些字符会在新的一行出现(目前的下一行)
c:替换,c的后面可以接字符,这些字符可以替换n1,n2之间的行
d:删除,因为是删除,d后面通常不接任何东西
i:插入,i的后面可以接字符,而这些字符会在新的一行出现(目前的上一行)
p:打印,将某个选择的数据打印出来,通常p会与参数sed -n一起运用
s:替换,可以直接进行替换的工作,通常这个s的操作可以搭配正则表达式
以行为单位的新增/删除功能
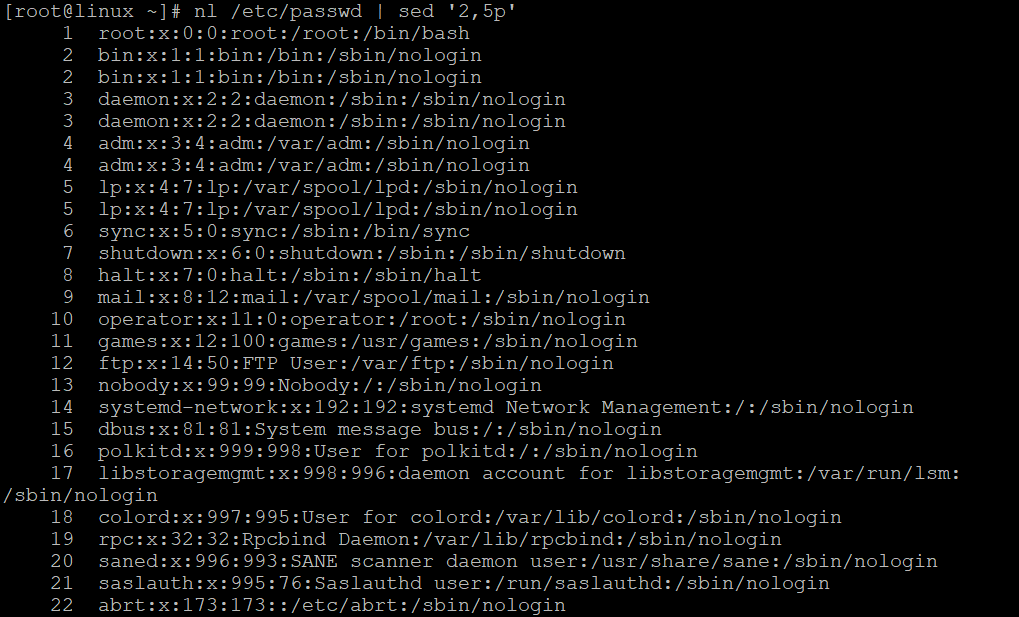
1、将/etc/passwd的内容列出并打印行号,同时,请将第2~5行删除
[root@linux ~]# cat -n /etc/passwd | sed '2,5d'注:sed后面的操作要以' '两个单引号括住
2、在第2行后加上drink tea?字样
[root@linux ~]# nl /etc/passwd | sed '2a drink tea'3、在第2行后面加上两行字
[root@linux ~]# nl /etc/passwd | sed '2a drink tea or ......\
drink beer'注:新增多行时,,每行之间必须要以反斜杠\来进行新行的增加
以行为单位的替换与显示功能
4、将2~5行的内容替换成no 2~5 number
[root@linux ~]# nl /etc/passwd | sed '2,5c no 2~5 number'5、仅列出文件内的2~5行
[root@linux ~]# nl /etc/passwd | sed -n '2,5p'- -n代表安静模式,如果没有加上-n的话,2~5行会重复输出
-
部分数据的查找并替换功能
sed 's/要被替换的字符/新的字符/g'
6、查询这台虚拟机的IP地址
首先,可以利用ifconfig这个命令来查看IP地址所在的那一行
[root@linux ~]# ifconfig ens33 然后可以发现IP地址在第二行,把它单独弄出来
然后可以发现IP地址在第二行,把它单独弄出来
[root@linux ~]# ifconfig ens33 | grep 'inet ' 这时候就可以使用sed的替换功能了
这时候就可以使用sed的替换功能了
[root@linux ~]# ifconfig ens33 | grep 'inet ' | sed 's/^.*inet //g'![]()
[root@linux ~]# ifconfig ens33 | grep 'inet ' | sed 's/^.*inet //g' | sed 's/ *netmask.*$//g'![]() 直接修改文件内容
直接修改文件内容
7、利用sed将regular_express.txt内每一行结尾若为.则换成!
[root@linux ~]# sed -i 's/\.$/\!/g' regular_express.txt8、利用sed直接在 regular_express.txt最后一行加入 # this is a test.
[root@linux ~]# sed -i '$a # this is a test.' regular_express.txt















 3137
3137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











