







目录
作业基本要求
数据来源
经济管理中通常有大量的数据以csv等结构化格式存在,如本次作业要用的空气质量数据。数据见在线平台,格式说明如https://archive.ics.uci.edu/ml/datasets/Beijing+Multi-Site+Air-Quality+Data
其他要求
1. 至少实现一个数据分析类,以提供数据的读取及基本的时间(如某区域某类型污染物随时间的变化)和空间分析(某时间点或时间段北京空气质量的空间分布态势)方法。
2. 至少实现一个数据可视化类,以提供上述时空分析结果的可视化,如以曲线、饼、地图等形式对结果进行呈现。
3. 如果数据中包含空值等异常值(可人工注入错误数据以测试异常抛出与处理的逻辑),在进行数据分析以及可视化前需要检查数据。因此需要实现NotNumError类,继承ValueError,并加入新属性region, year,month,day,hour,pollutant,对数据进行检测,若取到的一列数据中包含空值等明显错误,则抛出该异常,并提供异常信息。在此基础上,利用try except捕获该异常,打印异常信息,并对应位置的数据进行适当的填充。
4. (附加)污染物含量与气象状态本身是否有相关性?请丰富数据分析类和数据可视化类,增加关于这些相关性探索的方法。
5. (附加)思考不同区域时间变化的趋势及差异的管理意义。
一、源代码
from pyecharts import Line,Pie,Map
import pandas as pd
import numpy as np
from seaborn.matrix import heatmap #绘制热力图
import matplotlib.pyplot as plt
from pyecharts.charts import Geo
from pyecharts import options as opts
from pyecharts.globals import GeoType
import pyecharts
class Data_ana:
'''这是一个提高数据读取操作的类'''
def __init__(self,path_list,station_list):
'''初始化传入一个路径列表和检测站列表'''
self.path_list = path_list
self.station_list = station_list
def read_csv(self,station):
'''这是一个根据传入的监测站,读入对应csv文件的函数'''
i = self.station_list.index(station)
df = pd.read_csv(self.path_list[i],header=0)
return df
def time_ana(self,station,pollutant):
pass
def area_ana(self,time):
pass
class Data_plt:
'''数据可视化类'''
def __init__(self,path_list,station_list):
'''初始化,把路径和检查站名称列表传入'''
self.path_list = path_list
self.station_list = station_list
def station_pollutant_graph(self,station,pollutant):
'''绘制出某一个检测站某种污染物随时间的变化'''
A = Data_ana(self.path_list, self.station_list)
df = A.read_csv(station)
data_array = np.array(df)
data_list =data_array.tolist() #将dataframe转化为list
time_list = []
num_list = []
row_name = ['No','year','month','day','hour','PM2.5','PM10','SO2','NO2','CO','O3','TEMP','PRES','DEWP','RAIN','wd','WSPM','station']
index1 = row_name.index(pollutant)
for i in data_list[1:1000]:
time_list.append(str(i[1])+'.'+str(i[2])+'.'+str(i[3])+'.'+str(i[4])) #对应的时间
num_list.append(i[index1]) #对应的值
line = Line("在{},{}随着时间的变化折线图".format(station,pollutant))
line.add(station, time_list, num_list, mark_point=["average"])
line.render()
def time_station_pie(self,time_str,station):
'''绘制在某一时间下,某一检测站不同污染物的占比的饼图'''
A = Data_ana(self.path_list, self.station_list)
df = A.read_csv(station)
data_array = np.array(df)
data_list =data_array.tolist() #将dataframe转化为list
time = time_str.split('.')
year = int(time[0]);month = int(time[1]);day = int(time[2]);hour = int(time[3])
i = 0;flag = 1
while i < len(data_list) and flag == 1:
if year == data_list[i][1] and month == data_list[i][2] and day == data_list[i][3] and hour == data_list[i][4]:
num_list = data_list[i][5:11]
flag = 0
i = i + 1
pollutants = ['PM2.5','PM10','SO2','NO2','CO','O3']
pie = Pie('{}{}'.format(station,time_str))
pie.add("", pollutants, num_list, is_label_show=True)
pie.render()
def bj_time_pollutant_map(self,time_str,pollutant):
'''传入时间和污染物,在北京地图上绘制不同检查站的数据'''
values = []
A = Data_ana(self.path_list, self.station_list) #将A实例化为第一个类
row_name = ['No','year','month','day','hour','PM2.5','PM10','SO2','NO2','CO','O3','TEMP','PRES','DEWP','RAIN','wd','WSPM','station']
index1 = row_name.index(pollutant) #找出我们选定的污染物在数据中的列数
time = time_str.split('.')
year = int(time[0]);month = int(time[1]);day = int(time[2]);hour = int(time[3]) #将我们传入的数据分割
for station in self.station_list: #对每个监测站进行遍历
df = A.read_csv(station)
data_array = np.array(df)
data_list =data_array.tolist() #由dataframe转化为list
i = 0;flag = 1
while i < len(data_list) and flag == 1:
#对比时间
if year == data_list[i][1] and month == data_list[i][2] and day == data_list[i][3] and hour == data_list[i][4]:
value = data_list[i][index1]
values.append(value)
flag = 0
i = i + 1
#下面开始地图绘制环节
city = '北京'
g = pyecharts.charts.Geo()
g.add_schema(maptype=city)
# 定义坐标对应的名称,添加到坐标库中 add_coordinate(name, 经度, 纬度)
g.add_coordinate('奥体中心', 116.401665, 39.985069)
g.add_coordinate('昌平', 116.23128, 40.22077)
g.add_coordinate('定陵', 116.10098901489258, 40.36113569243784)
g.add_coordinate('东四', 116.42371240356445, 39.92600162086124)
g.add_coordinate('官园', 116.35916772583008, 39.93495273529134)
g.add_coordinate('古城', 116.197319, 39.908829)
g.add_coordinate('怀柔', 116.64601388671875, 40.32397764738031)
g.add_coordinate('农展馆', 116.46147790649414, 39.94127046425559)
g.add_coordinate('顺义', 116.66146341064453, 40.15966193736629)
g.add_coordinate('天坛', 116.41189990551759, 39.88038235336456)
g.add_coordinate('万柳', 116.28929076702882, 39.972465789671865)
g.add_coordinate('万寿西宫', 116.35602412731934, 39.878933304535224)
data_pair = []
#通过一个循环,得到一个数据对
for i in range(len(values)):
data_pair.append((self.station_list[i],values[i]))
# 将数据添加到地图上
g.add('', data_pair, type_=GeoType.EFFECT_SCATTER, symbol_size=7)
# 设置样式
g.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
# 自定义分段 color 可以用取色器取色
pieces = [
{'max': 1, 'label': '0以下', 'color': '#50A3BA'},
{'min': 1, 'max': 10, 'label': '1-10', 'color': '#3700A4'},
{'min': 10, 'max': 20, 'label': '10-20', 'color': '#81AE9F'},
{'min': 20, 'max': 30, 'label': '20-30', 'color': '#E2C568'},
{'min': 30, 'max': 50, 'label': '30-50', 'color': '#FCF84D'},
{'min': 50, 'max': 100, 'label': '50-100', 'color': '#DD0200'},
{'min': 100, 'max': 200, 'label': '100-200', 'color': '#DD675E'},
{'min': 200, 'label': '200以上', 'color': '#D94E5D'} # 有下限无上限
]
# is_piecewise 是否自定义分段, 变为true 才能生效
g.set_global_opts(
visualmap_opts=opts.VisualMapOpts(is_piecewise=True, pieces=pieces),
title_opts=opts.TitleOpts(title="{},{}各地{}检测".format(time_str,city,pollutant)),
)
g.render()
def station_heatmap(self,station):
'''这是一个绘制不同变量相关系数热力图的函数'''
A = Data_ana(self.path_list, self.station_list)
df = A.read_csv(station)
df1 = df.iloc[:,1:]
heatmap(df1.corr(),annot = True,fmt = ".2f",vmax = 1,square = True, xticklabels = False,cmap = "Reds",annot_kws={'size':7})
class NotNumError(Exception): #NotNumError类,用来检验是否有空值
def __init__(self,station_list,pollutants,station,df):
'''初始化函数'''
self.station_list = station_list
self.pollutants = pollutants
self.station = station
self.df = df
def check(self):
'''检查函数,传入一个dataframe'''
data_array = np.array(self.df)
data_list =data_array.tolist() #由dataframe转化为list
flag = 0
for row in data_list:
for index in range(len(row)):
if row[index] == None:
self.message = f'在{self.station}监测站,第{row[0]}行,第{index+1}个数据为空'
flag = 1
if flag == 0:
self.message = '没有错误'
def __str__(self):
'''抛出异常信息的初始化函数'''
return self.message #抛出异常实例
def main():
path_list = ["D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Aotizhongxin_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Changping_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Dingling_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Dongsi_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Guanyuan_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Gucheng_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Huairou_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Nongzhanguan_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Shunyi_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Tiantan_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Wanliu_20130301-20170228.csv",
"D:\学习文件\大三上\现代程序设计\第七次作业\PRSA_Data_20130301-20170228\PRSA_Data_Wanshouxigong_20130301-20170228.csv"]
row_name = ['No','year','month','day','hour','PM2.5','PM10','SO2','NO2','CO','O3','TEMP','PRES','DEWP','RAIN','wd','WSPM','station']
station_list = ['奥体中心','昌平','定陵','东四','官园','古城','怀柔','农展馆','顺义','天坛','万柳','万寿西宫']
PLT = Data_plt(path_list, station_list)
#PLT.station_heatmap('奥体中心')
PLT.station_pollutant_graph('奥体中心','PM2.5')
#PLT.bj_time_pollutant_map('2015.10.20.12','NO2')
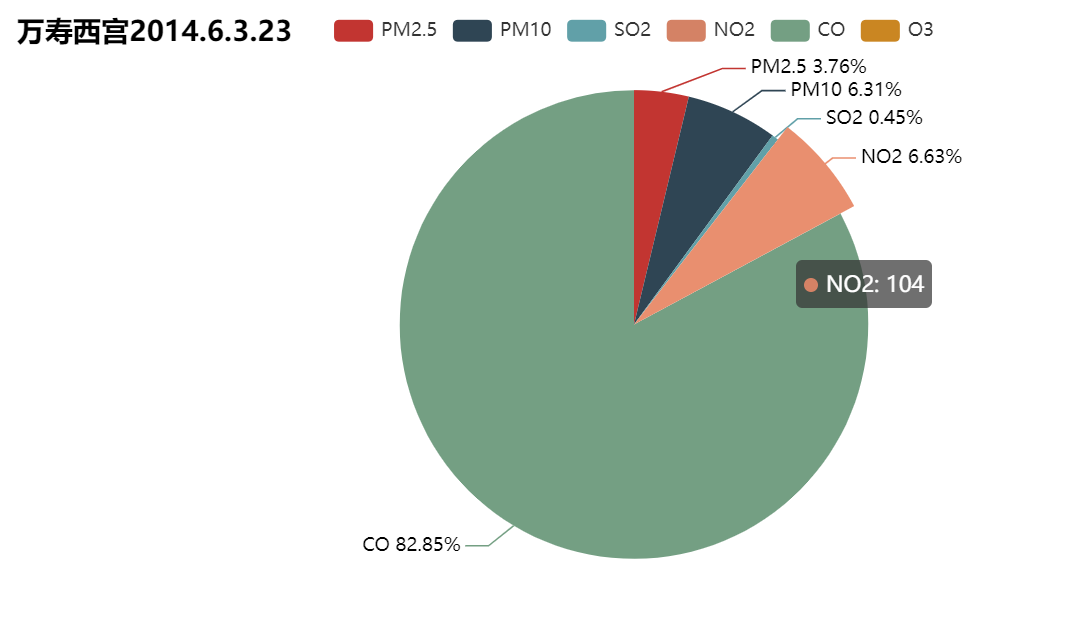
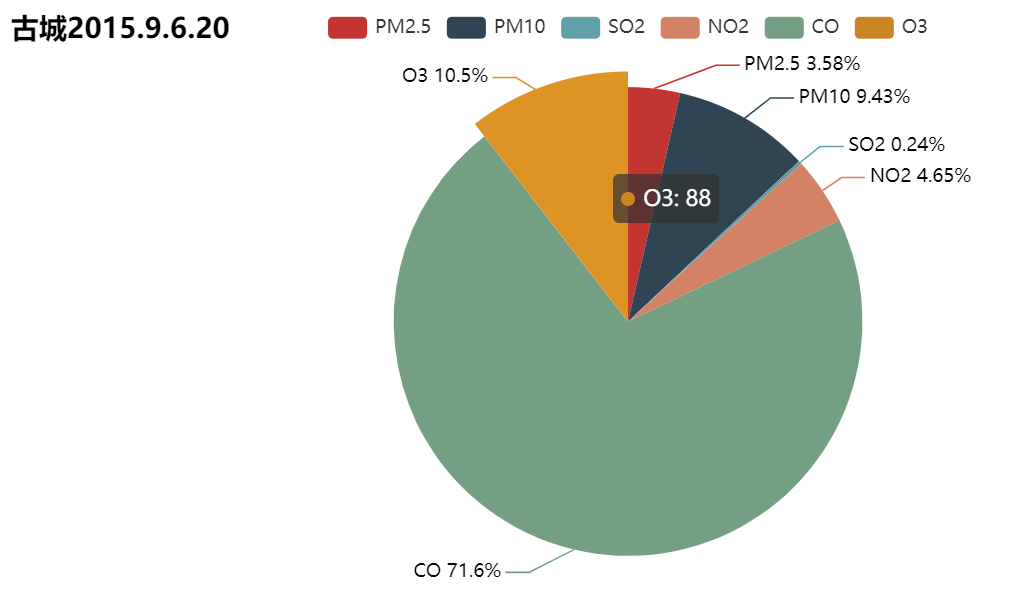
PLT.time_station_pie('2015.9.6.20','古城')
main()二、可视化展示
1.绘制随时间变化曲线图
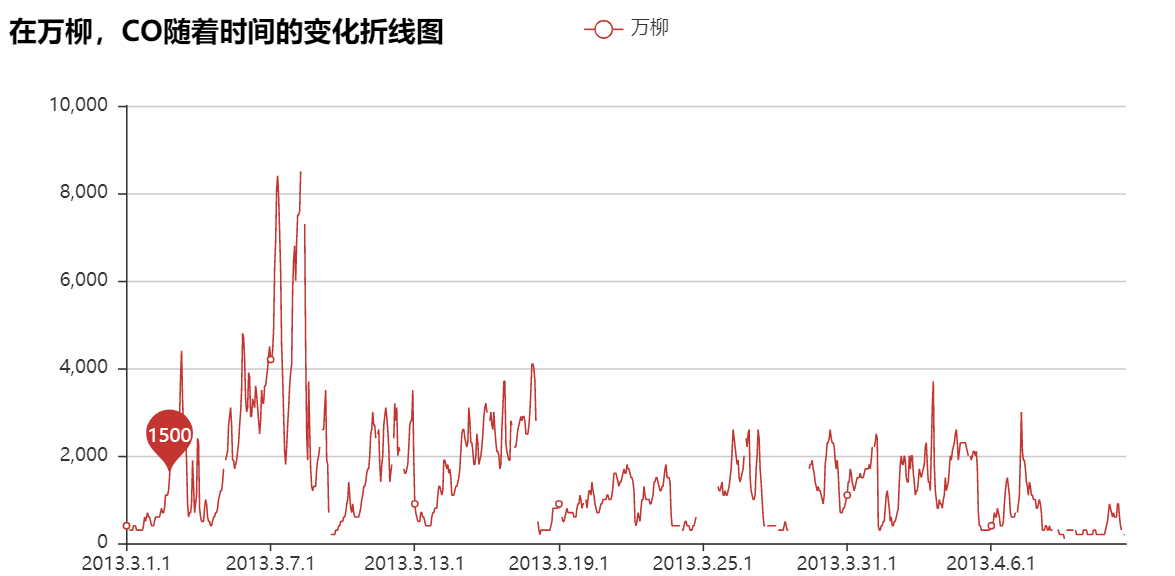
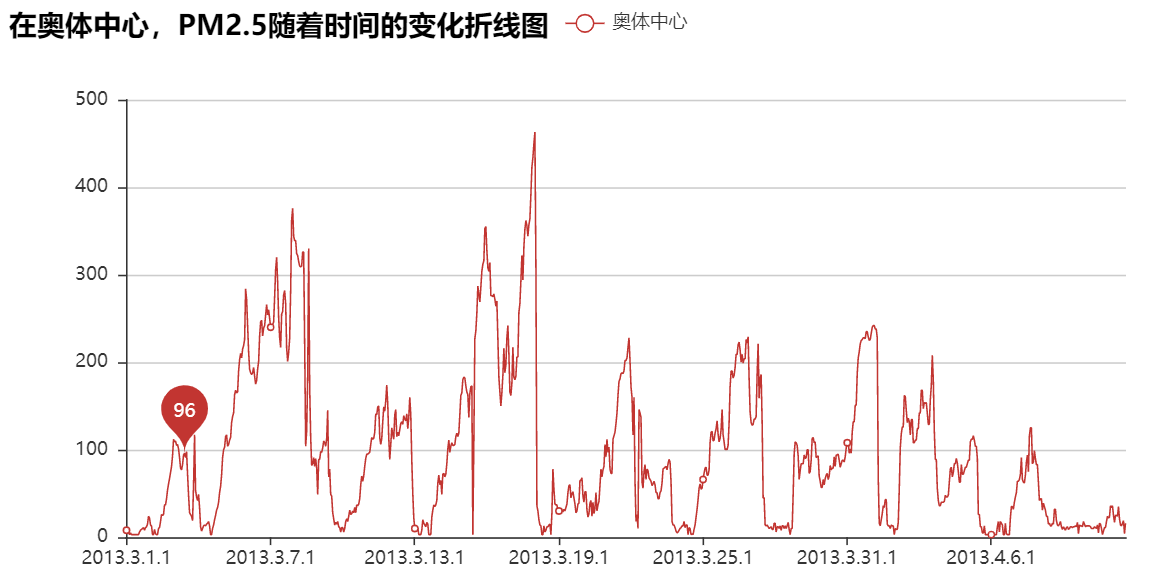
2.绘制某一时点下污染物占比
3.绘制北京地图下的各个检测站污染情况

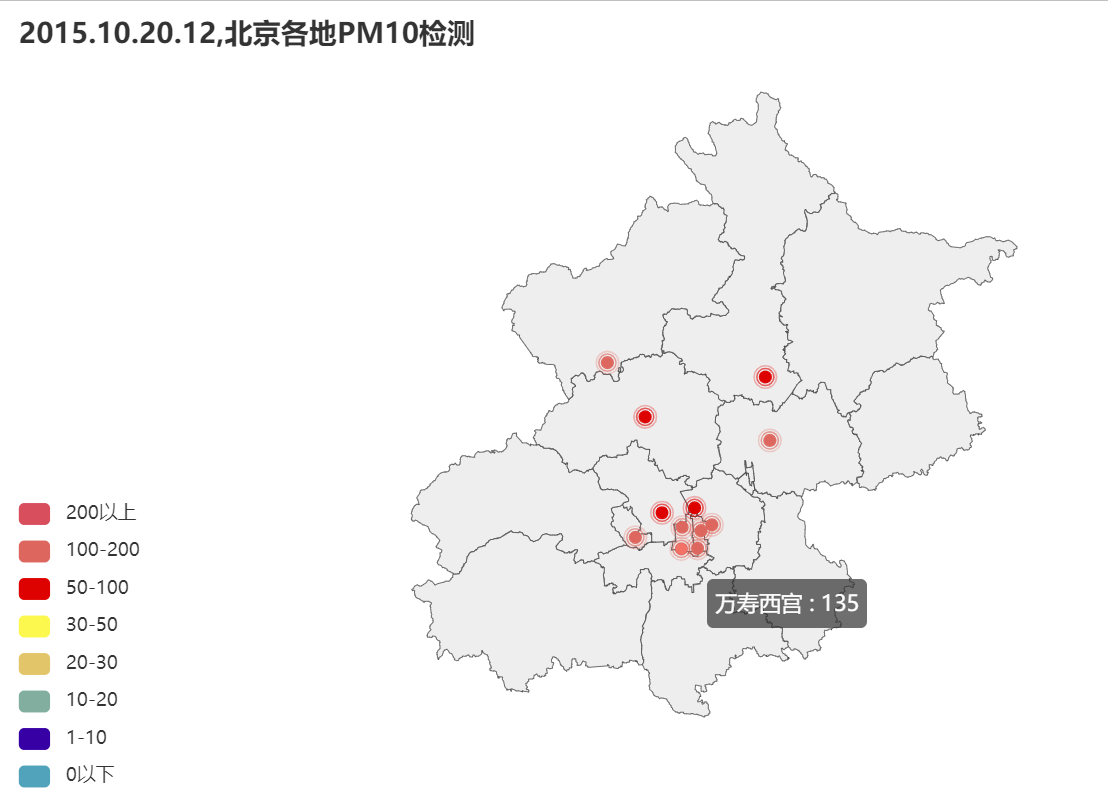 4.分析变量之间的相关性(污染物含量与气象状态)
4.分析变量之间的相关性(污染物含量与气象状态)
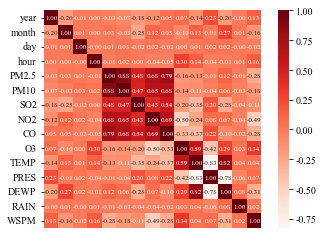
在RAIN(雨天),WSPM9(风速)大的情况下,污染情况都比较小
'PM2.5','PM10','SO2','NO2','CO’这五类污染物之间相关性比较强,尤其是PM2.5和PM10
O3比较独立

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









