






ResNet50图像分类
ResNet网络介绍
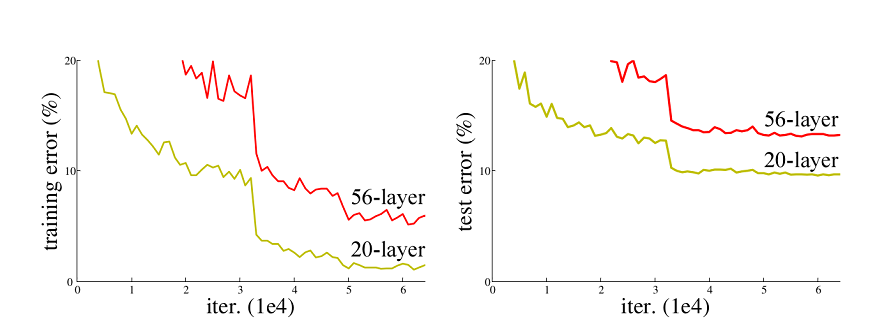
ResNet50网络是2015年由微软实验室的何恺明提出,获得ILSVRC2015图像分类竞赛第一名。在ResNet网络提出之前,传统的卷积神经网络都是将一系列的卷积层和池化层堆叠得到的,但当网络堆叠到一定深度时,就会出现退化问题。下图是在CIFAR-10数据集上使用56层网络与20层网络训练误差和测试误差图,由图中数据可以看出,56层网络比20层网络训练误差和测试误差更大,随着网络的加深,其误差并没有如预想的一样减小。
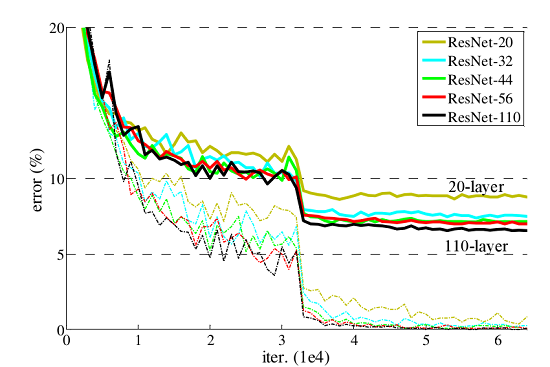
ResNet网络提出了残差网络结构(Residual Network)来减轻退化问题,使用ResNet网络可以实现搭建较深的网络结构(突破1000层)。论文中使用ResNet网络在CIFAR-10数据集上的训练误差与测试误差图如下图所示,图中虚线表示训练误差,实线表示测试误差。由图中数据可以看出,ResNet网络层数越深,其训练误差和测试误差越小。
了解ResNet网络更多详细内容,参见ResNet论文。
数据集准备与加载
CIFAR-10数据集共有60000张32*32的彩色图像,分为10个类别,每类有6000张图,数据集一共有50000张训练图片和10000张评估图片。首先,如下示例使用download接口下载并解压,目前仅支持解析二进制版本的CIFAR-10文件(CIFAR-10 binary version)。
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 查看当前 mindspore 版本
!pip show mindspore
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
download(url, "./datasets-cifar10-bin", kind="tar.gz", replace=True)
'./datasets-cifar10-bin'
下载后的数据集目录结构如下:
datasets-cifar10-bin/cifar-10-batches-bin
├── batches.meta.text
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
├── data_batch_5.bin
├── readme.html
└── test_batch.bin
然后,使用mindspore.dataset.Cifar10Dataset接口来加载数据集,并进行相关图像增强操作。
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore import dtype as mstype
data_dir = "./datasets-cifar10-bin/cifar-10-batches-bin" # 数据集根目录
batch_size = 256 # 批量大小
image_size = 32 # 训练图像空间大小
workers = 4 # 并行线程个数
num_classes = 10 # 分类数量
def create_dataset_cifar10(dataset_dir, usage, resize, batch_size, workers):
data_set = ds.Cifar10Dataset(dataset_dir=dataset_dir,
usage=usage,
num_parallel_workers=workers,
shuffle=True)
trans = []
if usage == "train":
trans += [
vision.RandomCrop((32, 32), (4, 4, 4, 4)),
vision.RandomHorizontalFlip(prob=0.5)
]
trans += [
vision.Resize(resize),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
vision.HWC2CHW()
]
target_trans = transforms.TypeCast(mstype.int32)
# 数据映射操作
data_set = data_set.map(operations=trans,
input_columns='image',
num_parallel_workers=workers)
data_set = data_set.map(operations=target_trans,
input_columns='label',
num_parallel_workers=workers)
# 批量操作
data_set = data_set.batch(batch_size)
return data_set
# 获取处理后的训练与测试数据集
dataset_train = create_dataset_cifar10(dataset_dir=data_dir,
usage="train",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_train = dataset_train.get_dataset_size()
dataset_val = create_dataset_cifar10(dataset_dir=data_dir,
usage="test",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_val = dataset_val.get_dataset_size()
对CIFAR-10训练数据集进行可视化。
import matplotlib.pyplot as plt
import numpy as np
data_iter = next(dataset_train.create_dict_iterator())
images = data_iter["image"].asnumpy()
labels = data_iter["label"].asnumpy()
print(f"Image shape: {images.shape}, Label shape: {labels.shape}")
# 训练数据集中,前六张图片所对应的标签
print(f"Labels: {labels[:6]}")
classes = []
with open(data_dir + "/batches.meta.txt", "r") as f:
for line in f:
line = line.rstrip()
if line:
classes.append(line)
# 训练数据集的前六张图片
plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
image_trans = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
image_trans = std * image_trans + mean
image_trans = np.clip(image_trans, 0, 1)
plt.title(f"{classes[labels[i]]}")
plt.imshow(image_trans)
plt.axis("off")
plt.show()
Image shape: (256, 3, 32, 32), Label shape: (256,)
Labels: [3 2 7 6 0 4]

网络构建部分下节进行
2024-07-08 15:12:02 Mindstorm















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









