






0. 前言
通过身边同学的反馈以及在网上浏览资料所见,配置Pytorch深度学习环境所遇到的大部分问题,都是版本不兼容的问题。所以在此文章中,我会着重说明根据不同的主机选择合适版本的安装方法。
为了更好地在文章中体现配置环境期间可能出现的问题,已将配置好的环境删除之后,重新安装一遍并编写的文章,放心使用!
本文章面向存在NVIDIA显卡(N卡)的主机,安装GPU版本的PyTorch。如果你的电脑中不存在N卡,请安装CPU版本的PyTorch。闲话不多说,直接上干货!!
- 判断电脑是否存在N卡(方法一)
- 使用
Win + R命令唤出运行对话框。 - 在框中输出
cmd唤出命令提示符。 - 在命令提示符中输入
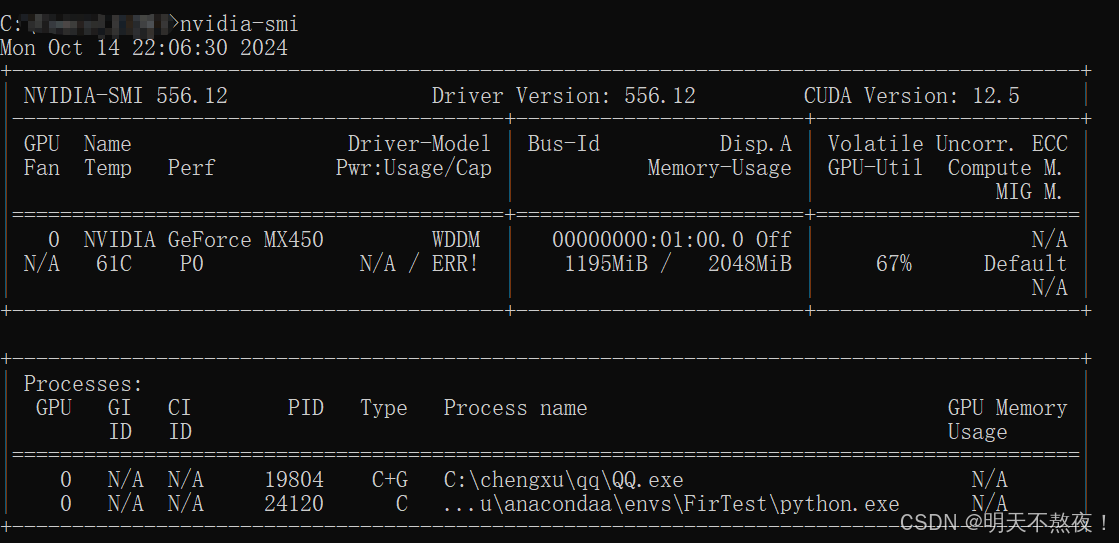
nvidia-smi命令。 - 如果显示如下图所示,则证明电脑中存在NVIDIA显卡。
- 记住红色框中的内容,后面会考。
- 使用

- 判断电脑是否存在N卡(方法二)
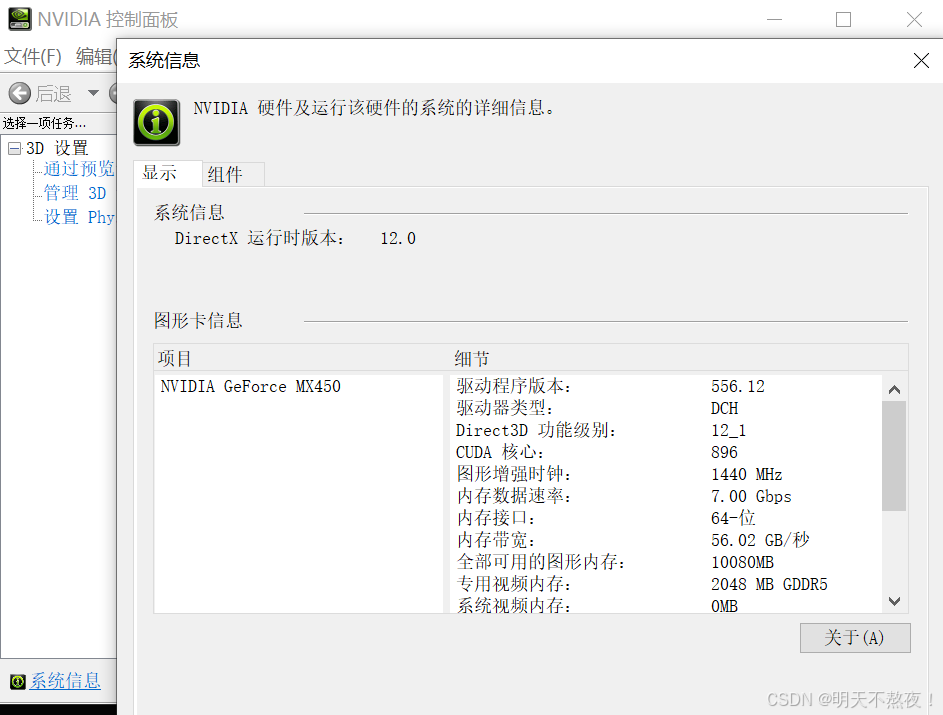
- 在桌面右键点击NVIDIA控制面板。
- 点击左下角的系统信息,查N卡信息。
1. Anaconda 安装
Anaconda 就是一个强大的环境管理工具。通过conda,用户可以创建多个独立的虚拟环境,每个环境可以拥有不同版本的 Python 和库。通俗来讲,虚拟环境就好比工具箱,用户可以创建多个工具箱,工具箱1存放精密仪器工具,工具箱2存放日常生活工具,工具3…等等。
具体安装下载步骤可以移步至该博客Anaconda安装与配置
2. CUDA 和 cuDNN 安装
CUDA是 NVIDIA 提供的并行计算平台,旨在利用 GPU 的强大计算能力加速复杂的计算任务。cuDNN是基于 CUDA 的深度学习加速库,专门优化神经网络的计算操作,如卷积和池化,以提升模型训练和推理的效率。
直接上安装步骤!
2.1 CUDA安装
- 打开[CUDA历史版本下载界面](CUDA Toolkit Archive | NVIDIA Developer),还记得在文章开头红色框中的
CUDA Version吗,这个的值是你下载CUDA版本的最大值,下载的CUDA版本不能超过该值。- 我的主机显示
CUDA Version:12.5,意味着我下载的CUDA版本需要小于等于12.5
- 我的主机显示

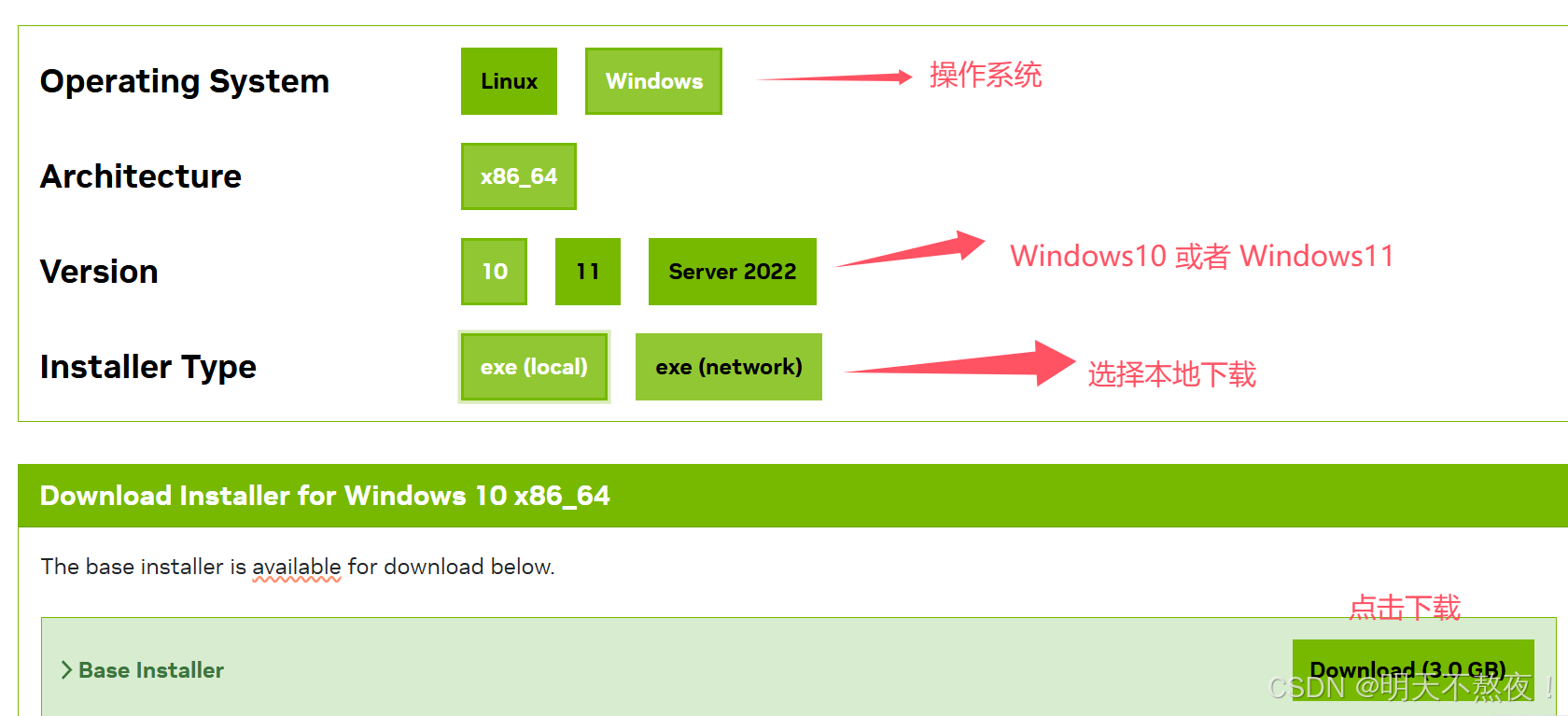
- 选择好配置之后点击
Download开始下载CUDA安装包
- 临时解压目录,直接点击ok,解压完成后会跳转到以下界面。
- 点击同意并继续,出现下面内容。
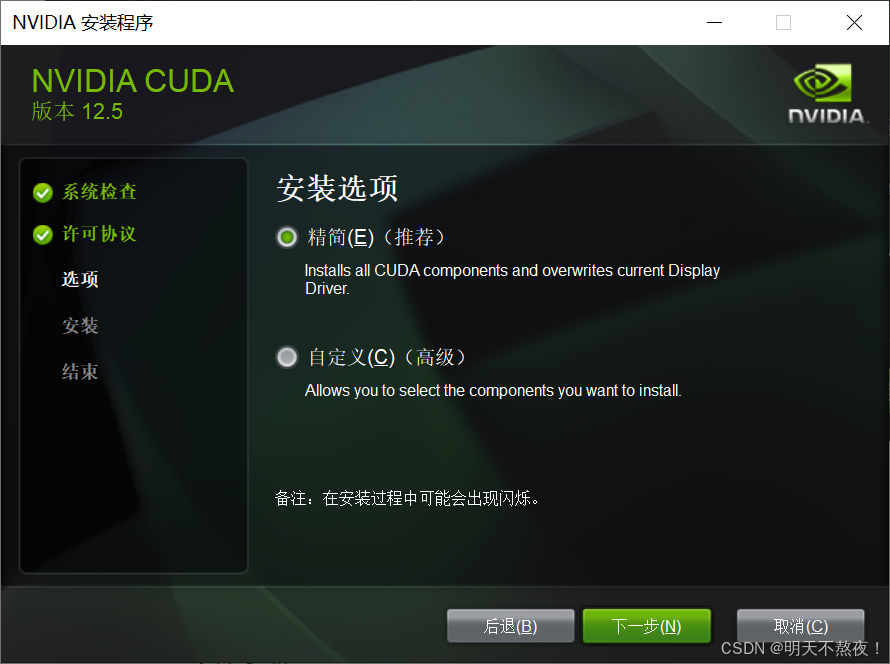
- 精简:自动安装进电脑,默认是C盘,C盘容量够的话可以直接精简安装。
- 自定义:我的笔记本本来就不大,所以就没有分区。但是我习惯性自定义存储位置。
- 自定义安装可以使用以下步骤。自定义安装的路径是我根据默认路径,在新文件夹中创建的路径。在C盘目录下创建
chengxu>NVIDIA GPU Computing Toolkit>CUDA>v12.5文件夹,>的意思为右边的文件夹在左边文件夹之中。
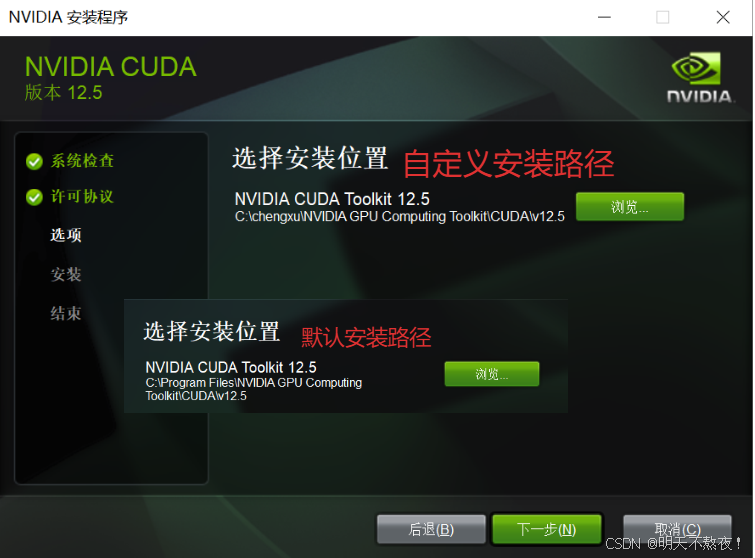
- 勾选完成,点击NEXT进入安装。
- 点击确定,安装完成。
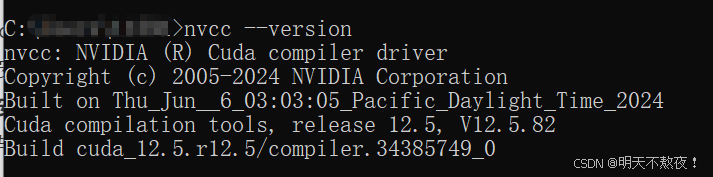
- 验证CUDA安装是否成功。在命令提示符端输入
nvcc --version,如果出现CUDA的版本信息,则证明安装成功。
2.2 cuDNN安装
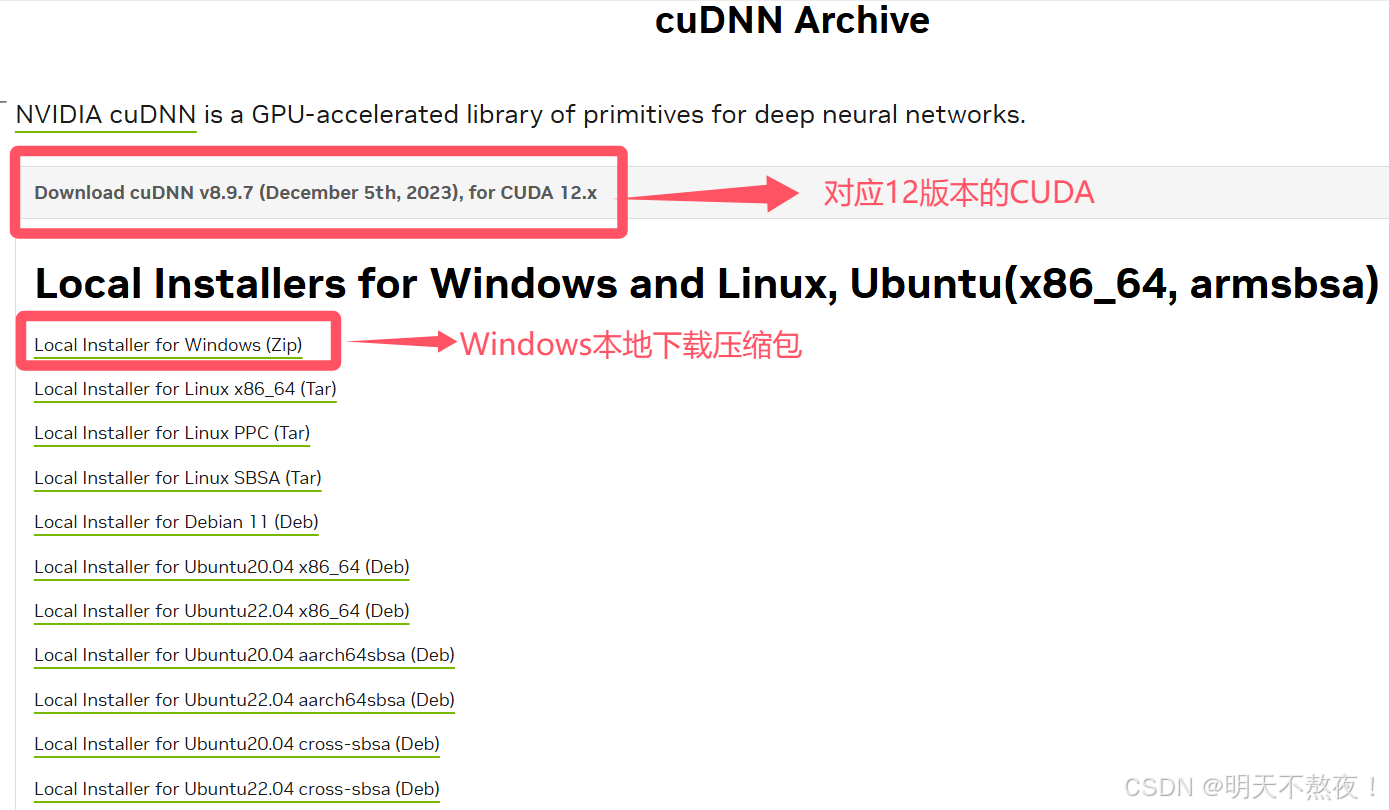
- 打开[cuDNN官方下载页面](cuDNN Archive | NVIDIA Developer),由于我们的CUDA版本是 12.5 ,所以下载cuDNN时,需要下载对应的版本。
- 下载压缩包时需要创建NVIDIA账户,直接用国内邮箱创建账户即可,创建完成之后可以下载cuDNN压缩包。
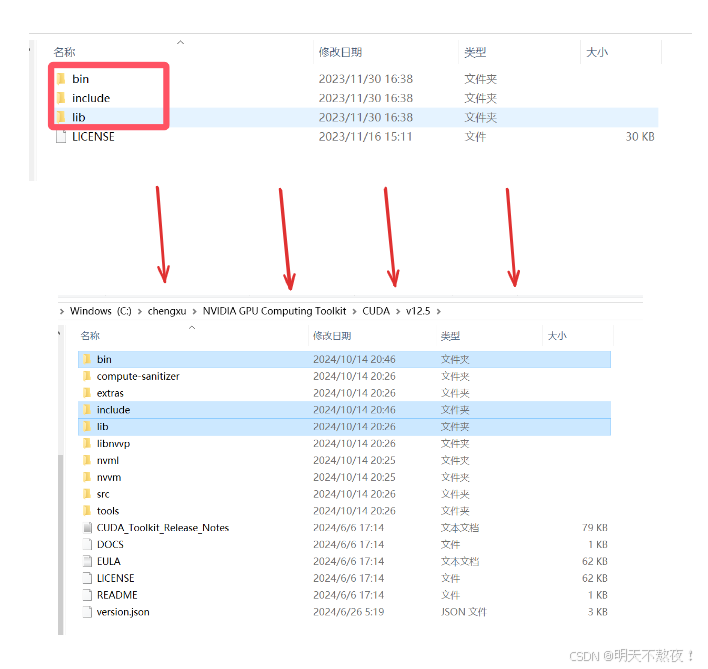
- 下载完之后解压cuDNN文件,将文件中的三个
bin、include、lib文件夹复制,打开刚才的CUDA安装文件夹,将这三个文件直接复制进去。
3. PyTorch 安装
3.1 创建虚拟环境
这里介绍一下如何创建虚拟环境以及一些基本操作,以便在后续针对不同的虚拟环境安装相应的库,从而避免库之间的冲突。
- 查看已安装的Python版本号。在命令提示符中输入
python --version,我的版本号是3.11。

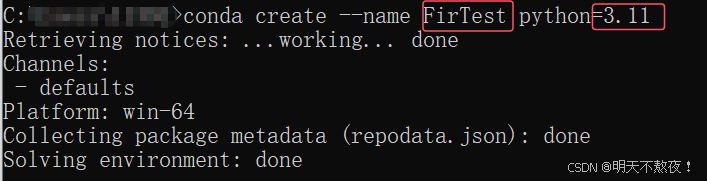
- 创建虚拟环境。在命令提示符中输入
conda create --name 虚拟环境名称 python=3.11,在Proceed ([y]/n)?后输入y并回车,创建虚拟环境。- 图中红色框中的内容可以根据自己的想法和配置进行更改。
- 查看虚拟环境。在命令提示符中输入
conda env list查看所有的环境列表。- base:本地环境、默认环境。若不创建虚拟环境,所以的库将被安装在此环境中。
- FirTest:虚拟环境。通过上面的命令创建的虚拟环境,用来存放Pytorch相关的库。

- 应用虚拟环境。在命令提示符中输入
activate FirTest命令,应用虚拟环境。- 当出现如下图所示的内容时,即表示已经应用虚拟环境FirTest,后续输入的命令会在该虚拟环境中被执行。

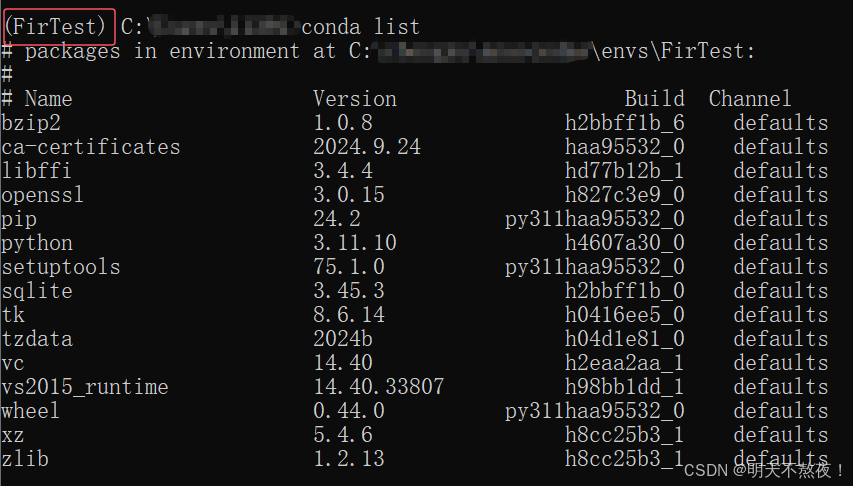
- 查看虚拟环境中已存在的库。在对应的虚拟环境中,输入
conda list命令,查看所有已存在的库。
3.2 安装 PyTorch
- 打开[PyTorch历史版本下载](Previous PyTorch Versions | PyTorch),咱们下载的CUDA版本是12.5,咱们需要找到12.5及以下的版本进行安装。
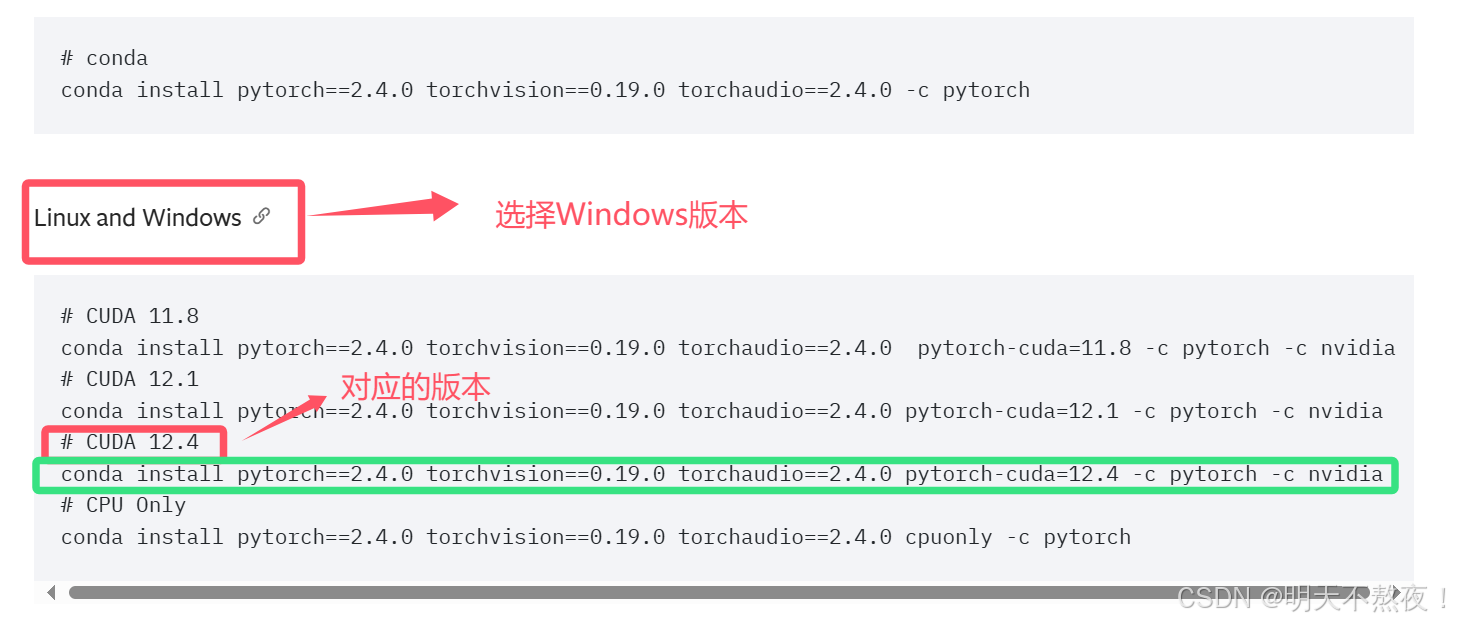
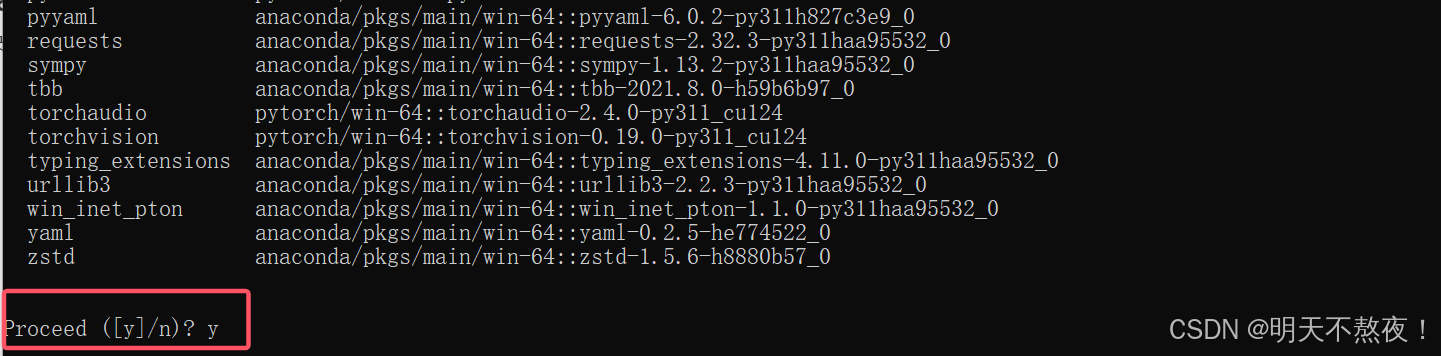
- 复制绿色框中的代码,进入虚拟环境中,输入复制的命令回车,在
Proceed ([y]/n)?后面输入y并回车,进行PyTorch的安装。

3.3 验证 PyTorch 安装
- 在命令行终端验证PyTorch,显示版本号则证明已经安装成功。

4. 深度学习初体验
4.1 在Pycharm中配置虚拟环境解释器
- 如果主机中未安装PyCharm,可以参考文章Pycharm安装及配置。
- 在PyCharm中创建一个新项目
- 配置python虚拟环境解释器。
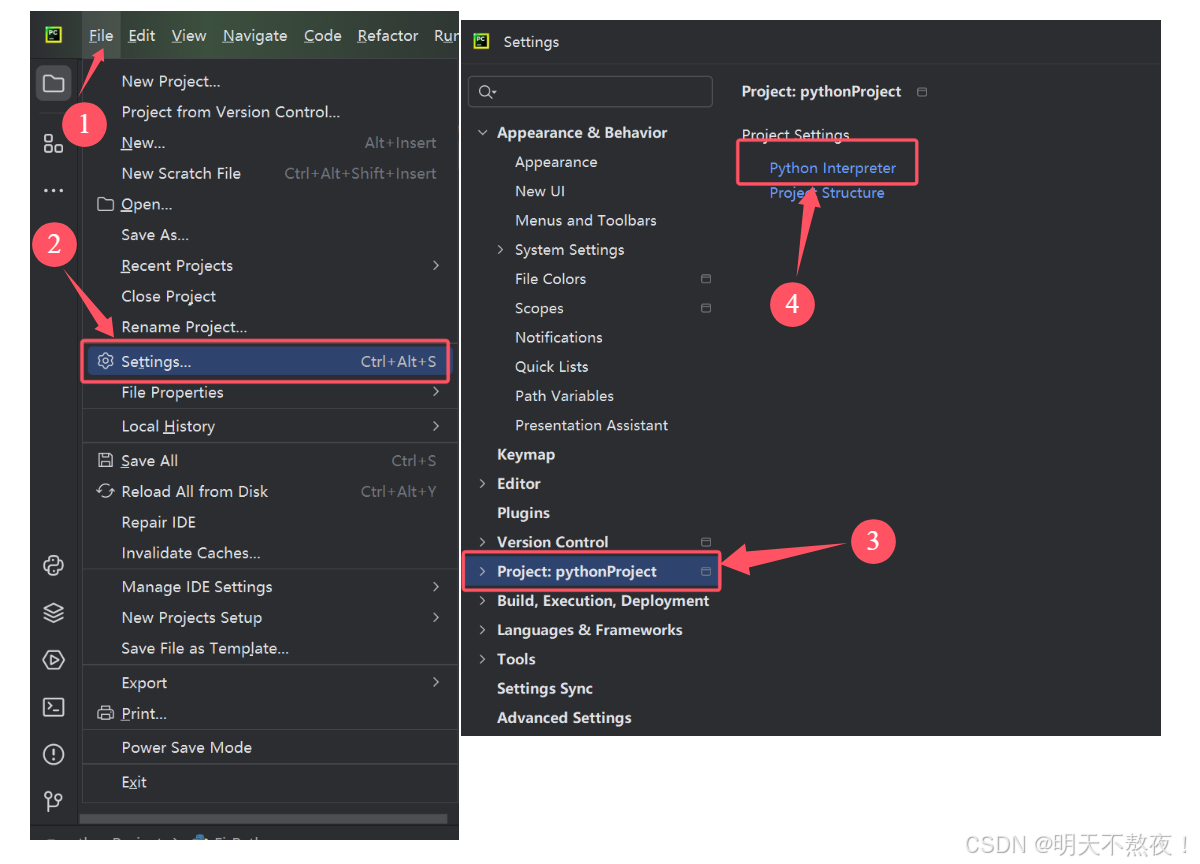
- 点击添加解释器
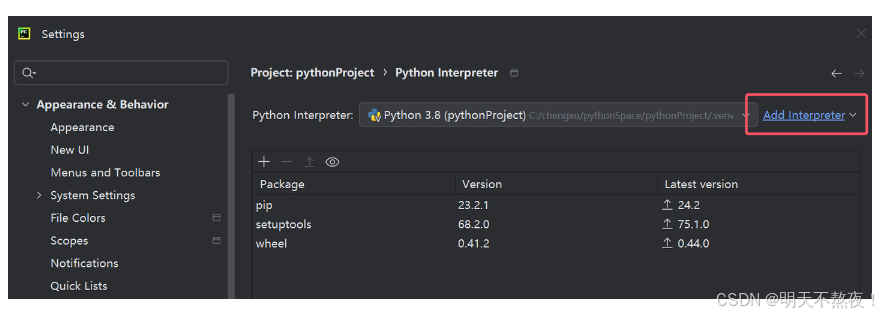
- 选择已经安装完成的虚拟环境python编译器。切记!!一定要点击OK和apply,将设置应用。
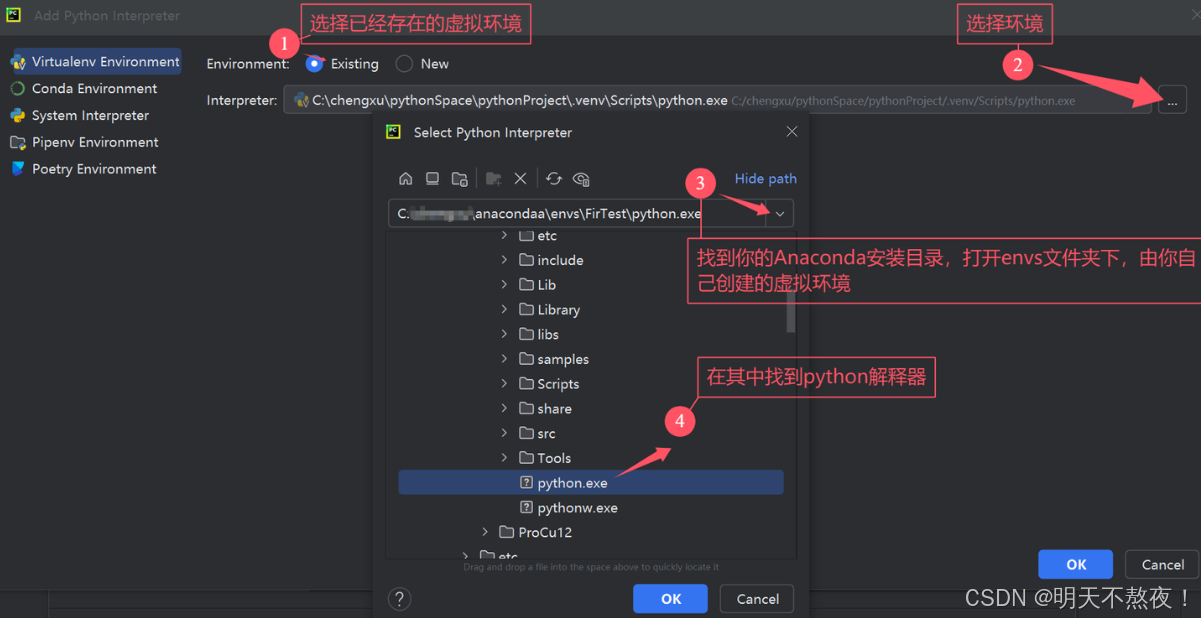
- 右键项目,创建一个
Python File文件来编程程序。
4.2 应用—MNIST手写数字识别
# 1. 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 2. 设置训练设备:GPU 或 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 3. 数据集准备
# 使用 transforms 对数据进行标准化并转换为张量
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # 标准化:均值为 0.1307,标准差为 0.3081
])
# 加载 MNIST 数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
# 创建数据加载器
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=1000, shuffle=False)
# 4. 定义卷积神经网络(CNN)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 定义卷积层,输入 1 个通道(灰度图像),输出 32 个通道,卷积核大小为 3x3
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
# 全连接层
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2) # 最大池化层,池化核大小为 2x2
x = self.dropout1(x)
x = torch.flatten(x, 1) # 将卷积层输出展平为 1D 向量
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# 5. 初始化模型并设置优化器和损失函数
model = CNN().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 6. 训练模型
def train(model, device, train_loader, optimizer, epoch):
model.train() # 设置模型为训练模式
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化参数
if batch_idx % 100 == 0:
print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} "
f"({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}")
# 7. 测试模型
def test(model, device, test_loader):
model.eval() # 设置模型为评估模式
test_loss = 0
correct = 0
with torch.no_grad(): # 禁止梯度计算
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item() # 计算损失
pred = output.argmax(dim=1, keepdim=True) # 获取预测值
correct += pred.eq(target.view_as(pred)).sum().item() # 计算正确预测数量
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f"\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} "
f"({accuracy:.0f}%)\n")
# 8. 运行训练和测试
n_epochs = 5
for epoch in range(1, n_epochs + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
# 训练结束后可以保存模型
torch.save(model.state_dict(), "mnist_cnn.pth")
- 程序运行中间结果输出。
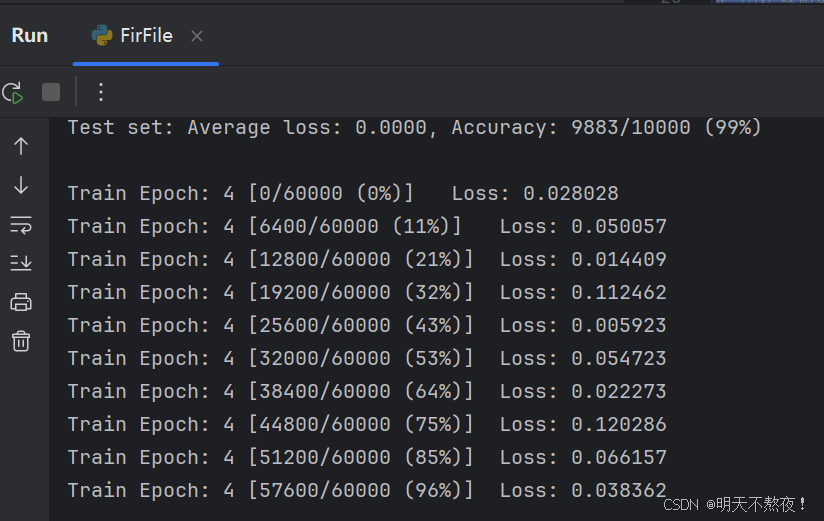
- 查看GPU使用情况。还记得文章一开头的重点吗?
5. 总结
经过以上的步骤,你已经可以开始炼丹之旅了,望各位道友炼丹愉快!
本文章结合了许多大佬的配置文章,从零配置深度学习的环境,用作学习之余的记录。
(os:为了记录最真实的从零开始配置环境,下午把环境删除了。晚上就突然通知明天开组会汇报文献学习,人都麻了,赶紧写完博客,研究僧扫地去了…)

















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









