







本节梗概
- 1. 认识HTTP报文交互方式,为urllib库的理解和使用做准备
- 2. 学习urllib库的组成与基本使用方法
文章目录
一、HTTP报文交互的简单介绍
1.1 引入
在用户正常上网时,通过浏览器可以完成从URL链接的输入到网页的直接获取,对于爬虫来讲,也就是进行模拟用户请求,模拟用户向服务器请求链接,从而获取指定的回复网页。因此我们不单单要对HTML网页源代码进行简单了解,还要对网页请求是如何访问服务器,服务器如何响应网页请求这个交互过程进行认识,这也为接下来要介绍的Urllib库作用和使用做下铺垫。
1.2. 客户端与服务器交互方式
1.2.1 HTTP协议

1.2.2 HTTP请求报文与响应报文
1. 作用介绍
·请求报文(request Message) :客户端向服务器端发送的HTTP报文,主要包含着客户端的请求信息,用于向网站请求不同的资源,比如HTML文档、图片、视频等信息;
·响应报文(response Message) :服务器向客户端回复的HTTP报文,报文信息一般较丰富,其内容可以是HTML文档的源代码、xhr交互数据、图片等信息;
2.结构介绍
·请求报文(request Message) :由起始行(请求行)、头部(header请求头)、实体(entity-body请求体)构成;起始行即报文第一行,主要是来表明通信类型、版本协议等信息,此区域通过标注三个信息来控制:请求方法(method)、请求URL(request-URL) 、协议版本(version),在请求方法中可以使用[GET、POST、HEAD]等参数,分别对应HTTP的get、post、head请求方式;头部主要是标明客户端处理请求是所需要的信息,请求头可以是多行,本质上来看是包含若干个属性键值对的列表,比如含有"Accept-Encoding: —"是表明浏览器支持的编码类型,相对于重要的键值对是User-Agent:—、cookie:—;分别表示用户代理和存储在用户本地终端的数据,有着表明客户端操作系统、浏览器版本等和识别用户、跟踪会话的作用。请求报文的实体主要是用来记录传输内容,对于请求报文,特别是GET、HEAD请求报文,一般用于静态网页请求,因此此类请求报文一般实体内容为空,但对于POST请求报文(一般用于提交),因此此类请求报文的实体内一般要包括请求附带的参数,也是属性键值对的形式。其构成(图二)与实例(图三)如图所示。
☆[查看请求、响应记录等操作方式:右键-检查-网络/Network-‘选择具体记录’-标头/headers]


·响应报文(response Message) :响应报文的构成与请求报文构成相似,也是由起始行(响应行)、头部(响应头)、实体(响应体)构成,但是存在细微的不同,主要体现在起始行上:响应报文的起始行的三个组成部分分别为协议版本(version)、状态码(status)、原因短语(reason-phrase);协议版本参数与请求报文一致,状态码用来表示服务器对客户请求的响应状态(常见状态码如下表),而原因状态则是对状态进行文本形式解释。值得一提的是,在响应报文中实体占着很重要的地位,一般情况下我们所需要的网页源代码就被放在其中。
| 状态码 | 释意 |
|---|---|
| 200 | OK,成功状态码,服务器成功处理了请求,请求所希望的响应头或实体会随着响应返回 |
| 202 | Accepted,服务器已接受请求,但尚未处理 |
| 301 | Move Permanently,请求资源已经永久的新位置,即被分配了新的URL |
| 400 | Bad Request,表示请求报文存在语法错误或者参数错误,服务器无法理解 |
| 403 | Forbidden,服务器已经理解请求,但拒绝执行 |
| 404 | Not Found,请求失败,服务器上没有相应的请求资源 |
| 500 | Internal Server Eorror,服务器执行请求错误,即服务器处于错误状态 |
| 503 | Server Unavailable,服务器超载或正在停机维护,无法处理请求 |
1.2.3 补充
1.URL的构成
URL(Uniform Resource Locator, 统一资源定位器),一般我们都把他叫做网址,它是www的统一资源定位标志,在网络中,每一个存储的网页都会有其对于的网址标识,它的构成也是具有规则含义的,再来简单复习一下它构成。
URL的标准链接格式为:scheme://netloc/path;params?query#fragment
| 部分 | 含义 |
|---|---|
| scheme | 基础参数,访问协议,常见的为http、https、ftp等 |
| netloc | 基础参数,存放资源的服务器的域名(DNS) |
| path | 基础参数,请求文件路径 |
| params | 基础参数,url所带参数,路径附加部分 |
| query | 非基础参数,客户端传递的参数 |
| fragment | 非基础参数,用于指定网络资源中的某个片段 |
2.请求报文请求方式的区别,为什么分“get、post、head等请求”,还有其他的请求方式吗?
请求报文的请求方式表明了用户请求的大致目的,能够加快服务器处理用户请求的速度。在HTTP1.0中只定义了三种请求方式:GET、POST、HEAD,到HTTP1.1中在原有基础上添加了五种新的请求方式:PUT、OPTIONS、DELETE、TRACE 、CONNECT 。他们之间有着一些细微的差距,我们常用的就涉及到GET与POST两种请求方式,可以简单来了解一下他们的含义。
请求方式GET偏向于只是单独获取数据,主要目的是获取url对应的页面信息,只需要将其包含在响应报文中即可,在浏览网页时这是最多见的请求方式;POST请求方式主要是用于提供数据,提交表单后进行页面访问,需要除了url外还有额外提交一些数据;举个例子:比如网址’https://so.csdn.net/so/search’这是CSDN网站的搜索界面,当在此网站输入关键字python进行检索时,会跳转到网页‘https://so.csdn.net/so/search?urw=&q=python’,这就相当于是在原网页基础上提交表单“key=python”等的信息,组合之后返回新的网址;当然我们也可以直接定义url为‘https://so.csdn.net/so/search?urw=&q=python’使用GET方法来请求,既然POST请求可以使用GET请求进行等同访问,那么定义POST请求的意义在哪儿呢?虽然提交的表单会以‘?’连接url与表单键值对(各键值对之间使用‘&’连接),但是GET请求会将输入信息裸露在网址上,而POST请求是会将用户表单输入存储在实体中的,相对于较安全,这也就解释了为什么请求报文中GET请求的实体一般是空的,POST请求实体是不为空的;再者,GET请求的url长度是有限的,也就表示了对于表单数据较多时无法使用GET方法直接构造url,POST提交的数据是存储在实体中的,所以也不用考虑表单的长度问题。当然这两种请求的差别不止这些,有兴趣的可以查阅资料。其他的请求方式感兴趣的话也可以查阅资料进行认识。
3.请求头中的cookie参数含义?了解状态保持技术。
在日常使用浏览器时,只要在网页端登录一次csdn账号,在接下来的一段时间里再次进入这个网页时我们的账号信息仍然停留在这个网页之中,不需要我们每次都输入用户信息,这个是这么做到的呢?这就涉及到了HTTP协议的状态保持技术,实际上在第一次登录时,我们所提交的用户信息就会再次传输到服务器端,服务器辨别出我们的身份,会再次返回到我们的用户主页面,所谓的状态保持技术,就是将这种验证信息直接保存在客户端或者服务器上,等到再次登录页面时浏览器会自动提交这种信息,从而省略了客户再次手动登录的步骤。那么这种验证信息究竟是保存在客户端还是服务器上呢?答案是都可以,这也刚好对应了两种状态保持技术:Cookie和Session。
·Cookie:Cookie是由服务端生成,并在客户端进行保存和读取的一种信息,一般以文件形式保存在用户端。一般来讲cookie都是有时间限制的,等到到达了过期时间,cookie就会失效,需要再次生成,有些cookie是直接保存在内存中的,因此可以在用户文件中找到,当然通过查看浏览器中的请求头里“Cookie”对应的值也可以看到,cookie的编写格式也比较复杂,有兴趣的可以深入去了解;基于cookie的状态保持技术也存在一定缺陷:首先cookie在每个域名下的数量都是有限的,而且大小也有着一定的限制,这也就限制了在需要进行大量数据交换的应用中使用cookie并不合适,其次,cookie相较来说是不太安全的,因为cookie从客户端向服务器提交时容易被截获,可能会被冒充身份登录网站,因此我们也最好不要泄露自己的cookie信息。
·Session:Session状态保持技术是在服务器上划分一块区域,来把用户数据保存在其中,每次登录时用户数据也就不需要进行传输,那么问题是,服务器怎么辨别哪个是你的用户数据呢?Session会在保存你用户数据的区域进行编号为唯一的Session_id,然后这个编号由客户端进行存储,用户登录时只需传输Session_id即可,一般来讲,Session_id是加密存储的,虽然也有被截获的风险,但是Session_id是具有动态性的,相对较安全。因此在Session技术上也是依赖于cookie技术的,只是cookie不需要保存大量的用户数据,只需要保存Session_id即可,大致结构如图四所示。

二. Urllib库的简单使用
2.1 介绍
在编写爬虫时,显然我们需要让其自动获取目的网页的源代码,如何模拟用户使用浏览器发送请求并且如何处理响应报文呢?在Python中存在内置库Urllib,它是Python自带的库,不需要额外安装,它可以帮助我们解决这个问题。我们先对它进行简单的了解。
☆官方文档:https://docs.python.org/zh-cn/3.7/library/urllib.html
2.2 组成与基本使用
Urllib库主要由四个组成模块:
| 模块 | 作用 |
|---|---|
| urllib.request | 请求模块 |
| urllib.parse | url解析模块 |
| urllib.error | 异常处理模块 |
| urllib.robotparser | robot解析模块 |
①urllib.request模块
·urllib.request.Request():返回Request请求对象,相当于请求报文
import urllib
from urllib import request
# urllib.request.Request(url, data=None, headers={}, method=None)
# 常用参数:
# url:字符串,请求的url连接
# data:bytes字节流形式,可用内置方法 bytes(string, encoding=None)来将字符串进行转换
# headers:字典形式,请求头构造,通过构造请求头后可以伪装用户进行浏览器访问,减少被服务器识别的概率
# method:字符串('GET'、'POST'...),指定请求方式
url = 'https://www.csdn.net/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
req1 = urllib.request.Request(url=url, headers=header, method='GET')
type(req1)

# Request对象也有.add_header方法,可单独再为请求报文添加请求头
url = 'https://www.csdn.net/'
req2 = urllib.request.Request(url=url, method='GET')
req2.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36')
type(req2)

·urllib.request.urlopen():返回Response对象,相当于发送请求报文,接收响应报文
import urllib
from urllib import request
# urllib.request.urlopen(url, data=None, [timeout, ]*)
# url:请求网址
# data:None或者bytes字节流,指定为bytes字节流时请求方式默认为POST请求,为None则为GET请求
# timeout:double类型,指定最长等待时间,以秒为单位,请求时间超过时停止等待
res1 = urllib.request.urlopen(url='https://www.csdn.net/', timeout=1)
print(type(res1))
# 以上是用法一,可以看出其直接传入url即可完成响应报文的获取,但缺点也很明显,
# 不能很好的完成请求报文的构造,特别是无法添加请求头,因此我们也可以使用其另一种形式
# 它可以接收我们创建的Request对象,这种方法是符合我们思维的
res2 = urllib.request.urlopen(req1) #此req1是上一个函数创建的Request对象
print(type(res2))

# Response对象 常用属性与方法
# Response.status:响应报文的状态码
print(res2.status)
# Response.getheaders():查看响应头
print(res2.getheaders())
# Response.getheader("XXX"):查看响应头的某一项
print(res2.getheader('Content-Type'))
# Response.read():以字节字符串返回网页对应源码,要通过decode解码
res2.read().decode('utf-8') #解码方式要选择网页对应编码格式,在源码中"charset"属性可查到
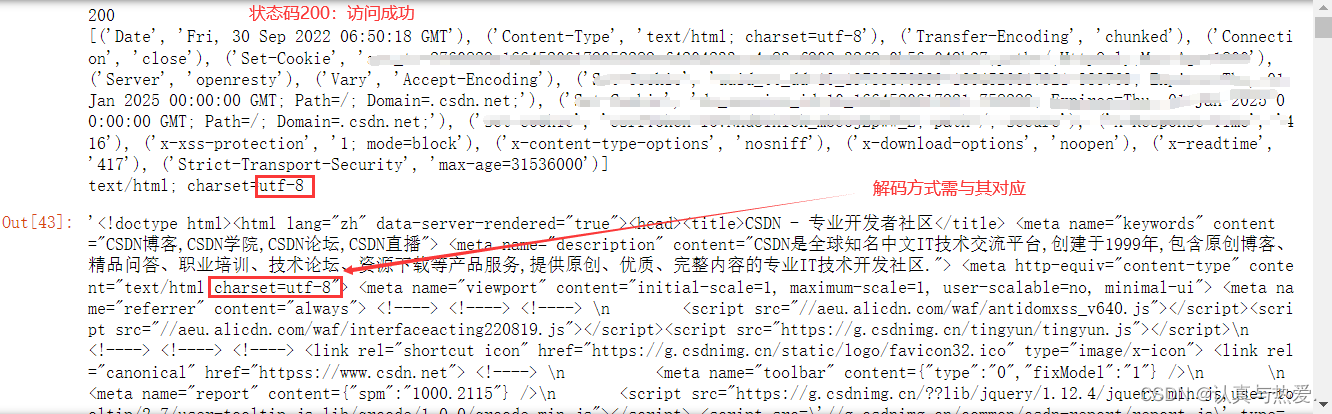
差不多理解request模块中这三个方法就能获得简单的网页源码获取,但是请求报文模拟的越好,爬虫被识别成功的概率也就越低,因此使用方法自带的模拟补全方法或者只构造几个请求头属性可能稍微有点欠缺,因此稍微高级的用法可以使用handler工具,也很好理解,此模块下有很多handler工具,像设置代理ip,加载或者保存cookie信息等等,在这里我们就稍微介绍两个handler工具:设置代理ip与cookie操作。
代理ip的作用:很多网站都会统计一段时间内ip访问次数,频率过高会被禁止访问,设置代理ip可以减少被禁止访问的几率
·urllib.request.ProxyHandler():传入字典对象或者字典组成的列表,返回ProxyHandler对象
·urllib.request.build_opener():传入Handler对象,返回OpenerDirector对象
·OpenerDirector对象的open()方法:urllib.request.urlopen()用法一致
import urllib
import urllib.request
# 设置代理ip,字典形式(传入多个字典组成的列表会随机从中选择一个ip)
proxy_handler = urllib.request.ProxyHandler({
'http':'代理ip地址'
})
opener = urllib.request.build_opener(proxy_handler)
# 使用代理ip对象访问目的网址,此处也可以传入Request对象
res3 = opener.open('http://www.baidu.com')
设置cookie的作用:对于一些网站,必须提交表单信息才能进行访问,构造cookie信息可以获取内容页面,进行目的信息获取
·urllib.request.HTTPCookieProcessor():接收cookie文件,返回Handler子对象
import http.cookiejar
import urllib.request
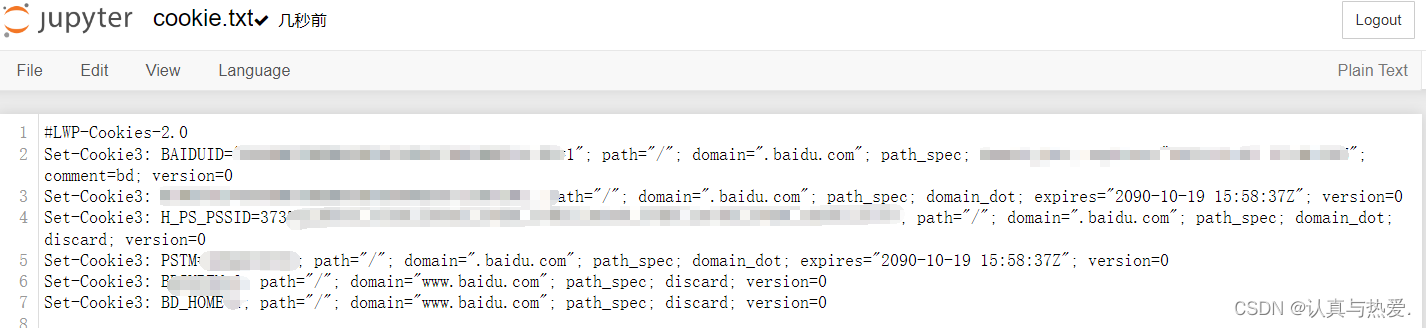
#------------将cookie信息保存至指定文件之中-------------------
# 创建cookie文件
cookie = http.cookiejar.LWPCookieJar('cookie.txt')
# 构造cookie形式handler
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
# 生成OpenerDirector对象
opener = urllib.request.build_opener(cookie_handler)
# 访问网页
res5 = opener.open('http://www.baidu.com')
# 生成并保存cookie文件
cookie.save(ignore_discard=True, ignore_expires=True)
import http.cookiejar
import urllib.request
#----------------加载cookie文件访问网页----------------------
# 生成cookie对象
cookie = http.cookiejar.LWPCookieJar()
# 将文件信息读入cookie对象
cookie.load('cookie.txt',ignore_discard=True, ignore_expires=True)
# 构造cookie形式handler
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
# 生成OpenerDirector对象
opener = urllib.request.build_opener(cookie_handler)
# 访问网页
res6 = opener.open('http://www.baidu.com')
②urllib.parse模块
·urllib.parse.urlencode() 组装post请求的表单信息,接收字典,生成字符串
import urllib
from urllib import parse
# urllib.parse.urlencode()
# 实质上就是把字典生成形如‘key1=value1&key2=value2...的字符串’
fro_url = 'https://so.csdn.net/so/search'
params = {
'urw':'',
'q':'python'}
# 将表单数据转换为url后缀
end_url = urllib.parse.urlencode(params)
# 注意此方法需要手动添加“?”
url = fro_url + '?' + end_url
end_url, url

# 注意urllib.parse.urlencode() 与 urllib.request.Request(url=url, data=data)两者都能组合链接
# 一般前者是相当于手动组装url,生成get请求,直接将params传给函数即可,但连接时需要手动添加“?”构造完整链接
# 后者将params生成bytes字符串形式,传给data参数,不用手动添加‘?’,但注意是需要转成字节形式
# 因此刚刚组装url的实例也可使用后者方法
fro_url = 'https://so.csdn.net/so/search'
params = {
'urw':'',
'q':'python'}
# 装换为字节流形式传给data
data = bytes(urllib.parse.urlencode(params), encoding='utf-8')
req4 = urllib.request.Request(url=url, data=data, method="GET")
res4 = urllib.request.urlopen(req4)
·urllib.parse.urlparse():接收url字符串,返回ParseResult对象
import urllib
from urllib import parse
# urllib.parse.urlparse(url, scheme='', allow_fragments=True)
# scheme:字符串,默认协议,只有url中没有表明协议时scheme才生效
# allow_fragments:布尔值,是否单独显示片段
cons = urllib.parse.urlparse('https://blog.csdn.net/m0_56364204?spm=1000.2115.3001.5343')
print(type(cons), cons, sep='\n')
# ParseResult对象含有六个属性,分别对应六个组成部分
cons.scheme, cons.path

·urllib.parse.urlunparse():组成url,与urlparse()作用刚好相反
import urllib
from urllib import parse
# urllib.parse.urlunparse() 接收url六个组成部分的列表
cons = ['https', 'blog.csdn.net', '/m0_56364204', '', 'spm=1000.2115.3001.5343', '']
url = urllib.parse.urlunparse(cons)
url

③urllib.error模块
·urllib.error模块主要处理在进行url处理时出现的各种错误,在此模块中一般含有三种错误类型:
·error.HTTPError:范围较小,只处理http报文交换时出现的错误,含有.code、.reason、.headers属性
·error.URLError:范围较大,处理url传输时出现的错误,含有.reason属性
·error.ContentTooShortError:文件下载不完全导致的报错,一般不常用
import urllib
from urllib import request, error
# 一般对于尝试爬取操作可以使用如下错误抓取(先小后大)
url = 'https:/www.csdn.net/' # 赋值错误网址 ('https://www.csdn.net/')√
try:
res5 = urllib.request.urlopen(url)
# 先测试是否为HTTP错误
except urllib.error.HTTPError as e:
# 如果是,输出错误原因、报错信息、报错报文头
print(e.reason. e.code, e.headers, sep='\n')
# 再测试是否为URL范围错误
except urllib.error.URLError as e:
# 如果是,输出错误原因
print(e.reason)
else:
# ---- 访问成功 -----
print(res5.read())

2.3 简单模板
☆模板中依靠chardet字符集编码格式检测模块,检测结果可能比较精细导致解码失败,报错时可以观察待爬网页编码格式之后手动输入,完成解码。
import chardet
import urllib
from urllib import request, error
def get_text(url):
#构造请求头
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
#构造请求体
req = urllib.request.Request(url=url, headers=header)
#尝试访问
try:
res = urllib.request.urlopen(req)
# 先测试是否为HTTP错误
except urllib.error.HTTPError as e:
# 如果是,输出错误原因、报错信息、报错报文头
print(e.reason. e.code, e.headers, sep='\n')
# 再测试是否为URL范围错误
except urllib.error.URLError as e:
# 如果是,输出错误原因
print(e.reason)
else:
# ---- 访问成功 -----
byte_text = res.read()
# 检测编码格式,返回置信度和对应编码方式
result = chardet.detect(byte_text)
encode = result['encoding']
return byte_text.decode(encode)
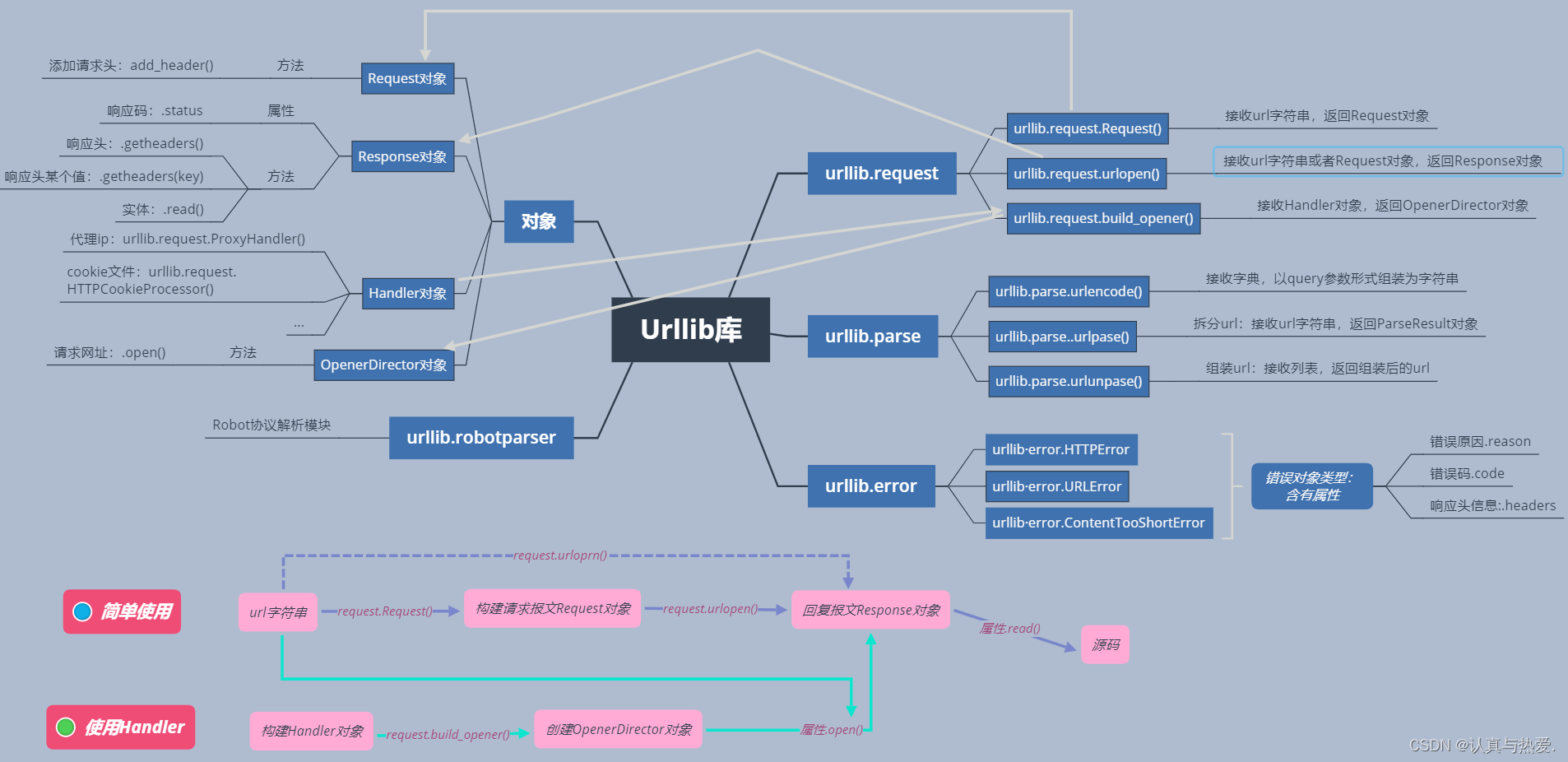
三、Urllib库总结
四、结尾
在此已经对urllib库的使用有了一定的理解与认识,能够简单的对网页进行源代码等信息获取,接下来预计介绍正则匹配技术与re库的使用。
文章和代码都为原创,在记录分享此篇文章时也花费了很长时间,查阅了很多资料,也对文章内容和代码进行很多次修改,作者水平有限,难免出现一些错误或者问题,因此内容仅供参考,也欢迎大家提出问题共同讨论,共同进步。















 1210
1210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









