






详细拆解目标检测中的NMS
1、简单介绍
官方解释:NMS非极大值抑制(Non-Maximum Suppression, NMS),一个关键的后处理步骤,用于从检测器输出的多个边界框中筛选出最优的边界框。
个人理解:模型推理输出后,会出现冗余框如下图所示。通过NMS操作可以去除冗余框,达到精准识别。

2、具体过程
以单类别目标检测为例
- 输入:
- 多个检测框的列表,每个检测框包含:
- 检测框的坐标值(模型输出)
- 类别得分(模型输出)
- 用户定义的iou阈值
- 多个检测框的列表,每个检测框包含:
- 操作:
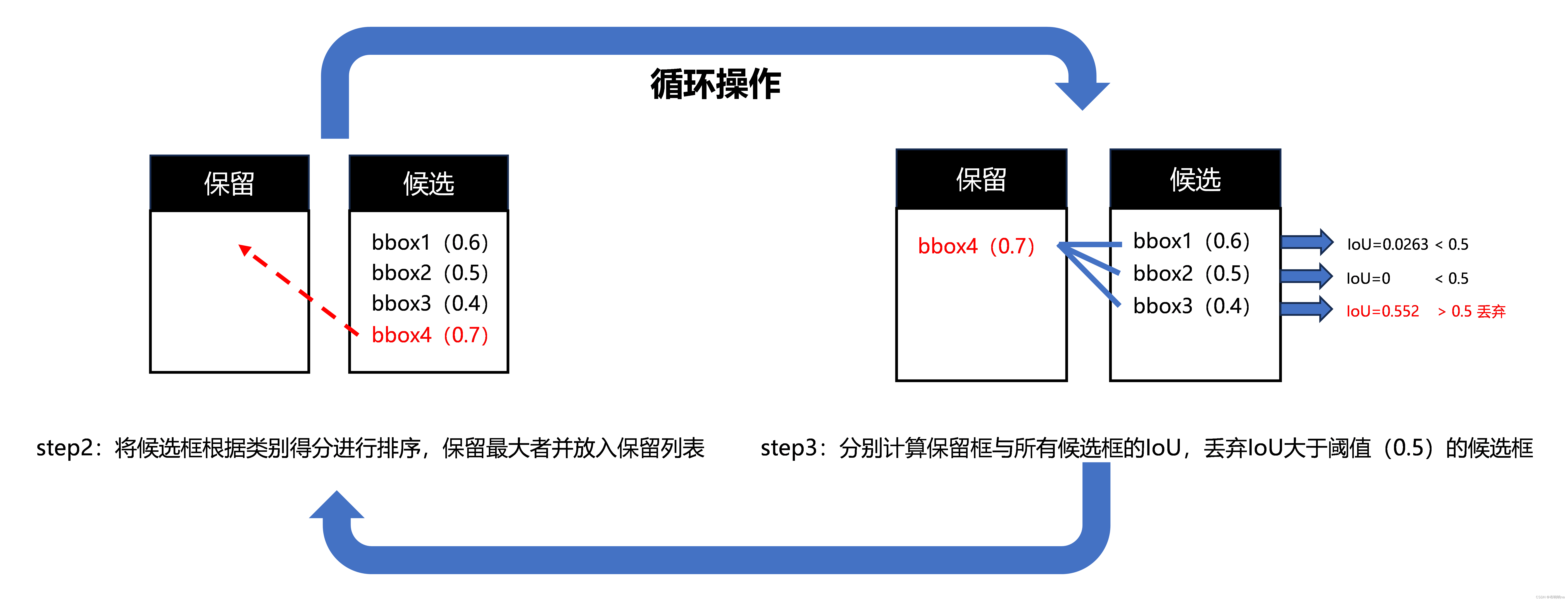
- 初始化保留列表(空)和候选列表(输入的检测框列表)
- 对候选列表中的检测框根据类别得分进行排序,将得分最高的检测框x放入保留列表
- 计算 x 与候选列表中每个检测框 y 的iou(交并比),如果大于设定阈值,则认为重叠过大,丢弃y,如果小于则保留
- 重复步骤2、3直到候选框为空
- 输出:
- 最终保留的检测框列表即为NMS的输出结果
3、具体代码示例
以yolov5的NMS为例
def non_max_suppression(prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300):
"""
prediction: 输入的预测结果,形状为 (batch_size, num_anchors, 5 + num_classes),其中 5 包括边界框的 (x, y, w, h, conf)
conf_thres: 置信度阈值,低于此阈值的预测框将被忽略
iou_thres: 交并比(IoU)阈值,高于此阈值的边界框将被抑制
classes: 类别列表
agnostic: 是否进行类别无关的 NMS
multi_label: 是否允许多标签分类
labels: 先验标签
max_det: 每张图像的最大检测数
"""
"""
以prediction=[1, 13860, 10], conf_thres=0.5, iou_thres=0.5, classes=None, agnostic= False, multi_label=False, labels=(), max_det=300为具体参数进行分析:
"""
bs = prediction.shape[0] # batch_size = 1
nc = prediction.shape[2] - 5 # 类别数量:10 - 4个坐标 - 1个置信度 = 5
xc = prediction[..., 4] > conf_thres # 筛选大于conf_thres的检测框,13860个检测框中置信度>conf_thres的bool列表 = [T,F,F...T], size:[1,13860]
# 确保阈值们都在0~1的合理范围内
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
max_wh = 7680 # 最大边界框宽度高度
max_nms = 30000 # 最大 NMS 输入框数
time_limit = 0.3 + 0.03 * bs # 超时时间
redundant = True # 是否需要冗余检测
multi_label &= nc > 1 # 每个框是否允许多个标签
merge = False # 是否使用合并 NMS
t = time.time()
"""
根据batch_size数量,初始化保留列表
"""
output = [torch.zeros((0, 6), device=prediction.device)] * bs
"""
循环batch_size的每一张图片
"""
for xi, x in enumerate(prediction): # xi = 0, x为13860个检测框,size为[13860,10]
# 根据xc筛选出不合格的检测框,x的size为[n, 10],0<=n<=13860
x = x[xc[xi]]
# 先验标签处理(暂时忽略)
if labels and len(labels[xi]):
lb = labels[xi]
v = torch.zeros((len(lb), nc + 5), device=x.device)
v[:, :4] = lb[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# 如果筛选完后,x的数量为0,即没有检测框,则进行下一张图片
if not x.shape[0]:
continue
# 将n个检测框中,各类别的conf*整体的conf,即6到10列都乘上第五列的数值
x[:, 5:] *= x[:, 4:5]
# 将n个检测框的边界框从 (x, y, w, h) 转换为 (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else:
# conf为n个检测框中各类别中概率的最大值,size为[n,1]
# j为conf的索引值,size[n,1]
conf, j = x[:, 5:].max(1, keepdim=True)
# 将box,conf,j在列方向拼接为[x1,y1,x2,y2,conf,j],size为[n,6]
# 将包含n个检测框类别最大值的conf,转置为[1,n]并和conf_thres比较得到[1,n]的bool列表
# 最终x为从n个检测框中筛选出最大类别概率大于conf_thres的m个检测框,m<=n,size[m,6]
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# 判断筛选完检测框数量是否小于0或大于最大值
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
# 开始进行NMS计算,c为x的第六列也就是j*max_wh,目的是让不同类别的检测框产生不同的偏移量,避免不同类别的检测框相互抑制,size为[n,1]
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
# boxes为x的前四列加上偏移量c,size为[n,4]
# scores为x的第五列也就是类别概率最大值,即类别置信度,size为[n,1]
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
# 调用nms操作函数,返回保留框的索引列表i
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
# 最终将保留检测框列表赋值给output,并返回
output[xi] = x[i]
if (time.time() - t) > time_limit:
LOGGER.warning(f'WARNING: NMS time limit {time_limit:.3f}s exceeded')
break # time limit exceeded
return output4、NMS优缺点分析
- 优点
-
减少冗余检测:NMS能够有效地去除重叠度较高的检测框,从而减少冗余检测,提高检测结果的准确性
-
提高检测结果的稀疏性:通过去除重叠的检测框,NMS可以使最终的检测结果更加稀疏
-
易于实现:NMS算法相对简单,易于实现,并且可以很容易地集成到现有的目标检测框架中
-
-
缺点
-
参数敏感:对阈值设定比较敏感,太大太小都影响效果,会出现误检漏检情况
-
计算复杂度高:虽然NMS算法相对简单,但在处理大量检测框时,其计算复杂度可能会很高
-
5、拓展
1、DIoU NMS
2、Soft NMS
















 2516
2516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









