







前提内容
- 正则表达式的构建:正则表达式(理论+代码演示)
本节梗概
- 学习使用python内置正则库re
文章目录
一、引入
在上一篇内容已经对正则表达式进行简单介绍,正则不仅仅能用在爬虫获取信息内容上,它是一种筛选字符串,检索信息的手段,像在Linux操作系统命令检索筛选、数据库筛选记录等很多地方都会用到正则匹配,因此正则规则是计算机程序员需要了解的知识。那么在爬虫数据检索中如何引入正则呢,Python的内置库re为我们提供了便捷的API,因此在此我们就简单了解一下re库的组成。
二、组成与使用方法
2.1 对象介绍 —— 正则模板(re.Pattern对象)
在正则中,重要的就在于构建正则模板,用于筛选、过滤出子串。在re库中,把这种正则模板定为为re.Pattern对象,在re的其他很多函数中都可以直接使用这个对象,此对象的创建方式如下。
① re.compile() 方法
re.compile(pattern, flags):
创建re.Pattern对象函数;接收字符串形式正则模板,返回为re.Pattern类型对象的正则模板
| 参数 | 说明/类型 |
|---|---|
| pattern | 正则模板;字符串 |
| flags | 匹配模式,默认模式:严格区分大小写,不能换行匹配等;RegeFlag |
| 返回值 | 正则模板;re.Pattern |
import re
# re.compile(pattern, flags)
# 参数:
# pattern:正则模板;字符串
# flags:匹配模式;RegeFlag;默认模式:严格区分大小写,不能换行匹配等
# 返回值:re.Pattern
pattern = re.compile(r"\s")
type(pattern)

② 对象属性
re.Pattern对象自身所具有的属性如下
| 属性 | 解释 |
|---|---|
| .pattern | 字符串模板 |
| .flags | 匹配模式 |
| .groups | 分组数量,即小括号个数 |
| .groupindex | 有别名的分组字典,别名为键,组别为值 |
import re
pattern = re.compile(r"name:(?P<name>.*?) .*?score:(?P<score>.*?) ", re.I)
# 正则模板:匹配名字与分数,并将分组后的值依次起别名name、score
strs = "This is a message: name:Mike score:100 "
a = pattern.findall(strs)
print(type(pattern))
print(".pattern属性", pattern.pattern)
print(".flags属性", pattern.flags)
print(".groups属性", pattern.groups)
print(".groupindex属性", pattern.groupindex)
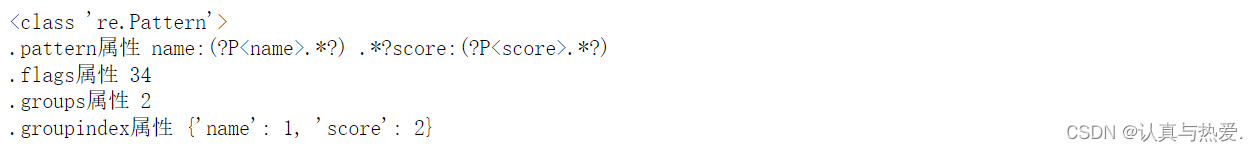
③ 对象方法
re.Pattern能够基本上能够直接调用全部re库中所有方法:
在2.4中介绍的方法re.Pattern均可直接调用:像Pattern.findall()、Pattern.finditer()…
2.2 对象介绍 —— re.match对象
在re正则库之中,还有一个经常返回得到的对象re.match,此对象可以通过一些re库中的方法可以返回得到(比如re.match()、re.search()、re.finditer()这些方法在下面会进行解释)。得到此对象的正则模板需要使用小括号确定关注部分,也被称为分组,此对象含有一些常用属性,如下表。
| 属性/方法 | 解释/形式 |
|---|---|
| .string | 被处理的字符串 |
| .re | 处理时的正则模板 |
| .pos | 正则表达式搜索文本的开始位置索引 |
| .endpos | 正则表达式搜索文本的末尾位置索引 |
| .groups() | 被匹配到的子串中小括号中内容 |
| .group(i) | 被匹配到的子串中第i个小括号里内容,索引为0时返回对应原子串 |
| .start() | 被匹配到的子串在原字符串中起始索引 |
| .end() | 被匹配到的子串在原字符串中末尾索引 |
| .span() | 被匹配到的子串在原字符串中起始与末尾索引 |
(使用re.search()方法:检索第一个正则模板匹配到的子串,来获得其re.match形式对象进行演示)。
import re
# re.match对象属性与方法的代码测试
strs = """
students datas
NAME:Alice | SCORE:100 |
Name:Jack | Score:90 |
name:Mike | score:95 |
tip: 2022.10.17"""
pattern = re.compile("name:(.*?) .*?score:(.*?) ", re.I)
answer = re.search(pattern=pattern, string = strs)
print(type(answer))
print("match的属性:")
print("属性.string:", answer.string)
print("属性.re:", answer.re)
print("属性.pos:", answer.pos)
print("属性.endpos:", answer.endpos)
print("match的方法:")
print("方法.groups():", answer.groups())
print("方法..group(0):", answer.group(0))
print("方法..group(i):", answer.group(1))
print("方法.start():", answer.start())
print("方法.end():", answer.end())
print("方法.span():", answer.span())

2.3 对象介绍 ——匹配模式(RegexFlag对象)
在进行正则筛选时,re正则默认的模式是:严格区分大小写、不允许隔行匹配,^$标志的开头结尾针对全文,并非每行…为使得匹配更加灵活,在正则匹配时设置了匹配模式对象RegexFlag,使得用户能够按照需求切换匹配方式。
| 模式 | 介绍 |
|---|---|
| re.S | 全文匹配,允许隔行匹配,.号允许匹配换行符 |
| re.I | 模糊匹配,不再严格区分英文大小写 |
| re.M | 多行匹配,匹配时每行头尾视为开头结尾,只对元字符^、$起作用 |
| re.A | ASCII匹配,匹配时只匹配ASCII字符,只对字符集\w,\W,\s,\S等起作用 |
| re.X | 注释模式,允许为正则模板添加注释,增加正则模板可读性 |
RegexFlag也是re库中经常使用的对象,为了充分体现各个模式的区别,以下将使用不同的匹配模式构建re.Pattern类型对象,并且调用re.Pattern对象的.findall()方法进行举例;findall方法即使用正则模板对字符串进行筛选,在其后会进行这个方法进行详细解释;
① re.DOTALL 与 re.S:全文匹配
默认模式下,正则模板会依次对每一行进行检索,当前行不匹配时到达下一行则重新开始匹配(原因:不同行之间在其看来由换行符\n连接)
re.S模式下,元字符"."允许匹配换行符\n,导致匹配模板不再单单限制与单行匹配
import re
# re.DOTALL 与 re.S
# re.S模式:全文查找,忽略换行,将全文视为一行字符串(所有行间按换行符连接);默认是按行查询,即换行后重新匹配
# 在此模式下元字符.可以匹配换行符
# 目标:提取文章中花所涉及的颜色
test_txt = """有些花颜色
是粉色,叶子颜色是青色;有些花颜色是紫色,叶子颜色
是白色"""
pattern1 = re.compile("花.*?是(.*?色)")
pattern2 = re.compile("花.*?是(.*?色)", re.S)
print("普通模式:", pattern1.findall(test_txt), "\nre.S模式:",pattern2.findall(test_txt))

② re.I 于 re.IGNORECASE:模糊匹配
默认模式下,严格区分英文大小写
在re.I模式下,忽略英文大小写进行匹配
import re
# re.IGNORECASE 与 re.I
# re.I模式:忽略大小写;默认是严格区分大小写的
# 目标:提取所有名字
test_txt = """
Name:Alice sex:girl
NAME:Jake sex:boy
name:Mike sex:boy"""
pattern1 = re.compile("name:(.*?) ")
pattern2 = re.compile("name:(.*?) ", re.I)
print("普通模式:", pattern1.findall(test_txt), "\nre.I模式:",pattern2.findall(test_txt))

③ re.M 与 re.MULTILINE:多行匹配
对于元字符^与$,对应的开头位置与结尾位置是以全文来看的
在re.M模式下,元字符^与$对应的开头与结尾是针对于每一行来看的
import re
# re.M 与 re.MULTILINE
# re.M模式:指针对于起始标志^与末尾标志$使用,限制为行头和行尾;默认是全文开头与末尾
test_txt = """12月是特别的1月,
5月也很特别!
"""
pattern1 = re.compile("^(\d*)月")
pattern2 = re.compile("^(\d*)月", re.M)
print("普通模式:", pattern1.findall(test_txt), "\nre.M模式:",pattern2.findall(test_txt))

④ re.A 与 re.ASCII: ASCII匹配
默认情况下,使字符集\w, \W, \d, \D, \s和\S等其各自有自己的范围
在ASCII匹配模式下,匹配成功的字符必须在原基础上还要符合是ASCII字符才可以(比如文本字符集\w在此模式下不能匹配到汉字)
☆补充:ASCII字符:大小写英文字母、标点符号、阿拉伯数字、数学符号、控制字符等共128个字符,一个ASCII码占一个字节,用7位二进制数编码组成
import re
# re.A 与 re.ASCII
# 目标:提取除汉字外的文本字符
test_txt = "__Birthday__:5月27日"
pattern1 = re.compile(r"\w")
pattern2 = re.compile(r"\w", re.A)
print("普通模式:", pattern1.findall(test_txt), "\nre.A模式:",pattern2.findall(test_txt))
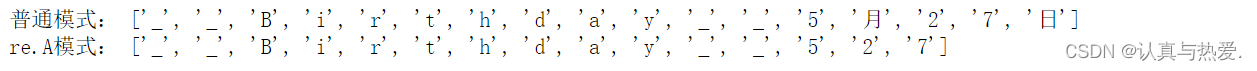
⑤ re.X 与 re.VERBOSE 注释模式
默认情况下,构建的re.Pattern是不会自带注释的
在注释模式下,可以通过#来为其添加注释,注释并不会影响正则模块的构建,只是为了增加代码可读性
import re
# re.X 与 re.VERBOSE
# re.X 模式:在正则匹配中添加注释,#后写注释,会忽略#前到#后的空白
test_txt = "12月是特别的一月,5月也很特别!"
pattern1 = re.compile(r"\d{1,2}.")
pattern2 = re.compile(r"""
\d{1,2} #匹配月份数字
. #匹配 月 字""", re.X)
# 添不添注释不会影响结果,只是为了增加可读性
print("普通模式:", pattern1.findall(test_txt), "\nre.X模式:",pattern2.findall(test_txt))

⑥ 模式混合
所有的模式并不是只能单一使用,在实际应用中可以按照需求使用多个,混合使用,模式之间使用“|”连接即可
# 模式混合
# 模式并不是单一选择的,可以按照需求多选,以|连接
# 目标:获取所有记录的当前名字
test_txt = """
Name:Alice sex:girl
NAME:Jake old_name:Jcke sex:boy
name:Mike sex:boy"""
pattern1 = re.compile("^name:(.*?) ",re.M)
pattern2 = re.compile("name:(.*?) ",re.I)
pattern3 = re.compile("^name:(.*?) ",re.M|re.I)
print("re.M模式:", pattern1.findall(test_txt), "\nre.I模式:",pattern2.findall(test_txt))
print("re.M|re.I模式:", pattern3.findall(test_txt))

2.4 方法介绍
① re.findall()
re.findall(pattern, string, pos, endpos, flags):从字符串中筛选出所有符合正则模板的子串,以列表形式返回
| 参数 | 说明 |
|---|---|
| pattern | 筛选模板;字符串 或者 re.Pattern 对象(若为re.Pattern对象则不需要指定flags参数) |
| string | 需处理的字符串;字符串 |
| pos | 范围开始的索引,默认为0;int |
| endpos | 范围结束的索引,默认为string长度;int |
| flags | 匹配模式,若传入的pattern参数为re.Pattern对象,则不再允许指定此参数;RegexFlag |
| 返回值 | 列表,如果正则模板含有小括号分组,则返回以元祖为元素的列表 |
import re
# re.findall(pattern, string, pos, endpos, flags=0)
# pattren:正则模板;字符串 或者 re.Pattern 对象(若re.Pattern对象则不需要再指定flags参数)
# string:需处理的字符串
# pos:范围开始的索引,默认为0;int
# endpos:范围结束的索引,默认为string长度;int
# 返回值:列表,如果正则模板含有小括号,则返回以元祖为元素的列表
strs = """
NAME:Alice | SCORE:100 |
Name:Jack | Score:90 |
name:Mike | score:95 |
"""
pattern = re.compile("name:(.*?) .*?score:(.*?) ", re.I)
# answer = re.findall(pattern=pattern, string=strs)
# 也可以直接调用re.Pattern的.findall方法
answer = pattern.findall(strs)
answer

② re.finditer()
re.finditer(pattern, string, flags):从字符串中筛选出所有符合正则模板的子串,并以re.match的迭代对象返回
| 参数 | 说明 |
|---|---|
| pattern | 筛选模板;字符串 或者 re.Pattern 对象(若为re.Pattern对象则不需要指定flags参数) |
| string | 需处理的字符串;字符串 |
| flags | 匹配模式,若传入的pattern参数为re.Pattern对象,则不再允许指定此参数;RegexFlag |
| 返回值 | 以re.match为元素的迭代对象 |
# re.finditer(pattern, string, flags=0)
# 搜索所有符合子串,返回元素为re.match对象的迭代对象
strs = """
NAME:Alice | SCORE:100 |
Name:Jack | Score:90 |
name:Mike | score:95 |
"""
pattern = re.compile("name:(.*?) .*?score:(.*?) ", re.I)
answers = re.finditer(pattern=pattern, string=strs)
for answer in answers:
print(answer.groups(), type(answer))

③ re.search()
re.search(pattern,string,flags):从字符串中筛选出第一个符合正则模板的子串,并以re.match对象返回,没找到则返回None
| 参数 | 说明 |
|---|---|
| pattern | 筛选模板;字符串 或者 re.Pattern 对象,正则模板需要结合小括号的分组方法 |
| string | 需处理的字符串;字符串 |
| flags | 匹配模式,若传入的pattern参数为re.Pattern对象,则不再允许指定此参数;RegexFlag |
| 返回值 | re.match对象,或者None |
import re
# re.search(pattern,string,flags=0)
# 只搜索第一个匹配的子字符串,返回re.match对象(需要与小括号结合使用),没有搜索到就返回为None
# pattern:正则模板;字符串 或者 re.Pattern 对象(若re.Pattern对象则不需要再使用flag模式)
# string:需处理的字符串;字符串
# flags:匹配模式
strs = """NAME:Alice | SCORE:100 |
Name:Jack | Score:90 |
name:Mike | score:95 |
tip: 2022.10.17"""
pattern = re.compile("name:(.*?) .*?score:(.*?) ", re.I)
answer = re.search(pattern=pattern, string = strs)
# 查看正则匹配结果
print(answer.groups())
# 查看匹配到的子串(忽略小括号作用)
print(answer.group(0))
# 获取此字符串中第一个小括号内容
print(answer.group(1))
# 获取此字符串中第二个小括号内容
print(answer.group(2))

④ re.match()
re.match(pattern,string,flags):从字符串中筛选出起始位置匹配符合正则模板的子串,并以re.match对象返回,不符合则返回None
| 参数 | 说明 |
|---|---|
| pattern | 筛选模板;字符串 或者 re.Pattern 对象,正则模板需要结合小括号使用 |
| string | 需处理的字符串;字符串 |
| flags | 匹配模式,若传入的pattern参数为re.Pattern对象,则不再允许指定此参数;RegexFlag |
| 返回值 | re.match对象,或者None |
import re
# re.match(pattern,string,[flags])
# 只从开头位置搜索是否匹配,若匹配返回re.match对象,不匹配则返回None
strs = """NAME:Alice | SCORE:100 |
Name:Jack | Score:90 |
name:Mike | score:95 |
"""
pattern = re.compile("name:(.*?) .*?score:(.*?) ", re.I)
answer = re.match(pattern=pattern, string=strs)
print(answer.groups())

⑤ re.sub()
re.sub(pattern,repl,string,count,flag):将字符串中的某种子串进行替换
| 参数 | 解释/形式 |
|---|---|
| pattern | 正则模板;字符串 或者 re.Pattern 对象(若re.Pattern对象则不需要再指定flags参数) |
| string | 待处理的字符串;字符串 |
| flags | 匹配模式,默认模式:严格区分大小写,不能换行匹配等;RegeFlag |
| repl | 替换后的字符串;字符串 |
| count | 修改前多少个,默认为0修改全部;int |
| 返回值 | 返回字符串 |
import re
# re.sub(pattern=,repl=,string=,count=,flags=)
# 参数:
# pattren:正则模板;字符串 或者 re.Pattern 对象(若re.Pattern对象则不需要再使用flags模式)
# repl: 替换后形式;字符串
# string:需处理的字符串;字符串
# count:修改的前多少个,默认为0修改全部;int
# flags:匹配模式,如果传入pattern对象自带RegeFlag则此处不可以指定模式;RegeFlag对象
# 返回值: 替换过后的字符串;字符串
strs = """
NAME:Alice SCORE:100
Name:Jack Score:90
name:Mike score:95
"""
# 方法一:pattern传参为字符串,使用flags指定模式匹配
new_strs = re.sub(pattern="score", repl="grade", string=strs, count=0, flags=re.I)
print(new_strs)
# 方法二:pattern传参为re.Pattern对象
pattern = re.compile("score", re.I)
new_strs = re.sub(pattern=pattern, repl="grade", string=strs, count=0)
print(new_strs)

⑥ re.split()
re.split(pattern, string, maxsplit, flags):以正则模板为分界标志,对字符串进行拆分,返回子串形成的列表
| 参数 | 解释/形式 |
|---|---|
| pattern | 正则模板;字符串 或者 re.Pattern 对象(若re.Pattern对象则不需要再指定flags参数) |
| string | 待处理的字符串;字符串 |
| flags | 匹配模式,默认模式:严格区分大小写,不能换行匹配等;RegeFlag |
| maxsplit | 最大分割次数,默认为0分割全部;int |
| 返回值 | 返回以字符串为元素的列表 |
import re
# re.split(pattern, string[, maxsplit=0, flags=0])
# 以pattern为标志分割字符串
# pattern:替换前形式;字符串 或者 re.Pattern 对象(若re.Pattern对象则不需要再使用flags模式)
# string:需处理的字符串;字符串
# flags:匹配模式
# maxsplit:最大切割次数
# 返回:列表
strs = "三种选择:可以学数学,或者学语文,或者学计算机"
pattern = re.compile("可以|或者")
answer = re.split(pattern=pattern, string=strs)
answer

三. re库总结
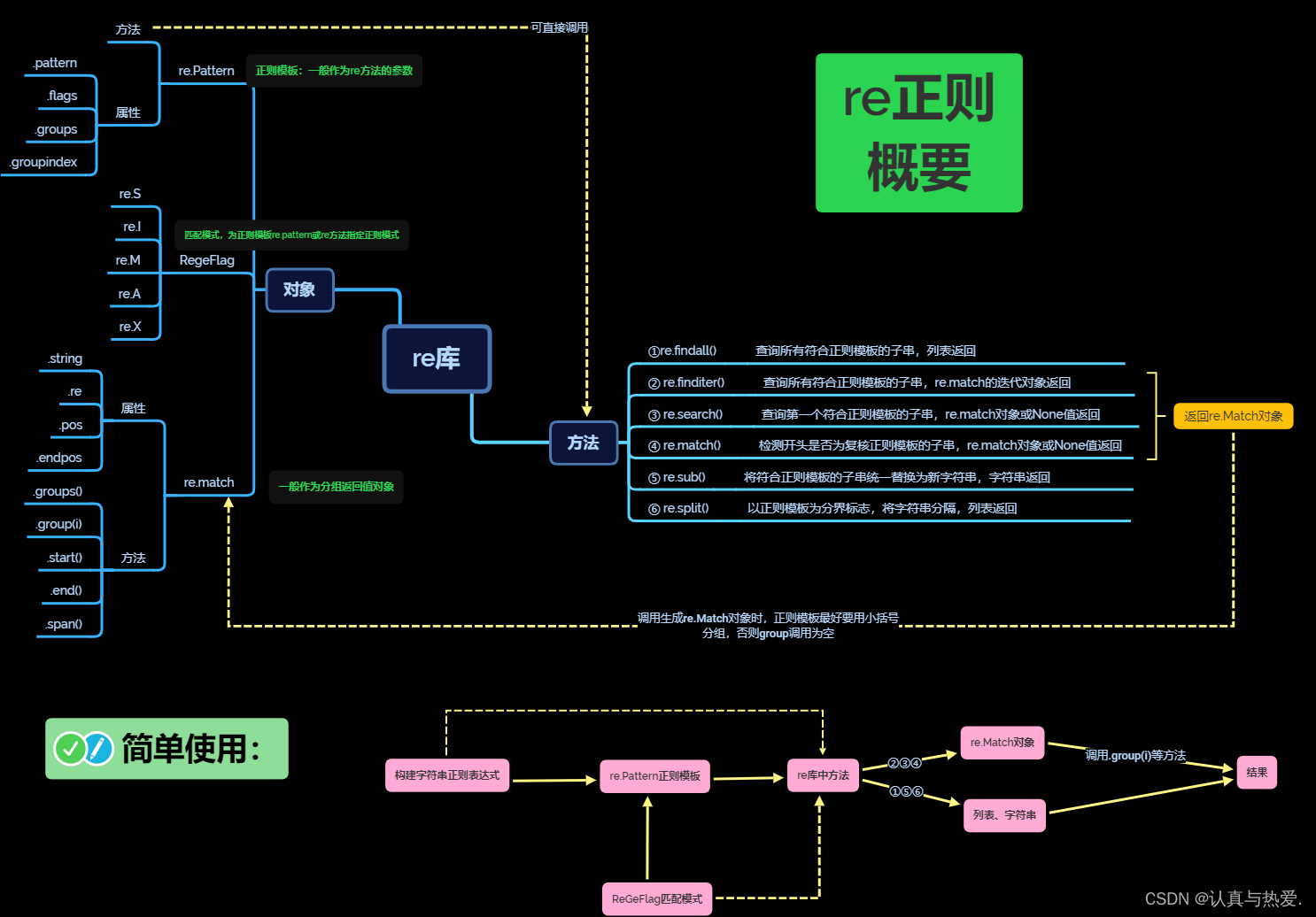
四、总结
在此已经对re库分享了简单的使用方法与思路,通过urllib库、正则技术,已经能够实现简单的爬虫代码,下一篇会对如何结合这两种库完成简单的爬虫实例进行思路分享与代码演示。
文章和代码都为原创,在记录分享此篇文章查阅了很多资料,也对文章内容和代码进行很多次修改,作者水平有限,难免出现一些错误或者问题,因此内容仅供参考,也欢迎大家提出问题共同讨论,共同进步。















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









