






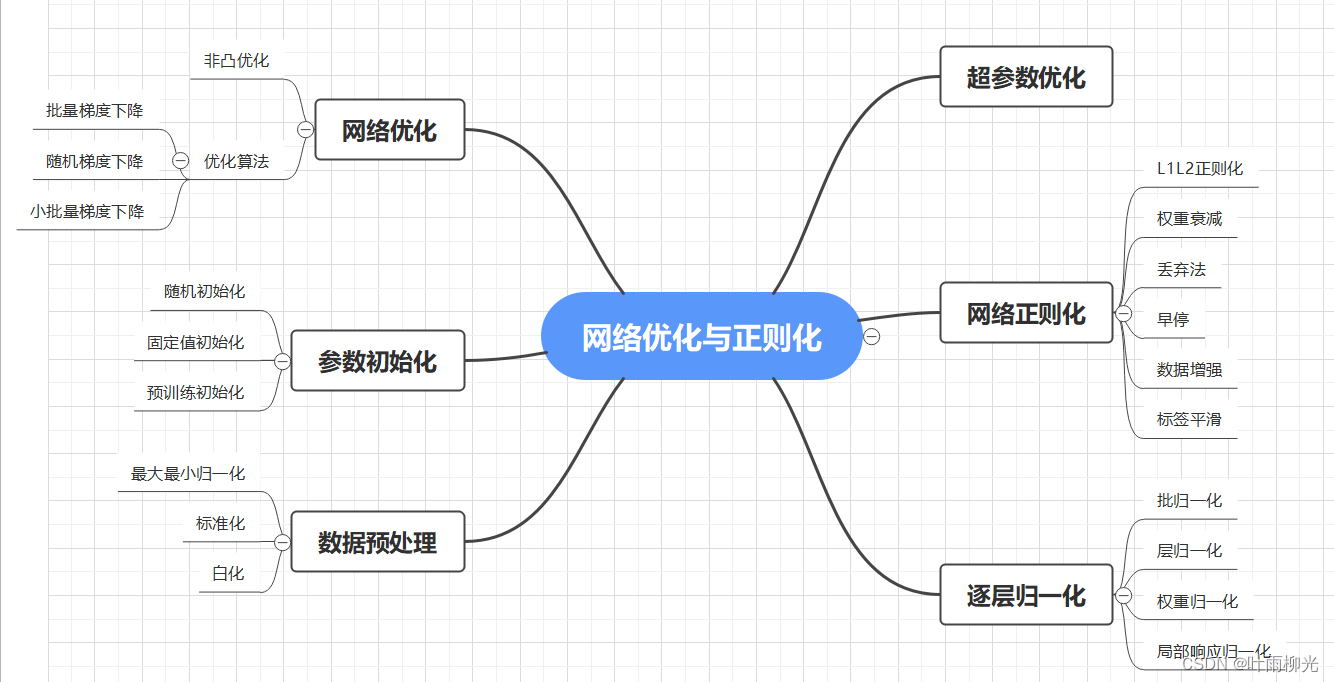
NNDL 作业12:第七章课后题
习题7-1 在小批量梯度下降中,试分析为什么学习率要和批量大小成正比
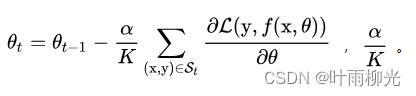
批量越大方差越小,引入的噪声越小,训练稳定,可以设置较大学习率,批量小时,学习率也变小,否则不收敛。所以一般成正比。
习题7-2 在Adam算法中,说明指数加权平均的偏差修正的合理性

习题7-9 证明在标准的随机梯度下降中,权重衰减正则化和L_{2}正则化的效果相同.并分析这一结论在动量法和Adam算法中是否依然成立
正则化可以定义为我们为了减少泛化误差而不是减少训练误差而对训练算法所做的任何改变。有许多正规化策略。有的对模型添加额外的约束,如对参数值添加约束,有的对目标函数添加额外的项,可以认为是对参数值添加间接或软约束。如果我们仔细使用这些技术,这可以改善测试集的性能。在深度学习的环境中,大多数正则化技术都基于正则化估计器。
L2正则化梯度更新的方向取决于最近一段时间内梯度的加权平均值。
当与自适应梯度相结合时(动量法和Adam算法),
L2正则化导致导致具有较大历史参数 (和/或) 梯度振幅的权重被正则化的程度小于使用权值衰减时的情况。
L2正则化属于正则化技术的一类,称为参数范数惩罚。之所以提到这类技术,是因为在这类技术中,特定参数的范数(主要是权重)被添加到被优化的目标函数中。在L2范数中,在网络的损失函数中加入一个额外的项,通常称为正则化项。那L2正则化和权重衰减是一回事吗?其实L2正则化和权值衰减并不是一回事,但是可以根据学习率对权值衰减因子进行重新参数化,从而使SGD等价。
以λ为衰减因子,给出了权值衰减方程。

在以下证明中可以证明L2正则化等价于SGD情况下的权值衰减:
1.我们先看一下L2正则化方程
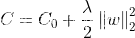
我再对正则化方程进行求导操作
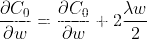
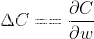
在得到损失函数的偏导数结果后,将结果代入梯度下降学习规则中,如下式所示。
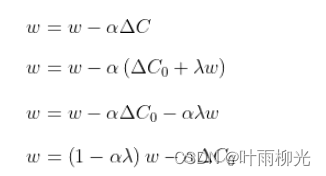
最终重新排列的L2正则化方程和权值衰减方程之间的唯一区别是α(学习率)乘以λ(正则化项)。为了得到两个方程,我们用λ来重新参数化L2正则化方程。
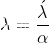
将λ’替换为λ,对L2正则化方程进行重新参数化,将其等价于权值衰减方程,如下式所示
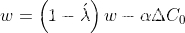
where
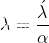
从上面的证明中,你必须理解为什么L2正则化在SGD情况下被认为等同于权值衰减,但对于其他基于自适应梯度的优化算法,如Adam, AdaGrad等,却不是这样。特别是,当与自适应梯度相结合时,L2正则化导致具有较大历史参数和/或梯度振幅的权值比使用权值衰减时正则化得更少。这导致与SGD相比,当使用L2正则化时adam表现不佳。另一方面,权值衰减在SGD和Adam身上表现得一样好。
参考:权值衰减和L2正则化是一回事吗?
总结















 1179
1179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









