






问题
我最近想训练一套自己的nerf
就当我围绕目标物体拍摄了20张图片,用COLMAP生成位姿数据了之后,用llff格式化数据,遇到了以下报错:
ERROR: the correct camera poses for current points cannot be accessed

解决
我在这个github issue上找到了参考答案:

也就是说,我给的数据集里存在未识别出位姿的图片。
于是,我回头看COLMAP。一方面,识别出的位姿不是呈现环状扫描,而是单向的。另一方面,看面板右下角,我明明提供了20张图片,但识别出的结果只有13 Images。据我所知,数据集至少要提供20张图片,训练效果才会达到预期。

我之前获取数据集的方式有问题:我不应该用直接拍摄的形式,我提供的图片数量不够多不够保险。
以下是我探索到的、可行的方法:
第一步,围绕目标物体拍摄视频。以防万一,我绕了两圈,绝对确保数据集能形成一个位姿闭环。
第二步,截帧。
打开这个免费的截帧网站https://www.bytedig.com/web/video-frame,上传视频,设置采样间隔,设置总帧数,点击提取视频帧。

然后这个网站就会播放一遍视频,并且截帧。视频最好停止在最后一秒。
检查一下截到的图片,目标物体是不是都在画面中间,有没有被挡住。把不满意的图片删掉。点击“下载全部帧图片”。把下载到的压缩包解压。(图片名已经编号了,超贴心。)粘贴到数据集文件夹。
第三步,再次检测位姿。
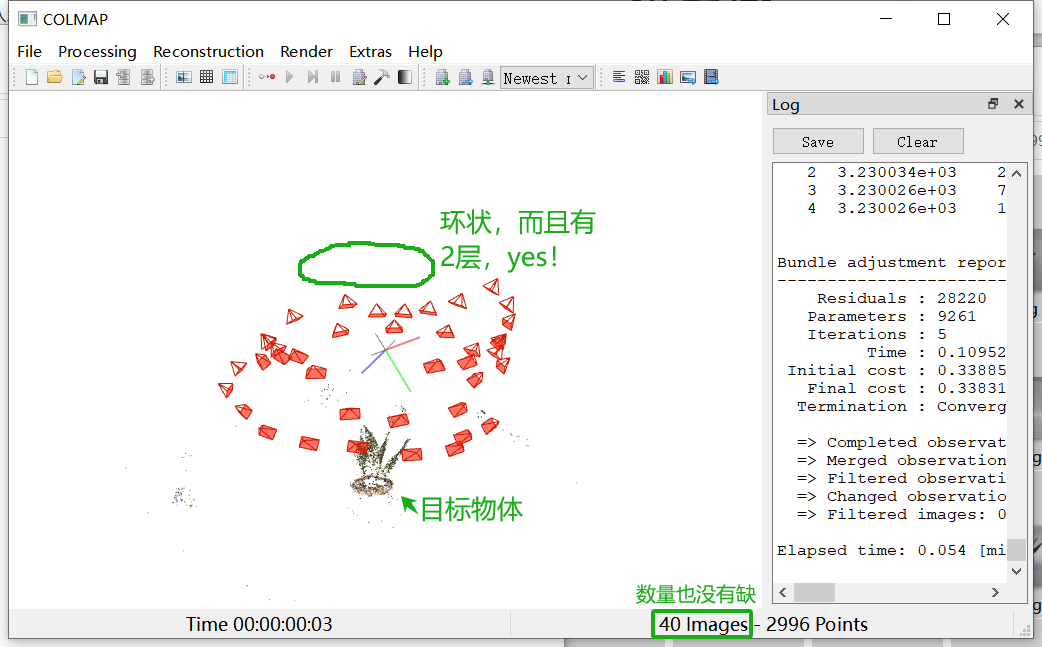
第四步,再次启用LLFF。成功!

题外话:LLFF环境依赖
关于llff的依赖库,我总是搞不下来,报错ERROR: No matching distribution found for tensorflow-gpu==1.*

我尝试着使用nerfstudio的环境,没想到也可以!















 6097
6097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









