







 本文详细介绍了卷积神经网络(CNN)中的输入输出大小计算,以及CNN模型的常用结构。重点阐述了池化层的作用,包括特征不变性、特征降维和防止过拟合,并对比了平均池化与最大池化的特点。此外,文章探讨了模型压缩技术,如低秩近似、剪枝、参数量化和二值网络,以及知识蒸馏和紧凑网络结构。最后,针对RNN中的梯度消失和梯度爆炸问题,解释了LSTM和GRU如何解决这些问题,以及它们的结构和优势。
本文详细介绍了卷积神经网络(CNN)中的输入输出大小计算,以及CNN模型的常用结构。重点阐述了池化层的作用,包括特征不变性、特征降维和防止过拟合,并对比了平均池化与最大池化的特点。此外,文章探讨了模型压缩技术,如低秩近似、剪枝、参数量化和二值网络,以及知识蒸馏和紧凑网络结构。最后,针对RNN中的梯度消失和梯度爆炸问题,解释了LSTM和GRU如何解决这些问题,以及它们的结构和优势。
参考:
https://mp.weixin.qq.com/s/9aRto7i_JivHCniSxlVsxA
CNN
卷积操作实现
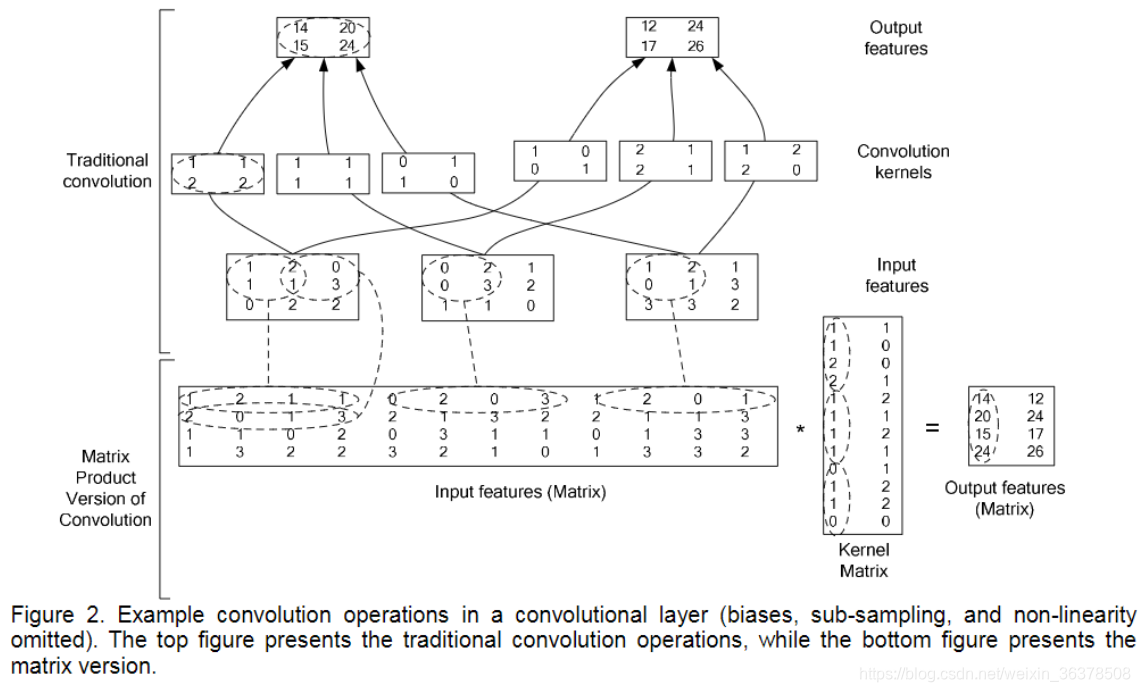
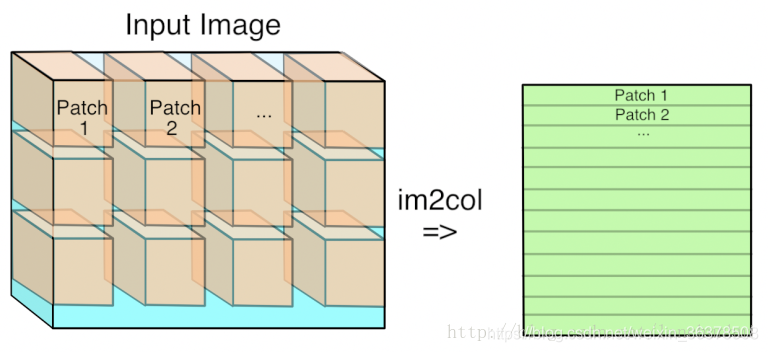
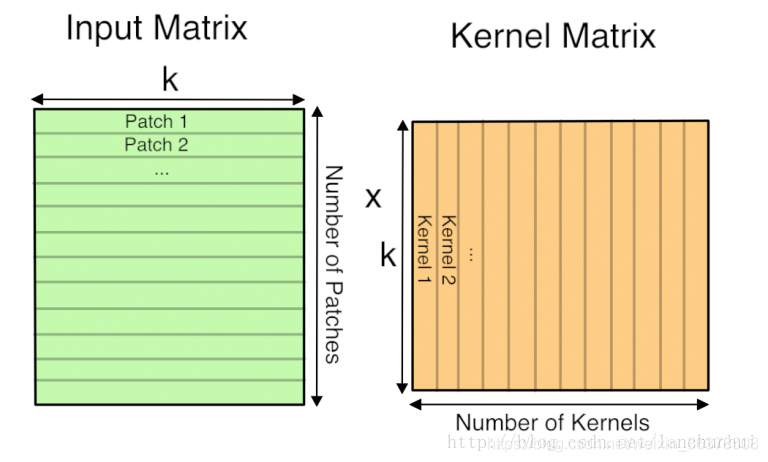
输入输出大小计算 :
𝑁=(𝑊−𝐹+2𝑃)/𝑆+1
其中:
N:输出大小
W:输入大小
F:卷积核大小
P:填充值大小
S:步长大小
CNN常用的模型

池化
池化层不包含可学习的参数。只需要指定池化类型,池化操作核大小,池化步长等超参数。
池化有平均池化,最大池化,随机池化(对输入数据中的元素按照一定概率大小随机选择,并不像最大池化那样总是选最大元素,对随机池化而言,元素值大的响应被选中的概率也大。可以说在全局意义上,随机池化与平均池化近似,在局部意义上,则服从最大池化的准则)
作用:其实就是降采样操作,池化层的引入是仿照人的视觉系统对视觉输入对象进行降维(降采样)和抽象。
研究者认为池化有三种作用:
特征不变性:池化操作让模型更关注是否存在某些特征而不是特征的具体位置。可看做是一种很强的闲言,使特征学习包含某种程度的自由度,能容忍一些特征微小的位移
特征降维:降采样,池化结果中一个元素对应于原输入数据的一个子区域,因此池化相当于在空间范围内做了维度约检,从而使模型可以抽取更广范围的特征。同时减小下一层输入的大小,进而减小计算量和参数个数
在一定程度上防止过拟合,方便优化
根据相关理论, 特征提取的误差主要来自两个方面:
邻域大小受限造成的估计值 方差增大
卷积层参数误差造成估计 均值的偏移
平均池化能减小第一种误差(邻域大小受限造成的估计值方差增大), 更多的保留图像的背景信息
最大池化能减小第二种误差(卷积层参数误差造成估计均值的偏移), 更多的保留纹理信息
随机池化介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行采样,在平均意义上,与均值近似,在局部意义上,服从最大池化的准则。
平均池化与最大池化分别适用于什么场景:
当map中的信息都应该有所贡献的时候用avgpool,比如图像分割中常用global avgpool来获取全局上下文关系,比如224x224图像分类将最后的7x7map进行avgpool而不是maxpool。因为深层高级语义信息一般来说都能够帮助分类器分类。
反之 为了减少无用信息时候用maxpool,比如浅层网络常见到maxpool,因为刚开始几层对图像而言包含较多的无关信息,另外avgpool与maxpool输出值幅度波动大,可以加一些归一化操作。具体使用场景根据任务来,实际效果炼丹后才知道
卷积神经网络的压缩
模型压缩技术主要分为两个部分:前端压缩,后端压缩
前端压缩:是指不改变网络结构的压缩技术,主要包括知识蒸馏,紧凑模型设计,滤波器层面的剪枝等。可很好匹配深度学习库
后端压缩:其目标在于尽可能的减少模型大小,因而会对原始的网络结构造成极大程度上的改造。这种改造往往不可逆。包括低秩近似,未加限制的剪枝,参数量化以及二值网络等。
当然也可以将前端压缩的输出作为后端压缩的输入,能够在最大程度上减少模型的复杂度。
低秩近似
采用低秩近似来重构权重矩阵。在小数据集上能够达到2-3倍的压缩效果,最终结果甚至可能超过压缩之前的网络。
还可以直接使用矩阵分解来降低矩阵权重参数。如用SVD分解。利用矩阵分解能够将卷积层压缩2-3倍,全连接压缩5-13倍,速度提升2倍,精度损失控制在1%之内。
低秩近似在 小网络模型上取得了不错的效果,但其参数量与网络层数呈线性变化趋势,随着层数增加与模型复杂度提高,其搜索空间急剧增大。
剪枝与稀疏约束
通过剪枝处理,在减小模型复杂度的同时,还能有效防止过拟合,提升模型泛化性。在训练中,需要一定冗余的参数数量来保证模型的可塑性与容量,在完成训练之后,则可以通过剪枝操作来移除这些荣誉参数,使得模型更加成熟。给定一个预训练好的网络模型,常用剪枝算法的流程:
衡量神经元重要程度(剪枝算法最重要的核心步骤)。根据剪枝粒度不同,神经元定义可以是一个权重连接,也可以是整个滤波器。
移除掉一部分不重要的神经元。可以根据阈值来判断神经元是否可以被剪除,也可以按照重要程度排序,剪除一定比例的神经元。后者简单
对网络进行微调。剪枝操作不可避免影响网络精度,为防止对分类性能造成过大破坏,需要对剪枝后的模型进行微调。 返回第1步,进行下一轮剪枝。
参数量化
量化是指从权重中归纳出若干“代表”,由这些代表来表示某一类权重的具体数值。代表被存储在码本中,而原权重矩阵只需记录各自代表的索引即可,从而极大降低存储开销。即使采用最简单的标量量化算法,也能在保持网络性能不受显著影响的情况下,将模型大小减少8-16倍。不足在于,当压缩率比较大时容易造成分类精度大幅度下降。
二值网络
所有参数取值只能是+1或-1。在普通NN中,一个参数由单精度浮点型表示,参数二值化能将存储开销降低为原来的1/32。二值化需要解决两个基本问题:
如何对权重进行二值化? 直接根据权重正负二值化,x=sign(x) 随机二值化,对每个权重以一定概率去+1,这个更耗时
如何计算二值权重梯度?二值权重梯度为0,无法进行参数更新。用符号函数进行放松。Htanh(x)=max(-1,min(1,x))代替sign(x)。当x在[-1,1],存在梯度值1,否则梯度值0
知识蒸馏
在不改变模型复杂度情况下,增加监督信息的丰富程度肯定会带来性能上的提升。知识蒸馏是迁移学习的一种,目的是将庞大复杂模型学到的知识通过一定
的手段迁移到精简的小模型上,使得小模型能够获得与大模型相近的性能。这两个模型分别扮演老师(大模型)和学生(小模型)角色:让学生自己学的话,收效甚微;若能经过一个老师的指导,便能够事半功倍,学生甚至有可能超越老师。
紧凑的网络结构
设计出很多更加紧凑的网络结构,将这些新结构运用到神经网络设计中来,能够使模型在规模与精度之间达到一个较好的平衡。比如:
fire module用在SqueezeNet中
MobileNet:Depth-wise conv,深度分离卷积等
RNN
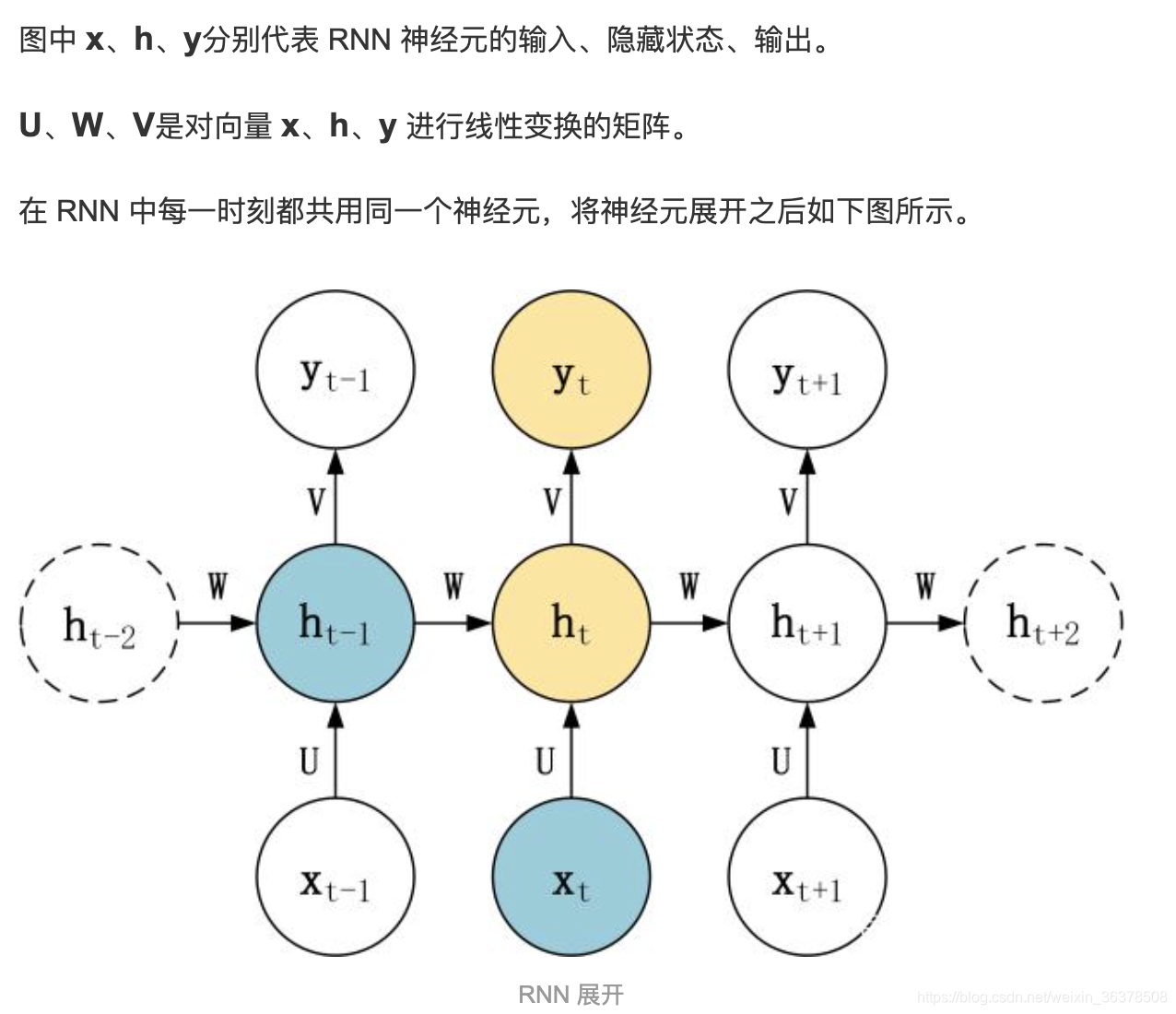
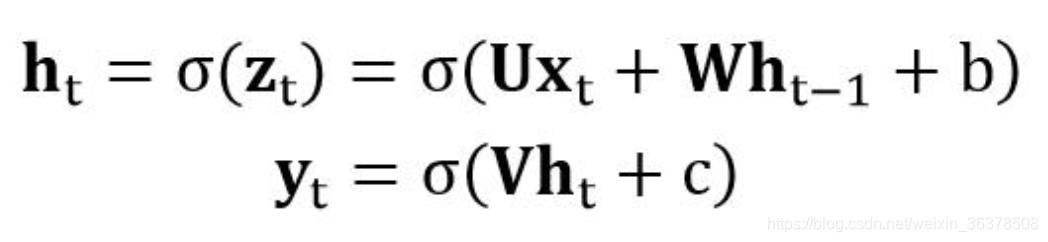
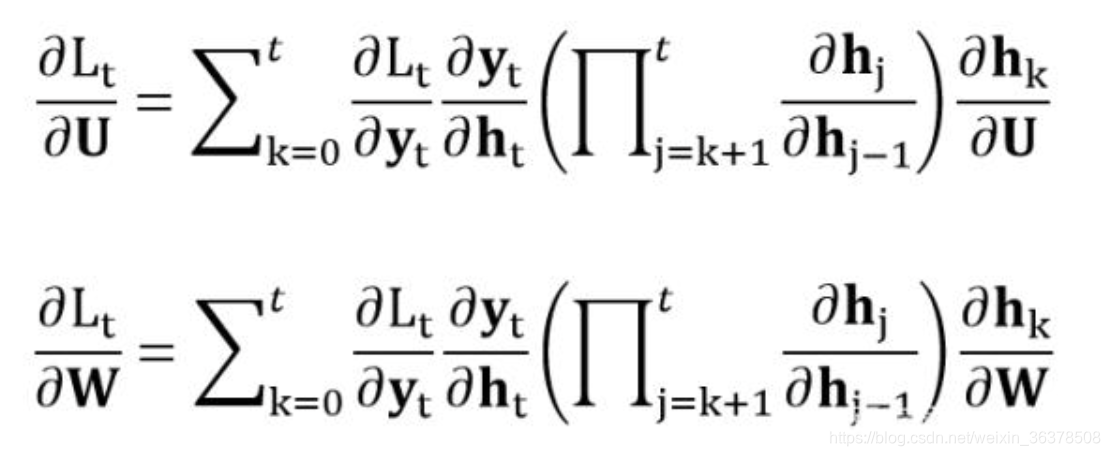
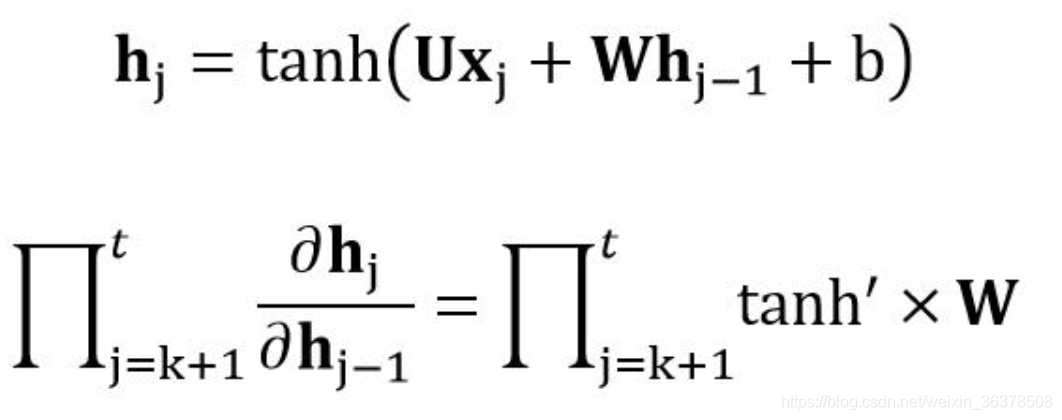
为什么出现梯度爆炸和梯度消失
由于RNN当中也存在链式求导规则,并且其中序列的长度位置。
所以如果矩阵中有非常小的值,并且经过矩阵相乘N次之后,梯度值快速的以指数形式收缩,较远的时刻梯度变为0。
如果矩阵的值非常大,就会出现梯度爆炸
可以看出,「当W很小或者很大,同时i和j相差很远的时候」,由于公式里有一个「指数运算」,这个梯度就会出现异常,变得超大或者超小,也就是所谓的“梯度消失/梯度爆炸”问题。
当系数比较小时,前面的网络层比后面的网络层梯度变化更小,故权值变化缓慢,从而引起了梯度消失问题。 当系数比较大时,则前面的网络层比后面的网络层梯度变化更快,引起了梯度爆炸的问题。
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。

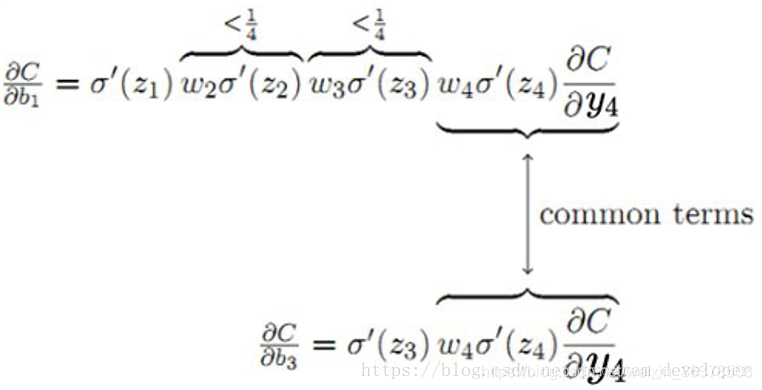
那梯度消失和梯度爆炸时分别有什么问题呢?
「梯度消失」时,会让RNN在更新的时候,只更新邻近的几步,远处的步子就更新不了。所以遇到“长距离依赖”的时候,这种RNN就无法handle了。
「梯度爆炸」时,会导致在梯度下降的时候,每一次更新的步幅都过大,这就使得优化过程变得十分困难。
如何解决梯度爆炸问题
前面讲到,梯度爆炸,带来的主要问题是在梯度更新的时候步幅过大。那么最直接的想法就是限制这个步长,或者想办法让步长变短。因此,我们可以使用“梯度修剪(gradient clipping)”的技巧来应对梯度爆炸。cs224n中给出了伪代码:

当激活函数为sigmoid时,梯度消失和梯度爆炸哪个更容易发生?
结论:梯度爆炸问题在使用sigmoid激活函数时,出现的情况较少,不容易发生
对于更普遍的梯度消失问题,可以考虑一下三种方案解决:
用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。
用Batch Normalization。
LSTM的结构设计也可以改善RNN中的梯度消失问题。
如何解决梯度消失
梯度消失带来的最严重问题在于,在更新参数时,相比于临近的step,那些较远的step几乎没有被更新。从另一个角度讲,每一个step的信息,由于每一步都在被反复修改,导致较远的step的信息难以传递过来,因此也难以被更新。
可以看出,hidden state在不断被重写,这样的话,经过几步的传递,最开始的信息就已经所剩无几了。这根前面在讨论梯度消失的那个包含指数计算的公式是遥相呼应的,都反映了RNN无法对付长距离依赖的问题。既然RNN无法很好地保存历史信息,那么我们能不能想办法把这个“历史的记忆”进行保存日后使用呢?————当然是可以的,LSTM就是干这事儿!
2 LSTM
主要是为了解决RNN梯度消失问题
论文地址:https://www.bioinf.jku.at/publications/older/2604.pdf
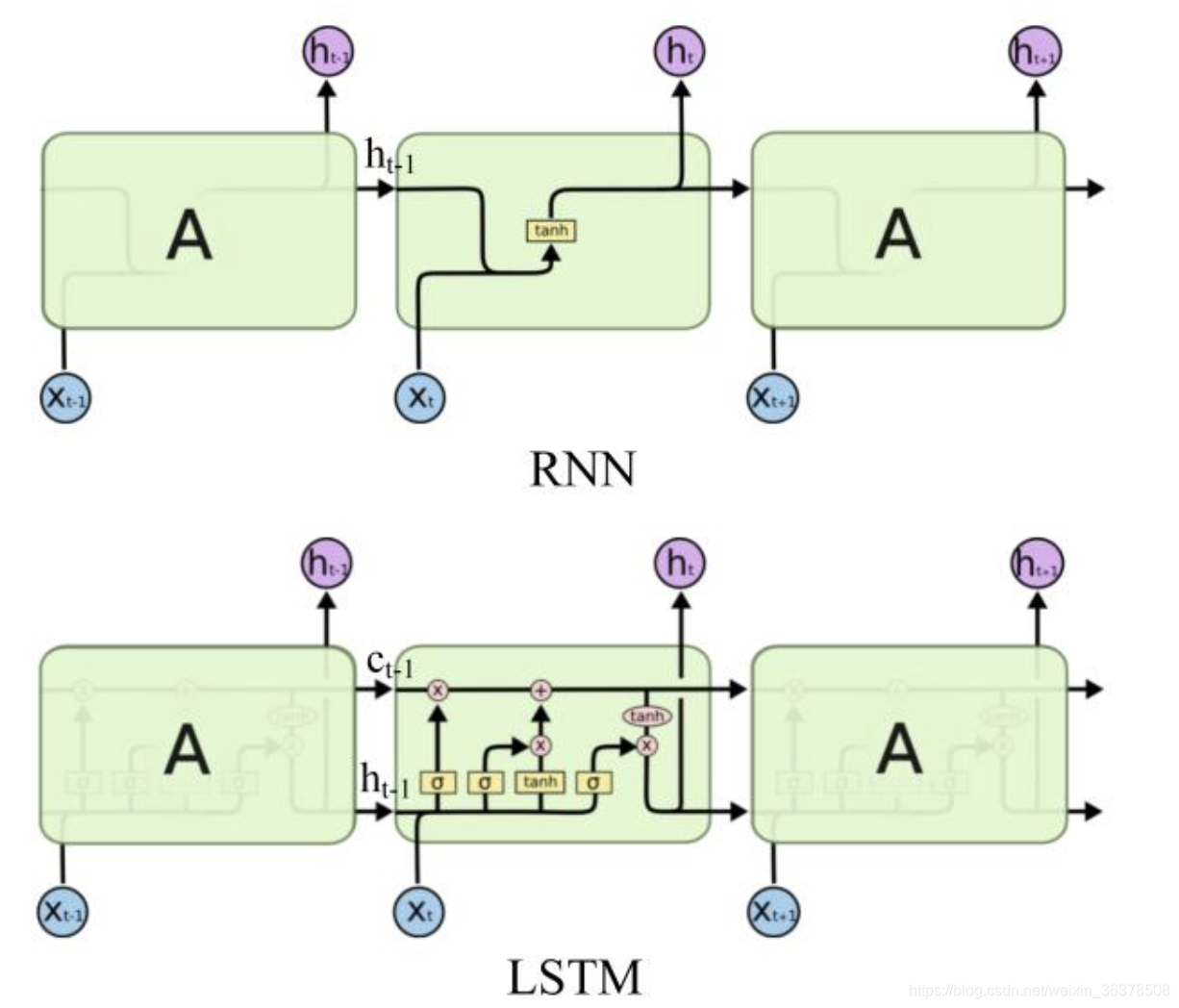
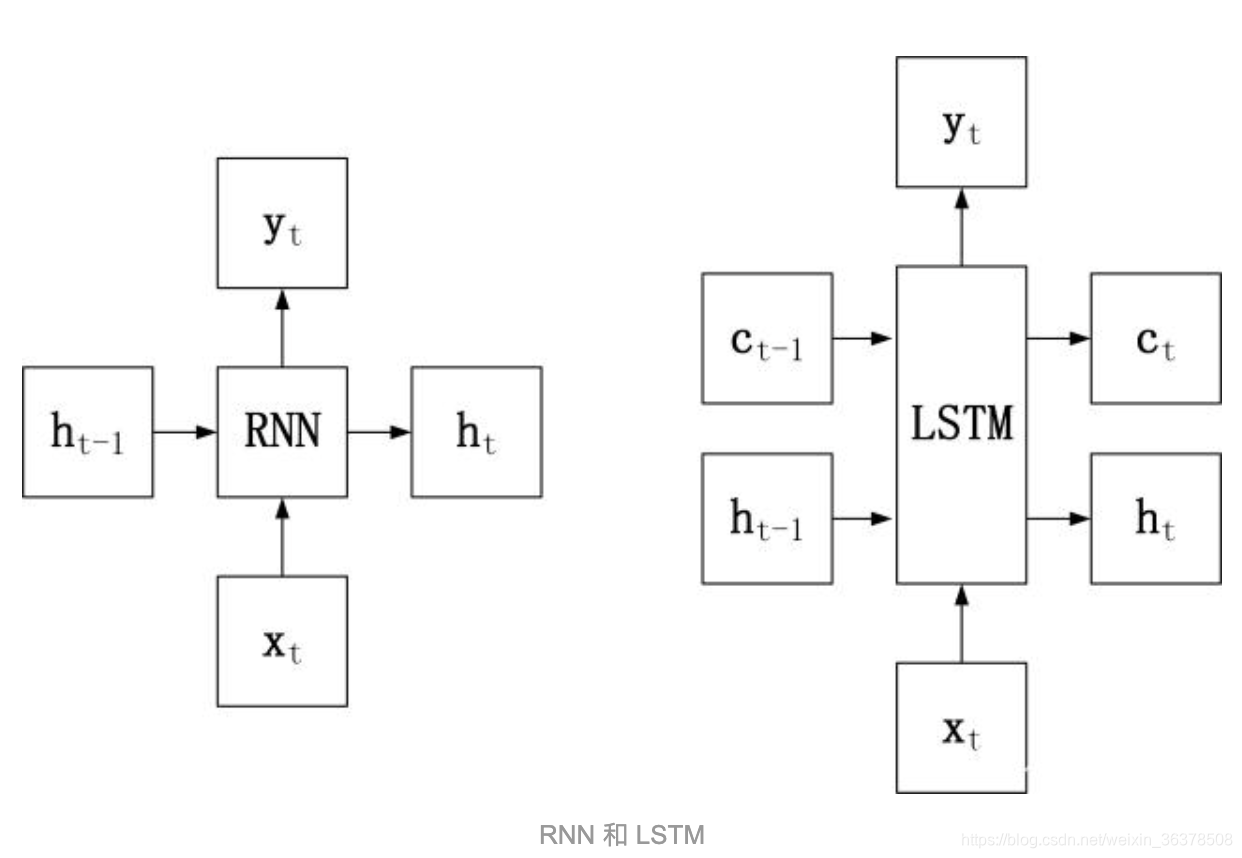
LSTM 的神经元在此基础上还输入了一个 cell 状态 ct-1, cell 状态 c和 RNN 中的隐藏状态 h相似,都保存了历史的信息,从 ct-2 ~ ct-1 ~ ct。在 LSTM 中 c 与 RNN 中的 h扮演的角色很像,都是保存历史状态信息,而在 LSTM 中的 h 更多地是保存上一时刻的输出信息。
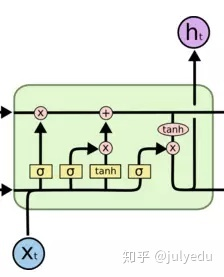
除此之外,LSTM 内部的计算更加复杂,包含了遗忘门、输入门和输出门,接下来分别介绍每一个门的作用。
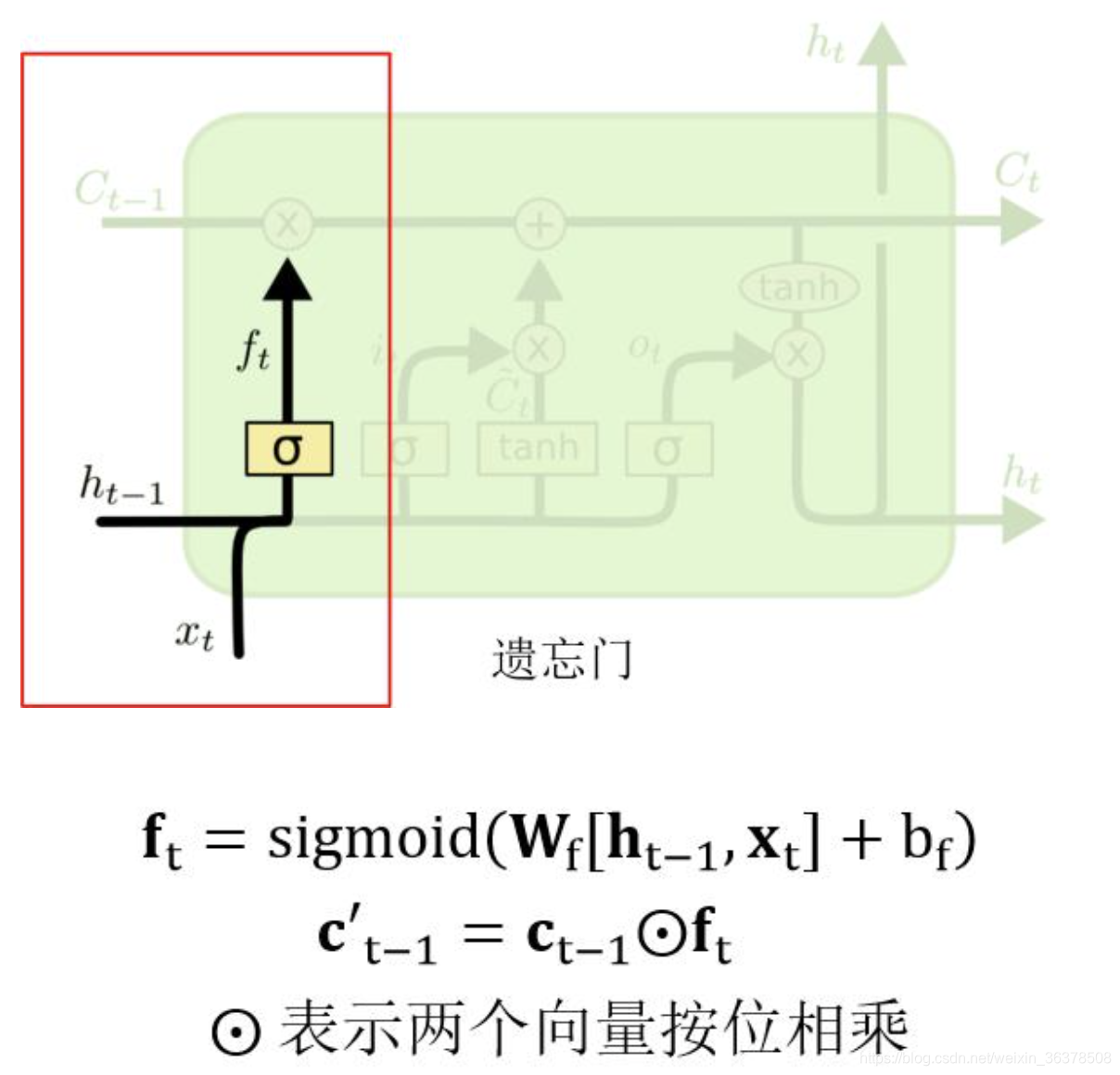
遗忘门
下图中红色框中的是 LSTM 遗忘门部分,用来判断 cell 状态 ct-1 中哪些信息应该删除。其中 σ表示激活函数 sigmoid。
输入的 ht-1 和 xt 经过 sigmoid 激活函数之后得到 ft,
ft 中每一个值的范围都是 [0, 1]。ft 中的值越接近 1,表示 cell 状态 ct-1 中对应位置的值更应该记住;ft 中的值越接近 0,表示 cell 状态 ct-1 中对应位置的值更应该忘记。
将 ft 与 ct-1 按位相乘 (ElementWise 相乘),即可以得到遗忘无用信息之后的 c’t-1。
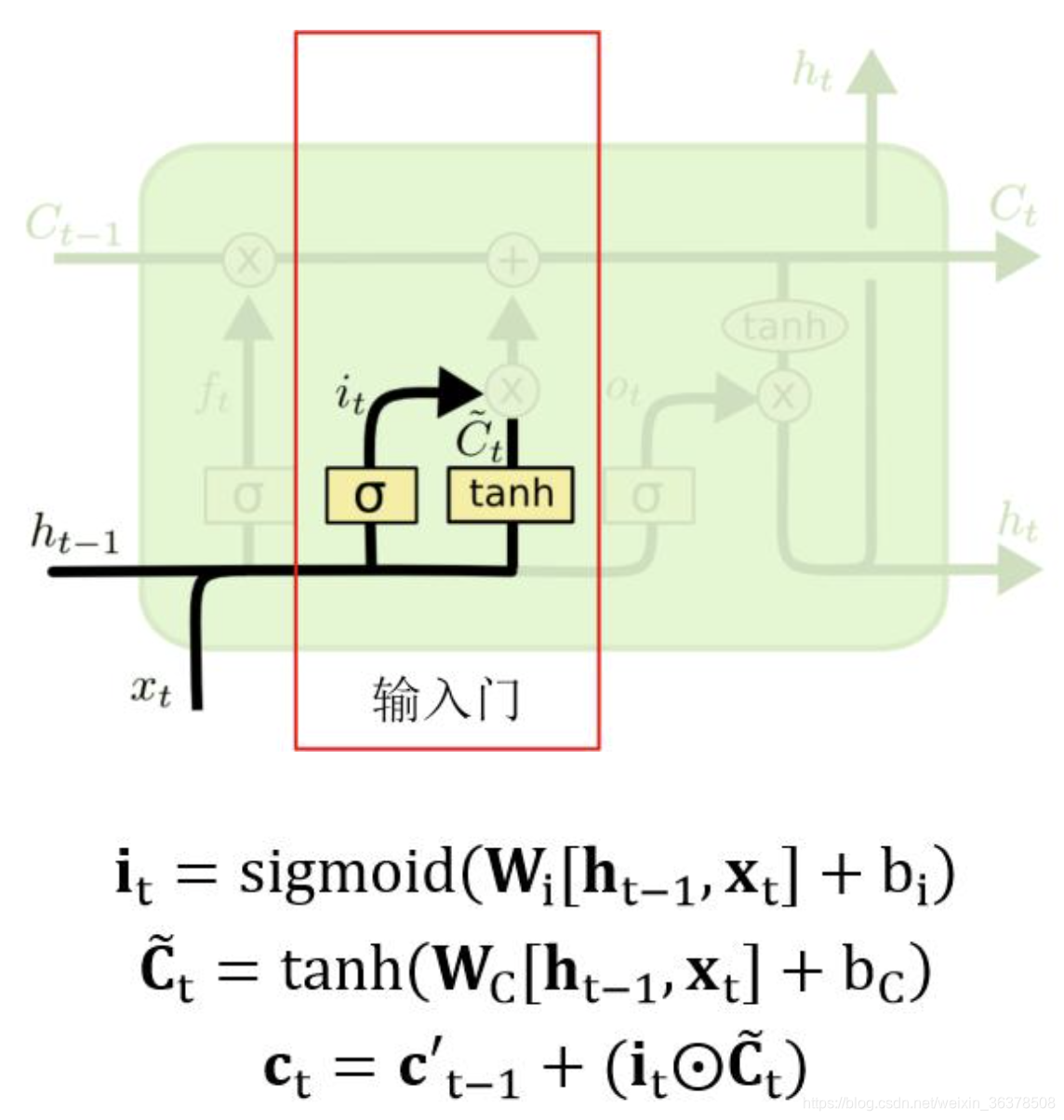
输入门:
下图中红色框中的是 LSTM 输入门部分,用来判断哪些新的信息应该加入到 cell 状态 c’t-1 中。
输入的 ht-1 和 xt 经过 tanh 激活函数可以得到新的输入信息 (图中带波浪线的Ct),但是这些新信息并不全是有用的,因此需要使用 ht-1 和 xt 经过 sigmoid 函数得到 it,
it表示哪些新信息是有用的。
两向量相乘后的结果加到 c’t-1 中,即得到 t 时刻的 cell 状态 ct。
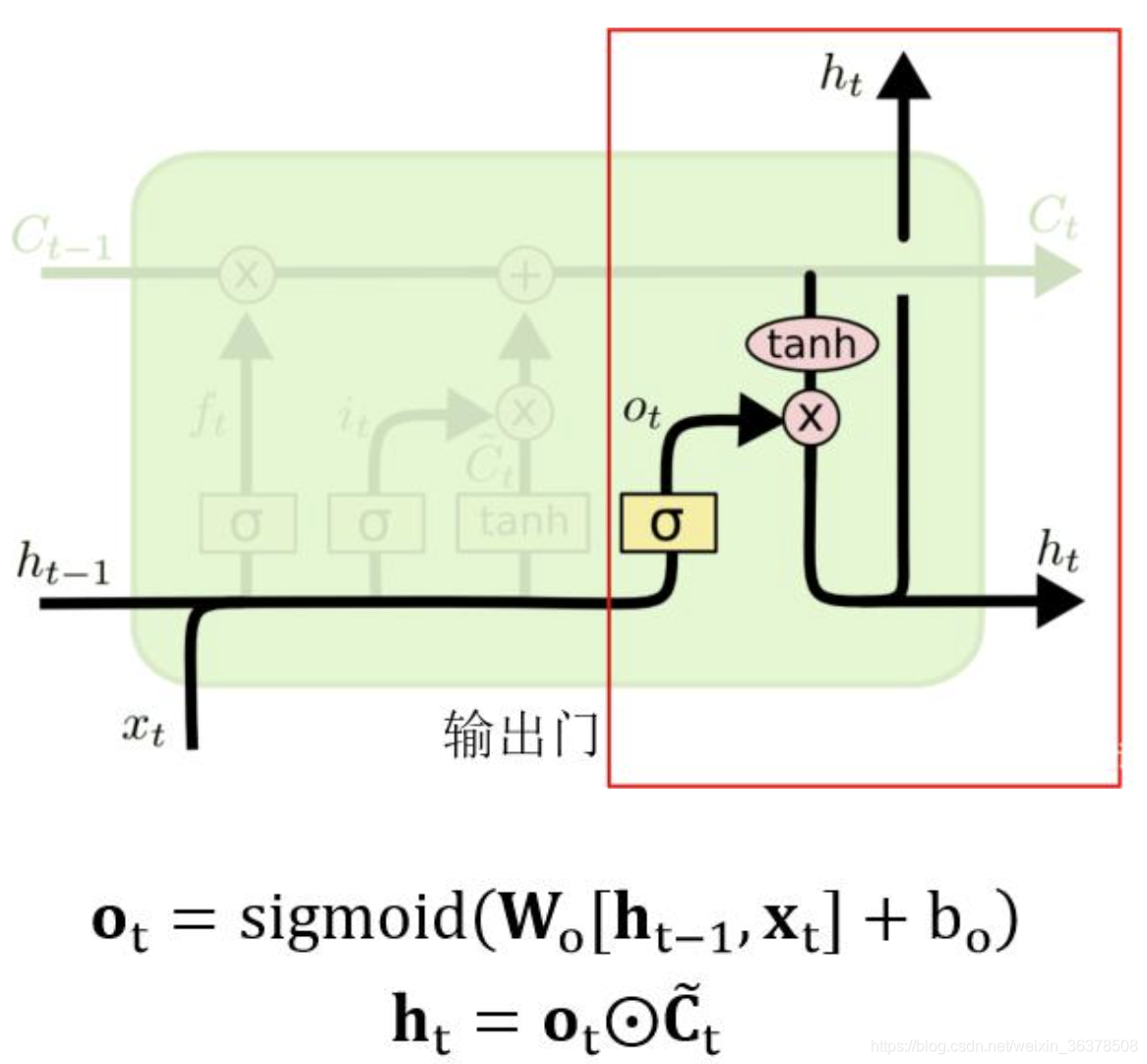
输出门:
下图中红色框中的是 LSTM 输出门部分,用来判断应该输出哪些信息到 ht 中。
cell 状态 ct 经过 tanh函数得到可以输出的信息,
然后 ht-1 和 xt 经过 sigmoid 函数得到一个向量 ot,ot 的每一维的范围都是 [0,1],表示哪些位置的输出应该去掉,哪些应该保留。两向量相乘后的结果就是最终的 ht。
LSTM 缓解梯度消失、梯度爆炸
在上一节中我们知道,RNN中出现梯度消失的原因主要是梯度函数中包含一个连乘项,如果能够把连乘项去掉就可以克服梯度消失问题。如何去掉连乘项呢?我们可以通过使连乘项约等于0 或者约等于 1,从而去除连乘项
LSTM 中通过门的作用,可以使连乘项约等于 0 或者 1。首先我们看一下 LSTM 中 ct 与 ht 的计算公式:
在公式中 ft 与 ot 都是通过 sigmoid 函数得到的,意味着它们的值要么接近 0,要么接近 1。因此在 LSTM 中的连乘项变成:
因此当门的梯度接近1时,连乘项能够保证梯度很好地在 LSTM 中传递,避免梯度消失的情况发生。
而当门的梯度接近 0 时,意味着上一时刻的信息对当前时刻并没有作用,此时没有必要把梯度回传。
这就是 LSTM 能够克服梯度消失、梯度爆炸的原因。
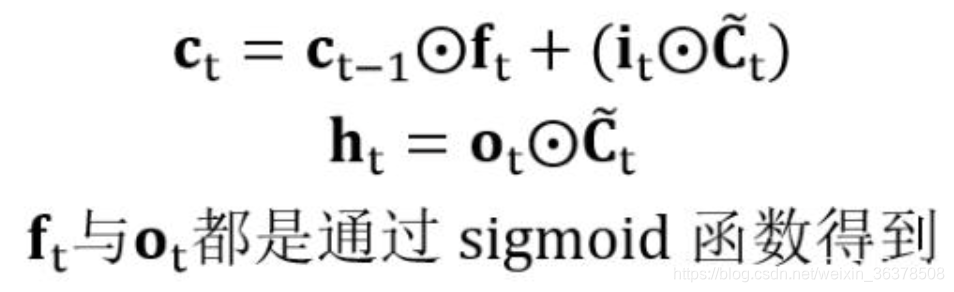
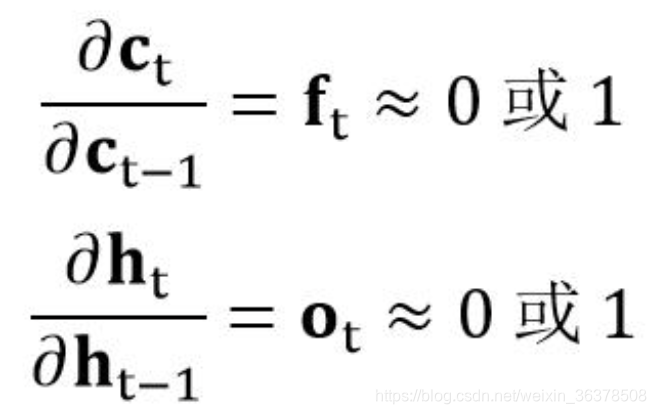
LSTM结构推导,为什么比RNN好?
推导forget gate,input gate,cell state, hidden information等的变化;因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。
为什么LSTM模型中既存在sigmoid又存在tanh两种激活函数,而不是选择统一一种sigmoid或者tanh?这样做的目的是什么?
sigmoid 用在了各种gate上,产生0~1之间的值,这个一般只有sigmoid最直接了。
tanh 用在了状态和输出上,是对数据的处理,这个用其他激活函数或许也可以。
二者目的不一样 另可参见A Critical Review of Recurrent Neural Networks for Sequence Learning的section4.1,说了那两个tanh都可以替换成别的。
BILSTM
https://github.com/bozheng-hit/ELMo/blob/bedbdbd8893e3ee9c734b43aa55c297331ddf456/src/modules/lstm_cell_with_projection.py
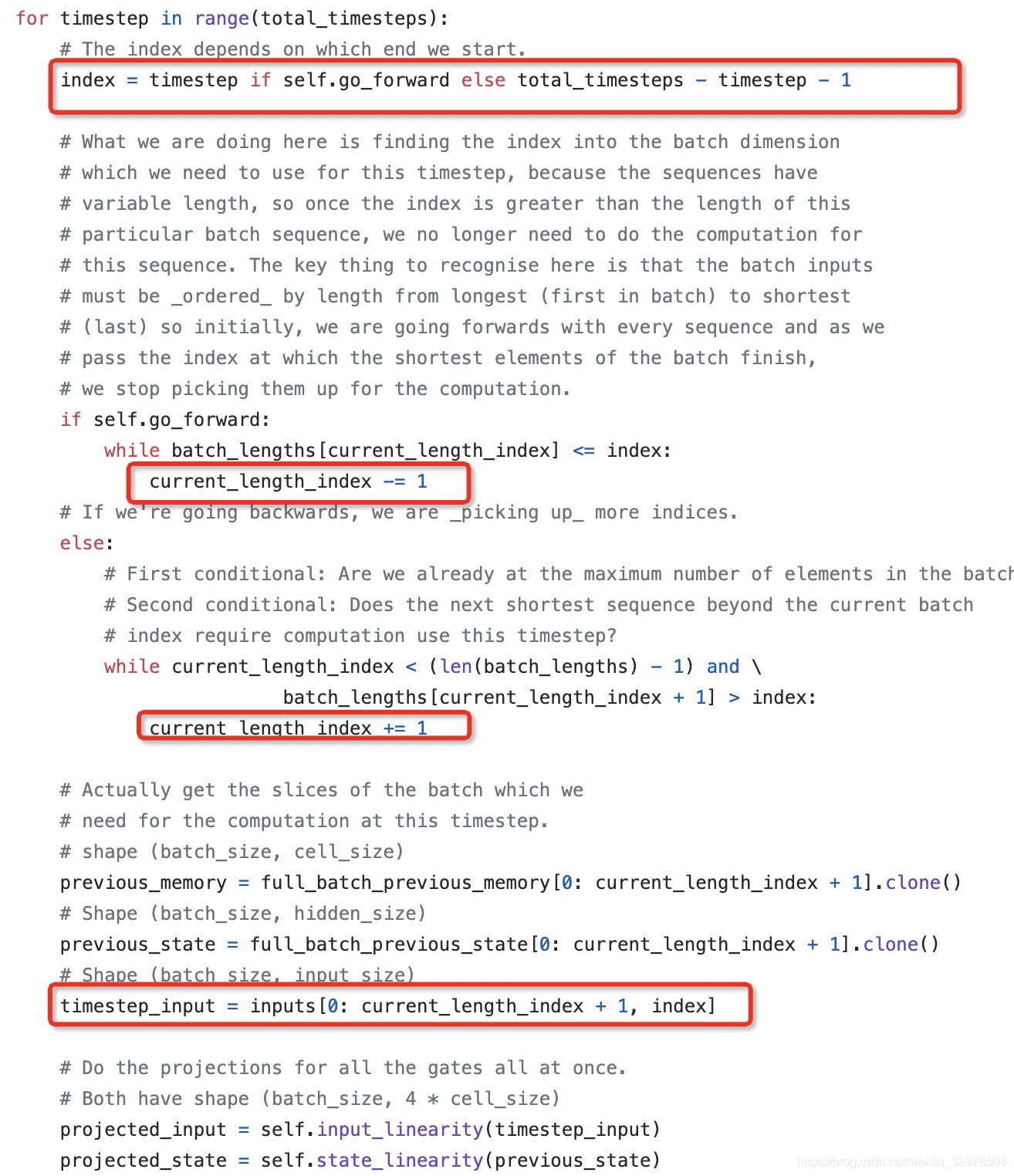
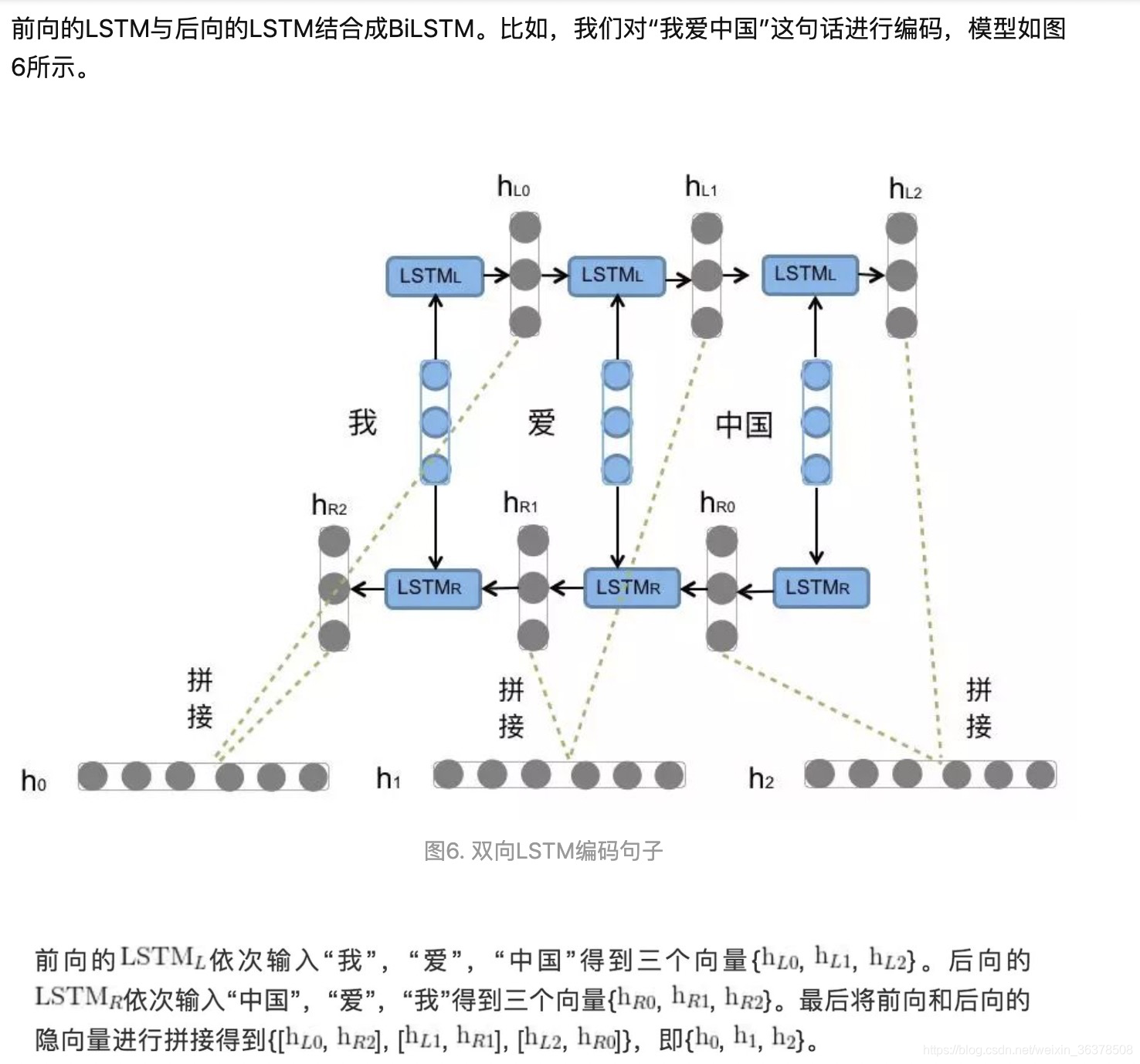
3 GRU
GRU 是 LSTM 的一种变种,结构比 LSTM 简单一点。LSTM有三个门 (遗忘门 forget,输入门 input,输出门output),而 GRU 只有两个门 (更新门 update,重置门 reset)。另外,GRU 没有 LSTM 中的 cell 状态 c。
图中的 zt 和 rt 分别表示更新门 (红色) 和重置门 (蓝色)。
重置门 rt 控制着前一状态的信息 ht-1 传入候选状态 (图中带波浪线的ht) 的比例,重置门 rt 的值越小,则与 ht-1 的乘积越小,ht-1 的信息添加到候选状态越少。
更新门用于控制前一状态的信息 ht-1 有多少保留到新状态 ht 中,当 (1- zt) 越大,保留的信息越多。

GRU是什么?GRU对LSTM做了哪些改动?
GRU是Gated Recurrent Units,是循环神经网络的一种。
GRU只有两个门(update和reset),LSTM有三个门(forget,input,output)
GRU直接将hidden state 传给下一个单元,而LSTM用memory cell 把hidden state 包装起来。
4 更多更好的RNNs
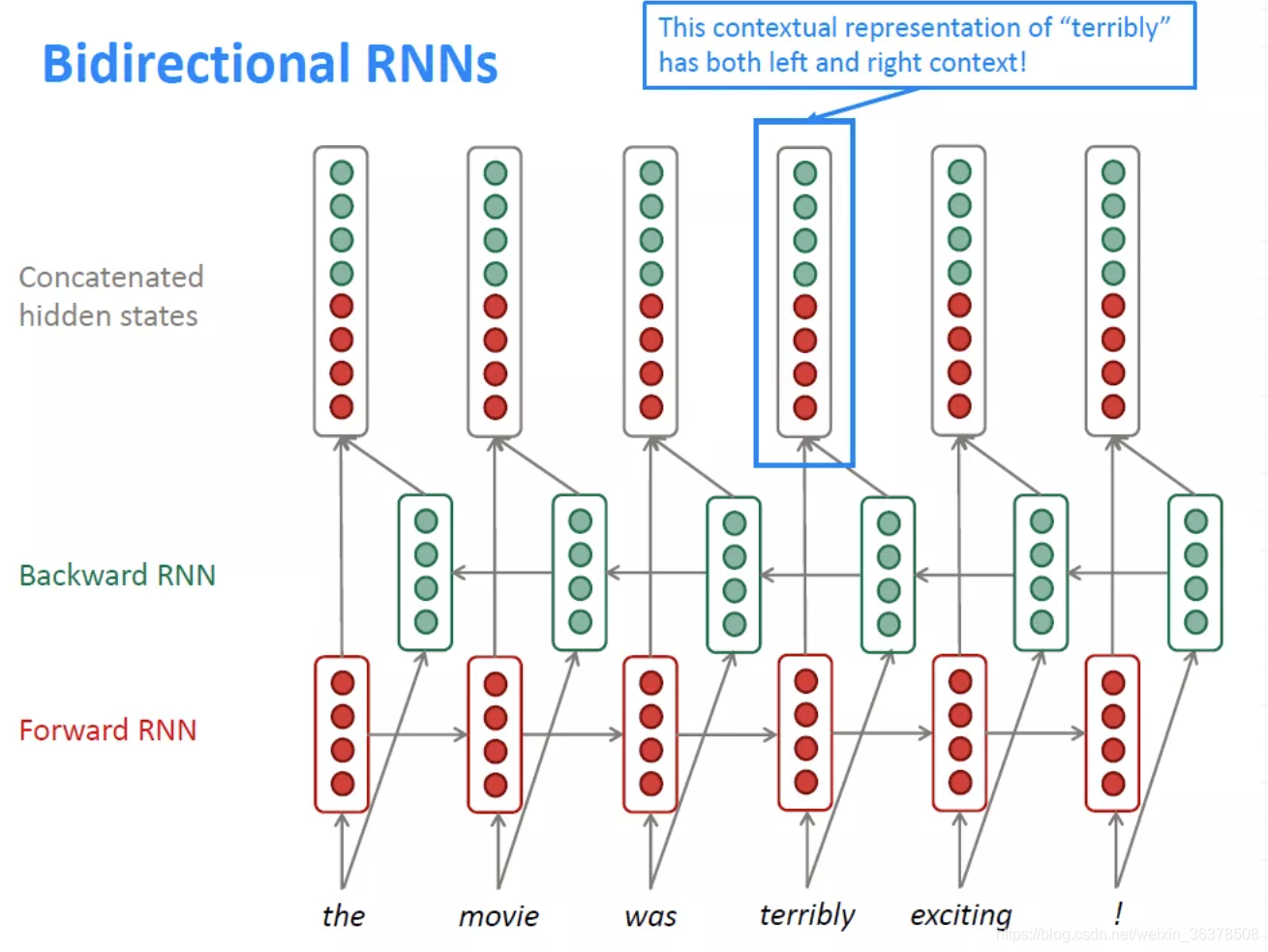
双向RNNs(Bidirectional RNNs)
RNN是按照顺序处理一个序列的,这使得每个step我们都只能考虑到前面的信息,而无法考虑到后面的信息。而很多时候我们理解语言的时候,需要同时考虑前后文。因此,我们可以将原本的RNN再添加一个相反方向的处理,然后两个方向共同表示每一步的输出。
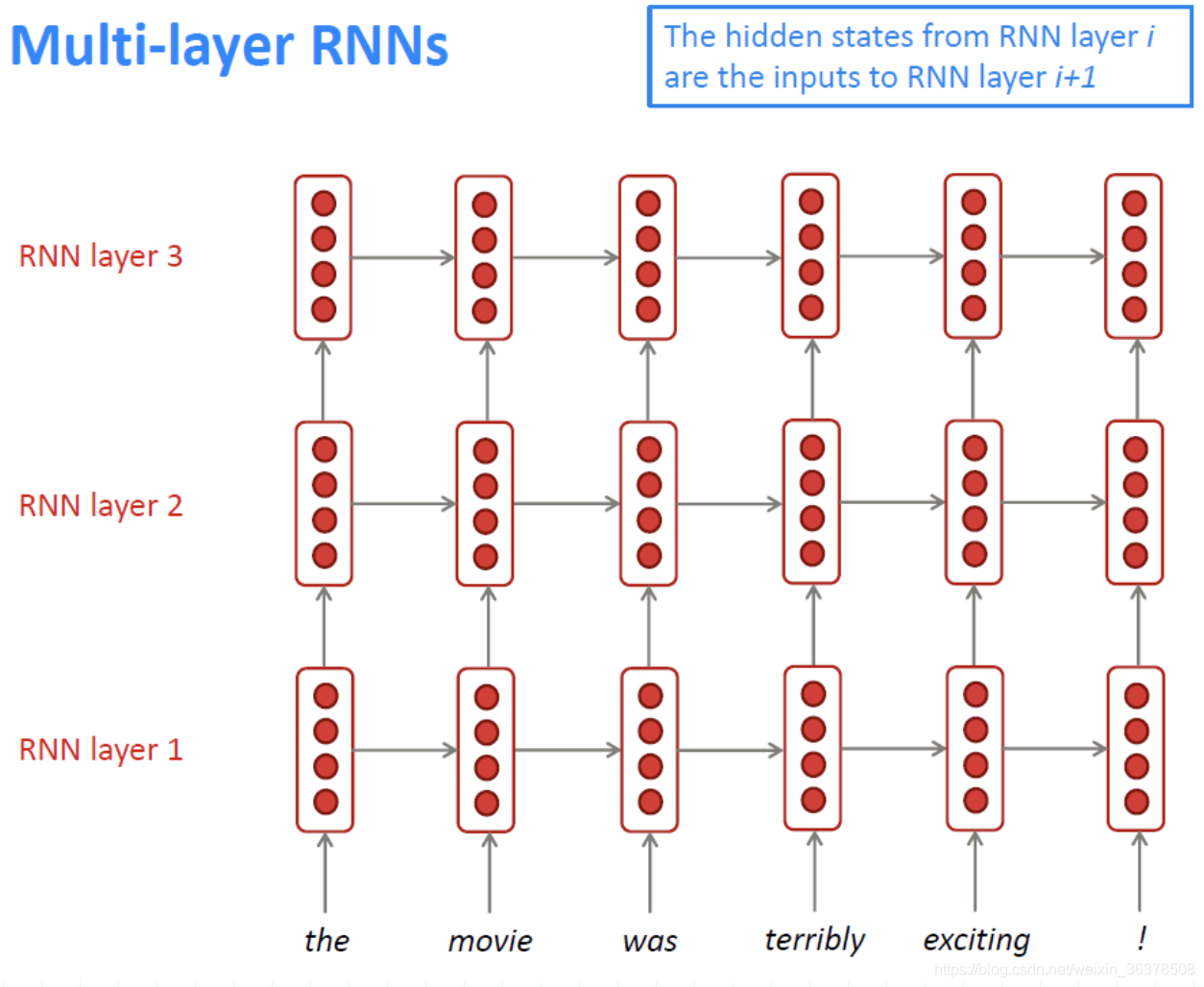
多层RNN(Multi-layer RNNs)
Multi-layer RNNs也可以称为Stacked RNNs,就是堆叠起来的一堆RNN嘛。这个更加无需更多解释,相当于神经网络加深:

















 1707
1707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









