







背景
提供免费算力支持,有交流群有值班教师答疑的华为昇思训练营进入第二十三天了。
今天是第二十三天,从第十天开始,进入了应用实战阶段,前九天都是基础入门阶段,具体的学习内容可以看链接
基础学习部分
昇思25天学习打卡营第一天|快速入门
昇思25天学习打卡营第二天|张量 Tensor
昇思25天学习打卡营第三天|数据集Dataset
昇思25天学习打卡营第四天|数据变换Transforms
昇思25天学习打卡营第五天|网络构建
昇思25天学习打卡营第六天|函数式自动微分
昇思25天学习打卡营第七天|模型训练
昇思25天学习打卡营第八天|保存与加载
昇思25天学习打卡营第九天|使用静态图加速
应用实践部分
昇思25天学习打卡营第十天|CycleGAN图像风格迁移互换
昇思25天学习打卡营第十一天|DCGAN生成漫画头像
昇思25天学习打卡营第十二天|Diffusion扩散模型
昇思25天学习打卡营第十三天|GAN图像生成
昇思25天学习打卡营第十四天|Pix2Pix实现图像转换
昇思25天学习打卡营第十五天|基于 MindSpore 实现 BERT 对话情绪识别
昇思25天学习打卡营第十六天|基于MindSpore的GPT2文本摘要
昇思25天学习打卡营第十七天|文本解码原理–以MindNLP为例
昇思25天学习打卡营第十八天|基于MindNLP+MusicGen生成自己的个性化音乐
昇思25天学习打卡营第十九天|K近邻算法实现红酒聚类
昇思25天学习打卡营第二十天|基于MobileNetv2的垃圾分类
昇思25天学习打卡营第二十一天|FCN图像语义分割
昇思25天学习打卡营第二十二天|ResNet50迁移学习
学习内容
图像分类是最基础的计算机视觉应用,属于有监督学习类别,如给定一张图像(猫、狗、飞机、汽车等等),判断图像所属的类别。本章将介绍使用ResNet50网络对CIFAR-10数据集进行分类。
ResNet网络介绍
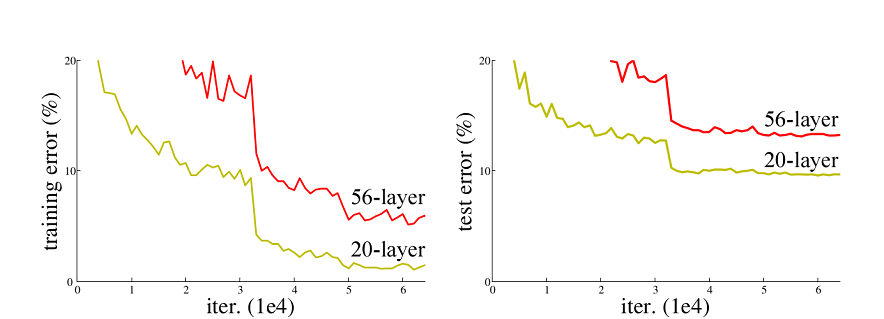
ResNet50网络是2015年由微软实验室的何恺明提出,获得ILSVRC2015图像分类竞赛第一名。在ResNet网络提出之前,传统的卷积神经网络都是将一系列的卷积层和池化层堆叠得到的,但当网络堆叠到一定深度时,就会出现退化问题。下图是在CIFAR-10数据集上使用56层网络与20层网络训练误差和测试误差图,由图中数据可以看出,56层网络比20层网络训练误差和测试误差更大,随着网络的加深,其误差并没有如预想的一样减小。
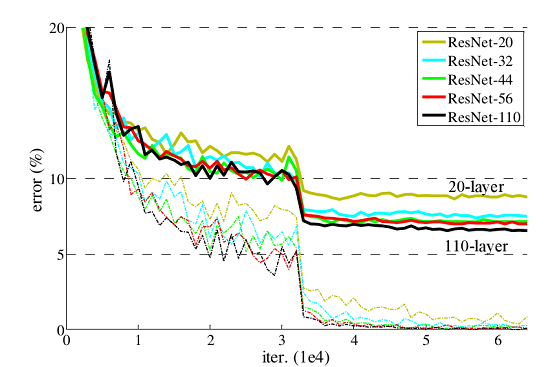
ResNet网络提出了残差网络结构(Residual Network)来减轻退化问题,使用ResNet网络可以实现搭建较深的网络结构(突破1000层)。论文中使用ResNet网络在CIFAR-10数据集上的训练误差与测试误差图如下图所示,图中虚线表示训练误差,实线表示测试误差。由图中数据可以看出,ResNet网络层数越深,其训练误差和测试误差越小。
了解ResNet网络更多详细内容,参见ResNet论文。
数据集准备与加载
CIFAR-10数据集共有60000张32*32的彩色图像,分为10个类别,每类有6000张图,数据集一共有50000张训练图片和10000张评估图片。首先,如下示例使用download接口下载并解压,目前仅支持解析二进制版本的CIFAR-10文件(CIFAR-10 binary version)。
下载后的数据集目录结构如下:
datasets-cifar10-bin/cifar-10-batches-bin
├── batches.meta.text
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
├── data_batch_5.bin
├── readme.html
└── test_batch.bin
然后,使用mindspore.dataset.Cifar10Dataset接口来加载数据集,并进行相关图像增强操作。
构建网络
残差网络结构(Residual Network)是ResNet网络的主要亮点,ResNet使用残差网络结构后可有效地减轻退化问题,实现更深的网络结构设计,提高网络的训练精度。本节首先讲述如何构建残差网络结构,然后通过堆叠残差网络来构建ResNet50网络。
构建残差网络结构
残差网络结构图如下图所示,残差网络由两个分支构成:一个主分支,一个shortcuts(图中弧线表示)。主分支通过堆叠一系列的卷积操作得到,shotcuts从输入直接到输出,主分支输出的特征矩阵 F ( x ) F(x) F(x)加上shortcuts输出的特征矩阵 x x x得到 F ( x ) + x F(x)+x F(x)+x,通过Relu激活函数后即为残差网络最后的输出。
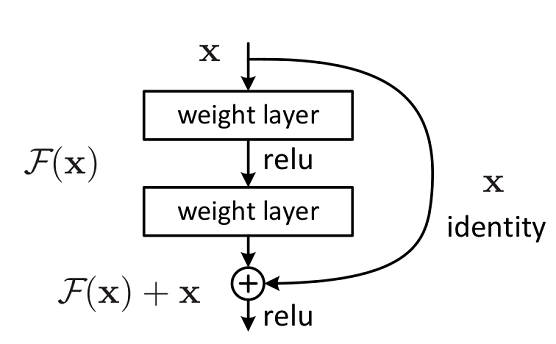
残差网络结构主要由两种,一种是Building Block,适用于较浅的ResNet网络,如ResNet18和ResNet34;另一种是Bottleneck,适用于层数较深的ResNet网络,如ResNet50、ResNet101和ResNet152。
Building Block
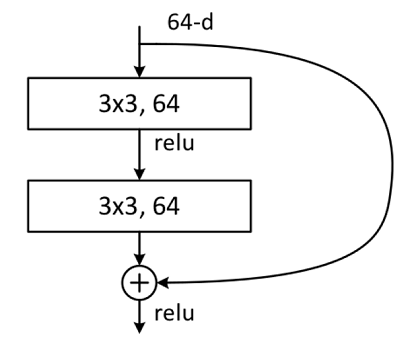
Building Block结构图如下图所示,主分支有两层卷积网络结构:
- 主分支第一层网络以输入channel为64为例,首先通过一个 3 × 3 3\times3 3×3的卷积层,然后通过Batch Normalization层,最后通过Relu激活函数层,输出channel为64;
- 主分支第二层网络的输入channel为64,首先通过一个 3 × 3 3\times3 3×3的卷积层,然后通过Batch Normalization层,输出channel为64。
最后将主分支输出的特征矩阵与shortcuts输出的特征矩阵相加,通过Relu激活函数即为Building Block最后的输出。
主分支与shortcuts输出的特征矩阵相加时,需要保证主分支与shortcuts输出的特征矩阵shape相同。如果主分支与shortcuts输出的特征矩阵shape不相同,如输出channel是输入channel的一倍时,shortcuts上需要使用数量与输出channel相等,大小为
1
×
1
1\times1
1×1的卷积核进行卷积操作;若输出的图像较输入图像缩小一倍,则要设置shortcuts中卷积操作中的stride为2,主分支第一层卷积操作的stride也需设置为2。
Bottleneck
Bottleneck结构图如下图所示,在输入相同的情况下Bottleneck结构相对Building Block结构的参数数量更少,更适合层数较深的网络,ResNet50使用的残差结构就是Bottleneck。该结构的主分支有三层卷积结构,分别为 1 × 1 1\times1 1×1的卷积层、 3 × 3 3\times3 3×3卷积层和 1 × 1 1\times1 1×1的卷积层,其中 1 × 1 1\times1 1×1的卷积层分别起降维和升维的作用。
- 主分支第一层网络以输入channel为256为例,首先通过数量为64,大小为 1 × 1 1\times1 1×1的卷积核进行降维,然后通过Batch Normalization层,最后通过Relu激活函数层,其输出channel为64;
- 主分支第二层网络通过数量为64,大小为 3 × 3 3\times3 3×3的卷积核提取特征,然后通过Batch Normalization层,最后通过Relu激活函数层,其输出channel为64;
- 主分支第三层通过数量为256,大小 1 × 1 1\times1 1×1的卷积核进行升维,然后通过Batch Normalization层,其输出channel为256。
最后将主分支输出的特征矩阵与shortcuts输出的特征矩阵相加,通过Relu激活函数即为Bottleneck最后的输出。
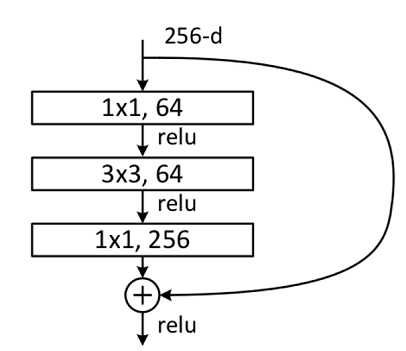
主分支与shortcuts输出的特征矩阵相加时,需要保证主分支与shortcuts输出的特征矩阵shape相同。如果主分支与shortcuts输出的特征矩阵shape不相同,如输出channel是输入channel的一倍时,shortcuts上需要使用数量与输出channel相等,大小为
1
×
1
1\times1
1×1的卷积核进行卷积操作;若输出的图像较输入图像缩小一倍,则要设置shortcuts中卷积操作中的stride为2,主分支第二层卷积操作的stride也需设置为2。
如下代码定义ResidualBlock类实现Bottleneck结构。
构建ResNet50网络
ResNet网络层结构如下图所示,以输入彩色图像 224 × 224 224\times224 224×224为例,首先通过数量64,卷积核大小为 7 × 7 7\times7 7×7,stride为2的卷积层conv1,该层输出图片大小为 112 × 112 112\times112 112×112,输出channel为64;然后通过一个 3 × 3 3\times3 3×3的最大下采样池化层,该层输出图片大小为 56 × 56 56\times56 56×56,输出channel为64;再堆叠4个残差网络块(conv2_x、conv3_x、conv4_x和conv5_x),此时输出图片大小为 7 × 7 7\times7 7×7,输出channel为2048;最后通过一个平均池化层、全连接层和softmax,得到分类概率。
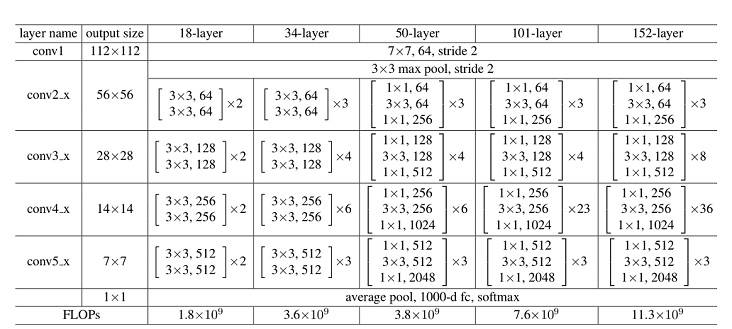
对于每个残差网络块,以ResNet50网络中的conv2_x为例,其由3个Bottleneck结构堆叠而成,每个Bottleneck输入的channel为64,输出channel为256。
如下示例定义make_layer实现残差块的构建,其参数如下所示:
last_out_channel:上一个残差网络输出的通道数。block:残差网络的类别,分别为ResidualBlockBase和ResidualBlock。channel:残差网络输入的通道数。block_nums:残差网络块堆叠的个数。stride:卷积移动的步幅。
ResNet50网络共有5个卷积结构,一个平均池化层,一个全连接层,以CIFAR-10数据集为例:
- conv1:输入图片大小为 32 × 32 32\times32 32×32,输入channel为3。首先经过一个卷积核数量为64,卷积核大小为 7 × 7 7\times7 7×7,stride为2的卷积层;然后通过一个Batch Normalization层;最后通过Reul激活函数。该层输出feature map大小为 16 × 16 16\times16 16×16,输出channel为64。
- conv2_x:输入feature map大小为 16 × 16 16\times16 16×16,输入channel为64。首先经过一个卷积核大小为 3 × 3 3\times3 3×3,stride为2的最大下采样池化操作;然后堆叠3个 [ 1 × 1 , 64 ; 3 × 3 , 64 ; 1 × 1 , 256 ] [1\times1,64;3\times3,64;1\times1,256] [1×1,64;3×3,64;1×1,256]结构的Bottleneck。该层输出feature map大小为 8 × 8 8\times8 8×8,输出channel为256。
- conv3_x:输入feature map大小为 8 × 8 8\times8 8×8,输入channel为256。该层堆叠4个[1×1,128;3×3,128;1×1,512]结构的Bottleneck。该层输出feature map大小为 4 × 4 4\times4 4×4,输出channel为512。
- conv4_x:输入feature map大小为 4 × 4 4\times4 4×4,输入channel为512。该层堆叠6个[1×1,256;3×3,256;1×1,1024]结构的Bottleneck。该层输出feature map大小为 2 × 2 2\times2 2×2,输出channel为1024。
- conv5_x:输入feature map大小为 2 × 2 2\times2 2×2,输入channel为1024。该层堆叠3个[1×1,512;3×3,512;1×1,2048]结构的Bottleneck。该层输出feature map大小为 1 × 1 1\times1 1×1,输出channel为2048。
- average pool & fc:输入channel为2048,输出channel为分类的类别数。
如下示例代码实现ResNet50模型的构建,通过用调函数resnet50即可构建ResNet50模型,函数resnet50参数如下:
num_classes:分类的类别数,默认类别数为1000。pretrained:下载对应的训练模型,并加载预训练模型中的参数到网络中。
模型训练与评估
本节使用ResNet50预训练模型进行微调。调用resnet50构造ResNet50模型,并设置pretrained参数为True,将会自动下载ResNet50预训练模型,并加载预训练模型中的参数到网络中。然后定义优化器和损失函数,逐个epoch打印训练的损失值和评估精度,并保存评估精度最高的ckpt文件(resnet50-best.ckpt)到当前路径的./BestCheckPoint下。
由于预训练模型全连接层(fc)的输出大小(对应参数num_classes)为1000, 为了成功加载预训练权重,我们将模型的全连接输出大小设置为默认的1000。CIFAR10数据集共有10个分类,在使用该数据集进行训练时,需要将加载好预训练权重的模型全连接层输出大小重置为10。
此处我们展示了5个epochs的训练过程,如果想要达到理想的训练效果,建议训练80个epochs。
可视化模型预测
定义visualize_model函数,使用上述验证精度最高的模型对CIFAR-10测试数据集进行预测,并将预测结果可视化。若预测字体颜色为蓝色表示为预测正确,预测字体颜色为红色则表示预测错误。
由上面的结果可知,5个epochs下模型在验证数据集的预测准确率在70%左右,即一般情况下,6张图片中会有2张预测失败。如果想要达到理想的训练效果,建议训练80个epochs。

















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











