






基于LeNet实现手写体数字识别实验
5.3.1数据
手写体数字识别是计算机视觉中最常用的图像分类任务,让计算机识别出给定图片中的手写体数字(0-9共10个数字)。由于手写体风格差异很大,因此手写体数字识别是具有一定难度的任务。
我们采用常用的手写数字识别数据集:MNIST数据集。
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
MNIST数据集是计算机视觉领域的经典入门数据集,包含了60,000个训练样本和10,000个测试样本。
这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28×28像素)。
为了节省训练时间,本节选取MNIST数据集的一个子集进行后续实验,数据集的划分为:
训练集:1,000条样本
验证集:200条样本
测试集:200条样本
MNIST数据集分为train_set、dev_set和test_set三个数据集,每个数据集含两个列表分别存放了图片数据以及标签数据。比如train_set包含:
图片数据:[1 000, 784]的二维列表,包含1 000张图片。每张图片用一个长度为784的向量表示,内容是 28×2828×28 尺寸的像素灰度值(黑白图片)。
标签数据:[1 000, 1]的列表,表示这些图片对应的分类标签,即0~9之间的数字。
观察数据集分布情况,代码实现如下:
import json
import gzip
# 打印并观察数据集分布情况
train_set, dev_set, test_set = json.load(gzip.open('./mnist.json.gz'))
train_images, train_labels = train_set[0][:1000], train_set[1][:1000]
dev_images, dev_labels = dev_set[0][:200], dev_set[1][:200]
test_images, test_labels = test_set[0][:200], test_set[1][:200]
train_set, dev_set, test_set = [train_images, train_labels], [dev_images, dev_labels], [test_images, test_labels]
print('Length of train/dev/test set:{}/{}/{}'.format(len(train_set[0]), len(dev_set[0]), len(test_set[0])))

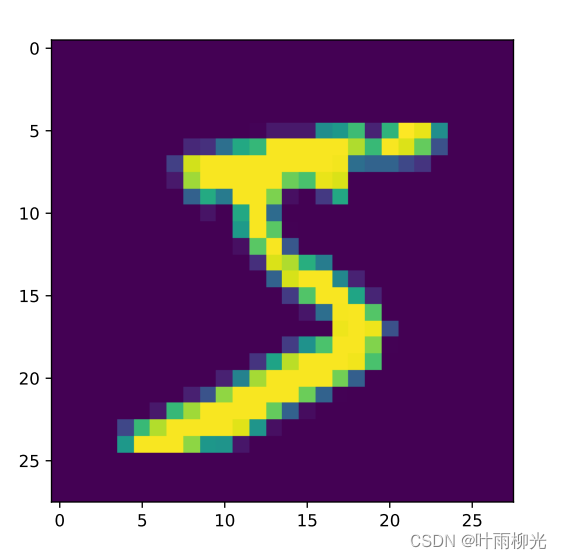
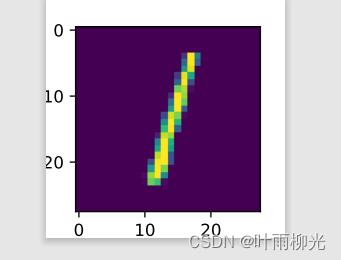
可视化观察其中的一张样本以及对应的标签,代码如下所示:
import numpy as np
import matplotlib.pyplot as plt
import PIL.Image as Image
image, label = train_set[0][0], train_set[1][0]
image, label = np.array(image).astype('float32'), int(label)
# 原始图像数据为长度784的行向量,需要调整为[28,28]大小的图像
image = np.reshape(image, [28,28])*255
image = Image.fromarray(image.astype('uint8'), mode='L')
print("The number in the picture is {}".format(label))
plt.figure(figsize=(5, 5))
plt.imshow(image)
plt.savefig('conv-number5.pdf')

5.3.1.1 数据预处理
图像分类网络对输入图片的格式、大小有一定的要求,数据输入模型前,需要对数据进行预处理操作,使图片满足网络训练以及预测的需要。本实验主要应用了如下方法:
调整图片大小:LeNet网络对输入图片大小的要求为 32×32 ,而MNIST数据集中的原始图片大小却是 28×28 ,这里为了符合网络的结构设计,将其调整为32×32;
规范化: 通过规范化手段,把输入图像的分布改变成均值为0,标准差为1的标准正态分布,使得最优解的寻优过程明显会变得平缓,训练过程更容易收敛。
代码如下所示:
import torchvision.transforms as transforms
from torch.utils.data import Dataset,DataLoader
# 数据预处理
transforms = transforms.Compose([transforms.Resize(32),transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5])])
class MNIST_dataset(Dataset):
def __init__(self, dataset, transforms, mode='train'):
self.mode = mode
self.transforms =transforms
self.dataset = dataset
def __getitem__(self, idx):
# 获取图像和标签
image, label = self.dataset[0][idx], self.dataset[1][idx]
image, label = np.array(image).astype('float32'), int(label)
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
image = self.transforms(image)
return image, label
def __len__(self):
return len(self.dataset[0])
# 加载 mnist 数据集
train_dataset = MNIST_dataset(dataset=train_set, transforms=transforms, mode='train')
test_dataset = MNIST_dataset(dataset=test_set, transforms=transforms, mode='test')
dev_dataset = MNIST_dataset(dataset=dev_set, transforms=transforms, mode='dev')
5.3.2 模型构建
这里的LeNet-5和原始版本有4点不同:
C3层没有使用连接表来减少卷积数量。
汇聚层使用了简单的平均汇聚,没有引入权重和偏置参数以及非线性激活函数。
卷积层的激活函数使用ReLU函数。
最后的输出层为一个全连接线性层。
网络共有7层,包含3个卷积层、2个汇聚层以及2个全连接层的简单卷积神经网络接,受输入图像大小为32×32=1024,输出对应10个类别的得分。
1.测试LeNet-5模型,构造一个形状为 [1,1,32,32]的输入数据送入网络,观察每一层特征图的形状变化。
import torch.nn.functional as F
import torch.nn as nn
class Model_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Model_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5×5
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5)
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5×5,步长为1
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool4 = nn.AvgPool2d(kernel_size=(2, 2), stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5×5
self.conv5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(120, 84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(84, num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, dim=3)
output = torch.squeeze(output, dim=2)
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return output
下面测试一下上面的LeNet-5模型,构造一个形状为 [1,1,32,32]的输入数据送入网络,观察每一层特征图的形状变化。代码实现如下:
# 这里用np.random创建一个随机数组作为输入数据
inputs = np.random.randn(*[1, 1, 32, 32])
inputs = inputs.astype('float32')
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
print(model)
# 通过调用LeNet从基类继承的sublayers()函数,查看LeNet中所包含的子层
print(model.named_parameters())
x = torch.tensor(inputs)
print(x)
for item in model.children():
# item是LeNet类中的一个子层
# 查看经过子层之后的输出数据形状
item_shapex = 0
names = []
parameter = []
for name in item.named_parameters():
names.append(name[0])
parameter.append(name[1])
item_shapex += 1
try:
x = item(x)
except:
# 如果是最后一个卷积层输出,需要展平后才可以送入全连接层
x = x.reshape([x.shape[0], -1])
x = item(x)
if item_shapex == 2:
# 查看卷积和全连接层的数据和参数的形状,
# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数b
print(item, x.shape, parameter[0].shape, parameter[1].shape)
else:
# 汇聚层没有参数
print(item, x.shape)
Model_LeNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(pool2): MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(pool4): AvgPool2d(kernel_size=(2, 2), stride=2, padding=0)
(conv5): Conv2d(16, 120, kernel_size=(5, 5), stride=(1, 1))
(linear6): Linear(in_features=120, out_features=84, bias=True)
(linear7): Linear(in_features=84, out_features=10, bias=True)
)
<generator object Module.named_parameters at 0x0000021A84B6EBA0>
tensor([[[[ 0.5429, -0.8290, 0.4323, ..., -0.6688, 2.3011, -0.2848],
[-1.7729, -0.4966, 0.7747, ..., 0.0077, -0.5124, 0.5942],
[-0.1660, 0.6238, 1.2487, ..., -0.4687, 2.0645, -1.1102],
...,
[ 1.2064, 0.1331, 0.8428, ..., 0.4045, -0.2459, 0.5491],
[ 0.6119, -0.2111, -1.1464, ..., -0.2260, 2.0758, 1.1377],
[-0.9793, -0.7080, -1.7508, ..., 1.1742, -0.0953, 0.2567]]]])
Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) torch.Size([1, 6, 28, 28]) torch.Size([6, 1, 5, 5]) torch.Size([6])
MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False) torch.Size([1, 6, 14, 14])
Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) torch.Size([1, 16, 10, 10]) torch.Size([16, 6, 5, 5]) torch.Size([16])
AvgPool2d(kernel_size=(2, 2), stride=2, padding=0) torch.Size([1, 16, 5, 5])
Conv2d(16, 120, kernel_size=(5, 5), stride=(1, 1)) torch.Size([1, 120, 1, 1]) torch.Size([120, 16, 5, 5]) torch.Size([120])
Linear(in_features=120, out_features=84, bias=True) torch.Size([1, 84]) torch.Size([84, 120]) torch.Size([84])
Linear(in_features=84, out_features=10, bias=True) torch.Size([1, 10]) torch.Size([10, 84]) torch.Size([10])
从输出结果看,
对于大小为32×32的单通道图像,先用6个大小为5×5的卷积核对其进行卷积运算,输出为6个28×28大小的特征图;
6个28×28大小的特征图经过大小为2×2,步长为2的汇聚层后,输出特征图的大小变为14×14;
6个14×14大小的特征图再经过16个大小为5×5的卷积核对其进行卷积运算,得到16个10×10大小的输出特征图;
16个10×10大小的特征图经过大小为2×2,步长为2的汇聚层后,输出特征图的大小变为5×5;
16个5×5大小的特征图再经过120个大小为5×5的卷积核对其进行卷积运算,得到120个1×1大小的输出特征图;
此时,将特征图展平成1维,则有120个像素点,经过输入神经元个数为120,输出神经元个数为84的全连接层后,输出的长度变为84。
再经过一个全连接层的计算,最终得到了长度为类别数的输出结果。
使用自定义算子,构建LeNet-5模型
自定义的Conv2D和Pool2D算子中包含多个for循环,所以运算速度比较慢。
使用pytorch中的相应算子,构建LeNet-5模型
torch.nn.Conv2d();torch.nn.MaxPool2d();torch.nn.avg_pool2d()
class Torch_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Torch_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5*5
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5*5
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5*5
self.conv5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(in_features=120, out_features=84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(in_features=84, out_features=num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, dim=3)
output = torch.squeeze(output, dim=2)
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return output
测试两个网络的运算速度。
import time
# 这里用np.random创建一个随机数组作为测试数据
inputs = np.random.randn(*[1,1,32,32])
inputs = inputs.astype('float32')
x = torch.tensor(inputs)
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
# 创建Torch_LeNet类的实例,指定模型名称和分类的类别数目
torch_model = Torch_LeNet(in_channels=1, num_classes=10)
# 计算Model_LeNet类的运算速度
model_time = 0
for i in range(60):
strat_time = time.time()
out = model(x)
end_time = time.time()
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
model_time += (end_time - strat_time)
avg_model_time = model_time / 50
print('Model_LeNet speed:', avg_model_time, 's')
# 计算Torch_LeNet类的运算速度
torch_model_time = 0
for i in range(60):
strat_time = time.time()
torch_out = torch_model(x)
end_time = time.time()
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
torch_model_time += (end_time - strat_time)
avg_torch_model_time = torch_model_time / 50
print('Torch_LeNet speed:', avg_torch_model_time, 's')

令两个网络加载同样的权重,测试一下两个网络的输出结果是否一致。
# 这里用np.random创建一个随机数组作为测试数据
inputs = np.random.randn(*[1,1,32,32])
inputs = inputs.astype('float32')
x = torch.tensor(inputs)
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
# 获取网络的权重
params = model.state_dict()
# 自定义Conv2D算子的bias参数形状为[out_channels, 1]
# torch API中Conv2D算子的bias参数形状为[out_channels]
# 需要进行调整后才可以赋值
for key in params:
if 'bias' in key:
params[key] = params[key].squeeze()
# 创建Torch_LeNet类的实例,指定模型名称和分类的类别数目
torch_model = Torch_LeNet(in_channels=1, num_classes=10)
# 将Model_LeNet的权重参数赋予给Torch_LeNet模型,保持两者一致
torch_model.load_state_dict(params)
# 打印结果保留小数点后6位
torch.set_printoptions(6)
# 计算Model_LeNet的结果
output = model(x)
print('Model_LeNet output: ', output)
# 计算Torch_LeNet的结果
torch_output = torch_model(x)
print('Torch_LeNet output: ', torch_output)
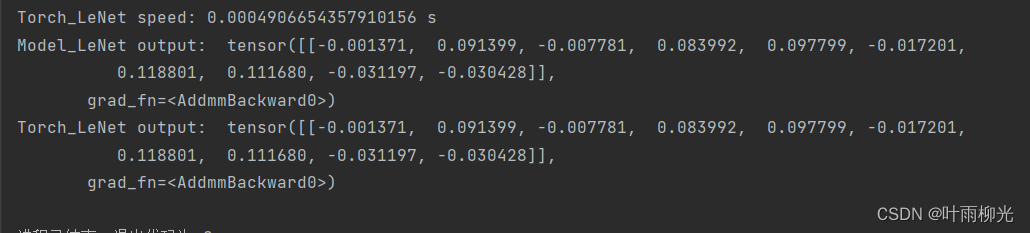
可以看到,输出结果是一致的。
这里还可以统计一下LeNet-5模型的参数量和计算量。
参数量
第一个卷积层的参数量为:6×1×5×5+6=156;
第二个卷积层的参数量为:16×6×5×5+16=2416;
第三个卷积层的参数量为:120×16×5×5+120=48120;
第一个全连接层的参数量为:120×84+84=10164;
第二个全连接层的参数量为:84×10+10=850;
所以,LeNet-5总的参数量为61706。
from torchsummary import summary
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # PyTorch v0.4.0
Torch_model= Torch_LeNet(in_channels=1, num_classes=10).to(device)
summary(Torch_model, (1,32, 32))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 156
MaxPool2d-2 [-1, 6, 14, 14] 0
Conv2d-3 [-1, 16, 10, 10] 2,416
AvgPool2d-4 [-1, 16, 5, 5] 0
Conv2d-5 [-1, 120, 1, 1] 48,120
Linear-6 [-1, 84] 10,164
Linear-7 [-1, 10] 850
================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.06
Params size (MB): 0.24
Estimated Total Size (MB): 0.30
----------------------------------------------------------------
计算量
第一个卷积层的计算量为:28×28×5×5×6×1+28×28×6=122304;
第二个卷积层的计算量为:10×10×5×5×16×6+10×10×16=241600;
第三个卷积层的计算量为:1×1×5×5×120×16+1×1×120=48120;
平均汇聚层的计算量为:16×5×5=400
第一个全连接层的计算量为:120×84=10080;
第二个全连接层的计算量为:84×10=840;
所以,LeNet-5总的计算量为423344。
from torchstat import stat
# 导入模型,输入一张输入图片的尺寸
stat(model, (1, 32,32))
module name input shape output shape params memory(MB) MAdd Flops MemRead(B) MemWrite(B) duration[%] MemR+W(B)
0 conv1 1 32 32 6 28 28 156.0 0.02 235,200.0 122,304.0 4720.0 18816.0 0.00% 23536.0
1 pool2 6 28 28 6 14 14 0.0 0.00 3,528.0 4,704.0 18816.0 4704.0 0.00% 23520.0
2 conv3 6 14 14 16 10 10 2416.0 0.01 480,000.0 241,600.0 14368.0 6400.0 0.00% 20768.0
3 pool4 16 10 10 16 5 5 0.0 0.00 1,600.0 1,600.0 6400.0 1600.0 0.00% 8000.0
4 conv5 16 5 5 120 1 1 48120.0 0.00 96,000.0 48,120.0 194080.0 480.0 0.00% 194560.0
5 linear6 120 84 10164.0 0.00 20,076.0 10,080.0 41136.0 336.0 0.00% 41472.0
6 linear7 84 10 850.0 0.00 1,670.0 840.0 3736.0 40.0 0.00% 3776.0
total 61706.0 0.03 838,074.0 429,248.0 3736.0 40.0 0.00% 315632.0
=====================================================================================================================================
Total params: 61,706
-------------------------------------------------------------------------------------------------------------------------------------
Total memory: 0.03MB
Total MAdd: 838.07KMAdd
Total Flops: 429.25KFlops
Total MemR+W: 308.23KB
5.3.3 模型训练
使用交叉熵损失函数,并用随机梯度下降法作为优化器来训练LeNet-5网络。
用RunnerV3在训练集上训练5个epoch,并保存准确率最高的模型作为最佳模型。
import torch.optim as opti
# 学习率大小
lr = 0.1
# 批次大小
batch_size = 64
# 加载数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
# 定义LeNet网络
# 自定义算子实现的LeNet-5
model = Model_LeNet(in_channels=1, num_classes=10)
# 飞桨API实现的LeNet-5
# model = Paddle_LeNet(in_channels=1, num_classes=10)
# 定义优化器
optimizer = opti.SGD(model.parameters(), 0.2)
# 定义损失函数
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy()
# 实例化 RunnerV3 类,并传入训练配置。
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 15
eval_steps = 15
runner.train(train_loader, dev_loader, num_epochs=6, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
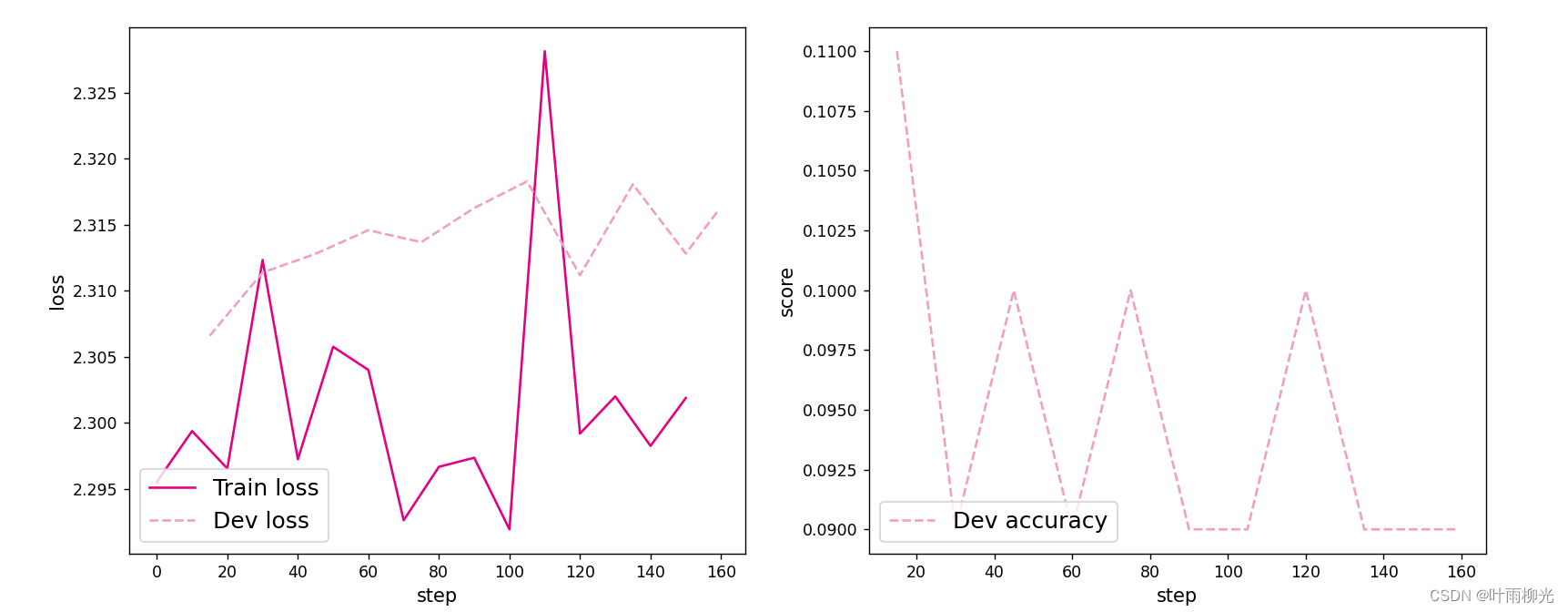
[Evaluate] dev score: 0.10000, dev loss: 2.30024
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.10000
[Train] epoch: 1/10, step: 30/160, loss: 2.31290
[Evaluate] dev score: 0.10000, dev loss: 2.30303
[Train] epoch: 2/10, step: 45/160, loss: 2.31105
[Evaluate] dev score: 0.10000, dev loss: 2.30605
[Train] epoch: 3/10, step: 60/160, loss: 2.29040
[Evaluate] dev score: 0.10000, dev loss: 2.30849
[Train] epoch: 4/10, step: 75/160, loss: 2.28025
[Evaluate] dev score: 0.09000, dev loss: 2.31210
[Train] epoch: 5/10, step: 90/160, loss: 2.29547
[Evaluate] dev score: 0.09000, dev loss: 2.31265
[Train] epoch: 6/10, step: 105/160, loss: 2.29400
[Evaluate] dev score: 0.09000, dev loss: 2.31451
[Train] epoch: 7/10, step: 120/160, loss: 2.30260
[Evaluate] dev score: 0.10000, dev loss: 2.31319
[Train] epoch: 8/10, step: 135/160, loss: 2.31520
[Evaluate] dev score: 0.10000, dev loss: 2.31567
[Train] epoch: 9/10, step: 150/160, loss: 2.27207
[Evaluate] dev score: 0.10000, dev loss: 2.31446
[Evaluate] dev score: 0.09000, dev loss: 2.31613
[Train] Training done!
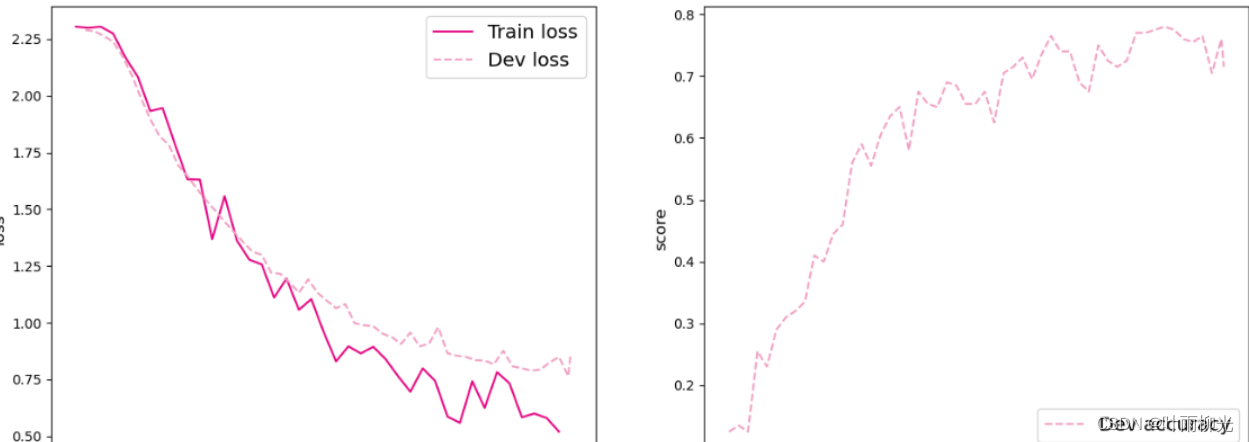
可视化观察训练集与验证集的损失变化情况。
from nndl import plot_training_loss_acc
plot_training_loss_acc(runner, 'cnn-loss1.pdf')
5.3.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失变化情况。
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))

5.3.5 模型预测
同样地,我们也可以使用保存好的模型,对测试集中的某一个数据进行模型预测,观察模型效果。
# 获取测试集中第一条数据
X, label = next(iter(test_loader))
logits = runner.predict(X)
# 多分类,使用softmax计算预测概率
pred = F.softmax(logits,dim=1)
# 获取概率最大的类别
pred_class = torch.argmax(pred[2]).numpy()
label = label[2].numpy()
# 输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
# 可视化图片
plt.figure(figsize=(2, 2))
image, label = test_set[0][2], test_set[1][2]
image= np.array(image).astype('float32')
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
plt.imshow(image)
plt.savefig('cnn-number2.pdf')

使用前馈神经网络实现MNIST识别,与LeNet效果对比。(选做)
import struct
import numpy as np
import torch.optim as opt
from nndl import runnerV3, metric
import random
import torch.utils.data as io
import torch.nn.functional as F
import torch.nn as nn
import torch
from PIL import Image
import matplotlib.pyplot as plt
from torchvision.transforms import Compose, Resize, Normalize
import torchvision.transforms as transforms
import torchmetrics
from nndl.dataset import load_data
class Accuracy(torchmetrics.Metric):
def __init__(self,is_logist=True):
"""
输入:
- is_logist: outputs是logist还是激活后的值
"""
# 用于统计正确的样本个数
super().__init__()
self.add_state("num_correct",torch.tensor(0))
# 用于统计样本的总数
self.add_state("num_count", torch.tensor(0))
#self.add_state("is_logist", is_logist)
def update(self, outputs, labels):
"""
输入:
- outputs: 预测值, shape=[N,class_num]
- labels: 标签值, shape=[N,1]
"""
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, -1)
if self.is_logist:
# logist判断是否大于0
p = []
for i in range(len(outputs)):
if outputs[i] > 0.:
p.append([1])
else:
p.append([0])
preds = torch.tensor(p)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
p = []
for i in range(len(outputs)):
if outputs[i] > 0.5:
p.append([1])
else:
p.append([0])
preds = torch.tensor(p)
else:
# 多分类时,使用'paddle.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1).int()
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, -1)
batch_correct = torch.sum(torch.eq(preds, labels).float()).numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def compute(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
class Model_MLP_L2_V3(nn.Module):
def __init__(self, input_size, output_size, hidden_size):
super(Model_MLP_L2_V3, self).__init__()
# 构建第一个全连接层
self.fc1 = nn.Linear(
input_size,
hidden_size,
)
nn.init.normal_(self.fc1.weight, mean=0, std=0.01)
nn.init.constant_(self.fc1.bias,1.0)
# 构建第二全连接层
self.fc2 = nn.Linear(
hidden_size,
output_size,
)
nn.init.normal_(self.fc2.weight, mean=0, std=0.01)
nn.init.constant_(self.fc2.bias, 1.0)
# 定义网络使用的激活函数
self.act = nn.Sigmoid()
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
return outputs
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X)
loss = self.loss_fn(logits, y) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.compute()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)
# 数据预处理
transforms = Compose([transforms.ToTensor(), Normalize(mean=[0.5], std=[0.5], )])
class IrisDataset(io.Dataset):
def __init__(self, mode='train', num_train=120, num_dev=15):
super(IrisDataset, self).__init__()
# 调用第三章中的数据读取函数,其中不需要将标签转成one-hot类型
X, y = load_data(shuffle=True)
if mode == 'train':
self.X, self.y = X[:num_train], y[:num_train]
elif mode == 'dev':
self.X, self.y = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
else:
self.X, self.y = X[num_train + num_dev:], y[num_train + num_dev:]
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
def __len__(self):
return len(self.y)
class MNIST_dataset(io.Dataset):
def __init__(self, dataset, transforms, mode='train'):
self.mode = mode
self.transforms =transforms
self.dataset = dataset
def __getitem__(self, idx):
# 获取图像和标签
image, label = self.dataset[0][idx], self.dataset[1][idx]
image, label = np.array(image).astype('float32'), int(label)
image = Image.fromarray(image.astype('uint8'), mode='L')
image = self.transforms(image)
image = torch.squeeze(image, 0)
image = torch.squeeze(image, 1)
return image, label
def __len__(self):
return len(self.dataset[0])
# 读取标签数据集
with open('./train-labels.idx1-ubyte', 'rb') as lbpath:
labels_magic, labels_num = struct.unpack('>II', lbpath.read(8))
labels = np.fromfile(lbpath, dtype=np.uint8)
# 读取图片数据集
with open('./train-images.idx3-ubyte', 'rb') as imgpath:
images_magic, images_num, rows, cols = struct.unpack('>IIII', imgpath.read(16))
images = np.fromfile(imgpath, dtype=np.uint8).reshape(images_num, rows * cols)
train_images, train_labels = images[:1000], labels[:1000]
dev_images, dev_labels = images[1000:1200], labels[1000:1200]
test_images, test_labels = images[1200:1400], labels[1200:1400]
train_set, dev_set,test_set= [train_images, train_labels], [dev_images, dev_labels],[test_images, test_labels]
print("train_set[0].shape::",train_set[0].shape)
train_dataset = MNIST_dataset(dataset=train_set, transforms=transforms, mode='train')
test_dataset = MNIST_dataset(dataset=test_set, transforms=transforms, mode='test')
dev_dataset = MNIST_dataset(dataset=dev_set, transforms=transforms, mode='dev')
print("train_dataset:",next(iter(train_dataset))[0].shape)
batch_size = 64
train_loader = io.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = io.DataLoader(dev_dataset, batch_size=batch_size)
test_loader = io.DataLoader(test_dataset, batch_size=batch_size)
print("test_loader:",next(iter(test_loader))[0].shape)
lr = 0.2
fnn_model = Model_MLP_L2_V3(input_size=784, output_size=10, hidden_size=6)
# 定义网络
model = fnn_model
# 定义优化器
optimizer = opt.SGD(model.parameters(),lr, )
# 定义损失函数。softmax+交叉熵
loss_fn = F.cross_entropy
metric = Accuracy(is_logist=True)
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 15
eval_steps = 15
runner.train(train_loader, dev_loader,
num_epochs=50, log_steps=log_steps, eval_steps = eval_steps,
save_path="best_model.pdparams")
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
from nndl import Plot_training_loss_acc
Plot_training_loss_acc.plot_training_loss_acc(runner, 'cnn-loss1.pdf')
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
总结
了解了 MNIST数据集,加深了对卷积神经网络的认识,也比较了前馈神经网络与卷积神经网络。















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









