







前提内容
本节梗概
- 学习Xpath定位检索的规则
文章目录
一、 介绍
在之前我们对正则表达式进行了了解,并通过实例演示了如何基于正则表达式来对网页内容进行解析和完成爬虫的制作。在信息检索方式中其实目前有着多种方案,像基于正则表达式的正则匹配、基于Dom树的Xpath定位和css选择器等多种方法,接下来我们可以来了解一下什么是基于Dom树的Xpath定位检索方式,以及Xpath语法的规则以及如何使用集成Xpath第三方库来进行网络爬虫的编写。
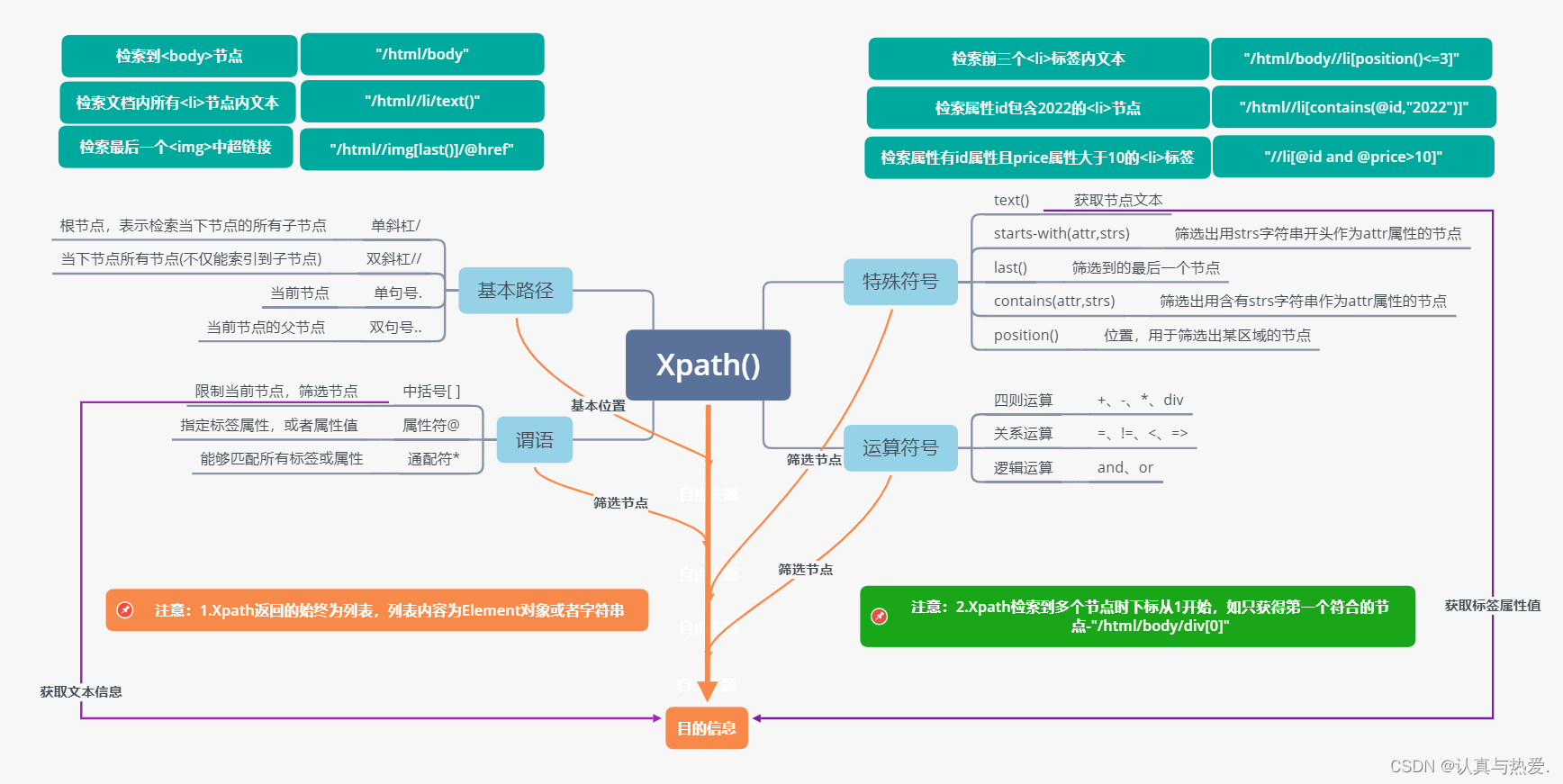
Xpath语法,全称为Xml Path Language,是一种专门用于检索HTML、XML文档的语言,可用来在xml和html文档中对元素和属性进行遍历,从而进行文档的检索、查询与修改。相比于正则表达式检索信息,Xpath检索速度比较慢,但是规则相对于简单,容易上手,因此这也是当下比较常用的爬虫定位方式。还有一点需要注意的是,正则表达式定位时,是将HTML文档视为整个字符串的,但是Xpath语法和css选择器的定位,它们都是基于Dom树进行检索的,利用树的节点层层筛选,来找的相应的目的内容。
二、 Xpath语法
注:为了学习并演示Xpath语法,在文章中的演示部分借助Python第三方库lxml中内置的Xpath方法,来进行演示(大部分基于Xpath进行爬虫信息定位检索的项目中,也都是基于lxml库来进行使用),基本流程如下:
- 调用etree模块转换HTML源码字符串:dom = lxml.etree.HTML(html_string)
- 调用Xpath语法进行检索定位:data = dom.xpath(“xpath语法”)
☆第三方库lxml安装:pip install lxml
演示所用的HTML代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>HTML网页测试</title>
</head>
<body>
<h1>生肖</h1>
<div class="auto_1">区域一
<li class="line_reai" id="p2022001">
<a title="mouse" href="https://hanyu.baidu.com/s?wd=%E9%BC%A0&from=poem"> 鼠 </a>
</li>
<li class="line_reai" id="p2022002">
<a title="cow" href="https://hanyu.baidu.com/s?wd=%E7%89%9B&from=zici"> 牛 </a>
</li>
<li class="line_reai" id="p2022003">
<a title="tiger" href="https://hanyu.baidu.com/s?wd=%E8%99%8E&from=poem"> 虎 </a>
</li>
</div>
<div class="auto_2">区域二
<li class="line_reai" id="p2022004">
<a title="rabbit" href="https://hanyu.baidu.com/s?wd=%E5%85%94&from=poem"> 兔 </a>
</li>
<li class="line_reai" id="p2022005">
<a title="dragon" href="https://hanyu.baidu.com/s?wd=%E9%BE%99&from=poem"> 龙 </a>
</li>
<li class="line_reai" id="p2022006">
<a title="snake" href="https://hanyu.baidu.com/s?wd=%E8%9B%87&from=poem"> 蛇 </a>
</li>
</div>
</body>
</html>
这个用于测试的HTML网页很简单,为了使得对其结构更加形象,我们可以看出它的Dom结构图像化如下:

2.1 基本组成
Xpath语法并不复杂,整体上可以视为四部分组成:基本路径符号、特殊符号、谓语、运算符。
| 类型 | 举例 | 返回列表内的元素类型 |
|---|---|---|
| 基本路径 | 双斜杠// 单斜杠/ 单句号. 双句号 | 节点对象 |
| 特殊符号 | [ ]、@、* | 节点对象 |
| 谓语 | text()、last()、starts-with()、contains()… | 节点对象或字符串 |
| 运算符 | +、-、=、<、and… | 节点对象 |
2.2 组成 —— 基本路径
在Xpath语法中,最基础的在于路径如何表示,首先经过.etree.HTML()函数转换后默认当前是在根节点即<html>-</html>处,类似于Linux操作系统下的一些路径表示方法,注意返回值是一个列表,列表中的元素是节点对象,下面来介绍一下常用的基本路基表示符号。
| 符号 | 作用 | 返回列表内的元素类型 |
|---|---|---|
单斜杠/ | 表示当下节点下的所有子节点(只包括子节点) | 节点对象 |
双斜杠// | 表示当下节点下所有节点 (包括子节点的子节点) | 节点对象 |
单句号. | 当前节点 | 节点对象 |
双句号.. | 当前节点的父节点 | 节点对象 |
① 单斜杠
/Dom树默认起始节点为<html>的节点,单斜杠必须要顺序检索,跳级会返回检索失败,返回空列表!因此若要顺序访问<body>,可以用如下方式进行开始索引:
- .xpath(“/html/body”)
- .xpath(“body”)
from lxml import etree
html_strs = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>HTML网页测试</title>
</head>
<body>
<h1>生肖</h1>
<div class="auto_1">区域一
<li class="line_reai" id="p2022001">
<a title="mouse" href="https://hanyu.baidu.com/s?wd=%E9%BC%A0&from=poem"> 鼠 </a>
</li>
<li class="line_reai" id="p2022002">
<a title="cow" href="https://hanyu.baidu.com/s?wd=%E7%89%9B&from=zici"> 牛 </a>
</li>
<li class="line_reai" id="p2022003">
<a title="tiger" href="https://hanyu.baidu.com/s?wd=%E8%99%8E&from=poem"> 虎 </a>
</li>
</div>
<div class="auto_2">区域二
<li class="line_reai" id="p2022004">
<a title="rabbit" href="https://hanyu.baidu.com/s?wd=%E5%85%94&from=poem"> 兔 </a>
</li>
<li class="line_reai" id="p2022005">
<a title="dragon" href="https://hanyu.baidu.com/s?wd=%E9%BE%99&from=poem"> 龙 </a>
</li>
<li class="line_reai" id="p2022006">
<a title="snake" href="https://hanyu.baidu.com/s?wd=%E8%9B%87&from=poem"> 蛇 </a>
</li>
</div>
</body>
</html>
'''
# 根节点/
# 检索到<html> - <body> - <div>中
# 根节点/演示 -- 两种起始检索形式作用一样:都会返回为<div>节点对象为元素的列表
dom = etree.HTML(html_strs)
ans = dom.xpath("/html/body/div")
print('xpath("/html/body/div")索引结果:', ans)
ans2 = dom.xpath("body/div")
print('xpath("body/div")索引结果:', ans2)
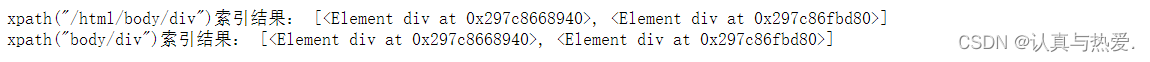
② 双斜杠
//双斜杠//与单斜杠一样,都用来表示基本路径,但唯一不同的是,双斜杠会检索当下节点的所有节点、包括节点的子节点…
# //
# 使用//跳级检索所有符合条件的节点
# 检索到<html> - <body> - <div>中
dom = etree.HTML(html_strs)
ans3 = dom.xpath("/html//div")
print('xpath("/html//div")', ans3)
ans4 = dom.xpath("//div")
print('xpath("//div")索引结果:', ans4)

③ 单句号
.单句号来表示当前节点,与Linux操作系统中命令很相似
# .
# 从根节点检索到<body>
dom = etree.HTML(html_strs)
# "./body" 等价于 body
ans5 = dom.xpath("./body")
print('xpath("./body")索引结果:', ans5)

④ 双句号
..单句号来表示当前节点的父节点,与Linux操作系统中命令很相似
#..
# 从<body>节点借助父节点访问<head>节点
# 进入<body>节点
dom = etree.HTML(html_strs)
ans5 = dom.xpath("./body")
print('xpath("./body")索引结果:', ans5)
# <body> -> <head>
ans6 = ans5[0].xpath("../head")
print('.xpath("../head")索引结果:', ans6)

2.3 组成 —— 特殊符号
根据基本路径符号我们已经能够大体上进行Dom树的检索,但是有一个缺点,就是不够具体,像使用xpath(“//div”)时,我们会检索到该节点下的所有div节点对象,但是在具体应用中,我们有时候需要检索某个、或者某些div节点对象,并非所有。因此在此特殊符号就起到了这个关键作用,它能够对标签进行筛选、限制,从而能够检索到我们想要的内容,这些符号与谓语、运算符号结合起来,就能拥有强大的细化定位功能。
| 符号 | 作用 |
|---|---|
中括号[] | 限制当前节点,筛选符合条件的节点 |
符号@ | 指定某个属性来限制节点,或者获得某个属性值 |
符号* | 通配符,匹配所有节点或属性 |
① 中括号
[]中括号作用就是用来标志要对当前节点进行限制并筛选(需要结合谓语或运算符号等),也可以用作索引功能,需要格外注意的是,进行索引时Xpath的下标是从1开始的!
#[]
# 只要<body>中第二个<div>节点
dom = etree.HTML(html_strs)
# 不使用[]直接取<div>
ans7 = dom.xpath("/html/body/div")
print('.xpath("/html/body/div")索引结果:', ans7)
# 使用[]只取第二个<div>,注意下标是2不是1
ans8 = dom.xpath("/html/body/div[2]")
print('.xpath("/html/body/div[2]")索引结果:', ans8)
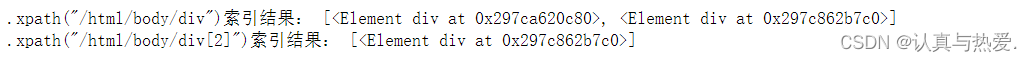
② 属性符号
@@符号用来限定具有某一属性值的节点,定位时一般要与中括号结合使用,@属性名称代表此节点的属性值,之后就可以使用运算符号像“=”、“>”进行筛选限制,也可以进行对
- @与[]等结合使用,用来定位节点
直接使用@,获取节点的某个属性值
# 用法一:借助@使用属性定位
# 只要<body>中的<div>标签,而且这个标签必须有属性class,且class=“auto_2”
# 也就是第二个<div>,此时通过是否含有某项属性值来进行筛选
dom = etree.HTML(html_strs)
# 不使用[]直接取<div>
ans7 = dom.xpath("/html/body/div")
print('.xpath("/html/body/div")索引结果:', ans7)
# 使用[@]只取第二个<div>
ans8 = dom.xpath("/html/body/div[@class='auto_2']")
print('.xpath("/html/body/div[@class=\'auto_2\']")索引结果:', ans8)

# 用法二:获取@属性值
# 抽取第一个<div>中所有<li>中<a>的超链接,即<a>中href的值
ans9 = dom.xpath("/html/body/div[1]/li/a")
print('.xpath("/html/body/div[1]/li/a")索引结果:\n', ans9)
ans10 = dom.xpath("/html/body/div[1]/li/a/@href")
print('.xpath("/html/body/div[1]/li/a/@href")索引结果:\n', ans10)
# 等效操作
# ans11 = dom.xpath("//div[@class='auto_1']//a/@href")

③ 通配符号
*星号*为通配符,和Linux中的*号作用相似,用来匹配所有的标签或者属性,也能与中括号等其他结合进行使用
# 在节点筛选上使用通配符*
# 匹配<body>中的所有节点,节点必须包括class属性,也就是两个div节点
dom = etree.HTML(html_strs)
# 不使用[]直接匹配
ans9 = dom.xpath("/html/body/*")
print('.xpath("/html/body/*")索引结果:', ans9)
# 通配符结合[@]筛选使用
ans10 = dom.xpath("/html/body/*[@class]")
print('.xpath("/html/body/*[@class]")索引结果:', ans10)

# 在属性上使用通配符*
# 匹配<h1>且含有属性的节点 没有,唯一的<body>-<h1>标签没有属性
dom = etree.HTML(html_strs)
# 只筛选<h1>标签
ans11 = dom.xpath("//h1")
print('.xpath("//h1")索引结果:', ans11)
# 不仅为<h1>标签,而且需要至少含有一个属性
ans12 = dom.xpath("//h1[@*]")
print('.xpath("//h1[@*]")索引结果:', ans12)
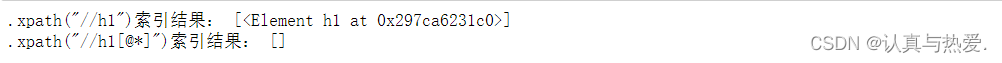
2.5 组成 —— 谓语
谓语,从字面上来理解就是指要对当前的节点做什么操作,这也十分符合它的作用。在上面我们已经能够通过路径以及定位符找到任意一个节点,接下来最重要的也就是如何将此节点的文本信息输出出来的,谓语就含有这个功能,他能帮我们提取出文本信息或者某个属性信息,而且他也能进行定位。接下来我们来认识一下常用的谓词。
| 谓词 | 作用 | 返回列表内的元素类型 |
|---|---|---|
text() | 挑选出此节点中的文本数据 | 字符串 |
| strats - with(attr, strs) | 与[]结合使用,匹配某一节点必须指定的属性以指定的字符开头 | 节点对象 |
| last() | 与[]结合使用,意为检索到的最后一个节点对象 | 节点对象 |
| contains(attr, strs) | 与[]结合使用,匹配某一节点必须指定的属性包含指定的子串 | 节点对象 |
| position() | 与[]、算术运算符结合使用,切片操作,以位置筛选区域节点 | 节点对象 |
① 谓词
text()HTML文本中有着标签、属性、文本的概念,文本就是闭合标签中镶嵌的文字,一般爬虫所需要爬取的信息就是文本数据,因此使用text()就能获得文本字符串。
# text()
# 挑出节点<html>-<body>-<div>-<li>-<a>的文本数据, 也就是六个属相
dom = etree.HTML(html_strs)
ans13 = dom.xpath("/html/body/div/li/a/text()")
print('.xpath("/html/body/div/li/a/text()")索引结果:\n', ans13)
# 等效
# ans14 = dom.xpath("//div//a/text()")

② 谓词 strats - with(attr, strs)
starts - with()谓词一般要与[@]结合使用,它也是限制节点的一种方式,有时候某一属性值很长,或者是想要检索的某些节点都含有相同属性,但是属性值略微不同,此时这个谓词就能很好解决这种问题。
# starts - with()
# 挑出节点html>-<body>-<div>,<div>必须要有class属性且必须一au开头 两个<div>都符合
dom = etree.HTML(html_strs)
ans14 = dom.xpath("/html/body/div[starts-with(@class, 'au')]")
print('.xpath("/html/body/div[starts-with(@class, \'au\')]")索引结果:\n', ans14)
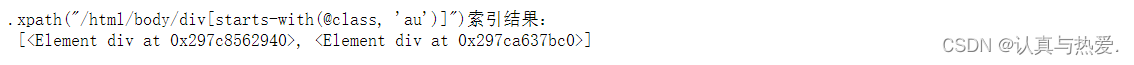
③ 谓词 last()
谓词last()也需要结合[]使用,last()表示当前检索到节点集合中最后一个节点,类似于python索引中的-1,它可以支持算术运算符,像[last()-1]就是倒数第二位节点。
# last()
# 挑出前六个属相中,倒数第二个属相名称与链接 龙
dom = etree.HTML(html_strs)
name = dom.xpath("/html/body/div[last()]/li[last()-1]/a/text()")
url = dom.xpath("/html/body/div[last()]/li[last()-1]/a/@href")
name, url

④ 谓词
contains(attr, strs)与starts-with(attr, strs)谓词相似,差别在于contains定位时要求是节点的属性包括子字符串strs,使用场景和starts-with差不多,根据需求可以借助这两种谓词进行定位筛选。
# contains()
# 挑出节点<html>-<body>-<div>,<div>必须要有class属性且含有to 两个<div>都符合
dom = etree.HTML(html_strs)
ans15 = dom.xpath("/html/body/div[contains(@class, 'to')]")
print('.xpath("/html/body/div[starts-with(@class, \'to\')]")索引结果:\n', ans15)

⑤ 谓词 position()
position()一般也要与[]结合使用,它经常用来进行类似于切片操作,可与运算符号进行结合使用,像取前两个节点可表示为[position()< 3]。
# position()
# 挑出前两个属相的名称与链接
dom = etree.HTML(html_strs)
names = dom.xpath("/html/body/div[1]/li[position()<3]/a/text()")
urls = dom.xpath("/html/body/div[1]/li[position()<3]/a/@href")
names, urls

2.6 组成 —— 运算符号
通过基本路径符号、特殊符号与定位符号就能够检索到大部分目的信息,而最后一部分的运算符号也是用来结合特殊符号和谓语进行定位的,刚刚例子也有涉及到四则运算符号的使用,在此我们简单总结一下常用运算符号。
| 运算 | 包含 |
|---|---|
| 四则运算 | +、-、*、div |
| 关系运算 | =、!=、<、<=、>、>= |
| 逻辑运算 | and、or |
① 四则运算
- 四则运算在介绍last()谓词时进行了简单实例:选择符合条件的倒数第二个节点-[last()-1];
② 关系运算
- 关系运算在介绍@时进行了简单实例:挑选某个含有特定属性值的节点-[@class=“auto_2”];
③ 逻辑运算
逻辑符号主要包括逻辑且“and”、逻辑或“or”,这两个也是需要结合[]进行使用,进行节点筛选的,通过逻辑运算,可以指定多种筛选规则。
# 逻辑运算符and
# 挑选出<li>标签,且其必须含有class、id属性,且id属性必须含有"001"字符 鼠所在的<li>标签
dom = etree.HTML(html_strs)
ans16 = dom.xpath("/html/body//li[@class and contains(@id, '001')]")
# 查看是否为“鼠”的<li>标签
# 注意xpath返回的是节点对象的列表,因此此处要先进行[0]取节点对象再xpath
name = ans16[0].xpath("./a/text()")
url = ans16[0].xpath("./a/@href")
print(name, url)
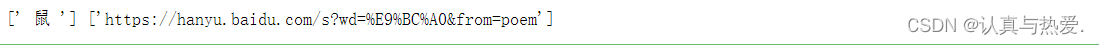
# 逻辑运算or
# 挑选出<li>标签,且其必须含有id属性,且id属性必须含有"001"或者"006"字符 鼠、蛇所在的<li>标签
dom = etree.HTML(html_strs)
ans16 = dom.xpath("/html/body//li[contains(@id, '001') or contains(@id, '006')]")
# 查看是否为“鼠\蛇”的<li>标签
# 注意xpath返回的是节点对象的列表,因此此处要先取节点对象再xpath
for ans in ans16:
name = ans.xpath("./a/text()")
url = ans.xpath("./a/@href")
print(name, url)

2.7 简单实例
基本上xpath的语法就已经了解完了,只要能够熟练掌握这些规则,在爬取某个网站时能够根据具体情况进行Xptah信息定位检索,就能够完成简单的爬虫项目了;接下来模拟上面的html源码已知,进行一些信息的定位爬取举例。
# 任务应用:抽取所有属相与对应链接
# 转换数据类型
dom = etree.HTML(html_strs)
# 检索到<body>下所有<a>
datas = dom.xpath("/html/body//a")
for data in datas:
# 每一个都是节点类型,名字在节点的文本中,链接在标签的href属性中
name = data.xpath("./text()")[0] # 返回值为列表,提取其中数据
url = data.xpath("./@href")[0]
print(f"属相:{name} 链接:{url}")

三、Xpath总结
在使用xpath定位时要格外注意的点如下:
- 注意区分路径/与//的区别,/只能检索到节点下的子节点,//会检索到子节点的子节点…
- 检索开始时可以"/html/body"、“body”、“//body”、切勿"/body"开始
- 检索进行时注意检索到的节点序列是从1开始的,且返回值必定是
列表, "//div[0]"不正确- 检索时只有节点类型才能使用xpath,使用xpath返回值再次进行xpath时注意不能直接使用
四、结尾
在此关于定位方法Xpath的规则已经介绍完了,xpath一般只是用来针对于HTML、XML文件进行定位检索的,并不像正则匹配那样应用广泛,但是规则简单,容易上手,因此在制作简单的爬虫代码时是一个不错的选择,在之后的内容里会介绍一下lxml库,以及分享一篇完整的爬虫实例代码。
文章和代码都为原创,在记录分享此篇文章查阅了很多资料,也对文章内容和代码进行很多次修改,作者水平有限,难免出现一些错误或者问题,因此内容仅供参考,也欢迎大家提出问题共同讨论,共同进步。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









