






习题5-2 证明宽卷积具有交换性,即公式(5.13)
现有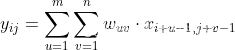
根据宽卷积定义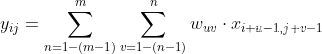
为了让x的下标形式和w的进行对换,进行变量替换
令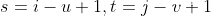
故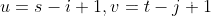
则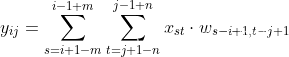
已知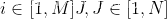
因此对于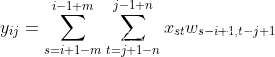
由于宽卷积的条件,s和t的变动范围是可行的。
习题5-3 分析卷积神经网络中用1×1的卷积核的作用
1、降维
比如,一张100 100且厚度depth为100 的图片在50个filter上做11的卷积,那么结果的大小为10010050。
2、升维(用最少的参数拓宽网络channal)
例子:64的卷积核的channel是64,只需添加一个11,256的卷积核,只用64256个参数就能把网络channel从64拓宽4倍到256。
3、加入非线性。
卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励,提升网络的表达能力。
习题5-4 对于一个输入为100×100×256的特征映射组,使用3×3的卷积核,输出为100×100×256的特征映射组的卷积层,求其时间和空间复杂度。如果引入一个1×1的卷积核,先得到100×100×64的特征映射,再进行3×3的卷积,得到100×100×256的特征映射组,求其时间和空间复杂度。
时间复杂度:时间复杂度即模型的运行次数。
单个卷积层的时间复杂度:Time~O(M^2 * K^2 * Cin * Cout)
M:输出特征图(Feature Map)的尺寸。
K:卷积核(Kernel)的尺寸。
Cin:输入通道数。
Cout:输出通道数。
注:每一层卷积都包含一个偏置参数(bias),这里也给忽略了。加上的话时间复杂度则为:O(M^2 * K^2 * Cin * Cout+Cout)。
空间复杂度:空间复杂度即模型的参数数量。1125664+10010064+3364256+100100256
单个卷积的空间复杂度:Space~O(K^2 * Cin * Cout+M^2*Cout)
①:时间复杂度=10010033**256256=5898240000
空间复杂度=3*3**256*256+100*100*256=3149824
②:时间复杂度=1001001125664+1001003364256=1638400000
空间复杂度=1*1*256*64+100*100*64+3*3*64*256+100*100*256=3363840
习题5-7 忽略激活函数,分析卷积网络中卷积层的前向计算和反向传播是一种转置关系。

CNN反向传播
误差传播:
参数更新规则:梯度下降法,公式如下:
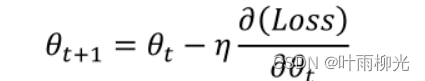
定义误差项δ,如下: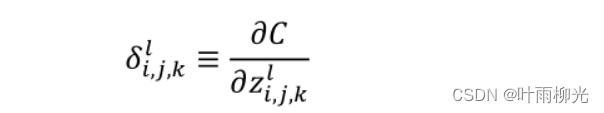
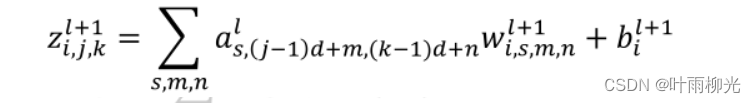
l代表卷积神经网络第l层, j、k表示其特征向量第j行,第k列。w表示权重,i对应下一层神经元特征向量个数,s代表上一层特征向量个数,m、n表示一个卷积核第(m,n)个的值,b为偏置,z为该层神经元输入,a为该层神经元输出。
由链式求导法则,得误差传播过程为:
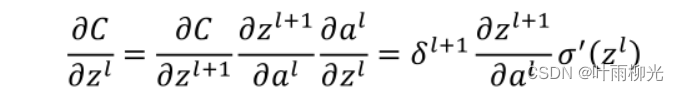
这里的式子其实和DNN的类似,区别在于对于含有卷积的式子求导时,卷积核被旋转了180度。即式子中的rot180(),翻转180度的意思是上下翻转一次,接着左右翻转一次。在DNN中这里只是矩阵的转置。那么为什么呢?由于这里都是张量,直接推演参数太多了。我们以一个简单的例子说明为啥这里求导后卷积核要翻转。
假设我们l−1层的输出al−1是一个3x3矩阵,第l层的卷积核Wl是一个2x2矩阵,采用1像素的步幅,则输出zl是一个2x2的矩阵。我们简化bl都是0,则有
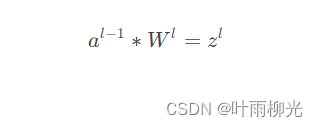
我们列出a,W,z的矩阵表达式如下:
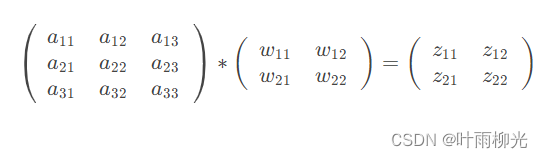
利用卷积的定义,很容易得出:
z11=a11w11+a12w12+a21w21+a22w22
z12=a12w11+a13w12+a22w21+a23w22
z21=a21w11+a22w12+a31w21+a32w22
z22=a22w11+a23w12+a32w21+a33w22
接着我们模拟反向求导:
*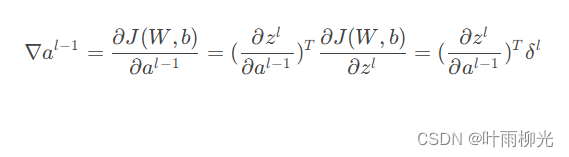
从上式可以看出,对于al−1的梯度误差∇al−1,等于第l层的梯度误差乘以∂zl∂al−1,而∂zl∂al−1对应上面的例子中相关联的w的值。假设我们的z矩阵对应的反向传播误差是δ11,δ12,δ21,δ22组成的2x2矩阵,则利用上面梯度的式子和4个等式,我们可以分别写出∇al−1的9个标量的梯度。
得误差传递公式:
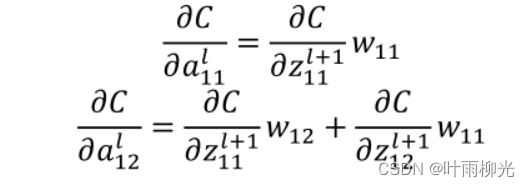
这里附上链接https://www.cnblogs.com/pinard/p/6494810.html
设计简易CNN模型,分别用Numpy、Pytorch实现卷积层和池化层的反向传播算子,并代入数值测试.(选做)
import numpy as np
def padding(X, pad):
X_pad = np.pad(X, (
(0, 0),
(pad, pad),
(pad, pad),
(0, 0)),
mode='constant', constant_values=(0, 0))
return X_pad
def conv_single_step(a_slice_prev, W, b):
s = np.multiply(a_slice_prev, W)
Z = np.sum(s)
Z = Z + float(b)
return Z
def conv_forward(A_prev, W, b, hparameters):
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
(f, f, n_C_prev, n_C) = W.shape
stride = hparameters['stride']
pad = hparameters['pad']
n_H = int((n_H_prev + 2 * pad - f) / stride) + 1
n_W = int((n_W_prev + 2 * pad - f) / stride) + 1
Z = np.zeros((m, n_H, n_W, n_C))
A_prev_pad = padding(A_prev, pad)
for i in range(m): # 依次遍历每个样本
a_prev_pad = A_prev_pad[i] # 获取当前样本
for h in range(n_H): # 在输出结果的垂直方向上循环
for w in range(n_W): # 在输出结果的水平方向上循环
# 确定分片边界
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
for c in range(n_C):
a_slice_prev = a_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :]
weights = W[:, :, :, c]
biases = b[:, :, :, c]
Z[i, h, w, c] = conv_single_step(a_slice_prev, weights, biases)
assert (Z.shape == (m, n_H, n_W, n_C))
mask = (A_prev, W, b, hparameters)
return Z, mask
def backward(theta, mask):
(A_prev, W, b, hparameters) = mask
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
(f, f, n_C_prev, n_C) = W.shape
stride = hparameters['stride']
pad = hparameters['pad']
(m, n_H, n_W, n_C) = theta.shape
dA_prev = np.zeros_like(A_prev)
dW = np.zeros_like(W)
db = np.zeros_like(b)
A_prev_pad = padding(A_prev, pad)
dA_prev_pad = padding(dA_prev, pad)
for i in range(m):
a_prev_pad = A_prev_pad[i]
da_prev_pad = dA_prev_pad[i]
for h in range(n_H):
for w in range(n_W):
for c in range(n_C):
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
a_slice = a_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :]
da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:, :, :, c] * theta[i, h, w, c]
dW[:, :, :, c] += a_slice * theta[i, h, w, c]
db[:, :, :, c] += theta[i, h, w, c]
dA_prev[i, :, :, :] = da_prev_pad[pad:-pad, pad:-pad, :]
assert (dA_prev.shape == (m, n_H_prev, n_W_prev, n_C_prev))
return dA_prev, dW, db
A_prev = np.random.randn(10, 4, 4, 3)
W = np.random.randn(2, 2, 3, 8)
b = np.random.randn(1, 1, 1, 8)
hparameters = {"pad": 2,
"stride": 2}
Z, mask_conv = conv_forward(A_prev, W, b, hparameters)
dA, dW, db = backward(Z, mask_conv)
print("卷积层卷积核参数反向传播的梯度:", dW)
print("卷积层偏置项反向传播的梯度:", db)
卷积层卷积核参数反向传播的梯度: [[[[ 24.46993556 67.48514002 -38.62247492 11.71810996
136.05647178 53.61172008 -11.17085223 -16.70240528]
[ -21.13216474 26.92151364 -66.03969944 12.89381138
8.8949686 53.08811601 89.00863725 -20.07174484]
[ 3.52904589 -4.70198615 44.42749098 27.68001942
-37.03866503 16.64156566 -20.11960752 -3.27642925]]
[[ -41.18779959 8.41305075 -52.35345346 -46.51516058
48.20203089 4.82454353 20.35719883 35.94198231]
[ 30.42150901 90.63882904 -25.95882993 8.62160859
108.48051936 54.34444806 -11.97409565 -15.28450426]
[ -53.60374511 -80.05025739 58.67535411 5.86996875
-38.90601022 6.92952065 -56.93950176 10.95374156]]]
[[[ 11.04295674 -51.29538567 -78.34533783 -29.88166331
48.53786758 -55.61498217 70.91304834 -2.98148387]
[ 15.67013671 101.9608459 -25.78512253 46.2113692
0.79111516 51.83057976 4.25198298 -76.55831864]
[ -15.95251537 -26.32560063 70.03015637 -61.38480126
-61.27283794 16.83619186 -88.33035642 101.64997559]]
[[ -28.2116401 -2.21187936 40.87145309 -36.82654332
-92.74568755 10.0069149 47.36069285 42.3576569 ]
[ -13.59411912 42.15270286 -54.6036216 21.53819946
29.12158802 33.25062589 -4.03293776 9.83912874]
[ 20.6598245 -46.63713292 -48.39657288 113.71349443
-107.23204237 -8.60012475 7.94910473 -64.88493673]]]]
卷积层偏置项反向传播的梯度: [[[[ -55.79936968 -90.66820199 -175.22062232 53.58215445
119.26937661 -93.45780871 -115.32030921 -56.94879437]]]]
import numpy as np
def mask1(x):
mask = (x == np.max(x))
return mask
def distribute_value(dz, shape):
(n_H, n_W) = shape
average = dz / (n_H * n_W)
a = np.ones(shape) * average
return a
def pool_forward(A_prev, hparameters, mode="max"):
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
f = hparameters["f"]
stride = hparameters["stride"]
# 计算输出数据的维度
n_H = int(1 + (n_H_prev - f) / stride)
n_W = int(1 + (n_W_prev - f) / stride)
n_C = n_C_prev
# 定义输出结果
A = np.zeros((m, n_H, n_W, n_C))
# 逐个计算,对A的元素进行赋值
for i in range(m): # 遍历样本
for h in range(n_H): # 遍历n_H维度
# 确定分片垂直方向上的位置
vert_start = h * stride
vert_end = vert_start + f
for w in range(n_W): # 遍历n_W维度
# 确定分片水平方向上的位置
horiz_start = w * stride
horiz_end = horiz_start + f
for c in range(n_C): # 遍历通道
# 确定当前样本上的分片
a_prev_slice = A_prev[i, vert_start:vert_end, horiz_start:horiz_end, c]
# 根据池化方式,计算当前分片上的池化结果
if mode == "max": # 最大池化
A[i, h, w, c] = np.max(a_prev_slice)
elif mode == "average": # 平均池化
A[i, h, w, c] = np.mean(a_prev_slice)
# 将池化层的输入和超参数缓存
cache = (A_prev, hparameters)
# 确保输出结果维度正确
assert (A.shape == (m, n_H, n_W, n_C))
return A, cache
def pool_backward(dA, cache, mode="max"):
(A_prev, hparameters) = cache
stride = hparameters['stride']
f = hparameters['f']
m, n_H_prev, n_W_prev, n_C_prev = A_prev.shape
m, n_H, n_W, n_C = dA.shape
# 对输出结果进行初始化
dA_prev = np.zeros_like(A_prev)
for i in range(m): # 遍历m个样本
a_prev = A_prev[i]
for h in range(n_H): # 在垂直方向量遍历
for w in range(n_W): # 在水平方向上循环
for c in range(n_C): # 在通道上循环
# 找到输入的分片的边界
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
# 根据池化方式选择不同的计算过程
if mode == "max":
# 确定输入数据的切片
a_prev_slice = a_prev[vert_start:vert_end, horiz_start:horiz_end, c]
# 创建掩码
mask = mask1(a_prev_slice)
# 计算dA_prev
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += np.multiply(mask, dA[i, h, w, c])
elif mode == "average":
# 获取da值, 一个实数
da = dA[i, h, w, c]
shape = (f, f)
# 反向传播
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += distribute_value(da, shape)
assert (dA_prev.shape == A_prev.shape)
return dA_prev
np.random.seed(1)
A_prev = np.random.randn(5, 5, 3, 2)
hparameters = {"stride": 1, "f": 2}
A, cache = pool_forward(A_prev, hparameters)
dA = np.random.randn(5, 4, 2, 2)
dA_prev = pool_backward(dA, cache, mode="max")
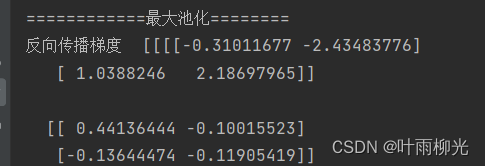
print("============最大池化========")
print('反向传播梯度 ', dA)
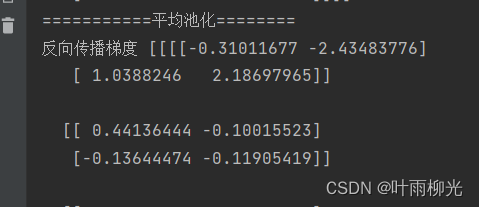
dA_prev = pool_backward(dA, cache, mode="average")
print("===========平均池化========")
print('反向传播梯度', dA)















 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









