







目录
3.使用tf.data.Dataset.from_tensor_slices五步加载数据集
3.1 tf.data.Dataset.from_tensor_slices() 详解
3.2 利用迭代器迭代tf.data.Dataset.from_tensor_slices()得到的数据
3.3 使用tf.data.Dataset.from_tensor_slices五步加载数据集
1. 内容简介

2. tf.keras.datasets()

tf.keras.datasets是提供tf.keras.datasets 空间的公开Api,相关机器学习的数据集,可以直接使用该API获取并使用数据,有以下几个数据集:
boston_housing:波斯顿房屋价格回归数据集
cifar10:CIFAR10小图像分类数据集
cifar100:CIFAR100小图像分类数据集
fashion_mnist:Fashion-MNIST 数据集.
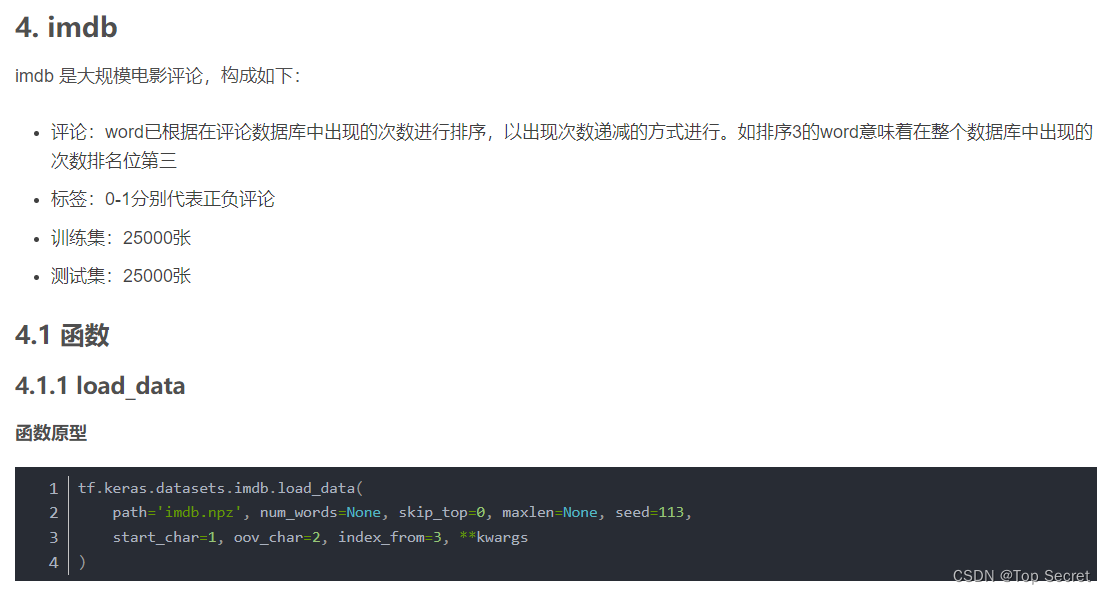
imdb:IMDB 分类数据集
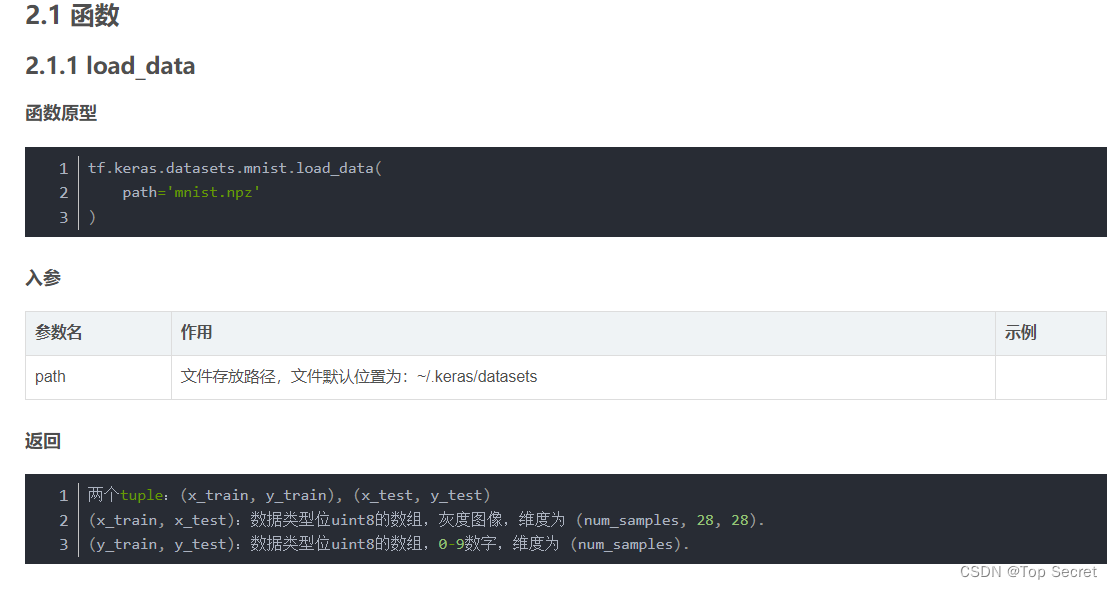
mnist:MNIST手写数字数据集
reuters:路透社主题分类数据集
2.1 minist


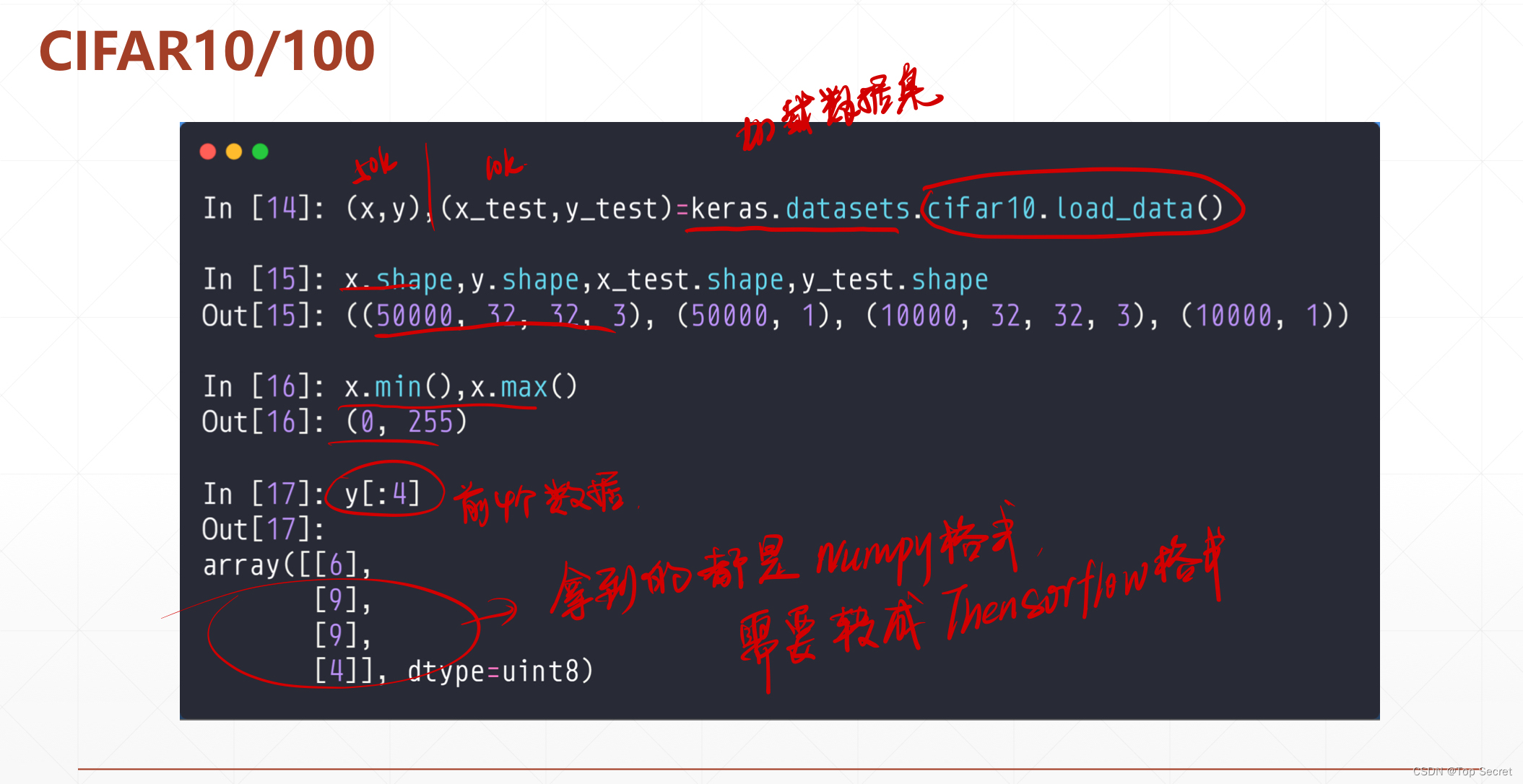
2.2 cifar10:CIFAR10小图像分类数据集



参考文章:
tf.keras.datasets学习并解析_「已注销」的博客-CSDN博客_keras.datasets
3.使用tf.data.Dataset.from_tensor_slices五步加载数据集
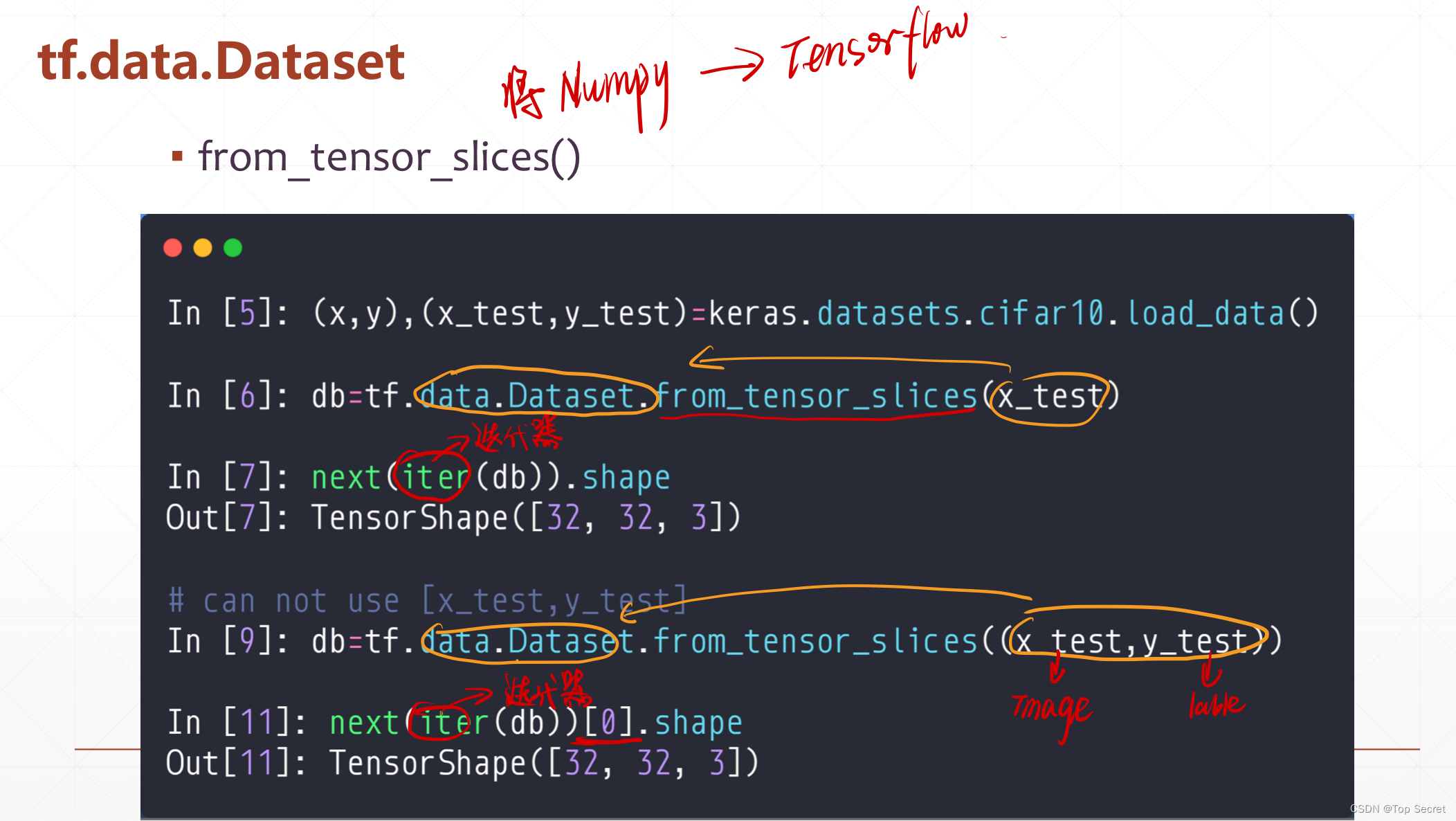
3.1 tf.data.Dataset.from_tensor_slices() 详解
参考文章:传送门
函数原型:
tf.data.Dataset.from_tensor_slices(
tensors, name=None
)
功能介绍:
该函数的作用是接收tensor,对tensor的第一维度进行切分,并返回一个表示该tensor的切片数据集.
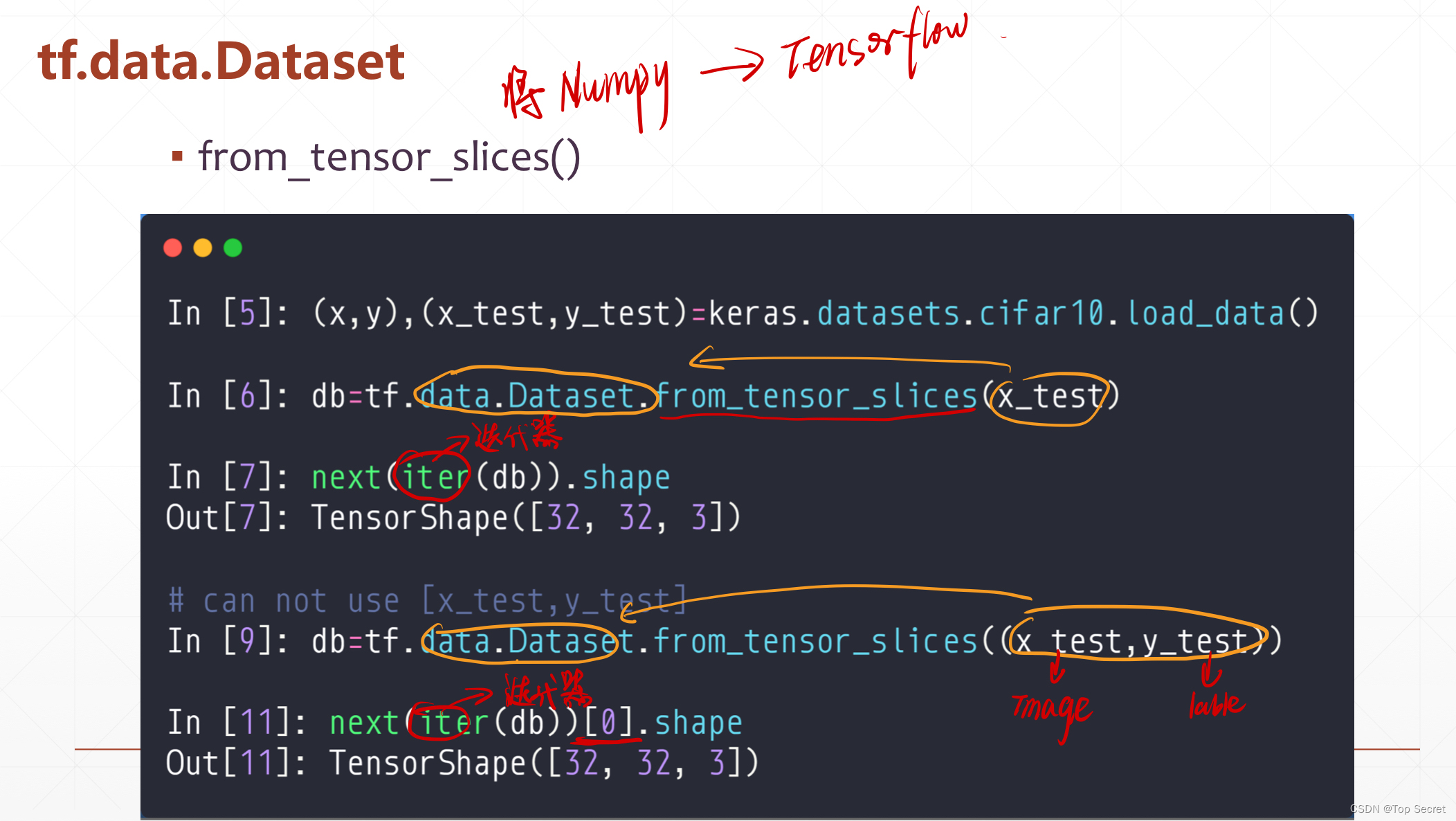
3.2 利用迭代器迭代tf.data.Dataset.from_tensor_slices()得到的数据
3.3 使用tf.data.Dataset.from_tensor_slices五步加载数据集
参考文章:传送门
思路:
Step0: 准备要加载的numpy数据
Step1: 使用 tf.data.Dataset.from_tensor_slices() 函数进行加载
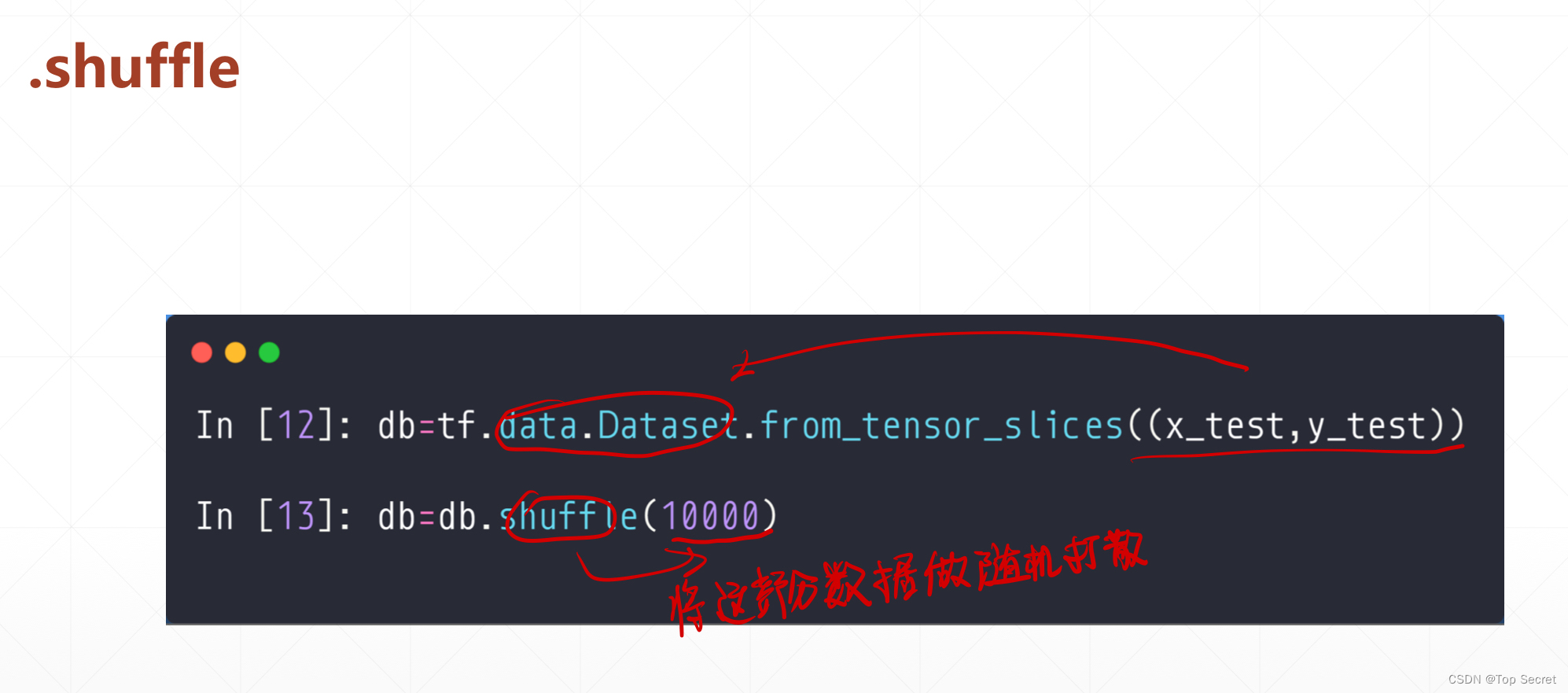
Step2: 使用 shuffle() 打乱数据
Step3: 使用 map() 函数进行预处理
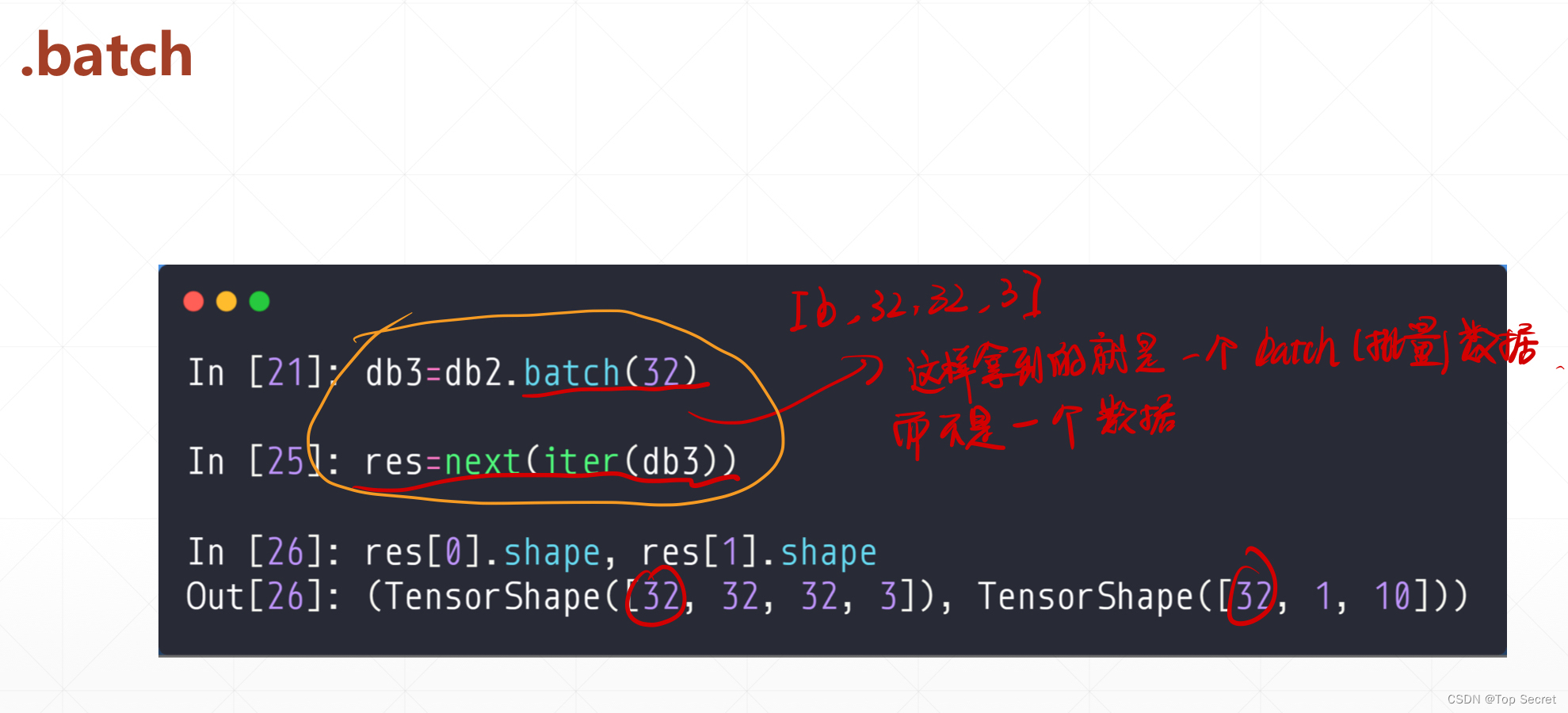
Step4: 使用 batch() 函数设置 batch size 值
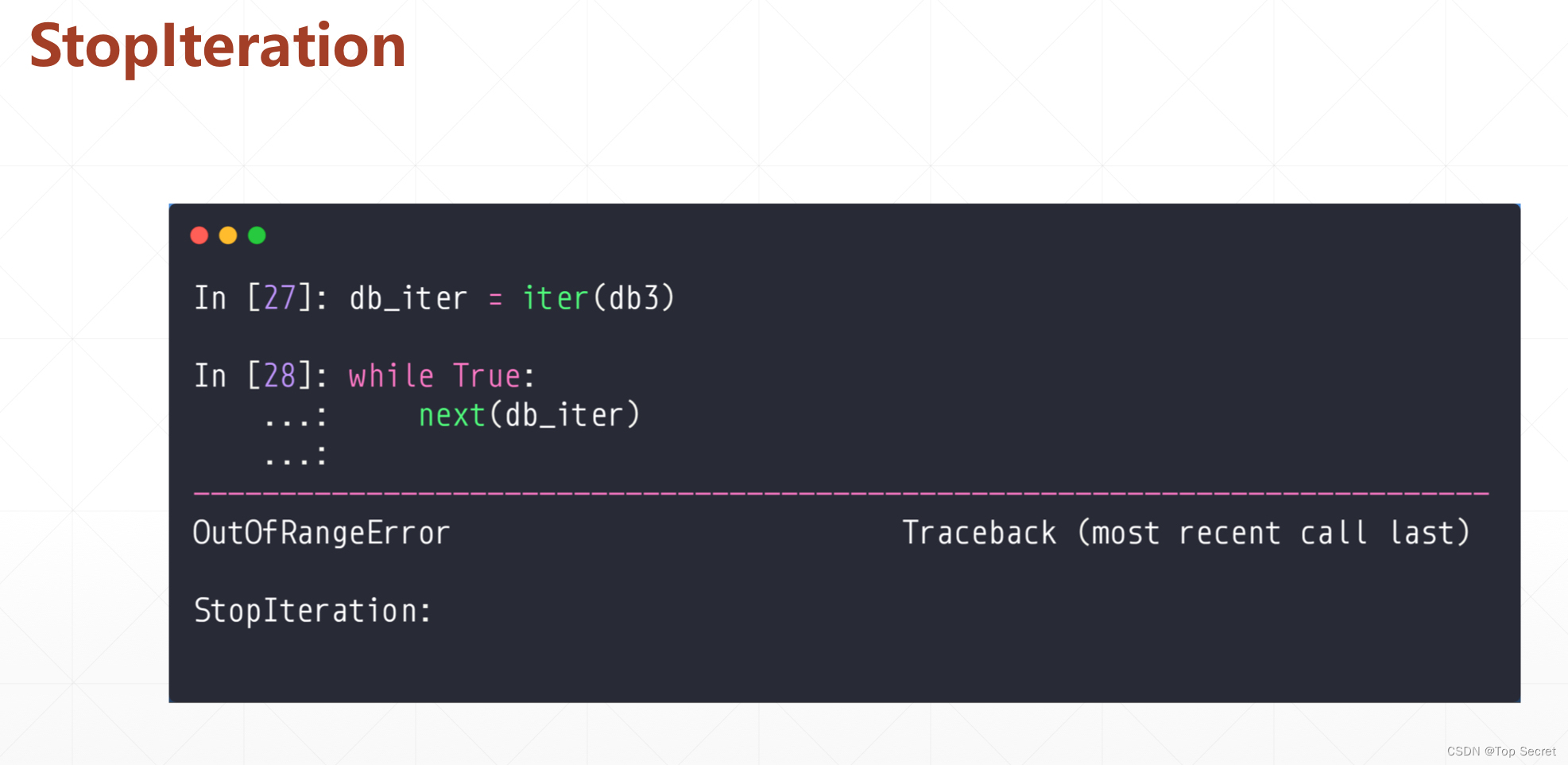
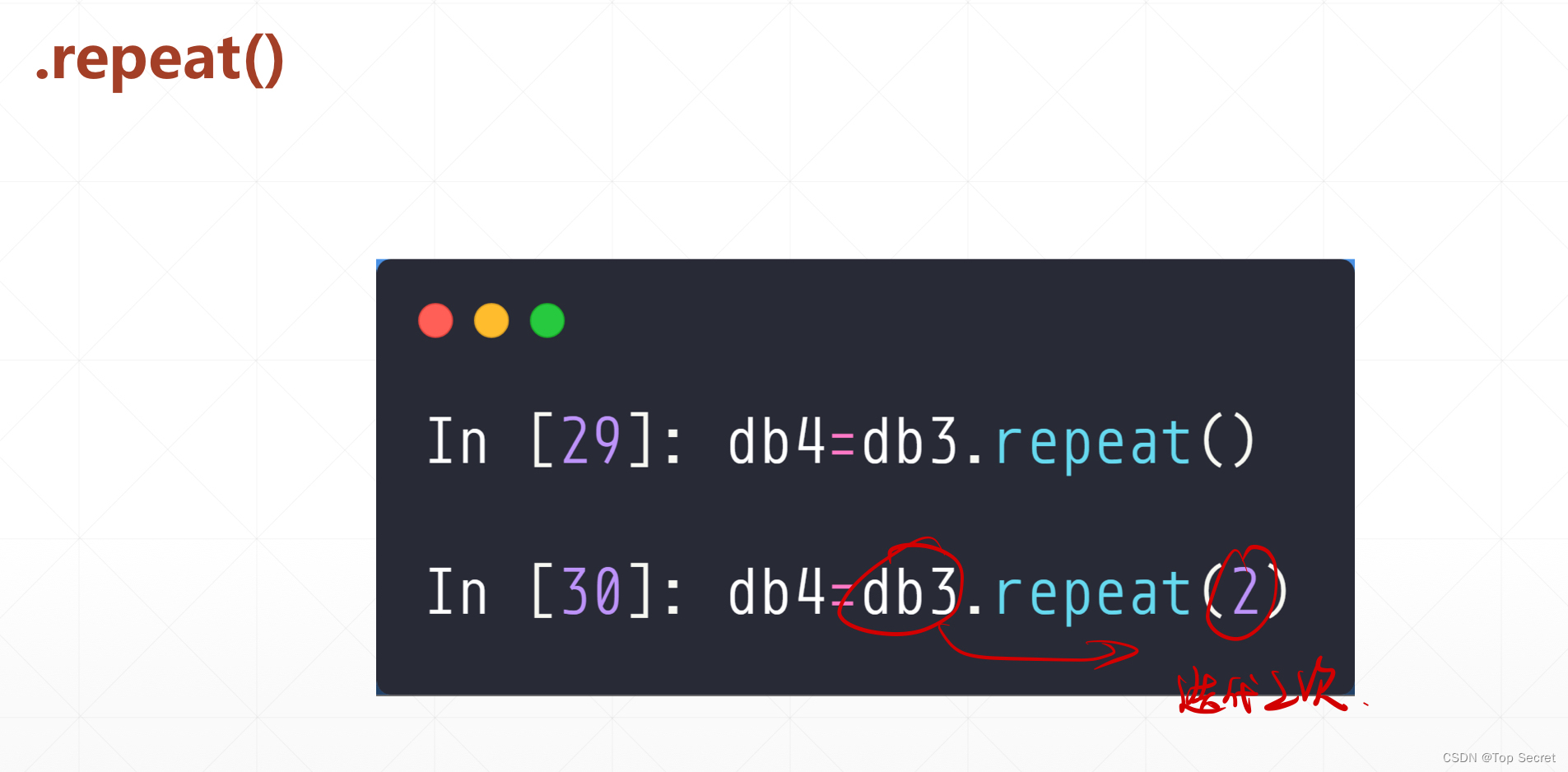
Step5: 根据需要 使用 repeat() 设置是否循环迭代数据集
代码:
import tensorflow as tf
from tensorflow import keras
def load_dataset():
# Step0 准备数据集, 可以是自己动手丰衣足食, 也可以从 tf.keras.datasets 加载需要的数据集(获取到的是numpy数据)
# 这里以 mnist 为例
(x, y), (x_test, y_test) = keras.datasets.mnist.load_data()
# Step1 使用 tf.data.Dataset.from_tensor_slices 进行加载
db_train = tf.data.Dataset.from_tensor_slices((x, y))
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
# Step2 打乱数据
db_train.shuffle(1000)
db_test.shuffle(1000)
# Step3 预处理 (预处理函数在下面)
db_train.map(preprocess)
db_test.map(preprocess)
# Step4 设置 batch size 一次喂入64个数据
db_train.batch(64)
db_test.batch(64)
# Step5 设置迭代次数(迭代2次) test数据集不需要emmm
db_train.repeat(2)
return db_train, db_test
def preprocess(labels, images):
'''
最简单的预处理函数:
转numpy为Tensor、分类问题需要处理label为one_hot编码、处理训练数据
'''
# 把numpy数据转为Tensor
labels = tf.cast(labels, dtype=tf.int32)
# labels 转为one_hot编码
labels = tf.one_hot(labels, depth=10)
# 顺手归一化
images = tf.cast(images, dtype=tf.float32) / 255
return labels, images
龙老师PPT:


















 1034
1034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











