









目录
java.net.ConnectException: 拒绝连接
IPv4 forwarding is disabled. Networking will not work
driver failed programming external connectivity on endpoint
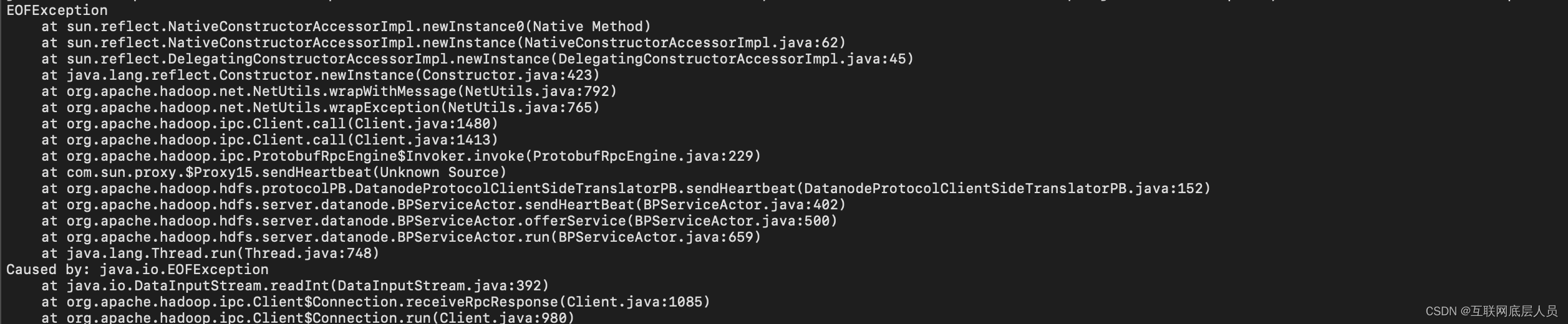
在使用输入输出流时,尤其是在HDFS上面是以分块存储的,在对于块操作时,往往会因为最后一个块不足指定大小而IO流越界,这时候最佳方法就是在程序中做异常处理 ,try catch。

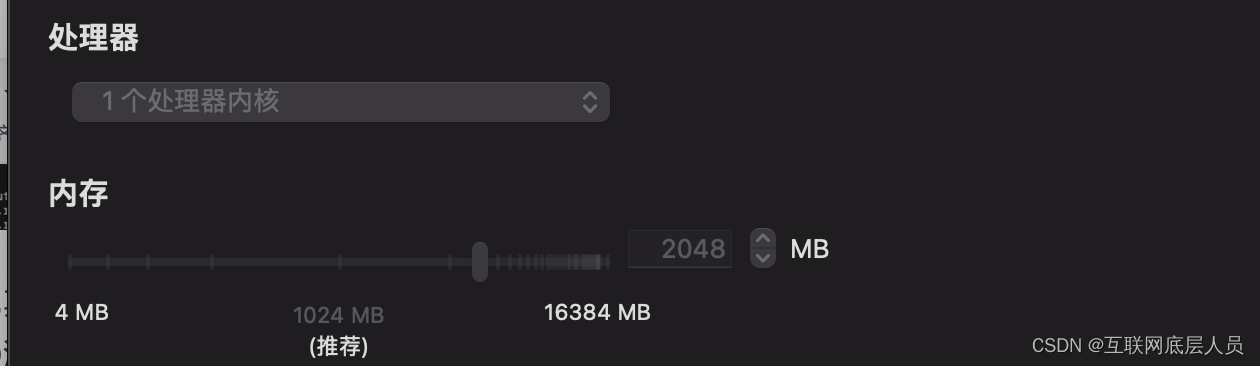
在日志中发现这个问题,首先要解决的就是找出现这个错误的之前的第一个错误,首先需要说明的就是很多问题都会导致出现这个错误,比如说当你的CPU高负荷时,当你的内存溢出,当你的系统出现死锁,或者网络带宽拥挤等等,但是一般出现这个问题都是CPU高负荷,这时候有两种做法,第一就是减少线程,进程数,第二就是增加CPU处理器。
vi /etc/security/limits.d/90-nproc.conf* soft nproc 1024
root soft nproc unlimited
会发现root用户在线程数是不受限制,只需改为1024即可。
如果你是在Mapreduce程序中,可以设置namenode和datanode的线程数。
在hdfs-site.xml中配置,以下是默认和优化配置,但是如果出现的上述情况,请把默认配置调小。
dfs.datanode.max.xcieveRegionServer
datanode可以同时处理的数据传输连接数,指定在 datanode 内外传输数据使用的最大线程数。
默认4096,推荐值8192
dfs.namenode.handler.count
namenode中用于处理RPC调用的线程数。默认为10,建议值:参数的自然对数*20
python -c ‘import math ; print int(math.log(N) * 20)’
dfs.namenode.service.handler.count
用于处理 datanode 上报数据块和心跳的线程数量,与dfs.namenode.handler.count 算法一致
datanode 处理 RPC 调用的线程数
dfs.datanode.handler.count
datanode中用于RPC调用的线程数,默认为3。可适当增加这个值提升datanode RPC服务的并发度,
线程数的提高将增加datanode内存需求,不宜过度调整这个数值。产线设置的为10
dfs.datanode.max.xcieveRegionServer
最大传输线程数,指定在datanode内外传输数据使用的最大线程数
读写数据时的缓存大小
io.file.buffer.size
设定在读写数据时的缓存大小,应该为硬件分页大小的2倍
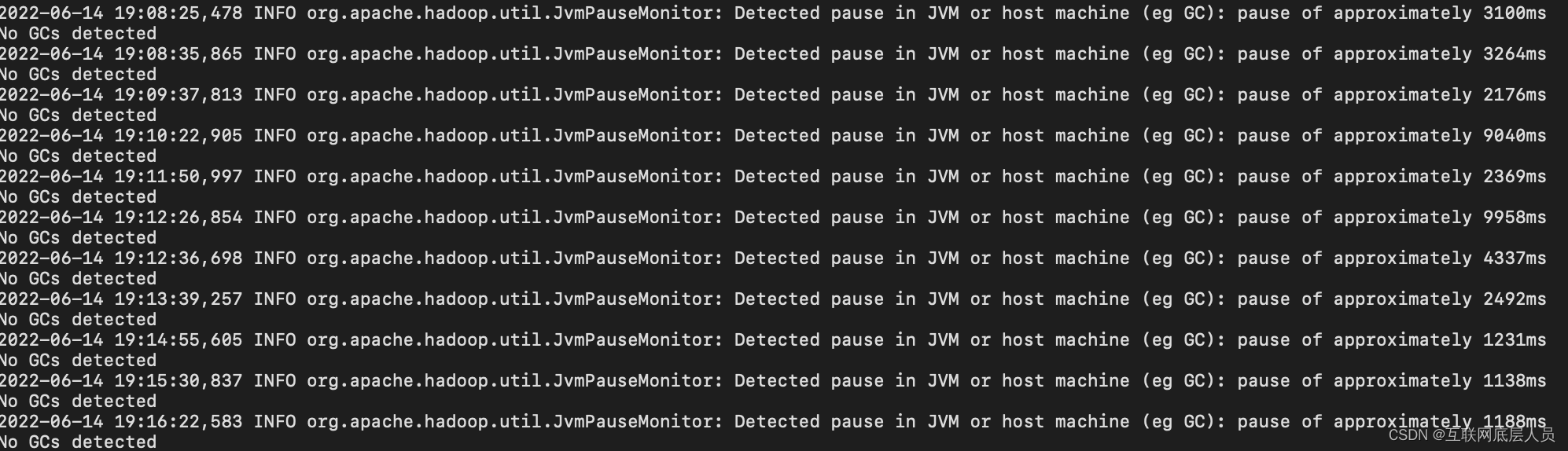
经查资料后总结出有2个方法:
方法一 设置达到70%时清理GC
方法二 增加超时时长
方法三 增加JVM堆内存
方法一设置了,但是没有用,方法二完全就是规避问题不推荐。
方法三是比较推荐的,但是前提是你的内存足够大,否则在hadoop-env.sh中增加堆内存,很容易使得你的机器因为高并发而内存溢出,或者宕机。
所以上述三种方法都不能解决我出现的这个问题,这个还有待考虑,不过可以试试方法一。
java.net.ConnectException: 拒绝连接
出现这个问题其实就是网络带宽问题,我们在集群模式下,所有的RPC协议都是通过网络传输来进行的,当在高并发模式下,网络带宽拥挤就会出现这种情况,解决方法就是
减少内存,减少高并发量
在yarn-site.xml中将
yarn.nodemanager.resource.memory-mb 默认为8GB,我们将它调小即可。
出现这个问题首先可以是因为线程进程数不足,许多进程或者线程还没轮到处理就已经过了60000ms,其次可以是因为网络拥挤问题,我是将线程和进程数改变后发现在大数据文件处理上面有好转,但是效果并不明显,最好的做法就是增加磁盘挂载数和增加datanode数量,如何增加磁盘挂在数,前前往我的博客:Hadoop集群Yarn集群各种常见错误(扩容教程附带)_互联网底层人员的博客-CSDN博客_hadoopyarn集群
通常是因为我们在环境变量设置时没有在PATH前面加$符号,使得你当前配置的环境变量覆盖了原有的环境变量,而$符号是在原有的基础上增加
正确写法应该是:

当然出现这种情况,只需要将原来的环境变量重新修改即可
export PATH="/usr/sbin:/usr/bin:/usr/local/bin:/usr/local/sbin:/bin:/sbin"IPv4 forwarding is disabled. Networking will not work
vim /etc/sysctl.conf
#配置转发
net.ipv4.ip_forward=1
#重启服务,让配置生效
systemctl restart network
#查看是否成功,如果返回为“net.ipv4.ip_forward = 1”则表示成功
sysctl net.ipv4.ip_forward
maven启动了Springboot项目,且显示8080端口已经占用,但是无法打开服务器
firewall-cmd --state
1
停止firewall
systemctl stop firewalld.service
1
禁止firewall开机启动
systemctl disable firewalld.service这个问题一开始我还解决不了,一直很困惑,直到发现防火墙没有关闭我真是晕了
driver failed programming external connectivity on endpoint
重启docker容器即可
systemctl restart docker有些网站打不开,可以自行前往下载,然后通过终端连接器上传到指定目录下
前往docker文件夹,/var/lib/docker/image/overlay2/imagedb/content/sha256
根据imagesid来删除镜像文件
这些都是我之前遇到的一些问题,整理起来不容易,一下子就花了好些时间,后续再补充。















 2133
2133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









