







- 论文题目:InversionNet: An Efficient and Accurate Data-Driven Full Waveform Inversion
- 论文作者:Yue Wu and Youzuo Lin
- 论文发表:IEEE Transactions on Computational Imaging ( Volume: 6)
- 面向数据集:OpenFWI中的Vel类、Fault类、Style类(时间域与宽度的比值很高,(1000,70))
InversionNet:深度学习实现的反演
InversionNet构建了一个具有编码器-解码器结构的卷积神经网络,以模拟地震数据与地下速度结构的对应关系。
1 编码器
编码器主要是用卷积层构建的,它从输入的地震数据中提取高级特征,并将它们压缩成单一的高维向量。注:在最后一个卷积层中并没有实施填充零的操作,以便将特征向量压缩为单一的高维向量。
采用的是非方形卷积,主要起到了压缩空间的作用,因为输入的地震波形图像的时间维度(图像的高)的尺度过大。

这个高维向量是由1*1的图块构成512通道张量。可以将其认为是一个512维的向量,这样压缩信息是是合理的,因为没有必要保留地震数据中的时间和空间相关性(1*1是对空间信息有一定程度的舍弃)。但有人写了论文不赞同该思想,后面表明这也是InversionNet的一个缺点:对空间进行了舍弃。
编码过程如下: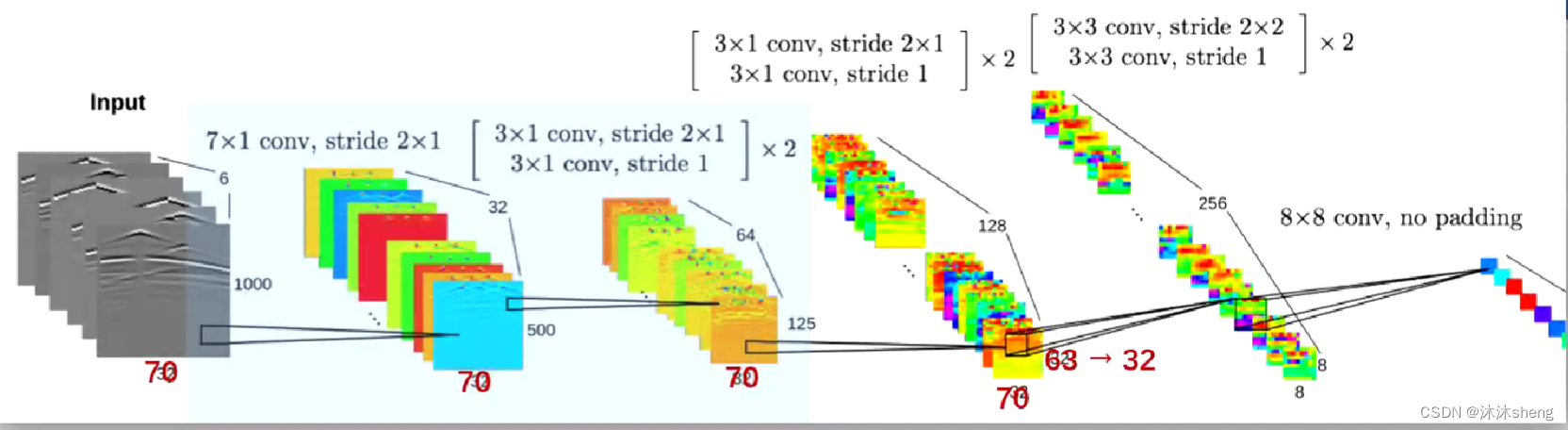



注:并没有使用原论文中提到了1000*32的数据,而是1000*70的OpenFWI中的数据。因此这里采用的代码是参照OpenFWI论文(2022)中公开的InversionNet修改版代码,在这个代码里面的卷积过程与原2019年发布的InversionNet论文中所示的架构存在一定程度的差异。
2 解码器
解码器通过一组反卷积将这些特征转换成速度模型。反卷积(转置卷积)可以将图像的维度进行升维,同时最大程度保留图像原本性质。这可以通过在输入特征图上填充零来实现,反卷积的效果比一般的反池化操作拥有更好的效果。
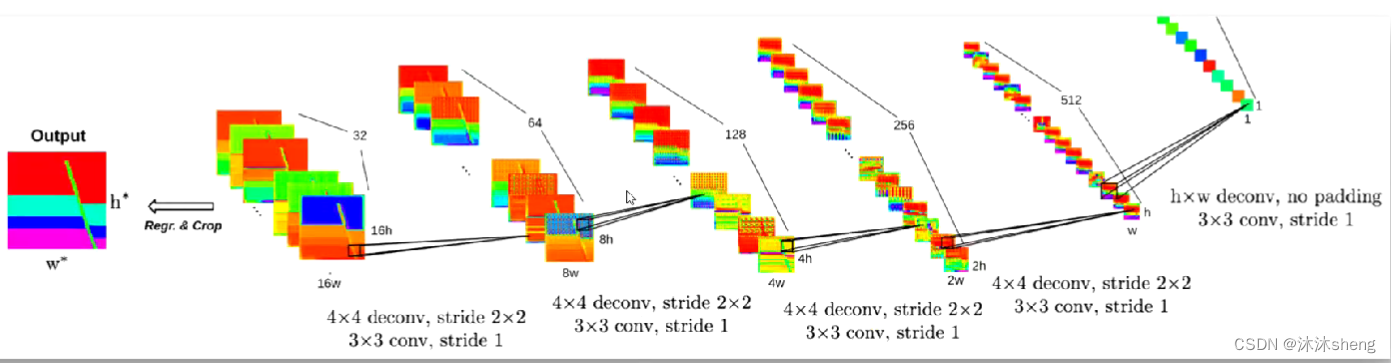
架构中给出h和w是方便用户适配更多的速度模型环境,对于70*70的速度模型,作者给出的h=w=5,这样模型最终输出的尺寸就是80*80,通过裁剪得到70*70。
3 代码介绍
网络结构中展示的每个卷积操作实质上都是由卷积层,批归一化(BN)和LeakyReLU共同构成组成。
在卷积层中,卷积承担输入信号的责任,同时担任滤波器的作用以提取有意义的特征。卷积是应用于DL-FWI问题的理想方法,因为地震测量在空间上是连续的,而卷积层的局部连通性和权重共享使得特征提取有效和高效。
批量归一化(Batch Normalization)表明,如果网络的输入具有零均值,单位方差和去相关,则深层网络的收敛速度会加快。有关进一步表明,使中间层的输出具有这些属性也是有利的。批处理归一化就是这样一种技术,它用于在每次迭代时,对馈送到网络中的中间层的数据子集在输出进行归一化。
用于解决ReLU的神经元死亡现象,LeaklyReLU被提出。LeaklyReLU通过把x的非常小的线性分量给予负输入来调整负值的零梯度问题;此外其也扩大的函数的y的范围。
# 对于一次卷积操作进行封装
NORM_LAYERS = {'bn': nn.BatchNorm2d,'in': nn.InstanceNorm2d,'ln': nn.LayerNorm}
class ConvBlock(nn.Module):
def__init__(self,in_fea,out_fea,kernel_size=3,stride=1,padding=1,norm='bn',relu_slop=0.2,dropout=None):
'''
Standard convolution operation
: param in_fea: Number of channels of input
: param out fea: Number of channels of output
: param kernel_size: Size of the convolution kernel
: param stride: Step size of the convolution
: param padding: Zero-fill width
: param norm: The means of normalization
: param relu_slop: Parameters of relu
: param dropout: Whether to apply dropout
'''
super(convBlock,self)._init_()
# 构造卷积
layers = [nn.Conv2d(in_channels=in_fea, out_channels=out_fea, kernel_size=kernel_size, stride=stride, padding=padding)]
# 批归一化层
if norm in NORM_LAYERS:
layers.append(NORM_LAYERS[norm](out_fea))
# 激活函数层
layers.append(nn.LeakyReLU(relu_slop, inplace=True))
if dropout:
layers. append(nn.Dropout2d(0.8))
self.layers = nn.Sequential( *layers)
def forward(self,×):
'''
:param x: Input Image
:return:
'''
return self.layers(x)
损失函数:
InversionNet的末端采用的标准损失函数是L1规范的损失函数。(但平常在进行训练和测试时,使用L2更多一些,效果好一些)

其中是真实速度模型,
预测速度模型,n是速度模型中空间像素的数量。输出的最后,我们会裁剪输出层以符合目标速度模型的大小。
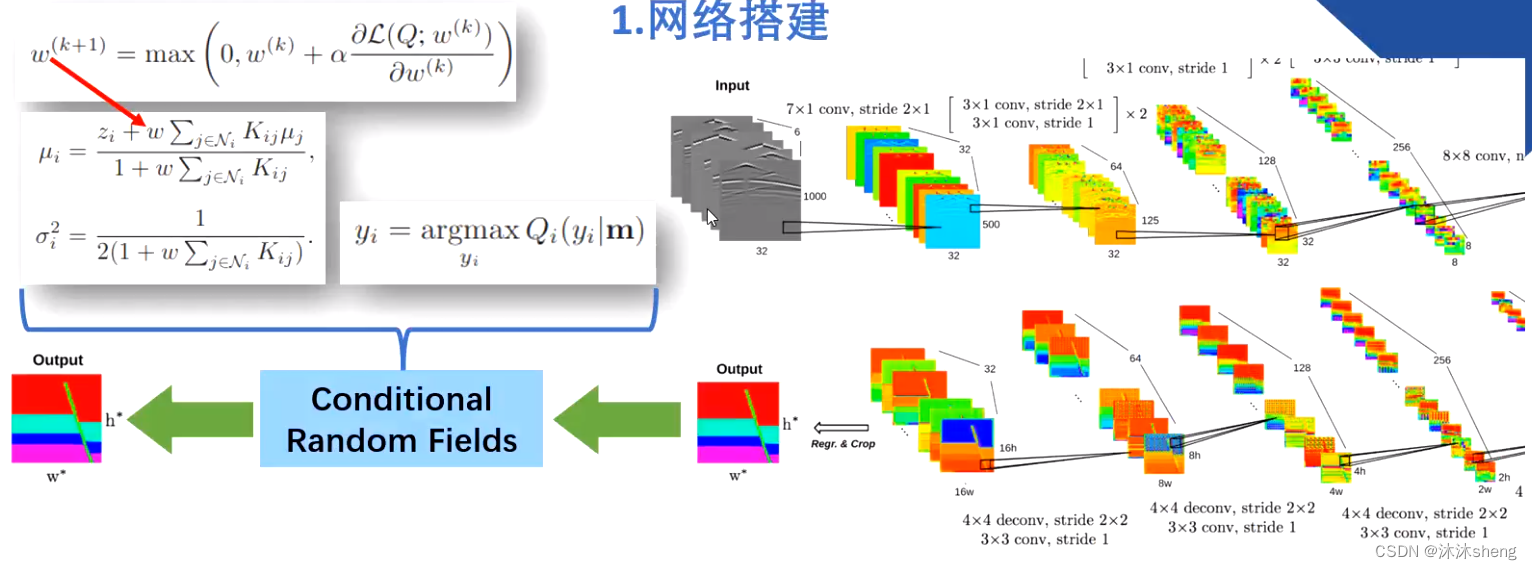
使用L1损失训练的CNN无法完全捕捉速度模型的结构特征,因为它没有对每个位置之间的相互作用进行建模。为了更好地反映地质特征,即速度在每个地下层内保持一致,我们构建了一个局部连接的CRF(Conditional Random Fields)来改进CNN预测的速度模型。
class InversionNet(nn.Module):
# dim:通道数,5是起始通道数
# input:(,5,1000,70)
def __init__(self, dim1=32, dim2=64, dim3=128, dim4=256, dim5=512, sample_spatial=1.0, **kwargs):
super(InversionNet, self).__init__()
# 一共8次
# 时间域的第一次降维,通过一批(32个)卷积来进行降维,(,32,500,70),H:1000->H:500
self.convblock1 = ConvBlock(5, dim1, kernel_size=(7, 1), stride=(2, 1), padding=(3, 0))
# 时间域的第二次降维,通过两批(64个)卷积来进行降维,(,64,250,70),H:500->H:250
# 每次下采样,需要两个卷积操作,第一个改变了图像尺寸,第二个没有改变,减小了计算量,空间使用量会更小
self.convblock2_1 = ConvBlock(dim1, dim2, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))
self.convblock2_2 = ConvBlock(dim2, dim2, kernel_size=(3, 1), padding=(1, 0))
# 时间域的第三次降维,通过两批(64个)卷积来进行降维,(,64,125,70),H:250->H:125
self.convblock3_1 = ConvBlock(dim2, dim2, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))
self.convblock3_2 = ConvBlock(dim2, dim2, kernel_size=(3, 1), padding=(1, 0))
# 时间域的第四次降维,通过两批(64个)卷积来进行降维,(,128,63,70),H:125->H:63
self.convblock4_1 = ConvBlock(dim2, dim3, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))
self.convblock4_2 = ConvBlock(dim3, dim3, kernel_size=(3, 1), padding=(1, 0))
# 单方向降维结束,进入两个方向同时的降维。(,128,32,35),W:70->35 W:63->32
self.convblock5_1 = ConvBlock(dim3, dim3, stride=2)
self.convblock5_2 = ConvBlock(dim3, dim3)
# 两个方向同时的降维。(,256,16,18),W:35->18 W:32->16
self.convblock6_1 = ConvBlock(dim3, dim4, stride=2)
self.convblock6_2 = ConvBlock(dim4, dim4)
# 两个方向同时的降维。(,256,8,9),W:16->8 W:16->8
self.convblock7_1 = ConvBlock(dim4, dim4, stride=2)
self.convblock7_2 = ConvBlock(dim4, dim4)
# 512通道数,(512,1,1),失去空间信息
self.convblock8 = ConvBlock(dim4, dim5, kernel_size=(8, ceil(70 * sample_spatial / 8)), padding=0)
self.deconv1_1 = DeconvBlock(dim5, dim5, kernel_size=5)
self.deconv1_2 = ConvBlock(dim5, dim5)
self.deconv2_1 = DeconvBlock(dim5, dim4, kernel_size=4, stride=2, padding=1)
self.deconv2_2 = ConvBlock(dim4, dim4)
self.deconv3_1 = DeconvBlock(dim4, dim3, kernel_size=4, stride=2, padding=1)
self.deconv3_2 = ConvBlock(dim3, dim3)
self.deconv4_1 = DeconvBlock(dim3, dim2, kernel_size=4, stride=2, padding=1)
self.deconv4_2 = ConvBlock(dim2, dim2)
self.deconv5_1 = DeconvBlock(dim2, dim1, kernel_size=4, stride=2, padding=1)
self.deconv5_2 = ConvBlock(dim1, dim1)
# 裁剪输出层
self.deconv6 = ConvBlock_Tanh(dim1, 1)
def forward(self, x):
# Encoder Part
x = self.convblock1(x) # (None, 32, 500, 70)
x = self.convblock2_1(x) # (None, 64, 250, 70)
x = self.convblock2_2(x) # (None, 64, 250, 70)
x = self.convblock3_1(x) # (None, 64, 125, 70)
x = self.convblock3_2(x) # (None, 64, 125, 70)
x = self.convblock4_1(x) # (None, 128, 63, 70)
x = self.convblock4_2(x) # (None, 128, 63, 70)
x = self.convblock5_1(x) # (None, 128, 32, 35)
x = self.convblock5_2(x) # (None, 128, 32, 35)
x = self.convblock6_1(x) # (None, 256, 16, 18)
x = self.convblock6_2(x) # (None, 256, 16, 18)
x = self.convblock7_1(x) # (None, 256, 8, 9)
x = self.convblock7_2(x) # (None, 256, 8, 9)
x = self.convblock8(x) # (None, 512, 1, 1)
# Decoder Part
x = self.deconv1_1(x) # (None, 512, 5, 5)
x = self.deconv1_2(x) # (None, 512, 5, 5)
x = self.deconv2_1(x) # (None, 256, 10, 10)
x = self.deconv2_2(x) # (None, 256, 10, 10)
x = self.deconv3_1(x) # (None, 128, 20, 20)
x = self.deconv3_2(x) # (None, 128, 20, 20)
x = self.deconv4_1(x) # (None, 64, 40, 40)
x = self.deconv4_2(x) # (None, 64, 40, 40)
x = self.deconv5_1(x) # (None, 32, 80, 80)
x = self.deconv5_2(x) # (None, 32, 80, 80)
x = F.pad(x, [-5, -5, -5, -5], mode="constant", value=0) # (None, 32, 70, 70) 125, 100
x = self.deconv6(x) # (None, 1, 70, 70)
return x
后续了解pytorch构建CNN的流程 。















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









