






Abstract:
In this paper, we exploit the capability of global context information by different-regionbased context aggregation through our pyramid pooling module together with the proposed pyramid scene parsing network (PSPNet).
Motivation:
Our pyramid scene parsing network (PSPNet) described to improve performance for open-vocabulary object and stuff identification in complex scene parsing.In order to get contextual relationship and global information for different receptive fields.
Directly fusing them to form a single vector may lose the spatial relation and cause ambiguity. Global context information along with sub-region context is helpful in this regard to distinguish among various categories. A more powerful representation could be fused information from different sub-regions with these receptive fields. Similar conclusion was drawn in classical work of scene/image classification.
Baseline:
In SPPNet, feature maps in different levels generated by pyramid pooling were finally flattened and concatenated to be fed into a fully connected layer for classification. This global prior is designed to remove the fixed-size constraint of CNN for image classification. To further reduce context information loss between different sub-regions, we propose a hierarchical global prior(分层全局先验), containing information with different scales and varying among different sub-regions.
Method:
Pyramid parsing module is applied to harvest different sub-region representations, followed by upsampling and concatenation layers to form the final feature representation, which carries both local and global context information.
Noted that the number of pyramid levels and size of each level can be modified. They are related to the size of feature map that is fed into the pyramid pooling layer. The structure abstracts different sub-regions by adopting varying-size pooling kernels in a few strides.
Using our 4-level pyramid, the pooling kernels cover the whole, half of, and small portions of the image. They are fused as the global prior. Then we concatenate the prior with the original feature map in the final part of pyramid pooling module. It is followed by a convolution layer to generate the final prediction map.
Advantages:
The pyramid pooling module can collect levels of information, more representative than global pooling . In terms of computational cost, our PSPNet does not much increase it compared to the original dilated FCN network.
Overview:
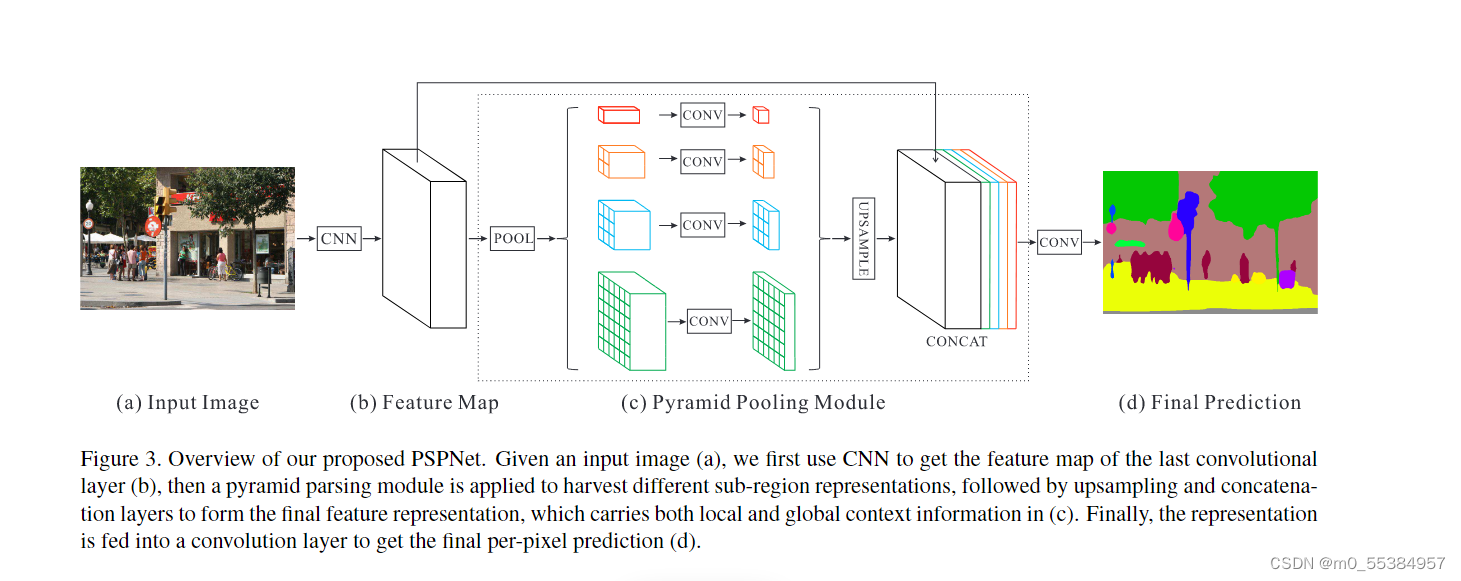
The pyramid pooling module fuses features under four different pyramid scales. The coarsest level highlighted in red is global pooling to generate a single bin output. The following pyramid level separates the feature map into different sub-regions and forms pooled representation for different locations. The output of different levels in the pyramid pooling module contains the feature map with varied sizes. To maintain the weight of global feature, we use 1×1convolution layer after each pyramid level to reduce the dimension of context representation to 1/N of the original one if the level size of pyramid is N . Then we directly upsample the low-dimension feature maps to get the same size feature as the original feature map via bilinear interpolation. Finally, different levels of features are concatenated as the final pyramid pooling global feature.














 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









