







新冠疫情来临,我简单的做一次疫情的数据分析温习我的python知识,也希望能帮到各位。分析中我用到的技术有:pyton爬取数据html+css将分析结果排版。用到的工具有excel+tableau进行数据处理分析和绘图。数据分析中还是存在很多的不足,很多地方有待提高,希望大家多多交流。
首先,我们要获取到数据,本次数据分析所需要的疫情数据来自https://ncov.dxy.cn。通过对网站的分析有世界的疫情数据和中国的疫情数据,所以我们要分别爬取到世界和全国的疫情数据。

好了,接下来废话不多说,为了更直观的了解数据爬取的过程,我把爬取世界疫情数据、爬取全国的疫情数据分开来写,虽然有很多相同的代码,不过能更好的理解数据获取的过程。
爬取世界疫情数据的代码:
import json
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
response = requests.get(url,headers = headers)
response.encoding = 'utf-8'
content = response.content.decode('utf-8')#以字节流形式打印网页源码
soup = BeautifulSoup(response.text,'lxml')
#爬取选择网页文档的内容
data = soup.find_all(name = 'script',attrs = {'id':'getListByCountryTypeService2true'})
#转为字符串
account = str(data)
account1 = account[95:-21]#切片截取从52到后面倒数21取到需要的数据
account1_json = json.loads(account1)
#提取数据到列表
id = []
continents = []
provinceName = []
currentConfirmedCount = []
confirmedCount = []
confirmedCountRank = []
suspectedCount = []
curedCount = []
deadCount = []
deadCountRank = []
deadRate = []
deadRateRank = []
print(len(account1_json))
i=0
for a in account1_json:
if 'id' in a:
id.append(a['id'])
else:
id.append('没有')
continents.append(a['continents'])
provinceName.append(a['provinceName'])
currentConfirmedCount.append(a['currentConfirmedCount'])
confirmedCount.append(a['confirmedCount'])
if 'confirmedCountRank' in a:
confirmedCountRank.append(a['confirmedCountRank'])
else:
confirmedCountRank.append('没有')
suspectedCount.append(a['suspectedCount'])
curedCount.append(a['curedCount'])
deadCount.append(a['deadCount'])
if 'deadCountRank' in a:
deadCountRank.append(a['deadCountRank'])
else:
deadCountRank.append('没有')
if 'deadRate' in a:
deadRate.append(a['deadRate'])
else:
deadRate.append('没有')
if 'deadRateRank' in a:
deadRateRank.append(a['deadRateRank'])
else:
deadRateRank.append('没有')
#转换成pandas数组
df = {
'id':pd.Series(id),
'所在大洲':pd.Series(continents),
'城市':pd.Series(provinceName),
'当前确诊':pd.Series(currentConfirmedCount),
'累计确诊':pd.Series(confirmedCount),
'确诊排名':pd.Series(confirmedCountRank),
'疑似病例':pd.Series(suspectedCount),
'治愈人数':pd.Series(curedCount),
'死亡人数':pd.Series(deadCount),
'死亡人数排名':pd.Series(deadCountRank),
'死亡率':pd.Series(deadRate),
'死亡率排名':pd.Series(deadRateRank)
}
pds = pd.DataFrame(df)
pds.to_excel('1.xlsx', index=False)
以上代码我将数据爬取后用pandas处理过后并写到表格文件里:
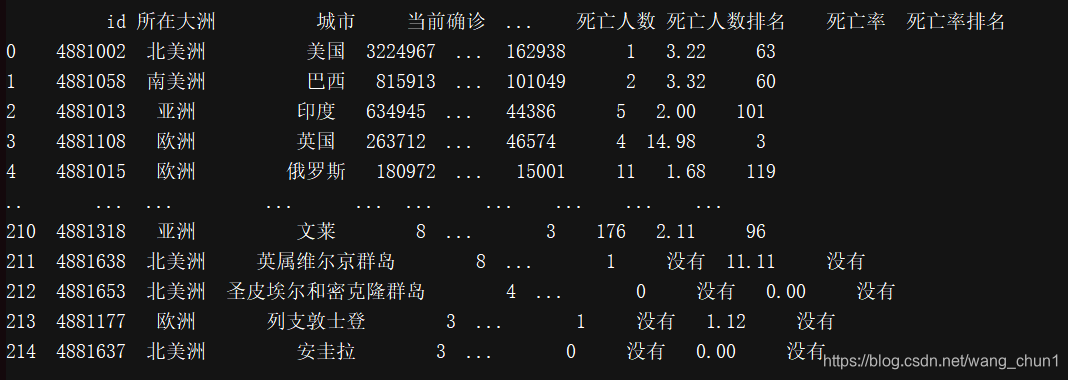
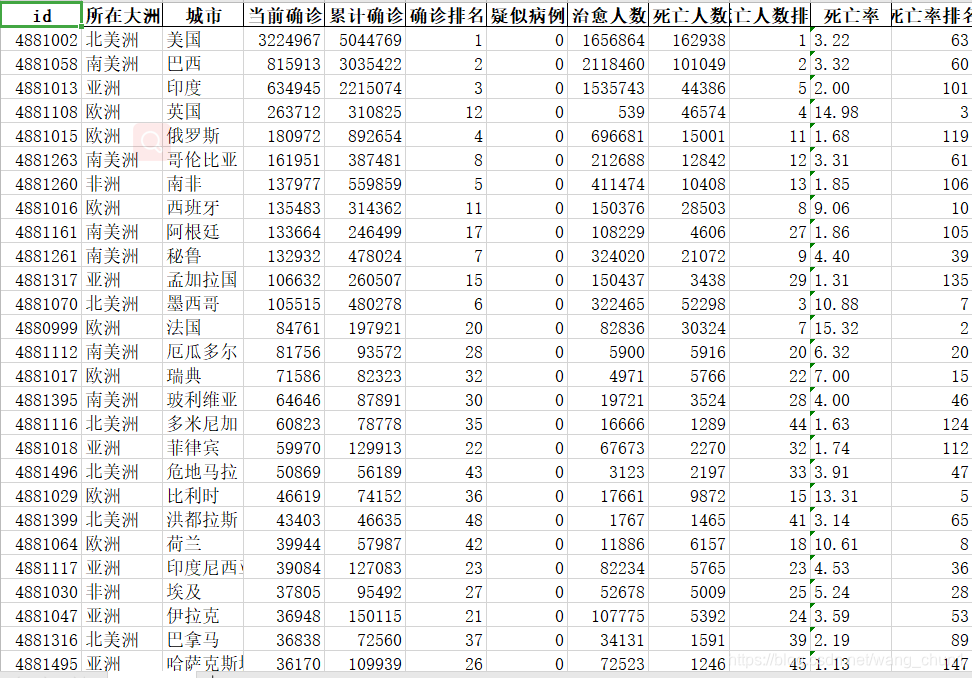
国内疫情数据的爬取:
import requests
import pandas as pd
from bs4 import BeautifulSoup
import re
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
#省级正则表达式
provinceName_re = re.compile(r'"provinceName":"(.*?)",')
provinceShortName_re = re.compile(r'"provinceShortName":"(.*?)",')
currentConfirmedCount_re = re.compile(r'"currentConfirmedCount":(.*?),')
confirmedCount_re = re.compile(r'"confirmedCount":(.*?),')
suspectedCount_re = re.compile(r'"suspectedCount":(.*?),')
curedCount_re = re.compile(r'"curedCount":(.*?),')
deadCount_re = re.compile(r'"deadCount":(.*?),')
comment_re = re.compile(r'"comment":"(.*?)",')
locationId_re = re.compile(r'"locationId":(.*?),')
statisticsData_re = re.compile(r'"statisticsData":"(.*?)",')
cities_re = re.compile(r'"cities":\[\{(.*?)\}\]')
#市级正则表达式
cityName_re = re.compile(r'"cityName":"(.*?)",')
currentConfirmedCount_1_re = re.compile(r'"currentConfirmedCount":(.*?),')
confirmedCount_1_re = re.compile(r'"confirmedCount":(.*?),')
suspectedCount_1_re = re.compile(r'"suspectedCount":(.*?),')
curedCount_1_re = re.compile(r'"curedCount":(.*?),')
deadCount_1_re = re.compile(r'"deadCount":(.*?),')
locationId_1_re = re.compile(r'"locationId":(.*?)\},')
#爬虫爬取数据
datas = requests.get(url,headers = headers)
datas.encoding = 'utf-8'
soup = BeautifulSoup(datas.text,'lxml')
data = soup.find_all('script',{'id':'getAreaStat'})
data = str(data)
data_str = data[54:-23]
#替换字符串内容,避免重复查找
citiess = re.sub(cities_re,'8888',data_str)
#查找省级数据
provinceNames = re.findall(provinceName_re,citiess)
provinceShortNames = re.findall(provinceShortName_re,citiess)
currentConfirmedCounts = re.findall(currentConfirmedCount_re,citiess)
confirmedCounts = re.findall(confirmedCount_re,citiess)
suspectedCounts = re.findall(suspectedCount_re,citiess)
curedCounts = re.findall(curedCount_re,citiess)
deadCounts = re.findall(deadCount_re,citiess)
comments = re.findall(comment_re,citiess)
locationIds = re.findall(locationId_re,citiess)
statisticsDatas = re.findall(statisticsData_re,citiess)
#查找市级数据
citiess_str1 = re.findall(cities_re,data_str)
#将市级列表数据转为字符串,方便正则表达式查找
citiess_str = str(citiess_str1)
cityName = re.findall(cityName_re,citiess_str)
currentConfirmedCount_1 = re.findall(currentConfirmedCount_1_re,citiess_str)
confirmedCount_1 = re.findall(confirmedCount_1_re,citiess_str)
suspectedCount_1 = re.findall(suspectedCount_1_re,citiess_str)
curedCount_1 = re.findall(curedCount_1_re,citiess_str)
deadCount_1 = re.findall(deadCount_1_re,citiess_str)
# 省级数据转换为pandas数组
df = {
'地区代码':pd.Series(locationIds),
'省':pd.Series(provinceNames),
'省区短名':pd.Series(provinceShortNames),
'当前确诊':pd.Series(currentConfirmedCounts),
'累计确诊':pd.Series(confirmedCounts),
'疑似确诊':pd.Series(suspectedCounts),
'治愈人数':pd.Series(curedCounts),
'死亡人数':pd.Series(deadCounts),
'评论':pd.Series(comments),
'统计数据区':pd.Series(statisticsDatas),
}
pds = pd.DataFrame(df)
pds.to_excel('国内疫情统计表1.xlsx',index=True)
获取数据后用Excel进行简单的处理,并和tableau一起将结果绘制成图像。下图是几张成果图:
世界疫情热点地图:
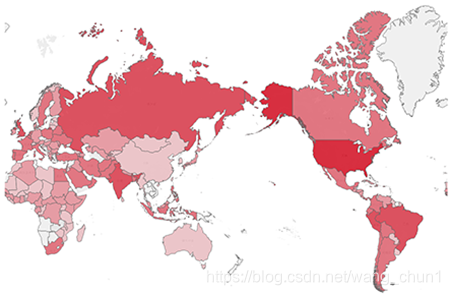
国内疫情热点地图:
将获取处理过的数据可视化以后还差形成报告分析的形式,编写报告的方式很多,不过我选择的是用前端网页的形式呈现出来。这种的方法的优点是:排版的效果更好,更直观,可以自己通过编写代码的形式自己设计想要的排版格式;缺陷是不可打印,难度较大,需要对html和css有一定的基础。数据可在我的个人博客获取,数据的链接如下见路不走个人博客
也有网友给我说能不能获取到历史的的数据,我下载仔细研究了一下,每个省每天都会公布当天的疫情数据,所以只有去爬取每个省每天的公布信息,然后对其挖掘处理便可得到对应省份的历史信息,我重新用java和springboot框架编写爬虫并已经获取了各个省份全部的新冠历史疫情数据,具体的看我的另一篇博文:全国各省新冠肺炎疫情的历史数据















 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











