1.2 访问目标页面
import requests
# 定义头文件
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}
# 定义要访问的地址
url = "http://coviddata.idatascience.cn/index"
# 使用requests发起请求
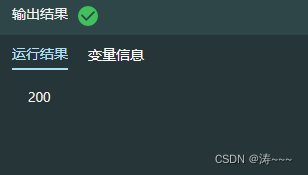
r = requests.get(url, headers=headers)
# 查看请求状态
print(r.status_code)
1.3 获取全国当日数据
import re
import pandas as pd
text = r.text.replace('\n','')#替换换行符
pattern = r'<table .*?>.*?</table>'
table = re.findall(pattern, text)[0] # 定位到国内表格
# 列名
cols = re.findall(r'<th>(.*?)</th>', table)#表头
# 提取表格所有行
rows = re.findall(r'<tr>(.*?)</tr>', table)
data=[]
for row in rows :
data.append(re.findall(r'<td>(.*?)</td>', row )) # 遍历表格每一行内容
# 将结果存为DataFrame
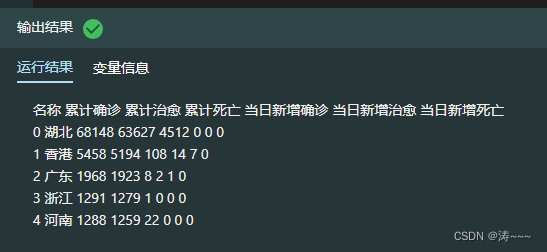
today_province= pd.DataFrame(data, columns=cols)
today_province.head()
1.4 访问中国整体历史数据
import requests
# 定义请求头
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
#访问URL
url = 'http://coviddata.idatascience.cn/china-history'
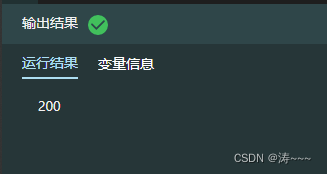
r = requests.get(url, headers=headers)
#查看访问状态码
print(r.status_code)
1.5 获取中国整体历史数据
import pandas as pd
#响应内容为r
data = r.json()
#存储为DataFrame
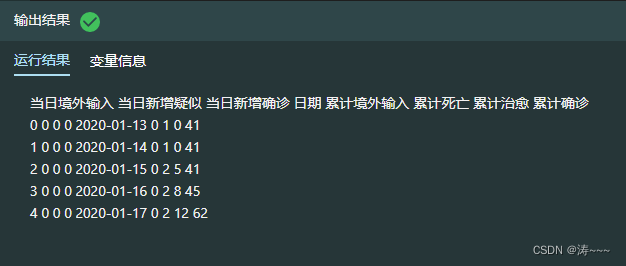
alltime_china = pd.DataFrame(data)
print(alltime_china.head())
1.6 获取境外输入当日数据
import requests
import pandas as pd
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
#访问URL
url = 'http://coviddata.idatascience.cn/today-input'
r = requests.get(url, headers=headers)
#转换成json格式并存为DataFrame
data = r.json()
today_input = pd.DataFrame(data)
print(today_input.head())

1.7 获取全球当日数据
from lxml import etree
import pandas as pd
#转换成DOM树
tree = etree.HTML(r.content)
# 列名
cols = tree.xpath('//*[@id="today_world"]/thead/tr/th/text()')
data = []
for row in tree.xpath('//table[@id="today_world"]/tbody/tr'):
#表格的每一行内容
data.append(row.xpath('td/text()'))
#存为DataFrame
today_world = pd.DataFrame(data, columns=cols)
today_world.head()
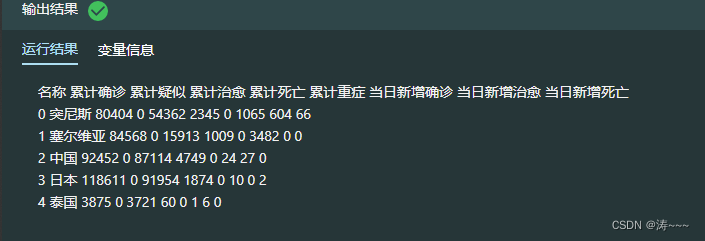
1.8 获取美国当日数据
from bs4 import BeautifulSoup
import pandas as pd
#使用lxml解析DOM树
soup = BeautifulSoup(r.content, 'lxml')
#定位到表格
table = soup.find('table', id='today_usa')
#列名
cols = table.find('thead').text.split('\n') #获取表头
cols = [x for x in cols if x!=''] #去除多余的空格
today_state = []
data = table.find('tbody').find_all('tr')#获取所有行
for row in data: #表格的每一行内容
today_state.append(row.text.split('\n')[1:-1])
today_state = pd.DataFrame(today_state, columns=cols)#存为DataFrame
today_state.head()








 本文通过Python爬虫技术,详细介绍了如何从idatascience.cn网站获取全国每日、中国整体历史、境外输入、全球当日及美国当日的COVID-19数据,并以pandas DataFrame形式进行处理和展示。涵盖了HTTP请求、正则表达式、DOM解析等技术应用。
本文通过Python爬虫技术,详细介绍了如何从idatascience.cn网站获取全国每日、中国整体历史、境外输入、全球当日及美国当日的COVID-19数据,并以pandas DataFrame形式进行处理和展示。涵盖了HTTP请求、正则表达式、DOM解析等技术应用。

















 7316
7316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









