






数据采集与获取
编辑:
先贴一下整理的相关fastcode:
1. BeautifulSoup的find方法
# for example
soup.find('a') # 根据标签名查找
soup.find(id='link1') # 根据属性查找
soup.find(attrs={'id':'link1'}) # 根据属性查找
soup.find(test='aaa') # 根据标签文本内容查找
2. Tag对象
find方法返回的是Tag对象,有如下属性
Tag对象对应于原始文档中的html标签
name:标签名称
attrs:标签属性的键和值
text:标签的字符串文本
3. 正则表达式
. \d
+*?
()
[]
\
r原串
import re
rs = re.findall('\d','123')
rs = re.findall('\d*','456')
rs = re.findall('\d+','789')
rs = re.findall('a+','aaabcd')
print(rs)
import re
# 分组的使用
rs = re.findall('\d{1,2}','chuan13zhi2')
rs = re.findall('aaa(\d+)b','aaa91b')
print(rs)
# 一般的正则表达式匹配一个\需要四个\
rs = re.findall('a\\\\bc','a\\bc')
print(rs)
print('a\\bc')
# 使用r原串
rs = re.findall(r'a\\rbc','a\\rbc')
print(rs)
4. json字符串互转python数据
import json
json_str = '''[{"a":"thia is a",
"b":[1,2,3]},{"a":"thia is a",
"b":[1,2,3]}]'''
rs = json.loads(json_str)
print(rs)
print(type(rs)) # <class 'list'>
print(type(rs[0])) # <class 'dict'>
print(type(json_str)) # <class 'str'>
import json
json_str = '''[
{
"a": "this is a",
"b": [1, 2,"熊猫"]
},
{
"c": "thia is c",
"d": [1, 2, 3]
}
]'''
rs = json.loads(json_str)
json_str = json.dumps(rs,ensure_ascii=False)
print(json_str)
5. json格式文件互转python数据
# json格式文件转python数据
with open('data/test.json') as fp:
python_list = json.load(fp)
print(python_list)
print(type(python_list)) # <class 'list'>
print(type(python_list[0])) # <class 'dict'>
print(type(fp)) # <class '_io.TextIOWrapper'>
with open("data/test1.json",'w') as fp:
json.dump(rs,fp,ensure_ascii=False)
整理疫情获取的渠道如下,这里仅仅列出几个常见的:
腾讯新闻https://news.qq.com/zt2020/page/feiyan.htm#%2F=
中国卫健委http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml
新浪新闻https://news.sina.cn/zt_d/yiqing0121
网易新闻https://wp.m.163.com/163/page/news/virus_report/index.html
TRT https://www.trt.net.tr/chinese/covid19
Tableau https://www.tableau.com/zh-cn/covid-19-coronavirus-data-resources/global-tracker
Outbreak https://www.outbreak.my/zh/world
新华网http://my‐h5news.app.xinhuanet.com/h5activity/yiqingchaxun/index.html
凤凰网https://news.ifeng.com/c/special/7uLj4F83Cqm
新浪网https://news.sina.cn/zt_d/yiqing0121
WHOhttps://covid19.who.int/
Tableau: https://www.tableau.com/covid‐19‐coronavirus‐data‐resources
Johns Hopkins:https://coronavirus.jhu.edu/map.html
Worldometers: https://www.worldometers.info/coronavirus/
CDC: https://www.cdc.gov/covid‐data‐tracker/#cases
各省份的卫健委、疫情防控部门的主页
我们着重看一下,在爬取境外网站的世界疫情数据时会遇到的一些反爬问题。
验证headers中的User-Agent字段
我们用的是Selenium,头字段肯定是有的,所以这点不攻自破。
限制用户必须登录
如果未登录或权限不够,则论坛直接禁止访问。
笔者从各种渠道获得了数十个不同的有权限的账号,全部正常登录一遍,获取cookie,组一个cookies池。在程序的最前面先随机选一个cookie加载。
同一账号/统一IP短时间内连续访问则返回广告页面
使用多个有权限的账号建cookie池;使用多个原生IP建cookie池;
给爬取循环添加随机sleep;
Cookies
论坛在校验cookie上有特殊的机制。除了两个用于验证用户名和id的memberID、userPasshash以外,还有一个用于验证账号合法性的随机生成的igneous字段。
多个账号cookie建池;每次访问之后清cookie;
AJAX
页面刷新结合了Ajax和传统模式。
就是为了克服Ajax使用的Selenium。这种类似无头浏览器的自动化工具可以很好处理Ajax动态拉取问题。
验证码
为了防止同Ip过多访问被封禁,我们使用了SoftEther来获取大量的原生Ip。如果走境外访问,一定几率会出Google平台的验证码ReCaptcha。
我们用国外的接码平台来搞。不同于一些小作坊式的数字/字幕验证码,谷歌的ReCaptcha还是不好搞。一开始想的是在本地部署一个深度学习模型,但是ReCaptcha的类型太多了,还是转向专业的接码平台。就是有点贵。
我们还是重点看各种反爬应对手段相关的代码。
验证headers中的User-Agent字段
我们用的是Selenium,看一下相关的代码。
options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
options.add_experimental_option("prefs", prefs)
driver_title = webdriver.Chrome(options=options, executable_path=chrome_driver)
driver_user = webdriver.Chrome(options=options, executable_path=chrome_driver)
driver_content = webdriver.Chrome(options=options, executable_path=chrome_driver)
限制用户必须登录
如果未登录或权限不够,则论坛直接禁止访问。
看一下用于模拟登陆,获取cookie的代码。
try:
driver.get("https://bbs.nga.cn/thread.php?fid=-7")
time.sleep(40)
with open('cookies.txt', 'w') as cookiefile:
# 将cookies保存为json格式
cookiefile.write(json.dumps(driver.get_cookies()))
看一看cookie池存储部分的代码。
REDIS_HOST = 'localhost'
REDIS_PASSWORD = None
class RedisClient(object):
def __init__(self,type,website,host=REDIS_HOST,port=REDIS_PORT,password=REDIS_PASSWORD):
self.db = redis.StrictRedis(host=host,port=port,password=password,decode_responses=True)
self.type = type
self.website = website
def name(self):
return "{type}:{website}".format(type=self.type,website=self.website)
def set(self,usename,value):
return self.db.hset(self.name(),usename,value)
def get(self,usename):
return self.db.hget(self.name(),usename)
def delete(self,usename):
return self.db.hdel(self.name(),usename)
def count(self):
return self.db.hlen(self.name())
def random(self):
return random.choice(self.db.hvals(self.name()))
def usernames(self):
return self.db.hkeys(self.name())
def all(self):
return self.db.hgetall(self.name())
看一下生成部分。
def __init__(self,username,password,browser):
self.url = ''
self.browser = browser
self.wait = WebDriverWait(browser,10)
self.username = username
self.password = password
def open(self):
self.browser.get(self.url)
self.wait.until(EC.presence_of_element_located((By.ID,'dologin'))).click()
self.browser.switch_to.frame('loginIframe')
self.wait.until(EC.presence_of_element_located((By.ID,'switcher_plogin'))).click()
self.wait.until(EC.presence_of_element_located((By.ID,'u'))).send_keys(self.username)
self.wait.until(EC.presence_of_element_located((By.ID,'p'))).send_keys(self.password)
time.sleep(2)
self.wait.until(EC.presence_of_element_located((By.ID,"login_button"))).click()
def password_error(self):
try:
# 当密码错误时会弹出一个提示,我们只需捕获这个错误提示就知道是否输入错误
return bool(self.wait.until(EC.presence_of_element_located((By.ID,'err_m'))))
except ex.TimeoutException:
return False
def get_cookies(self):
return self.browser.get_cookies()
同一账号/统一IP短时间内连续访问则返回广告页面
上面已经看了cookie池的相关代码,下面我们看一下IP池相关的部分。
IP池是通用的,我们这里直接采用开源的GitHub上面的项目proxy_list。
#持久化
PERSISTENCE = {
'type': 'redis',
'url': 'redis://127.0.0.1:6379/1'
}
协程并发数
#爬取下来的代理测试可用性时使用,减少网络 io 的等待时间
COROUTINE_NUM = 50
保存多少条代理
默认200,如果存储了200条代理并不删除代理就不会再爬取新代理
PROXY_STORE_NUM = 300
如果保存的代理条数已到阀值,爬取进程睡眠秒数
默认60秒,存储满200条后爬虫进程睡眠60秒,醒来后如果还是满额继续睡眠
PROXY_FULL_SLEEP_SEC = 60
#已保存的代理每隔多少秒检测一遍可用性
PROXY_STORE_CHECK_SEC = 1200
#web api
指定接口 IP 和端口
WEB_API_IP = '127.0.0.1'
WEB_API_PORT = '8111'
验证码
为了防止同Ip过多访问被封禁,我们使用了SoftEther来获取大量的原生Ip。如果走境外访问,一定几率会出Google平台的验证码ReCaptcha。
看一下用国外的接码平台的代码。接码平台除了要花钱以外没有任何缺点。这个价格其实也可以接受,毕竟我们个人爬,也用不了多少。

构造发给打码平台的请求。
import requests
response = requests.get(url)
print(response.json())
https://2captcha.com/in.php?key=c0ae5935d807c28f285e5cb16c676a48&method=userrecaptcha&googlekey=6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-&pageurl=https://www.google.com/recaptcha/api2/demo&json=1
当页面出现ReCaptcha验证码的时候,这个验证码是放在一个外部frame里面的。我们可以找到验证码的唯一id。我们直接把这个id提交给打码平台即可。大概10-30秒钟就会返回结果。然后平台会返回接口id。
通过接口id获取最后的结果,是一个加密的token。
把这个token赋值给验证码对应的表单提交即可。
document.getElementById("g-recaptcha-response").innerHTML="TOKEN_FROM_2CAPTCHA";
环境:python 3.8
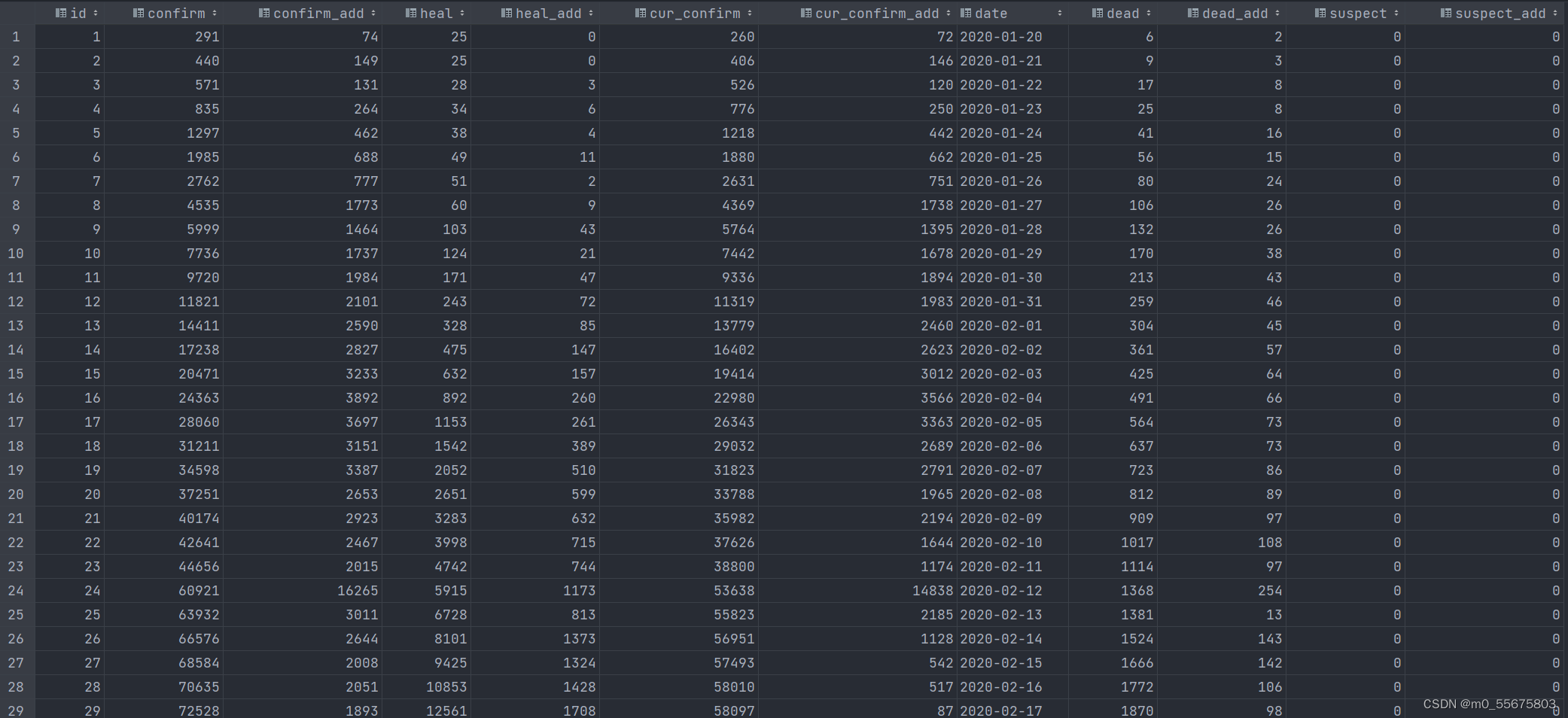
例如,爬取来源于腾讯的疫情数据。



import requests
import json
import pprint
import pandas as pd
发送请求
url = ‘https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&_=1638361138568’
response = requests.get(url, verify=False)
复制
获取数据
json_data = response.json()[‘data’]
复制
解析数据
json_data = json.loads(json_data)
china_data = json_data[‘areaTree’][0][‘children’] # 列表
data_set = []
for i in china_data:
data_dict = {}
data_dict[‘province’] = i[‘name’]
data_dict[‘nowConfirm’] = i[‘total’][‘nowConfirm’]
data_dict[‘dead’] = i[‘total’][‘dead’]
data_dict[‘heal’] = i[‘total’][‘heal’]
data_dict[‘healRate’] = i[‘total’][‘healRate’]
data_set.append(data_dict)
复制
保存数据
df = pd.DataFrame(data_set)
df.to_csv(‘data.csv’)
import requests
import json
import csv
url='https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery351007009437517570039_1629632572593&_=1629632572594'
head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
response = requests.get(url,headers=head).text
print(response)
dict1 =json.loads(response[42:132060])#这个切片位置是会变化的,需要我们去分析每天变化的位置,然后再去切片
d = json.loads(dict1['data'])#json是转化抓取来的数据格式,json.load是将字符串转化为字典的格式
print(d)
all_dict={}
all_dict['统计时间']=d["lastUpdateTime"]
chinaTotal = d['chinaTotal']
all_dict['累计确诊病例'] = chinaTotal['confirm']
all_dict['现有确诊'] = chinaTotal['nowConfirm']
all_dict['治愈病例'] = chinaTotal['heal']
all_dict['死亡病例'] = chinaTotal['dead']
all_dict['本土昨日新增'] = chinaTotal['suspect']
all_dict['境外输入'] = chinaTotal['importedCase']
all_dict['无症状感染者'] = chinaTotal['noInfect']
print(all_dict)
print(chinaTotal)
with open('yqin.csv','w+',newline='')as f:
f1= csv.writer(f)
list1=[]
f1.writerow(all_dict)
for i in all_dict:
list1.append(all_dict[i])
f1.writerow(list1)
# print(chinaTotal)
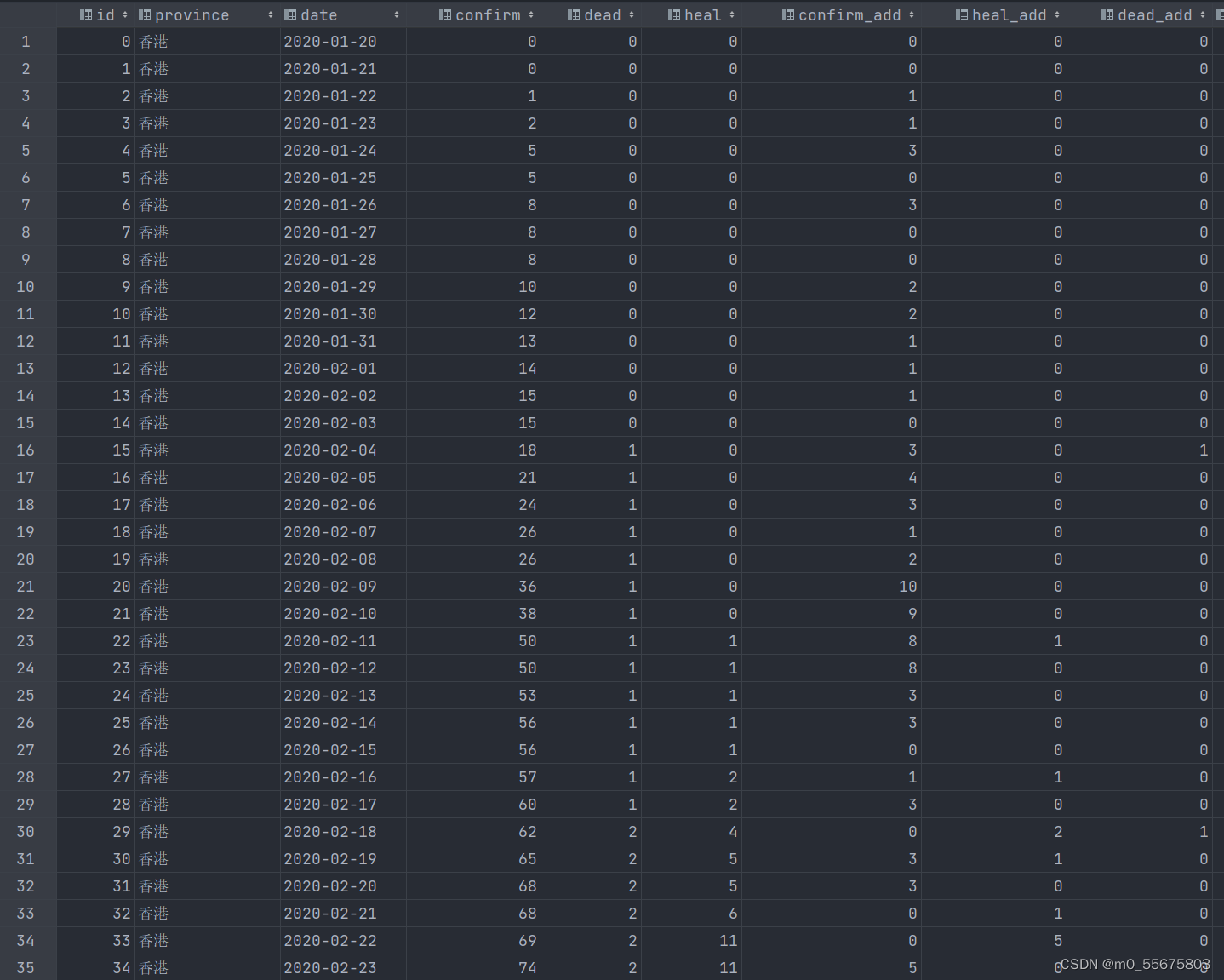
area = d['areaTree'][0]
# for i in area:
# print(area[i])
children = area['children']
with open('yq1.csv','w+',newline = '')as f:
list1= ['省份','现有病例','昨日新增','累计病例','死亡人数','治愈人数']
f1 = csv.writer(f)
f1.writerow(list1)
for i , index,in enumerate(children):
cc = children[i]
dd = []
dd.append(cc['name'])
dd.append(cc['total']['nowConfirm'])
dd.append(cc['today']['confirm'])
dd.append(cc['total']['confirm'])
dd.append(cc['total']['dead'])
dd.append(cc['total']['heal'])
f1.writerow(dd)
print(dd)
import json
import re
import requests
import datetime
today = datetime.date.today().strftime('%Y%m%d')
def crawl_dxy_data():
"""爬取丁香园实时统计数据,保存在data目录下,以当前日期作为文件名,文件格式为json格式
"""
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia') # 发送get请求
print(response.status_code) # 打印状态码
try:
url_text = response.content.decode() # 获取响应的html页面
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch', # re.search()用于扫描字符串以查找正则表达式模式产生匹配项的第一个位置,然后返回相应的match对象
url_text, re.S) # 在字符串a中,包含换行符\n,这种情况下:如果不适用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始匹配
texts = url_content.group() # 获取匹配正则表达式的整体结果
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') # 去除多余字符
json_data = json.loads(content)
with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
except:
print('<Response [%s]>' % response.status_code)
crawl_dxy_data()
# 获取当日国内疫情数据
def get_data(request):
response_data = json.loads(request.text)
all_data = response_data['data'] # 返回的数据
last_update_time = all_data['lastUpdateTime'] # 上次更新时间
# 总体数据
china_total = all_data['chinaTotal'] # 总计
total_confirm = china_total['confirm'] # 累计确诊
total_heal = china_total['heal'] # 累计治愈
total_dead = china_total['dead'] # 累计死亡
now_confirm = china_total['nowConfirm'] # 现存确诊(=累计确证-累计治愈-累计死亡)
suspect = china_total['suspect'] # 疑似
now_severe = china_total['nowSevere'] # 现存重症
imported_case = china_total['importedCase'] # 境外输入
noInfect = china_total['noInfect'] # 无症状感染
local_confirm = china_total['localConfirm'] # 本土确诊
# 新增数据
china_add = all_data['chinaAdd'] # 新增
add_confirm = china_add['confirm'] # 新增累计确诊?
add_heal = china_add['heal'] # 新增治愈
add_dead = china_add['dead'] # 新增死亡
add_now_confirm = china_add['nowConfirm'] # 新增现存确诊
add_suspect = china_add['suspect'] # 新增疑似
add_now_sever = china_add['nowSevere'] # 新增现存重症
add_imported_case = china_add['importedCase'] # 新增境外输入
add_no_infect = china_add['noInfect'] # 新增无症状
# print(china_add)
area_Tree = json.loads(response_data['data'])['areaTree'] # 各地区数据
for each_province in area_Tree[0]['children']:
# print(each_province)
province_name = each_province['name'] # 省名
province_today_confirm = each_province['today']['confirm'] # 省内今日确诊总数
province_total_confirm = each_province['total']['nowConfirm'] # 省内现存确诊总数
province_total_confirmed = each_province['total']['confirm'] # 省内确诊总数
province_total_dead = each_province['total']['dead'] # 省内死亡总数
province_total_heal = each_province['total']['heal'] # 省内治愈总数
province_total_localConfirm = each_province['total']['provinceLocalConfirm'] # 省内本土确证数
for each_city in each_province['children']:
city_name = each_city['name'] # 市名
city_today_confirm = each_city['today']['confirm'] # 市内今日确诊数
city_total_confirm = each_city['total']['nowConfirm'] # 市内现存确诊数
city_total_confirmed = each_city['total']['confirm'] # 市内确诊总数
city_total_dead = each_city['total']['dead'] # 市内死亡病例数
city_total_heal = each_city['total']['heal'] # 市内治愈数
city_grade = '' # 市风险等级
if 'grade' in each_city['total']:
city_grade = each_city['total']['grade']
print("省份:" + province_name +
" 地区:" + city_name +
" 今日确诊新增确诊:" + str(city_today_confirm) +
" 现存确诊:" + str(city_total_confirm) +
" 风险等级:" + city_grade +
" 累计确诊:" + str(city_total_confirmed) +
" 治愈:" + str(city_total_heal) +
" 死亡:" + str(city_total_dead))
if __name__ == '__main__':
# 接口
api = 'https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,' \
'diseaseh5Shelf '
head = {'User-Agent': 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, ' \
'like Gecko) Chrome/18.0.1025.166 Safari/535.19 '}
req = requests.get(api, headers=head)
print(req.text)
get_data(req)















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









