







Glenn Jocher(Ultralytics团队)于2020年6月发布了YOLOv5源码,将其作为YOLO系列的一个新版本,尽管它并不直接由原始YOLO作者开发,并且YOLOv5至今没有发表过正式的论文,但受到了广泛的关注和使用,相较于YOLOv4更快更准。本文对YOLOv5中改进之处作了详细分析,比较重点的有Backbone、目标框回归预测、正负样本匹配。
参考笔记:
YOLOv5深度解析:网络结构、数据增强与训练策略-CSDN博客
【YOLO系列】YOLOv5超详细解读(源码详解+入门实践+改进)-CSDN博客
yolov5-v6.0详细解读_yolov5 6.0-CSDN博客
学习视频:
yolov5 |损失函数 | 正样本匹配_哔哩哔哩_bilibili
目录
---------------------------------------------------------往期内容------------------------------------------------------------
【YOLO系列】IoU、GIoU、DIoU、CIoU详细解析
1.YOLOv5版本介绍
YOLOv5的特点:适合移动端部署、模型小、速度快
YOLOv5目前有YOLOv5s、YOLOv5m、YoLOv5l、YOLOv5x四个版本(YOLOv5n的yaml文文件官方没有提供)。这四个版本在网络结构上是没有区别的,唯一的区别就是网络的宽度、深度不一样,在这4个版本的配置文件里面是通过设置不同的depth_multiple和width_multiple参数来控制网络的大小。其中depth_multiple控制模型的深度(C3模块中的ResUnit个数),width_multiple控制模型的宽度(卷积核数量)。通过设置这两个不同参数,不同YOLOv5版本模型复杂度如下图:
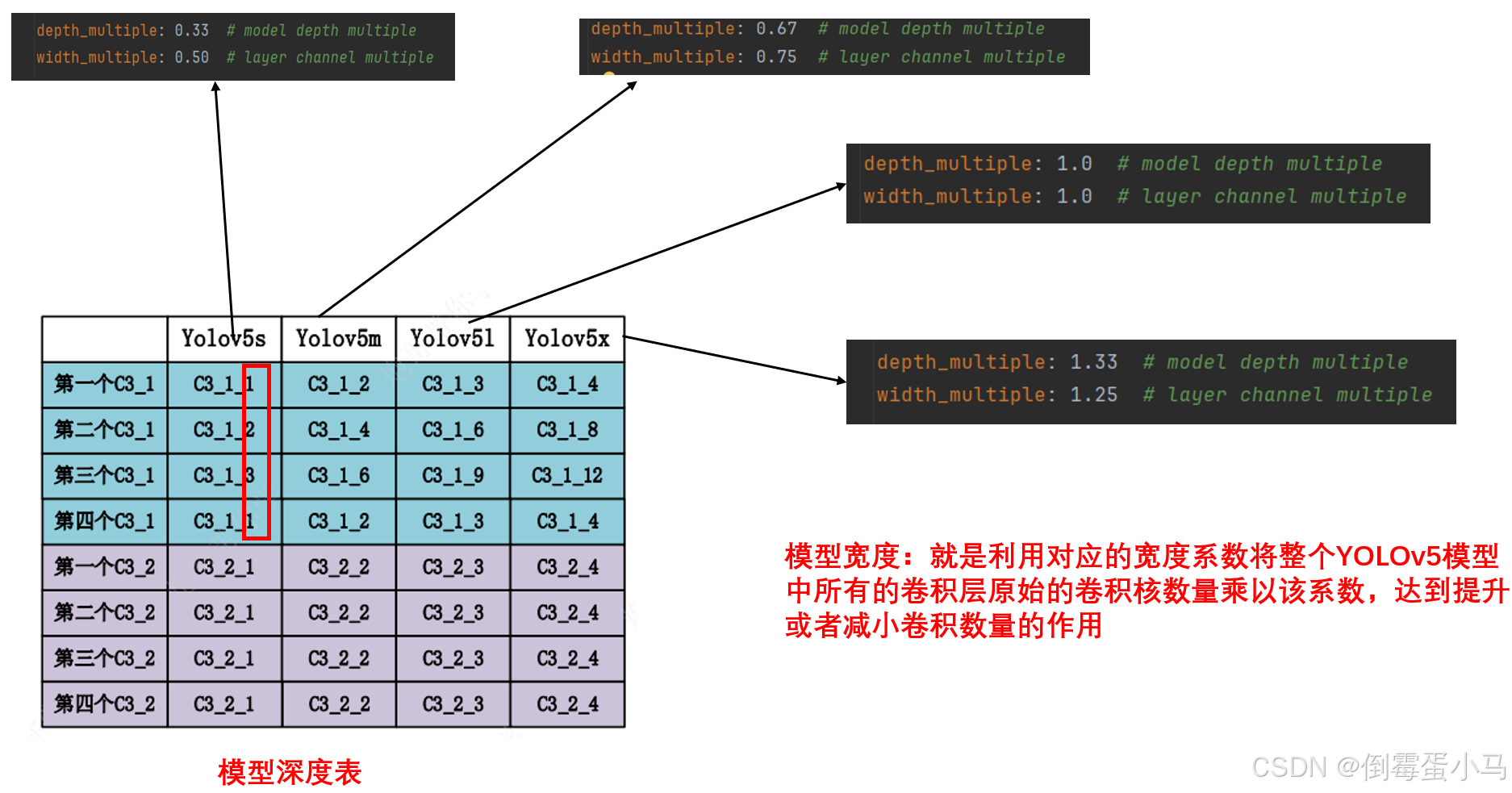
不同YOLOv5变种的模型深度、宽度
注意:基准版本是YOLOv5l,所以YOLOv5l的depth_multiple和width_multiple都设置为1
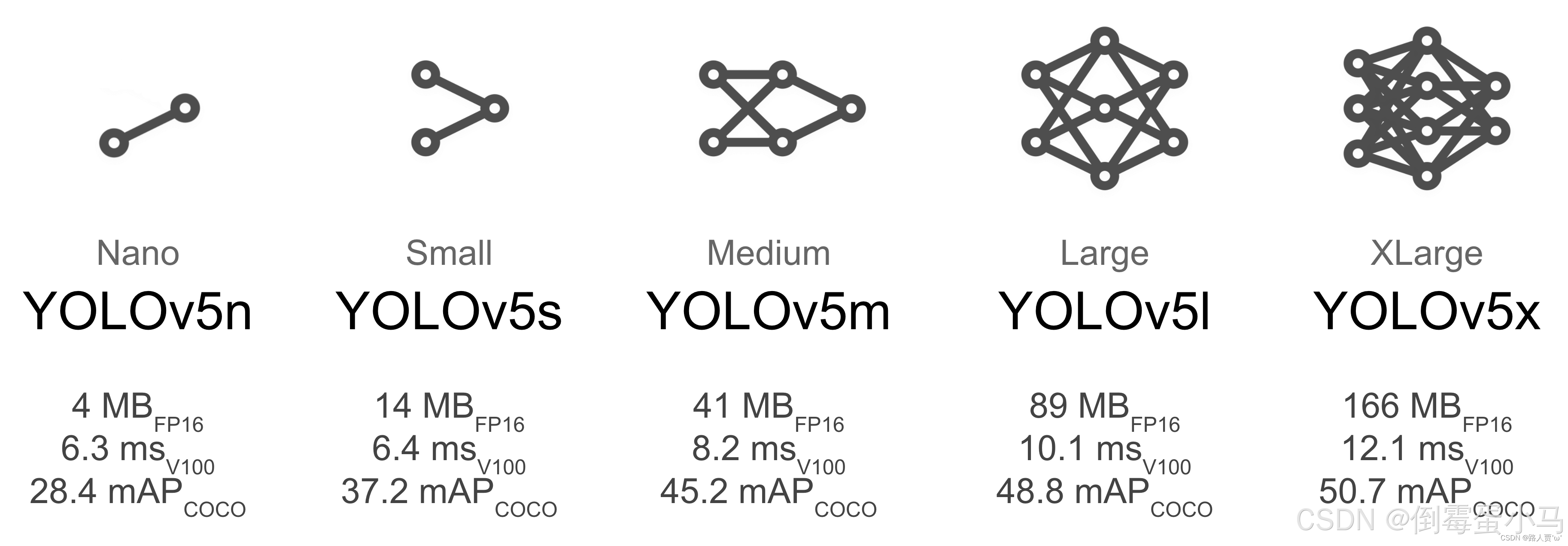
不同YOLOv5变种的性能
本文讲的YOLOv5版本是YOLOv5l
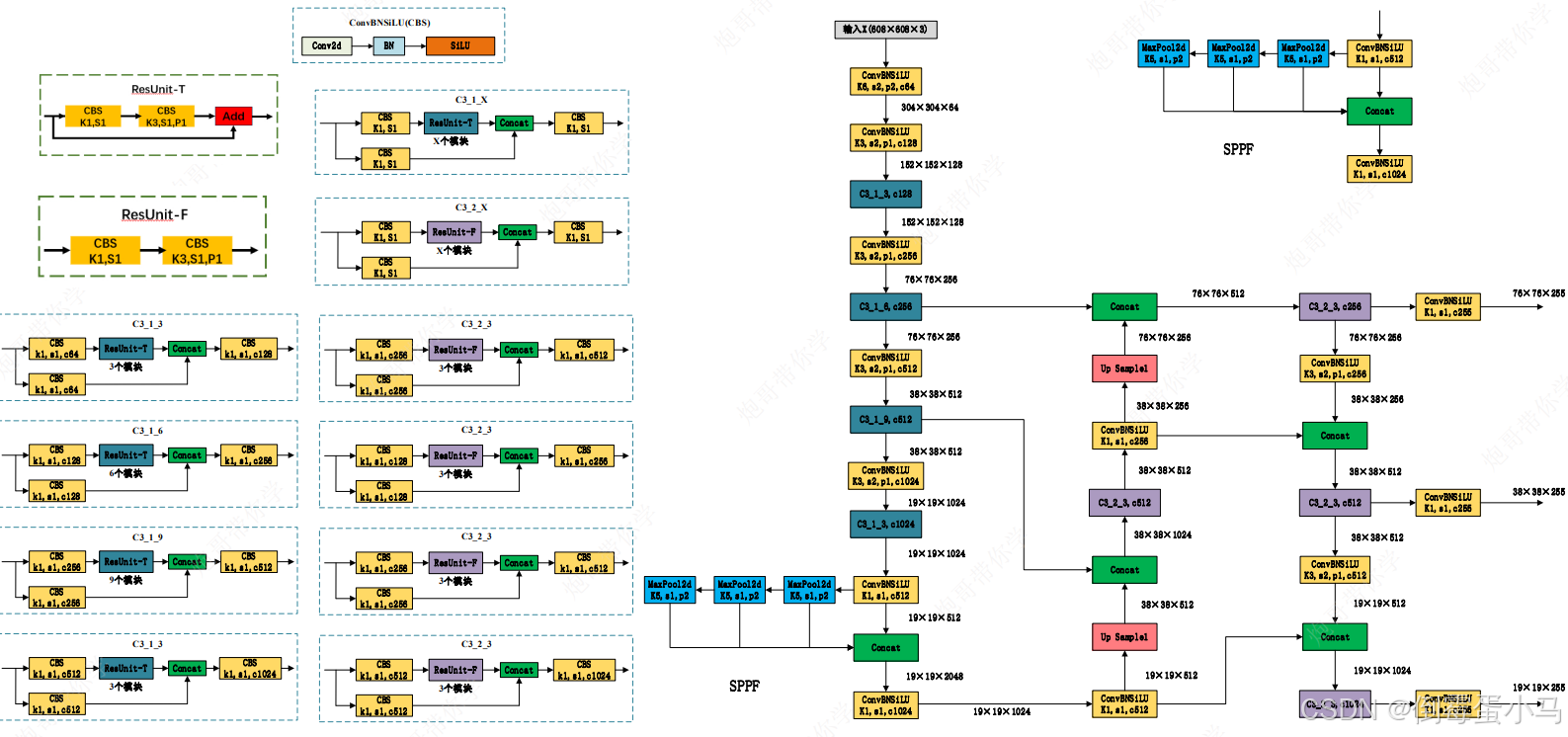
2.YOLOv5网络结构
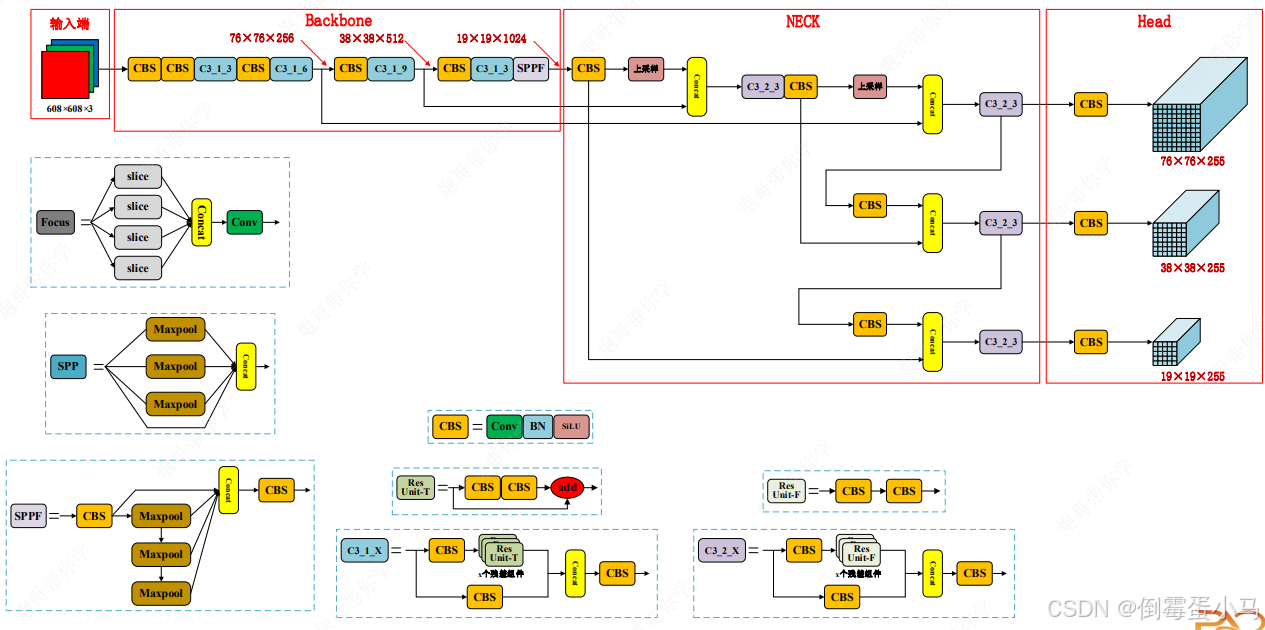
YOLOv5网络结构图
YOLOv5网络参数图
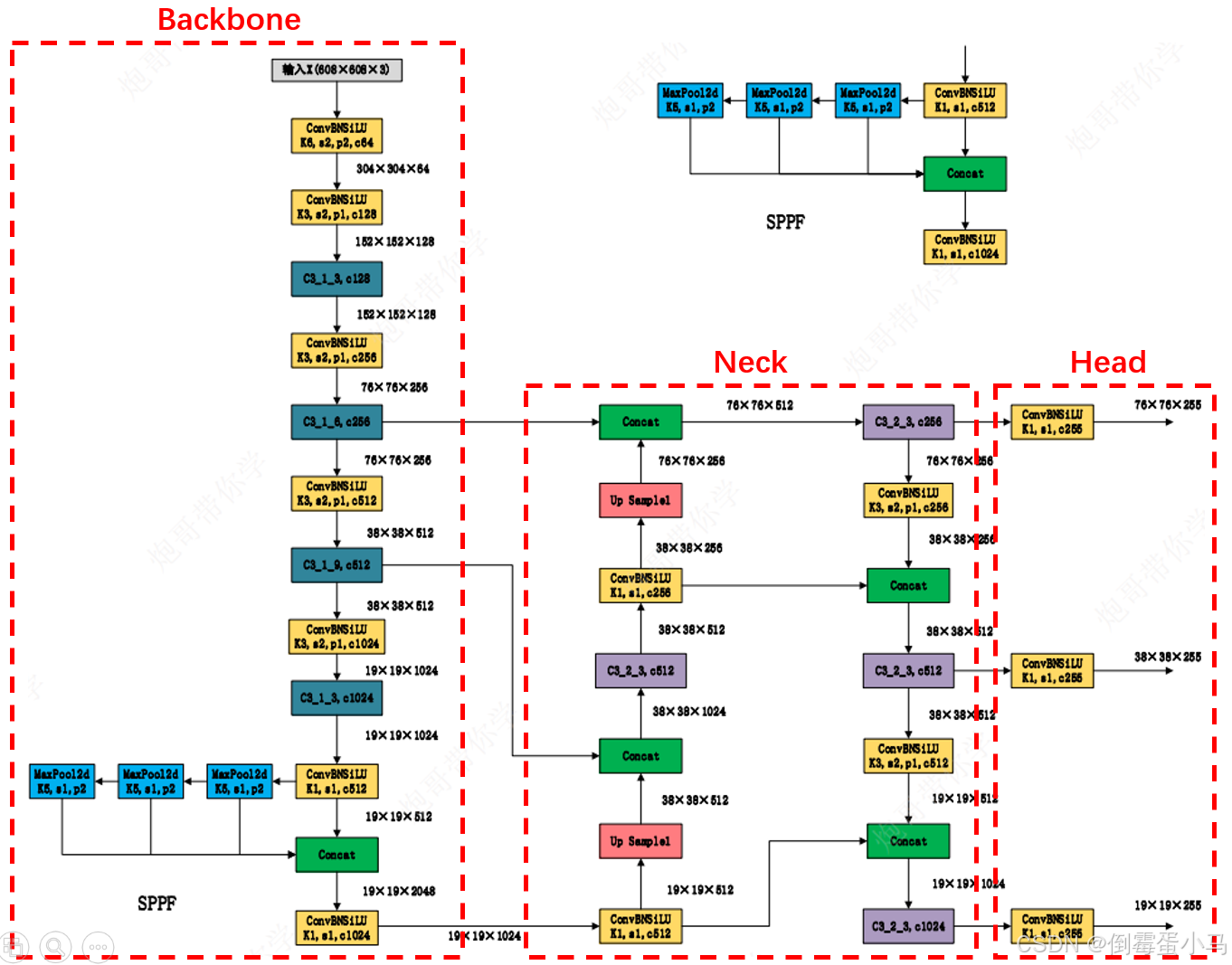
YOLOv5网络参数图中Backbone、Neck、Head划分
卷积层参数解释:K1:kernel_size=1,S1:stride=1,P1:padding=1,c1024:out_channel=1024
注意:有些卷积层未指明pading等于多少的,通常都是在源码中利用给定的kernle_size,stride自动计算出使得输出前后特征图尺寸不变的padding
2.1 Backbone
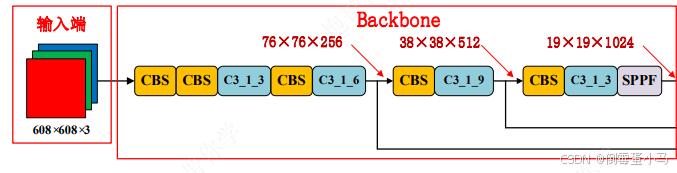
YOLOv5网络结构图中的Backbone
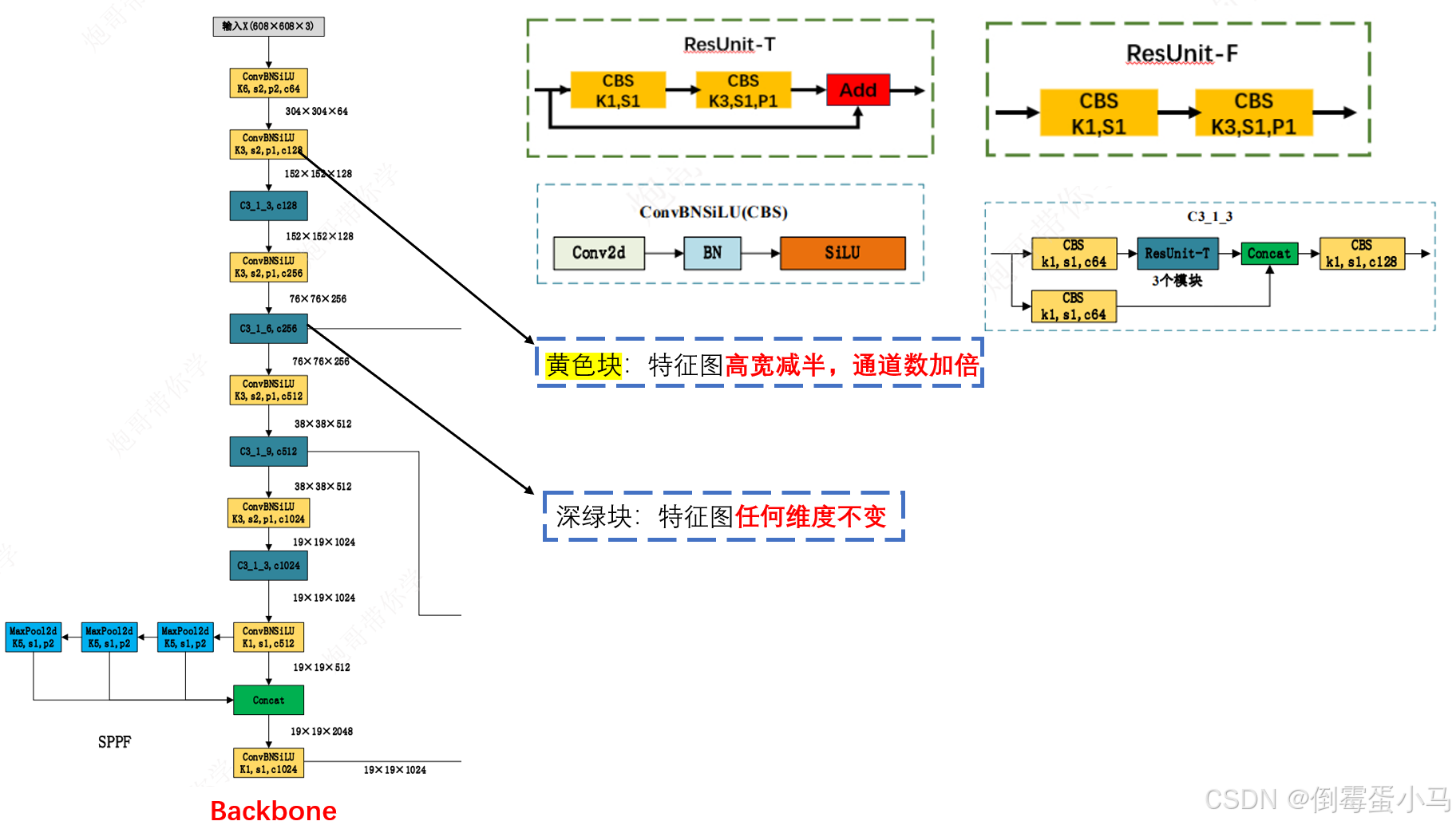
YOLOv5网络参数图中的Backbone
2.1.1 Focus
在YOLOv5的早些代码版本Backbone中是有Focus模块的,但随着代码的更新,后续移除掉了,该模块的所在的位置如下图:
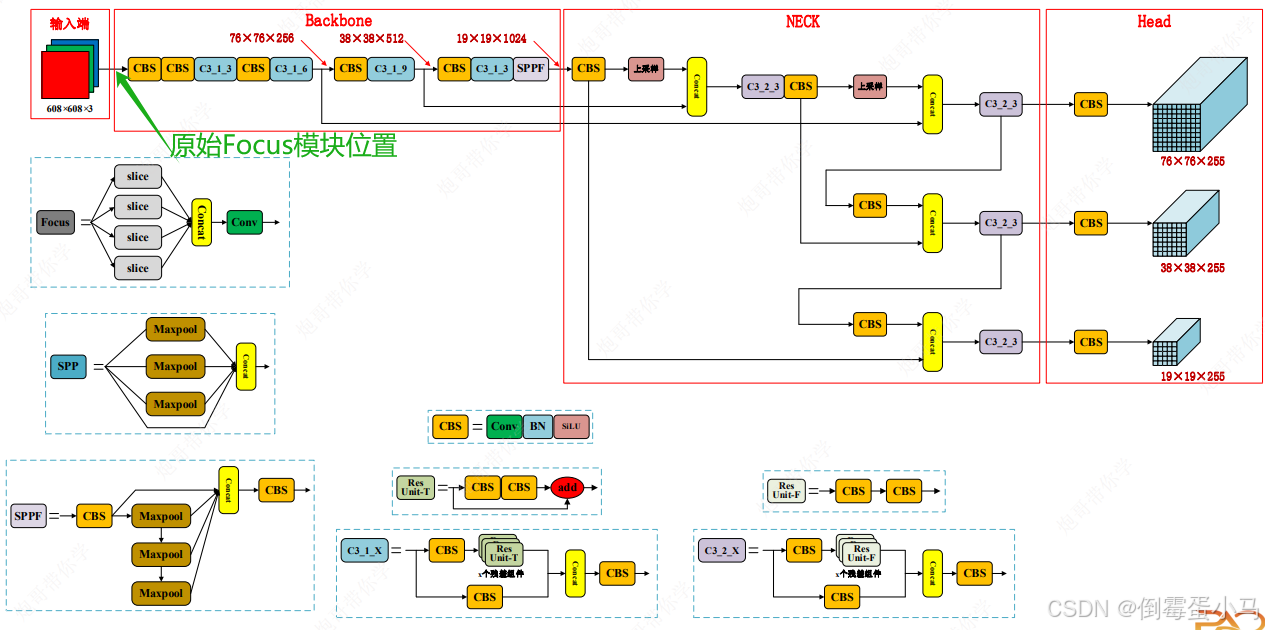
Focus模块所在位置
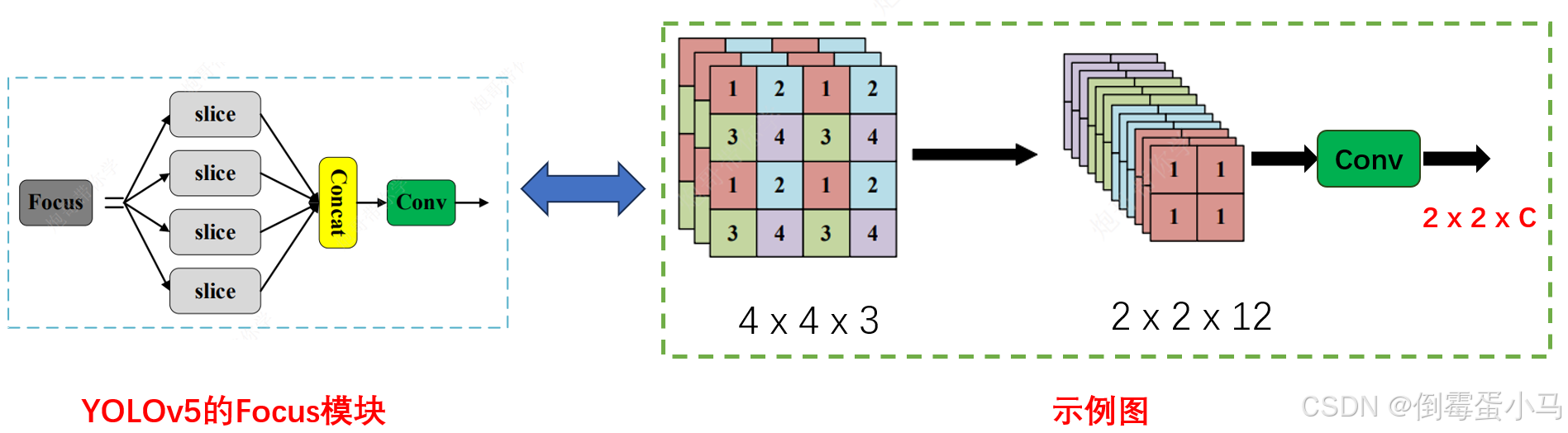
Focus模块结构
Focus模块在YOLOv5中是图片进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每个通道每隔一个像素拿到一个值,类似于邻近下采样,然后如上图右边例子中在每个通道将相同颜色的像素值拼在一起,接着将所有通道作Concat,至此输入通道扩充了4倍,特征图尺寸缩小一半,最后将得到的新图片再经过卷积操作即可
以YOLOv5s为例,原始的640 x 640 x 3的图像输入Focus结构,先变成320 x 320 x 12的特征图,再经过一次卷积操作,最终变成320 x 320 x 32的特征图
作用:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









