







目录
补充:os.environ['TF_CPP_MIN_LOG_LEVEL']
0. 实验概述
(以图片中的二分类问题为例)

1.利用Tensorflow自动加载mnist数据集

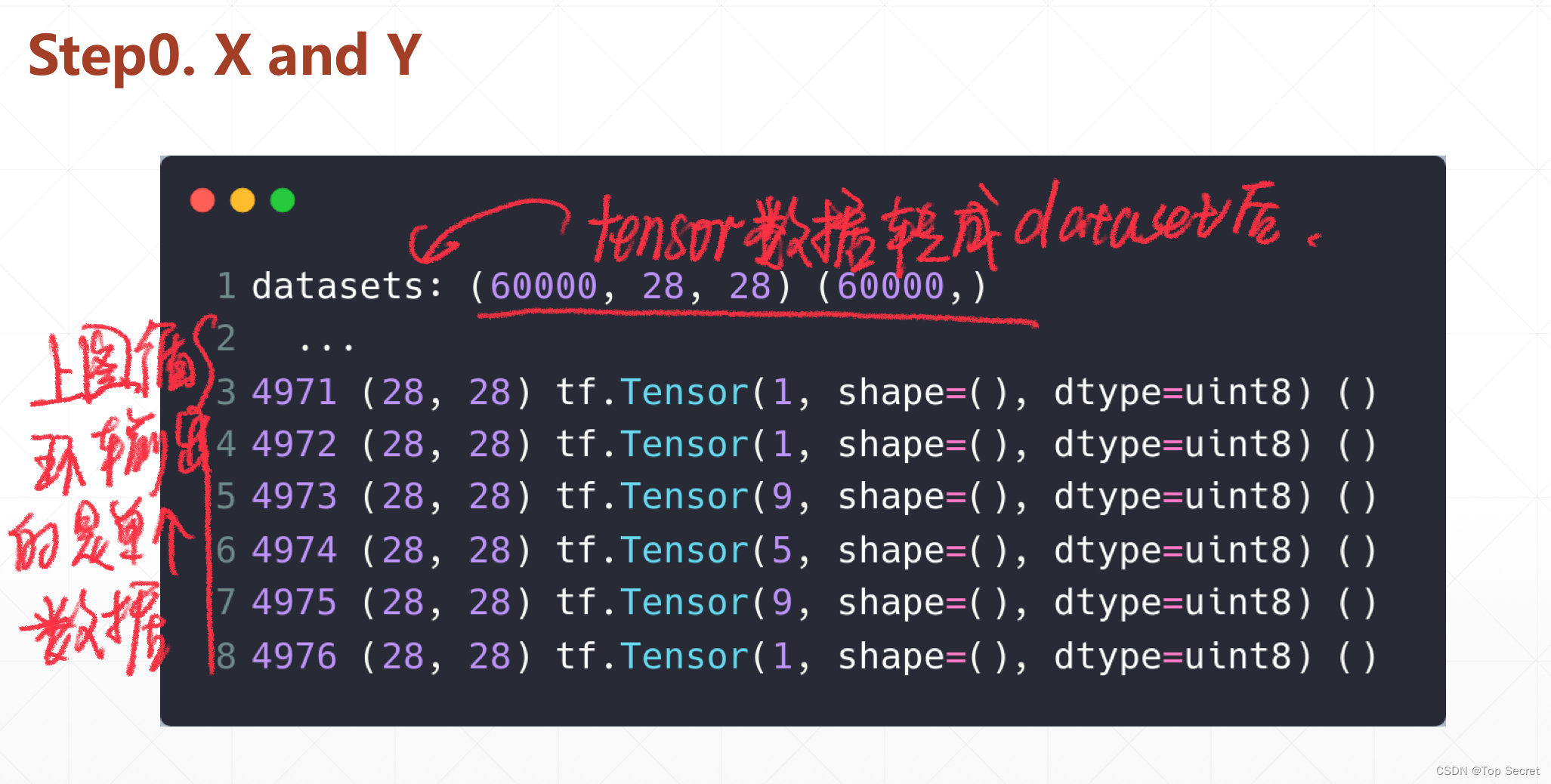
代码:
import tensorflow as tf
from tensorflow.keras import datasets, layers, optimizers
(xs,ys),_ = datasets.mnist.load_data() # 自动下载mnist数据集
print('datasets:',xs.shape,ys.shape)
xs = tf.convert_to_tensor(xs,dtype=tf.float32)/255. # 将mnist中的数据转为tensorflow格式
db = tf.data.Dataset.from_tensor_slices((xs,ys)) #将下载的数据存入datasets数据集
for step,(x,y) in enumerate(db): #单个数据输出
print(step,x.shape,y,y.shape)
代码切割分析:
2. 手写数字识别体验
2.1 准备网络结构与优化器

利用Sequential模块。
#准备网络结构与优化器
model = keras.Sequential([
#3层结构
layers.Dense(512, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(10)])
optimizer = optimizers.SGD(learning_rate=0.001)2.2 计算损失函数与输出

with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
# Step1. compute output
# [b, 784] => [b, 10]
out = model(x)
# Step2. compute loss
loss = tf.reduce_sum(tf.square(out - y)) / x.shape[0]2.3 梯度计算与优化
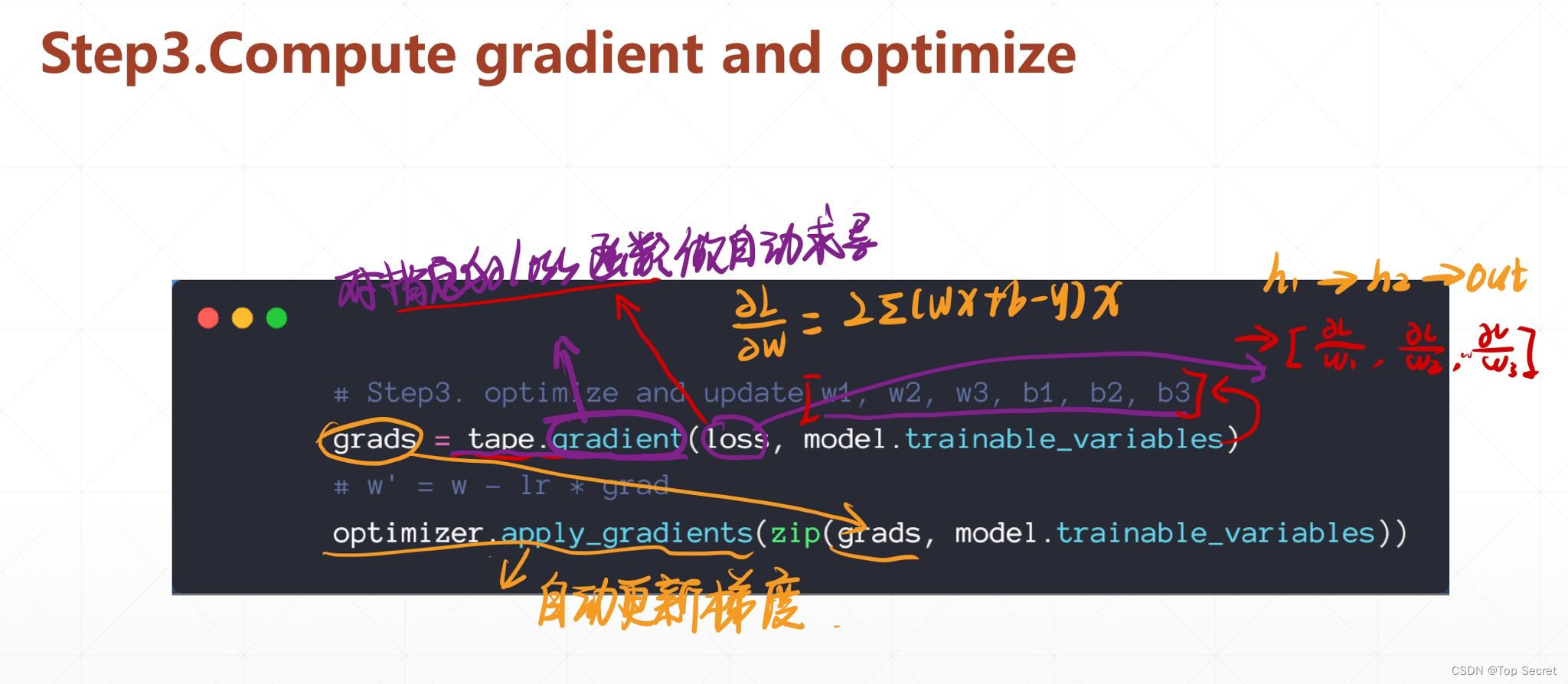
# Step3. optimize and update w1, w2, w3, b1, b2, b3
grads = tape.gradient(loss, model.trainable_variables)
# w' = w - lr * grad
optimizer.apply_gradients(zip(grads, model.trainable_variables))2.4 循环
2.5 完整代码
import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
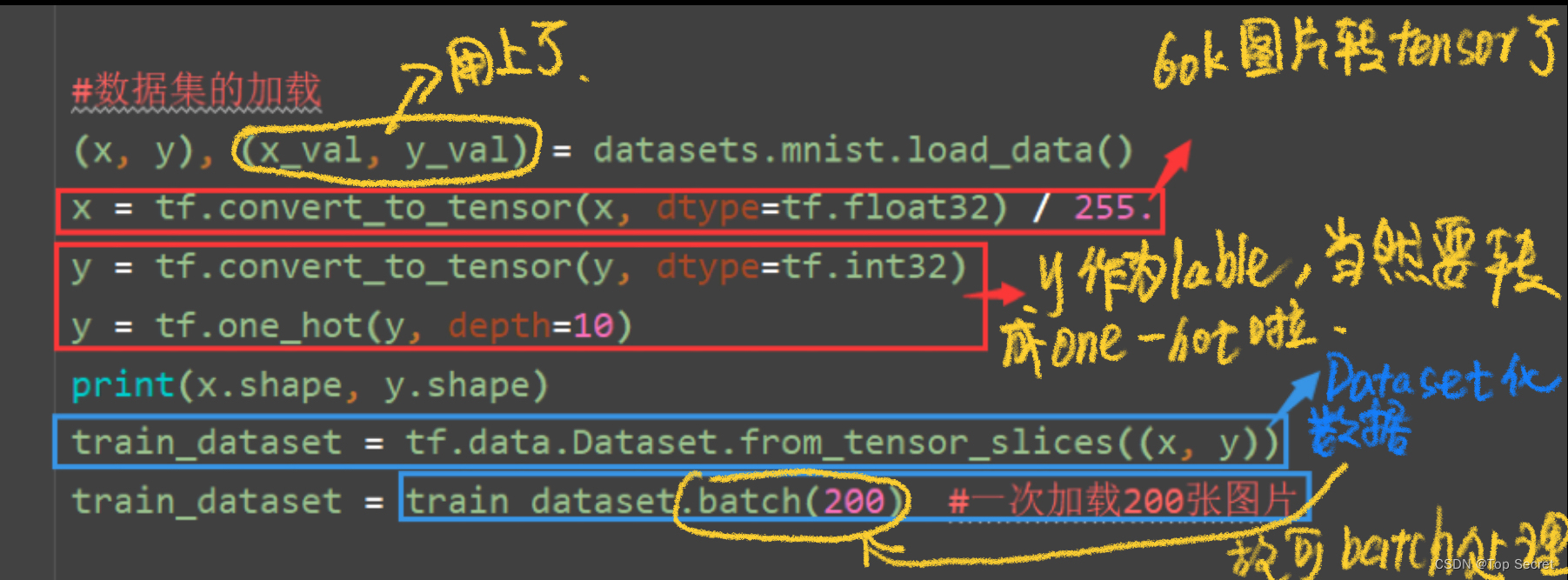
#数据集的加载
(x, y), (x_val, y_val) = datasets.mnist.load_data()
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
print(x.shape, y.shape)
train_dataset = tf.data.Dataset.from_tensor_slices((x, y))
train_dataset = train_dataset.batch(200) #一次加载200张图片
#准备网络结构与优化器
model = keras.Sequential([
#3层结构
layers.Dense(512, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(10)])
optimizer = optimizers.SGD(learning_rate=0.001)
#计算迭代
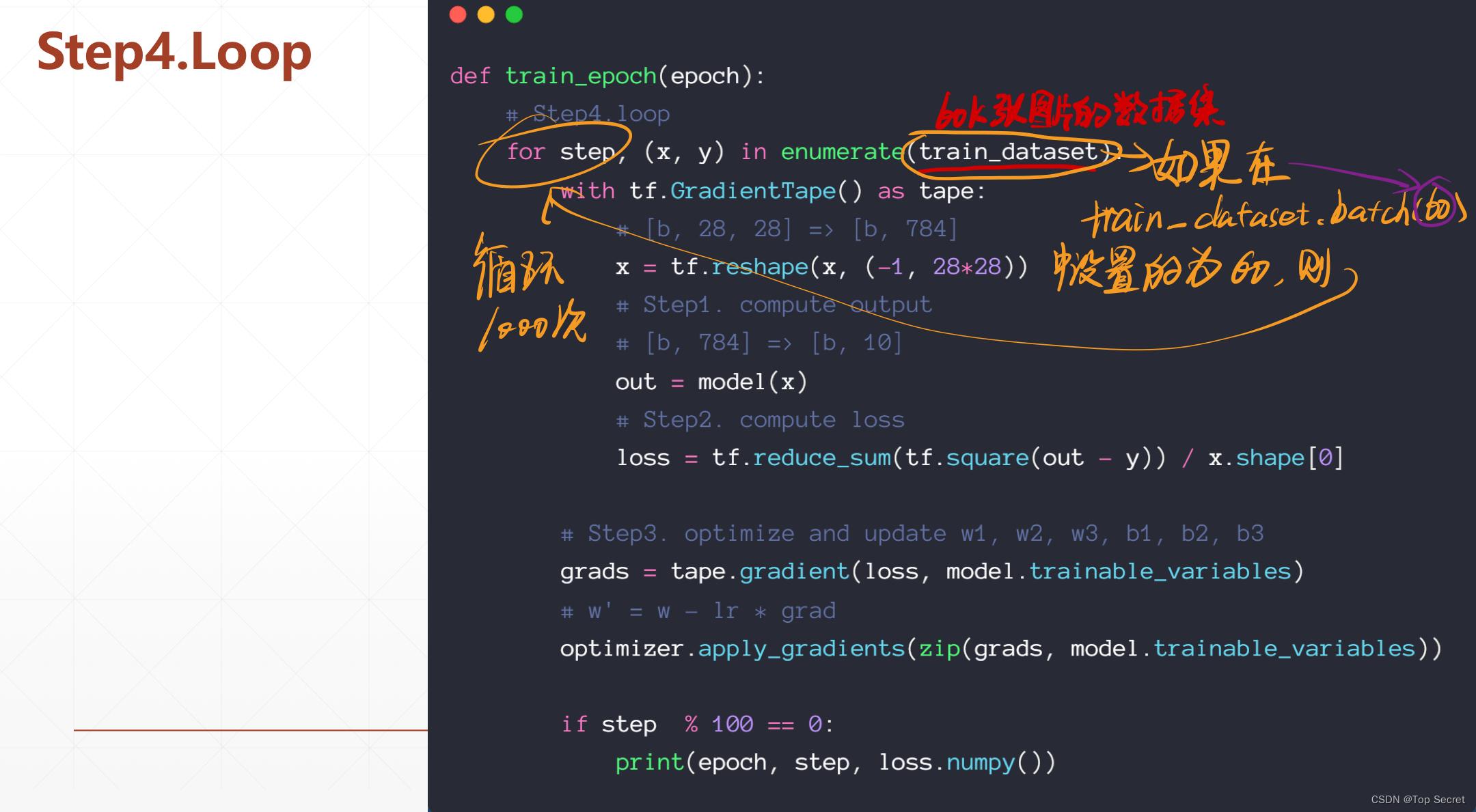
def train_epoch(epoch):
# Step4.loop
for step, (x, y) in enumerate(train_dataset):
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
# Step1. compute output
# [b, 784] => [b, 10]
out = model(x)
# Step2. compute loss
loss = tf.reduce_sum(tf.square(out - y)) / x.shape[0]
# Step3. optimize and update w1, w2, w3, b1, b2, b3
grads = tape.gradient(loss, model.trainable_variables)
# w' = w - lr * grad
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, 'loss:', loss.numpy())
def train():
#计算迭代30次
for epoch in range(30):
train_epoch(epoch)
if __name__ == '__main__':
train()训练结果:

补充:os.environ['TF_CPP_MIN_LOG_LEVEL']
os.environ["TF_CPP_MIN_LOG_LEVEL"]的取值有四个:0,1,2,3,分别和log的四个等级挂钩:INFO,WARNING,ERROR,FATAL(重要性由左到右递增)
当os.environ["TF_CPP_MIN_LOG_LEVEL"]=0的时候,输出信息:INFO + WARNING + ERROR + FATAL
当os.environ["TF_CPP_MIN_LOG_LEVEL"]=1的时候,输出信息:WARNING + ERROR + FATAL
当os.environ["TF_CPP_MIN_LOG_LEVEL"]=2的时候,输出信息:ERROR + FATAL
当os.environ["TF_CPP_MIN_LOG_LEVEL"]=3的时候,输出信息:FATAL

















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











