







Python微信订餐小程序课程视频
https://blog.csdn.net/m0_56069948/article/details/122285951
Python实战量化交易理财系统
https://blog.csdn.net/m0_56069948/article/details/122285941
目录
摘要1 引言2 相关工作3 学习内部稀疏结构3.1 内部稀疏结构3.2 学习方法4 实验4.1 语言建模4.1.2 延伸到经常性的高速公路网络4.2 机器阅读理解5 结论致谢参考文献附录 A 由L1-规范正则化 揭示的 ISS附录B 在BIDAF中的ISS
论文地址:在长短时记忆中学习内在的稀疏结构
论文代码:https://github.com/wenwei202/iss-rnns
引用格式:Wen W, He Y, Rajbhandari S, et al. Learning intrinsic sparse structures within long short-term memory[C]. nternational Conference on Learning Representations, 2018.
摘要
模型压缩对于递归神经网络(RNN)在资源有限的用户设备和需要快速响应大规模服务请求的商业客户中的广泛采用具有重要意义。这项工作旨在通过减少LSTM单元中基本结构的大小来学习结构稀疏的长期短期记忆(LSTM),这些基本结构包括输入更新(input updataes)、门(gates)、隐藏状态(hidden states)、单元状态(cell states)和输出(outputs)。单独减小基本结构的尺寸可能会导致它们之间的尺寸不一致,从而最终得到无效的LSTM单元。为了克服这一问题,我们提出了LSTM中的内部稀疏结构(Intrinsic Sparse structure, ISS)。移除ISS的一个组件将同时将所有基本结构的尺寸减少1,从而始终保持尺寸的一致性。通过学习LSTM单元内的ISS,获得的LSTM保持规则,同时具有更小的基本结构。基于分组Lasso正则化,我们的方法在不损失Penn TreeBank数据集语言建模的情况下,获得了10.59倍的加速比。通过一个仅有2.69M权值的紧凑模型,成功地对Penn TreeBank数据集的机器问答进行了评估。我们的方法被成功地扩展到非LSTM RNN,如循环高速网(Recurrent Highway Networks,RHNs)。我们的源代码是可用的。
1 引言
模型压缩(Jaderberg et al. (2014), Han et al. (2015a), Wen et al. (2017), Louizos et al.(2017))是一类减小深度神经网络(DNN)规模以加速推理的方法。结构学习(Zoph & Le (2017), Philipp & Carbonell (2017), Cortes et al. (2017))成为DNN结构探索的一个活跃的研究领域,有可能用机器自动化取代人工进行设计空间探索。在这两种技术的交叉中,一个重要的领域是学习DNN中的紧凑结构,以使用最小的内存和执行时间进行高效的推理计算,而不损失准确性。在过去的几年里,卷积神经网络(CNN)的紧凑结构学习已经得到了广泛的探索。Han等人(2015b)提出了稀疏CNN的连接剪枝。剪枝方法在粗粒度水平上也能成功工作,如CNN中的剪枝滤波器(Li et al.(2017))和减少神经元数量(Alvarez & Salzmann (2016)). Wen et al. (2016)提出了一个学习DNN中通用紧凑结构(神经元、滤波器、滤波器形状、通道甚至层)的一般框架。
学习循环神经网络的紧凑结构更具挑战性。由于循环单元在序列中的所有时间步骤中共享,压缩LSTM cell将影响所有时间步。Narang等人最近的一项工作(2017)提出了一种剪枝方法,可以删除RNNs中多达90%的连接。连接剪枝方法稀疏了循环单元的权值,但不能显式改变基本结构,如输入更新数、门、隐藏状态、单元状态和输出。此外,得到的稀疏矩阵具有非零权的不规则/非结构化模式,这不利于现代硬件系统的高效计算(Lebedev & Lempitsky(2016))。之前关于gpu中稀疏矩阵乘法的研究(Wen et al.(2016))表明,speedup2要么是适得其反,要么是可以忽略的。更具体地说,AlexNet权矩阵的稀疏性3为67.6%、92.4%、97.2%、96.6%和94.3%,加速率分别为0.25x、0.52x、1.38x、1.04x和1.36x。这个问题也存在于cpu中。图1显示了稀疏性下的非结构化模式限制了加速。只有当稀疏度超过80%时,我们才开始观察速度的增加,即使稀疏度为95%,远低于理论的20,加速速度也在3 - 4左右。在这项工作中,我们专注于学习结构稀疏的LSTM以提高计算效率。更具体地说,我们的目标是在学习过程中同时减少基本结构的数量,使得到的LSTM保持原始原理图的密集连接,但这些基本结构的尺寸更小;这种紧凑的模型具有结构稀疏性,去掉了权重矩阵中的列和行,其计算效率如图1所示。此外,深度学习框架中的现成库可以直接用于部署简化的LSTM。细节应该解释清楚。
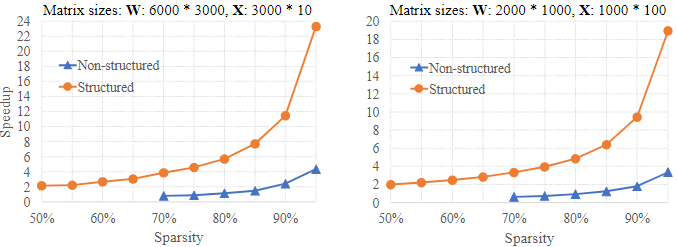
图1:使用非结构化和结构化稀疏性的矩阵乘法加速。速度是在英特尔至强CPU E5-2673 [email protected] GHz的英特尔MKL实施中测量的。W·X的广义矩阵-矩阵乘法(GEMM)是用CBLAS-SMEM实现的。选择矩阵大小以反映LSTM中常用的GEM。例如,(A)表示隐藏大小为1500、输入大小为1500、批大小为10的GEMM in LSTM。为了通过稀疏来加速GEMM,W被稀疏。在非结构化稀疏方法中,W被随机稀疏并编码为用于稀疏计算的压缩稀疏行格式(使用MKL scsrmm);在结构化稀疏方法中,W中的2k列和4k行被删除以匹配相同的稀疏度(即删除参数的百分比),从而在较小的规模下更快地进行GEMM。
循环单位是一个至关重要的挑战:由于基本结构相互交织,独立去除这些结构会导致它们的尺寸不匹配,进而导致无效的循环cell。这个问题在CNN中并不存在,在CNN中,神经元(或过滤器)可以被独立地移除,而不会破坏最终网络结构的可用性。我们的关键贡献之一是识别RNNs中的结构,这些结构应该被视为一个组,以最有效地探索基本结构的稀疏性。更具体地说,我们提出了内部稀疏结构(ISS)作为群体来实现这个目标。通过去除与ISS一个部件相关的重量,(基本结构)的尺寸/尺寸同时减少了一个。
我们在Penn Treebank数据集(Marcus et al.(1993))和SQuAD数据集(Rajpurkar et al.(2016))的语言建模中使用LSTM和RHNs来评估我们的方法。我们的方法既适用于微调,也适用于从零开始的训练。在一个包含两个隐藏大小为1500(即ISS的1500个分量)的堆叠LSTM层的RNN中(Zaremba等人(2014)),我们的方法发现,第一个LSTM和第二个LSTM的373和315的大小足以应对同样的困惑。推理速度达到10.59。结果是用相同的epoch数从头训练得到的。直接训练大小为373和315的LSTM不能达到同样的困惑,这证明了学习ISS对于模型压缩的优势。在更紧凑和最先进的模型RHN模型(Zilly等人(2017))和BiDAF模型(Seo等人(2017))中也获得了令人鼓舞的结果。
2 相关工作
DNN压缩的主要方法是降低DNN内部结构的复杂性,这些研究可以分为三类:一、去除原始DNN中的冗余结构,二、逼近DNN的原始功能(Denil等人)。(2013),Jaderberg等人。(2014),Hintonet等人。(2015),Lu等人。(2016),Prabhavalkar等人。(2016),Molchanov等人。(2017)),三、设计具有固有紧凑结构的DNN(Szegedy等人)。(2015),他等人。(2016)ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











