






常用shell指令
ls
ls 查看当前目录下包含的内容
ls -a 查看当前目录下包含的内容包括以.开头
ls -l 查看当前目录下的内容,以长列表格形式进行显示
ls -l -h 查看当前目录下的内容,以长列表格形式进行显示,单位为KMG等
ls -lh ls -lha / 查看根目录下的所有文件包括隐藏文件以长列表格式显示单位为KMG
cd
cd 目录 切换路径到指定目录下 cd -->cd ~ 切换路径到家目录下
cd . 进入当前目录
cd .. 进入上一级目录
cd - 回到上一次操作的路径,且在终端打印绝对路径
touch
功能:创建文件,如果存在同名文件,则时间戳发生修改,且不识别后缀名
touch 文件名 在当前目录下创建文件
touch 文件1 文件2 .. 在当前目录下创建多个文件
mkdir
功能:创建目录
mkdir 目录1 目录2... 在当前目录下创建一个或多个目录
mkdir 目录1/目录2 在指定目录1下创建一个目录2,目录1必须存在
mkdir 目录1/目录2 -p 如果目录1存在则不报错,如果目录1不存在则创建目录1
rm
删除文件:
rm 文件1 文件2... 删除一个或多个文件 删除目录
rm 目录1 目录2... -r 递归删除目录以及目录的内容
passwd
passwd 用户名 ------>修改超级用户的密码(+sudo) (密码不会在终端回显)
su 用户名----->切换用户
su ----->如果不加用户名,默认切换到超级用户
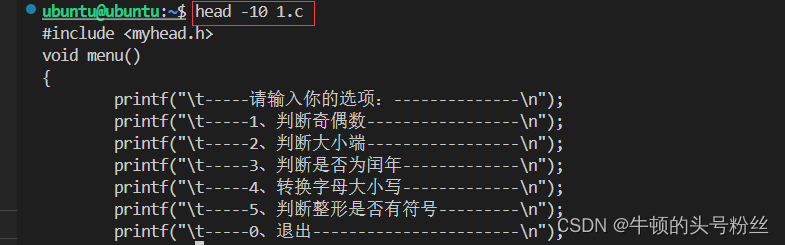
head
- head 文件名 ---->回显文件的前10行到终端
- head -n 文件名 ----->回显文件的前n行
显示了文件内容前10行
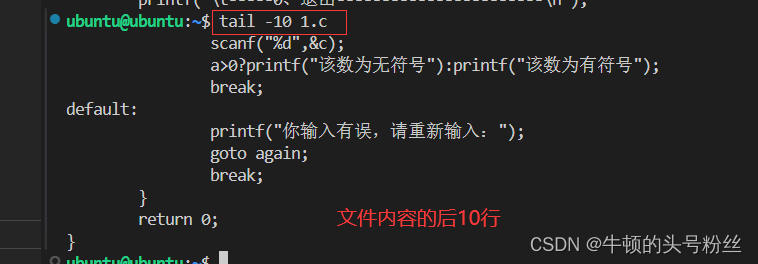
tail
- tail 文件名 ---->回显文件的后10行到终端
- ‘tail -n 文件名 ----->回显文件的后n行
| 管道符
shell 指令1 | shell 指令2
将shell指令1的输出结果,用作shell指令2的输入 (把前一条指令的输出,用作后一条指令的输入)
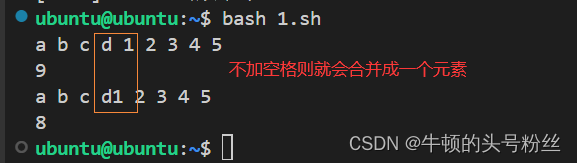
先是1.c文件的前10行,再把前10行的最后两行打印
可以观察到为举例head中的最后两行

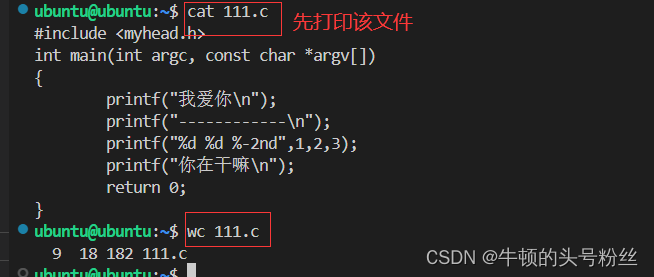
wc
- wc 文件名 ----->回显文件行数、单词数和字符个数
- wc -l 文件名 ----->回显文件的行数
- wc -w 文件名 ----->回显文件中单词的个数
- wc -c 文件名 ----->回显文件中字符的个数
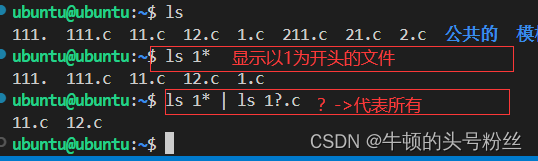
* ?[ ] 通配符
- *:通配一个或多个字符(相当于省略的意思)
- ?:通配一个字符(替代一个字符)
- [ ]:通配[ ]内的一个或多个字符([ ]相当于一个集合)
- [abc]:通配abc中的任一个字符
- [1-3abc]:通配123和abc中的任一个字符
- [[:lower:]]:通配所有的小写字母
- [[:upper:]]:通配所有的大写字母
file *
file 文件名 ----->显示文件的信息
file a.out
a.out: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=ddf53ec1d5d804bb4f6199e18b0de27eafb3807f, for GNU/Linux 3.2.0, not stripped
a.out: 这是文件名,表明这是编译后的输出文件,默认情况下,早期Unix-like系统中编译生成的可执行文件默认命名为a.out。
ELF 64-bit LSB shared object: 表明该文件是一个采用ELF格式的64位(x86-64架构)小端字节序(LSB,Little-Endian)的共享对象(动态链接库)。ELF是一种广泛使用的可执行文件格式,支持多种操作系统和体系结构。
x86-64: 指定该文件适用于基于x86-64(AMD64或Intel 64)处理器架构的系统。
version 1 (SYSV): 表示这个ELF文件遵循System V ABI(应用程序二进制接口)的第1版标准。System V是Unix操作系统的一个重要分支,其ABI定义了程序如何与操作系统交互的标准。
dynamically linked: 意味着这个共享对象在运行时需要与其他库文件一起链接,而不是静态地将所有依赖包含在内。这样可以减少内存占用和便于库的更新。
interpreter /lib64/ld-linux-x86-64.so.2: 指定了解释器路径,即负责加载这个共享对象和解析其动态链接信息的程序。这里是64位Linux系统的标准动态链接器(loader)。
BuildID[sha1]=ddf53ec1d5d804bb4f6199e18b0de27eafb3807f: 这是一个构建ID,用于唯一标识编译产物。这里使用SHA-1哈希值表示,有助于调试和识别特定的二进制版本。
for GNU/Linux 3.2.0: 表示该文件是为基于GNU/Linux内核版本3.2.0或兼容的系统编译的。虽然通常现代系统对较旧的库有较好的向后兼容性,但这提示了其预期的最低系统要求。
not stripped: 表明这个文件没有经过“剥离”处理。未剥离的文件包含了调试信息,如符号表,这对于开发者调试非常有用,但会使文件体积增大。相比之下,"stripped"版本会移除这些调试信息,更适合部署和生产环境使用。(简单来说就是文件没有被压缩)
grep
- grep [选项] 按字符串查找内容
- grep 要查找的字符串 要查找的路径 参数 (grep的查找路径,只能是文件或输入流)
- -n:回显查找到的行数
- -R:查找路径可以是目录,-R会进行递归查找
- -i:不区分大小写的查找
- -w:按单词查找关键字
- grep "^ubuntu" /etc/passwd -n 查找以Ubuntu开头的一行(字符用" ")
- grep ";$" 1.c 查找1.c中以;结尾的一行


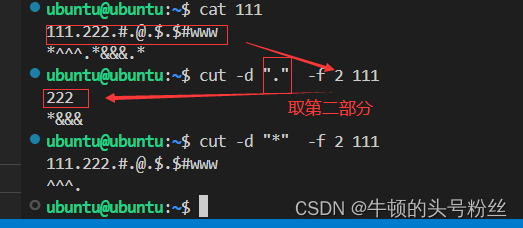
cut
- cut -d "分隔符" -f "要截取的域" 文件名 grep root /etc/passwd -wn |
- cut -d ":" -f "1,8" ---->(-f "1,8" 截取第1个和第8个域)
cut是作用于每一行
网络连接模式
Linux中网络三种模式
- 桥接模式:主机和虚拟机分别拥有不同的ip地址,可以实现和外界设备通信
- NAT模式:也可以联网,但是和主机共用同一个ip地址,外界无法识别虚拟机和主机发送的信息
- 仅主机模式:不能联网,只能和主机通信
下载软件
更新Linux软件源
更新Ubuntu下载软件的来源
因为Ubuntu默认的是国外的软件源,所以更新成国内的软件源,更方便快捷
国内的软件源及地址:
阿里源:
1、将原来的软件源保存一份(备份防止出错),
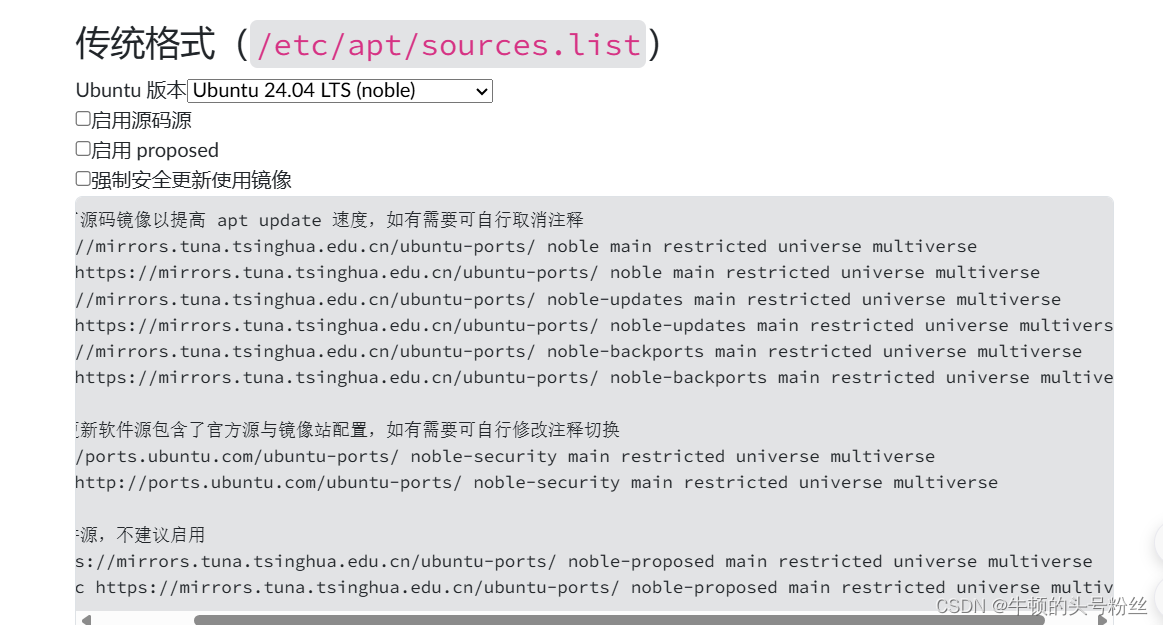
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
2、sudo vim /etc/apt/source.list文件,把从网页中拷贝的清华源的内容,复制到sources.list中 wq!强制保存退出
下载软件并安装
sudo apt-get install 【软件名】
下载软件包
sudo apt-get download 【软件名】(离线后可以再安装)
运行软件
直接在终端输入软件名
查看解释手册
man [软件名]
卸载软件
sudo apt-get remove 【软件名】(注册文件将会保留)
sudo apt-get remove --purge 【软件名】(完全卸载,删除配置文件)
清除默认下载路径的安装包
sudo apt-get clean
默认下载路径:/var/cache/apt/archives/
更新软件
sudo apt-get upgrade 【软件名】
压缩和打包
Linux下存在大量文件目录,我们需要整理好和处理它,就必须使用打包和压缩是两个相关但不相同的操作,它们通常一起使用来更有效地管理文件和目录,尤其是对于备份或传输大量数据时。
压缩文件和解压
三种压缩工具:gz、bz2、xz
gzip 要压缩的文件名 ------>自动生成.gz后缀的压缩文件
bzip2 要压缩的文件名 ------>自动生成.bz2后缀的压缩文件
xz 要压缩的文件名 ------>自动生成.xz后缀的压缩文件
例:
另外两种效果一样
ps:压缩后源文件不存在且不能对目录操作(打包可以)

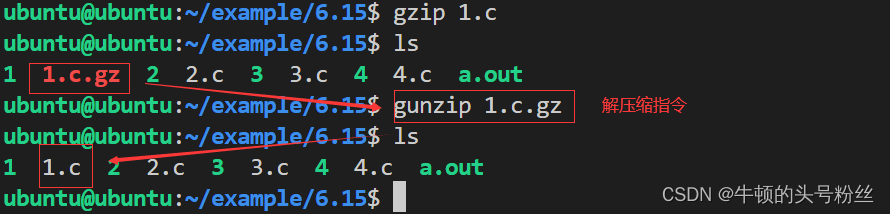
指定后缀的文件,需要用相同的压缩工具进行解压缩
gunzip 要解压缩的文件名
bunzip2 要解压缩的文件名
unxz 要解压缩的文件名
例:
压缩效果
压缩效率:xz > bz2 > gz
压缩时间:xz > bz2 > gz
gz用于临时的传输,xz用于文件的长期存储
打包压缩和拆包解压缩
不会影响源文件且可以对目录操作
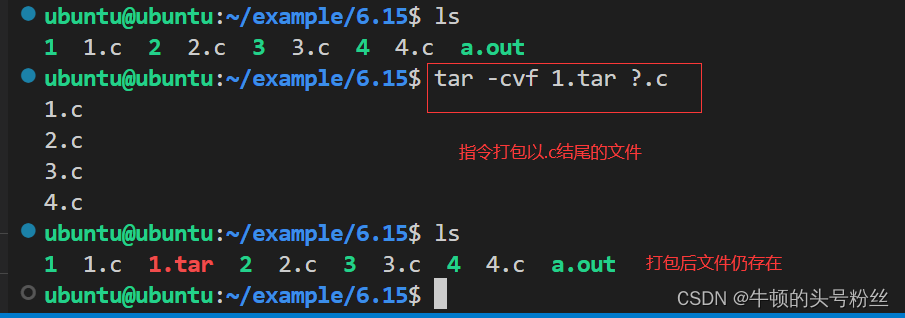
打包
tar -cvf 打包后生成的文件名.tar 要打包的文件
-c:用于打包的参数
-v:显示打包的过程(可以加也可以不加)
-f:跟要生成的文件名
打包压缩
-j:使用bz2工具完成压缩
-J:使用xz工具完成压缩
-z:使用gz工具完成压缩
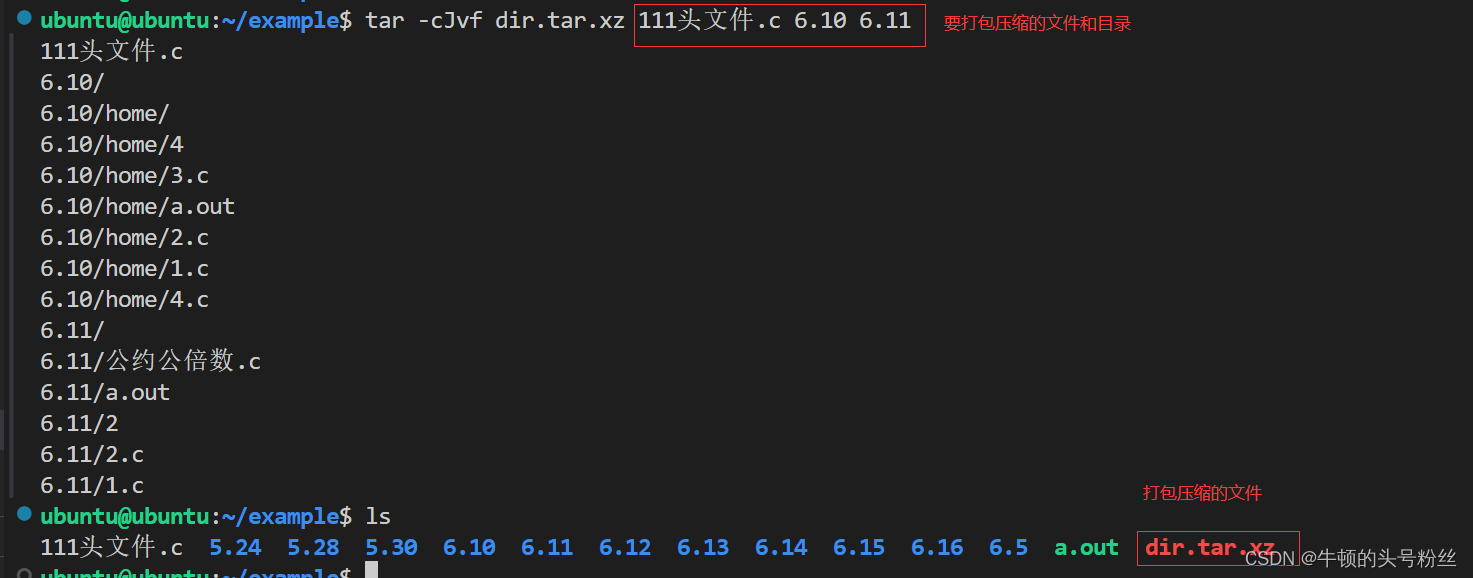
拆包
tar -xvf 要拆包的文件
-x:拆包参数
tar -xvf 要拆包解压缩的文件 (x是一个万能的拆包解压缩的指令,既可以拆包也可以解压缩)
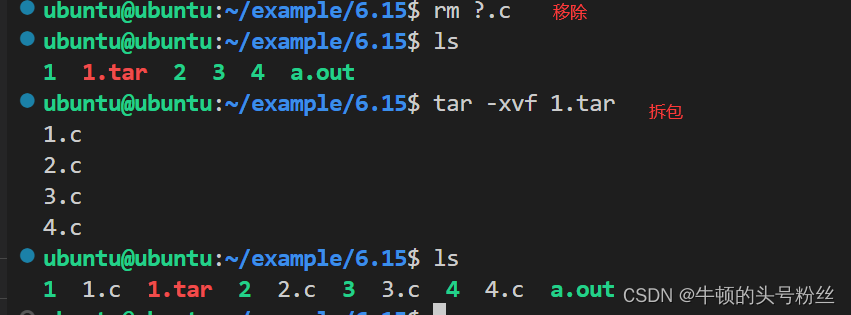
区别
打包是将多个文件整合为一个,便于整体处理;
而压缩则是减小文件的大小,节省存储空间。
在实际应用中,经常是先使用
tar命令打包文件和目录,然后再使用压缩工具如gzip、bzip2或xz对打包后的文件进行压缩,从而同时实现组织和减小体积的目的。一般常用打包后压缩处理;
ps:
有万能的拆包解压缩指令,没有万能的打包并压缩指令;
如果打包并压缩,后缀必须和压缩参数一致。
文件权限操作
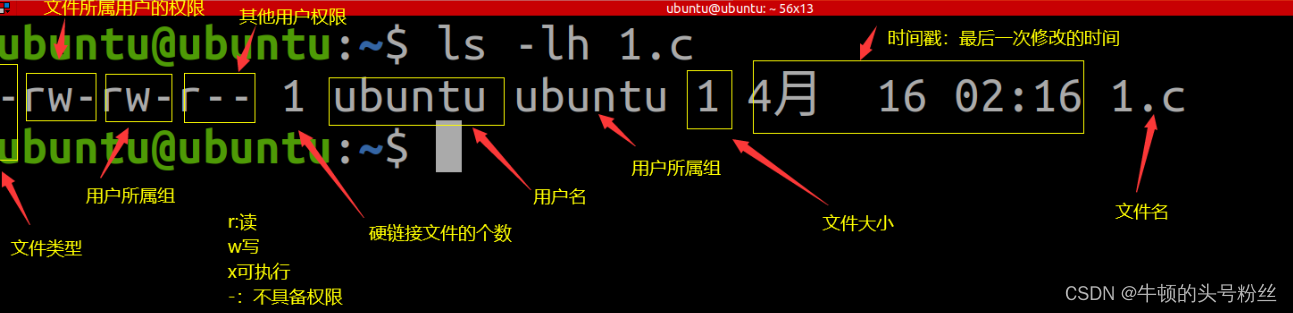
终端常用chmode
chgrp所属组
sudo chgrp [组名] [文件名]
chown所属用户
sudo chown [想要改的用户权限] [文件名]
sudo chown [想要改的所属用户和组的权限]: [文件名]
sudo chown :[想要改的所属组用户权限] [文件名]
sudo chown [想要改的所属用户] :[想要改的所属组] [文件名]
sudo chown root 1.c ---->将1.c文件的所属用户改为root用户
sudo chown root: 1.c ---->将1.c文件的所属用户和所属组用户改为root用户
sudo chown :ubuntu 1.c ---->将1.c文件的所属组用户改为ubuntu
sudo chown ubuntu:root 1.c ----->将1.c文件的所属用户改为ubuntu,将1.c的所属组用户改为root
链接文件的创建
硬链接(Hard Link)
硬链接实际上是一个文件的另一个名字,它直接指向文件的inode(索引节点)。每个硬链接都是文件实体的一部分,与原文件共享相同的inode和存储数据块。
ln 源文件 目标文件
软连接(Symbolic Link)
软链接是一个独立的文件,它包含的是对另一个文件或目录的路径名引用。软链接有自己的inode和数据块,其中存储的是目标文件的路径。
ln -s 源文件 目标文件
ln用法
我们可以通过ln --help 命令来获取帮助
ln基本语法:
ln [参数] 源文件或目录 目标文件或目录
ln命令可选参数:
-b:如果目标目录中已有同名的文件,那么在覆盖之前先进行备份(通常备份的文件后面加”~“)
-f:如果目标目录中已经有同名的文件,无需提示,直接覆盖
-i:如果目标目录中已经有同名的文件,则提示是否进行覆盖(y/n)
-s:创建软链接
-n:把软链接视为一般目录(后面有案例)
-v:详细显示操作进行的步骤,告诉我们谁链接了谁
-S:需要携带值如“-S=xx“;是替换通常使用的备份文件后缀
软硬区别
- 数据结构:硬链接共享inode,软链接有自己的inode和指向目标的路径。
- 跨文件系统:软链接可以跨文件系统,硬链接不可以。
- 目录链接:软链接可以链接到目录,硬链接一般不能。
- 删除效果:删除硬链接不影响文件内容,删除软链接或原文件会影响链接的有效性。
- 元数据:硬链接共享所有元数据,软链接独立且可能指向任何位置的文件。
- 详解Linux硬链接与软链接(ln命令)_软连接 ln-CSDN博客
用户相关操作
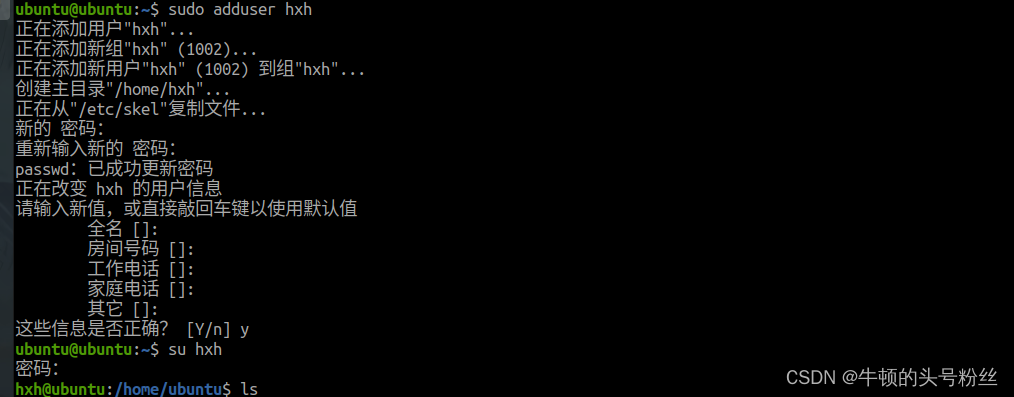
新建用户
sudo adduser [用户名]
修改用户信息
sudo usermod -c 新的描述信息 用户名 ----->开机界面显示的名字就是描述信息
sudo usermod -l 新的用户名 用户名
sudo usermod -m -d 新的家目录路径 用户名 ----->更改用户的家目录 -m:-MOVE -d:-HOME_DIR
sudo usermod -g 新的组名 用户名 ----->更改用户的所属组,需要保证新的组已经存在
删除用户
sudo deluser 用户名 ------>删除用户,但是不会删除用户的主目录(残留的主目录可以直接使用rm -r删除)
sudo userdel -r 用户名 ------>删除用户的同时,删除用户的主目录
磁盘相关操作
磁盘分区
查看磁盘使用情况:
df -h 如果U盘刚连入虚拟机,就可以使用df -h指令查找到,说明U盘被自动挂载
分区:
sudo fdisk /dev/sdb 要对整个磁盘进行分区
m:显示提示
p:打印已有的内存分区
n:新建分区
d:删除分区
q:不保存退出
w:写入磁盘并退出
格式化:
格式化操作,一般是对具体分区的格式化
sudo mkfs.文件系统类型 分区名
sudo mkfs.ntfs /dev/sdb1
挂载磁盘
在 Linux 中,挂载磁盘是将新的磁盘设备连接到文件系统的过程,使得该磁盘可用于存储和访问文件。挂载磁盘是一个常见的任务,尤其在添加新硬盘或使用外部存储设备时。以下是在 Linux 中挂载磁盘的基本步骤:
在挂载磁盘之前,首先需要查看系统中可用的磁盘设备。你可以使用 lsblk 命令来查看当前系统中的磁盘设备列表。
在挂载磁盘之前,你需要选择一个目录作为挂载点,用于访问磁盘中的文件。通常,你可以在 /mnt 或 /media 目录下创建一个新目录作为挂载点。
使用 mount 命令来挂载磁盘到指定的挂载点。
sudo mount /dev/sdb /mnt/my_disk成功挂载后,你可以使用 df 命令查看挂载结果。
如果你希望在系统重启后仍然保持磁盘的挂载状态,可以将挂载信息添加到 /etc/fstab 文件中。
sudo nano /etc/fstab取消挂载
如果想要取消挂载,用umount来实现
sudo umount /dev/sdb
shell脚本
语言分为C,C++等编译型语言和python,shell等解释型语言;
一个需要编译器,一个需要解释器
shell脚本以.sh结尾的文本。
操作系统框架:
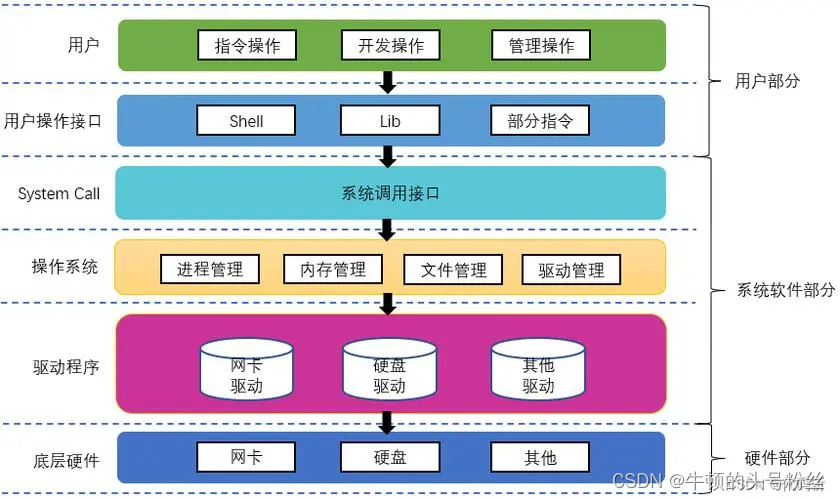
shell脚本主要起交互作用,极大地增强了系统的可管理性和灵活性。
shell脚本实现
#!/bin/bash ##说明使用的shell解析器
#! 用于指明该脚本默认使用的shell解析器
访问变量
变量名=变量的值
变量名='变量的值' ------>用于变量的值中间有空格时
变量名="变量的值" ------>用于使用已有变量的值和空格拼接给新变量赋值时(只要需要用已有变量的值都建议加"")
“=” 两侧不能有空格
“ '' ”内不能使用$展开变量的值
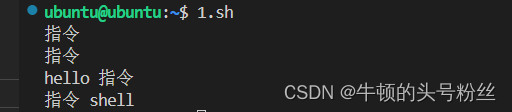
#!/bin/bash word1="指令" #赋值-->变量名=变量的值 word2="shell" echo $word1 #输出-->变量名 $表示输出变量的值 echo "$word1" #输出-->变量名 $表示输出变量的值 echo "hello $word1" #输出-->变量名 $表示输出变量的值 echo "${word1} ${word2}" #{}表示输出变量的值输出:
修饰变量的关键字
readonly:只读变量,值不能更改
unset:清空变量的值,不能清空
readonly类型变量的值 local:定义局部变量(函数再讲),只能在函数中使用
readonly word3="readonly" #只读变量 echo $word3 word3="666666" #尝试修改变量值 echo $word3 unset word3 #删除变量 echo $word3输出:

外部传参
在终端输入的时候可添加外部参数
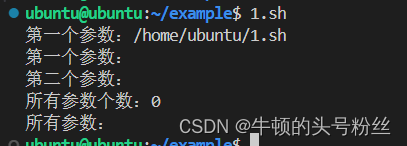
#!/bin/bash echo "第一个参数:$0" #表示当前脚本文件名 echo "第一个参数:$1" #表示第一个参数 echo "第二个参数:$2" #表示第二个参数 echo "所有参数个数:$#" #表示所有外部参数的个数(不包含脚本名) echo "所有参数:$*" #表示所有外部参数的个数(不包含脚本名)输出:

执行脚本
①bash 文件名 -->bash 1.sh
②./文件名 #前提文件要有可执行权限
③source 文件名
④文件名 #直接输入文件名,前提是当前路径要添加环境变量
输入输出
输入:
echo 输出内容(将内容回显到终端,并自动换行)
echo默认不解析转义字符
echo -n 输出内容 ------>取消
echo输出时的换行
echo -e "hello\n" ------->解析转义字符
输出:
read 变量名 ----->直接加变量名即可,可以读入带空格的数据
read -p "提示信息" 变量名 ------>在终端给用户输出提示信息
read -s 变量名 ------->输入的信息不回显
read -t 秒数 变量名 ------->如果n秒用户不输入,就结束输入向后执行语句
read -n 个数 变量名 ------->如果输入n个字符,自动停止
#!/bin/bash read -p "Please enter:" -s -n 5 -t 5 example read -p "Please enter:" test echo $test echo $example

数组
普通数组:
定义:
数组名=(初始值1 初始值2……)
ps:
#shell中的数组,不需要写出数组长度
#shell中数组初始化时,直接使用()
#shell中的数组每个元素之间是空格不是逗号
#访问仍然通过下标访问,并且下标仍然从0开始
访问:
只要在shell中需要使用变量的值,都要用$进行访问
${数组名[下标]} ----->获取数组中指定下标的元素的值
使用:
${数组名[*/@]} --------获取所有元素
${#数组名[*/@]} ------->获取数组中元素的个数
${#数组名[下标]} ------->获取数组中指定下标元素的长度(字符个数)
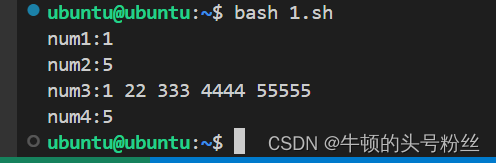
#!/bin/bash arr=(1 22 333 4444 55555) #定义数组 num1=${arr[0]} #获取数组元素 num2=${#arr[*]} #获取数组长度 num3=${arr[*]} #获取数组所有元素 num4=${#arr[4]} #获取数组最后一个元素的长度 echo "num1:$num1" echo "num2:$num2" echo "num3:$num3" echo "num4:$num4"输出:
稀疏数组:
定义:
与普通数组一样,唯一不同下标可以不连续,且稀疏数组中元素的个数,由不为空的数据的个数决定
#!/bin/bash arr[0]="hello" arr[2]="world" arr[4]="!" echo ${#arr[*]} echo ${arr[*]}输出:
数组间操作:
数组拼接
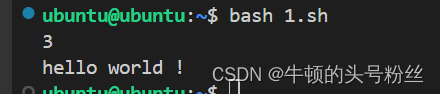
#!/bin/bash arr=(1 2 3 4 5) arr1=(a b c d) #定义一个arr2数组使用已有的arr和arr1数组赋值 arr2=(${arr1[*]} ${arr[*]}) #拼接加空格 arr3=(${arr1[*]}${arr[*]}) #拼接不加空格 echo ${arr2[*]} echo ${#arr2[*]} echo ${arr3[*]} echo ${#arr3[*]}输出:
shell运算
运算指令:(()) $[ ] let expr
(())
- (())几乎支持所有的C语言语法,还支持shell中的幂运算**
- ((表达式1,表达式2,表达式3,·······)) 每一个表达式都会执行,获取最右侧一个表达式的结果(相当于C语言中的逗号表达式)
- 想要获取运算的结果,需要使用$(()),还可以((变量名=表达式))
- 在(())中,使用变量的值,可以加$也可以不加$
- 在(())中,运算符两侧可以有空格
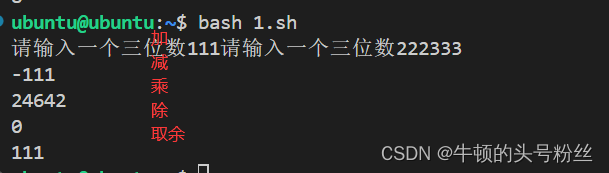
#!/bin/bash read -p "请输入一个三位数" -n 3 var1 read -p "请输入一个三位数" -n 3 var2 echo $((var1+var2)) echo $((var1-var2)) echo $((var1*var2)) echo $((var1/var2)) echo $((var1%var2))输出:
$[ ]
- 变量名=$[表达式1,表达式2,表达式3,·······]只获取最右侧表达式的结果
- 使用变量时,可以加$也可以不加$
- 运算符两侧可以加空格,也可以不加空格
- 仍然支持幂运算
- $[]的结果,建议直接按照"变量名=$[]"格式接收,因为$[]本质上,会遗留一个运算结果在表达式的位置,如果不接受继续向后运行指令会报错
#!/bin/bash num1=12 num2=30 echo $[$num1 + num2]
let
- let 变量名=表达式 ------>let和变量名中间一定要有空格
- let中使用变量,可以加$也可以不加$
- let运算时,运算符两侧一定不能有空格
- 如果直接写成 let 表达式,表达式会运行,但是没有办法接收
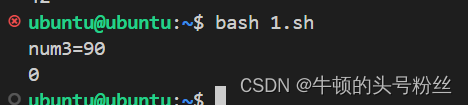
#!/bin/bash num1=90 num2=18 let num3=num1++ #使用num3接收num1++的结果 echo $num1 echo $num3
expr
expr为终端指令
- expr中使用变量,必须加$
- 如果想要接收expr的结果,必须使用命令置换符
- expr中运算符两侧必须有空格,不支持自增、自减和shell中的幂运算
- expr中使用某些运算符时,需要转义|、>、
- expr指令的结果,可以直接回显到终端上,可以使用命令置换符接收
- expr操作数的值不能为空
算术运算:
- num1 | num2 若ARG1 的值不为0,返回num1 ,否则返回num2
- num1 & num2 若两边的值都不为0,则返回num1 ,否则返回 0
- num1 < num2 num1小于num2(<= = != ……)
#!/bin/bash num1=90 num2=0 num3=`expr $num2 \| $num1` echo num3=$num3 expr $num2 \& $num1
字符串运算:
- match 字符串 表达式
返回表达式,在字符串中第一个位置起完全匹配成功的字符个数,如果能够匹配成功,返回值就是表达式中字符的个数
- substr 字符串 偏移量
长度 从字符串中偏移量的位置开始,截取指定长度的字串,偏移量从1开始
- index 字符串 字符
返回字符在字符串中第一次被查找到时的下标,下标从1开始
- length 字符串
计算字符串的长度
#!/bin/bash str1='hello world' str2='llo' expr match "$str1" $str2 #str2不能在str1中的第一个位置开始完全匹配返回0 expr match "$str1" "hello wor" #从第一位起匹配到的个数为9 expr substr "$str1" 7 5 #截取出子串world expr index "$str1" le #2 #如果查找多个字符在字符串中的位置,返回最先出现的字符的位置 expr length "$str1"
if分支结构
if语句是一种基本的流程控制结构,用于基于不同的条件执行不同的命令序列。Shell的if语句语法相对直观,类似于其他编程语言中的if语句。if [ 条件表达式 ]; then # 如果条件为真(true),则执行这里的命令 命令序列1 fi # 或者包含else部分 if [ 条件表达式 ]; then 命令序列1 else # 如果条件为假(false),则执行这里的命令 命令序列2 fi # 还可以加上elif(else if)用于更多的条件分支 if [ 条件表达式1 ]; then 命令序列1 elif [ 条件表达式2 ]; then 命令序列2 else 命令序列3 fi在Shell脚本中,
test是一个非常重要的命令,用于检查某个条件是否成立,并根据条件的真假返回一个退出状态码(返回值)。这个命令是编写条件逻辑的基础,经常与if语句配合使用,以根据不同的条件执行不同的命令序列。test返回值
- 如果条件表达式为真(即条件满足),
test命令返回0。- 如果条件表达式为假(即条件未满足),
test命令返回一个非零值(通常是1)。在Shell脚本中,可以通过
$?变量获取上一个命令的退出状态码。条件表达式选项:
数值比较:
n1 -eq n2:判断n1是否等于n2。n1 -ne n2:判断n1是否不等于n2。n1 -gt n2:判断n1是否大于n2。n1 -lt n2:判断n1是否小于n2。n1 -ge n2:判断n1是否大于等于n2。n1 -le n2:判断n1是否小于等于n2。字符串比较:
str1 = str2:判断str1是否等于str2。str1!= str2:判断str1是否不等于str2。-z str:判断字符串str的长度是否为 0 。-n str:判断字符串str的长度是否不为 0 。文件测试:
-e file:检查文件是否存在。-f file:检查文件是否为普通文件。-d file:检查文件是否为目录。-r file:检查文件是否可读。-w file:检查文件是否可写。-x file:检查文件是否可执行。例如:
num=10 if [ $num -gt 5 ]; then echo "$num 大于 5" elif [ $num -eq 5 ]; then echo "$num 等于 5" else echo "$num 小于 5" fi
case..in分支结构
在 Shell 脚本中,case 指令用于进行多分支条件判断。它允许根据一个变量或表达式的值,执行不同的命令或命令序列。
case 变量或表达式 in 模式 1) 命令 1 命令 2 ;; 模式 2) 命令 3 命令 4 ;; *) 默认命令序列 ;; esac以下是对语法的详细解释:
case:关键字,表示开始一个case语句。变量或表达式:要进行匹配的值。in:关键字,紧跟在变量或表达式后面。模式:用于与变量或表达式进行匹配的值或模式,可以是具体的值、范围、通配符等。模式后面必须以右括号)结束。- 命令序列:如果变量或表达式与某个模式匹配成功,就会执行该模式后面的命令序列。命令序列可以包含一条或多条命令,每条命令之间用换行符或分号
;分隔。最后一个命令后面可以跟两个分号;;,也可以将分号放在下一行。*):表示默认模式。如果变量或表达式与前面的所有模式都不匹配,就会执行默认模式后面的命令序列。esac:关键字,表示case语句的结束。
case指令的执行流程是:将变量或表达式的值依次与每个模式进行比较。如果找到匹配的模式,就执行该模式后面的命令序列,直到遇到;;为止,然后跳出case语句。如果没有找到匹配的模式,则执行*)后面的默认命令序列。
while循环结构
在Shell脚本中,
while循环是一种常用的控制结构,它允许你重复执行一段代码块,直到给定的条件不再满足为止。while循环的基本结构如下:while condition do # 循环体内的命令 command1 command2 ... done
condition: 这是一个表达式,用于测试真假(通常是0为真,非0为假)。只要这个条件为真(即返回0的状态码),循环就会持续执行。do: 标记循环体的开始。- 循环体内的命令: 在这一部分,你可以放置任意数量的Shell命令或语句,它们会在每次循环迭代中执行。
done: 标记循环体的结束。ps:
- 确保循环条件最终能够变为假,以避免创建无限循环。
- 可以使用
break命令提前退出循环,或使用continue跳过当前迭代的剩余部分。- 在循环体内修改控制循环条件的变量是非常重要的,否则可能会导致无限循环。
for循环结构
在Shell脚本中,
for循环是一种常用的循环结构,用于在给定的序列上迭代,重复执行一段代码块,直到序列中的所有元素都被处理完毕。Shell提供了几种不同类型的for循环,但最常见的是基于列表的循环和基于范围的循环(通过序列生成)。下面分别介绍这两种类型:基于列表的
for循环这种类型的
for循环遍历由空格分隔的元素列表。for variable in list do # 循环体内的命令 command1 command2 ... done
variable: 每次迭代中,列表中的一个元素会被赋值给这个变量。list: 由空格分隔的元素列表,可以是字符串、文件名、数字序列等。示例
打印列表中的每个元素:
for item in apple banana cherry do echo $item done遍历文件列表:
for file in *.txt do echo "Processing file: $file" # 这里可以放处理文件的命令 done基于序列生成的
for循环在某些Shell(如Bash)中,可以使用序列表达式来生成一个数字序列,然后遍历这个序列。
for ((initialization; condition; increment)) do # 循环体内的命令 command1 command2 ... done
initialization: 循环变量的初始值。condition: 继续循环的条件。increment: 每次迭代后对循环变量的更新。示例
从1数到5:
for ((i=1; i<=5; i++)) do echo $i doneps
- 确保循环条件最终能够变为假,以避免无限循环。
- 可以在循环体内使用
break和continue命令来控制循环流程。- 列表循环中,如果列表为空,则循环体一次也不会执行。
for循环在处理已知或可生成的元素序列时非常有用,无论是处理文件列表、数字序列还是简单的项目枚举。
select..in
在 shell 中,
select in是一种循环语句,用于增强交互性。它可以显示出带编号的菜单,用户输入不同的编号就可以选择不同的菜单,并执行相应的功能。这是 shell 独有的一种循环,在 C、C++、Java、Python 等其他编程语言中没有。其语法格式如下:
select 变量名 in 值1 (值2 …… 值n) do 语句或命令1 (……) (语句或命令n) done在
do和done之间,可以使用if或case语句根据变量的值执行相应的语句或命令,以实现不同的功能。例如,以下代码会询问你喜欢吃哪种水果,并显示出 4 个水果选项(apple、banana、orange、peach)以及一个退出循环的选项(exit):
echo "what is your favourite fruit?" select f in "apple" "banana" "orange" "peach" "exit" do if (($f == "exit")); then echo "bye" break else echo "you have selected $f" fi done执行上述代码后,它将显示类似如下的菜单:
what is your favourite fruit? 1) apple 2) banana 3) orange 4) peach 5) exit然后,根据你输入的菜单项前的数字,会显示相应的信息。例如,输入 1 会显示
you have selected apple,输入 5 会显示bye并结束循环。需要注意的是,
select是无限循环(死循环),输入空值(直接回车)或者输入的值无效时,都不会结束循环,只有遇到break语句或者按下 Ctrl+D 组合键才能结束循环。每次循环时,select都会要求用户输入菜单编号,并使用环境变量PS3的值作为提示符,PS3的默认值为#?,修改PS3的值就可以修改提示符。如果用户输入的菜单编号不在范围之内,会给变量赋一个空值;如果用户输入空值,会重新显示一遍菜单。
函数
在Shell脚本中,函数是一组命令的集合,它们被捆绑在一起并赋予一个名字,这样就可以像调用单个命令一样重复使用这些命令集合。函数使得代码更加模块化、易于理解、维护和重用。下面是Shell函数的基本概念和使用方法。
定义函数
在Shell脚本中定义函数的基本语法如下:
function_name() { # 函数体:可以包含任何合法的Shell命令和语句 command1 command2 ... }
function_name: 是函数的名称,遵循Shell变量命名规则,即只能包含字母、数字、下划线,且不能以数字开头。():紧跟函数名后面的圆括号,用来标识这是一个函数定义。{}:包围函数体的大括号,里面包含了当函数被调用时将执行的一系列命令。参数传递
函数可以接受参数,就像Shell脚本接受命令行参数一样。在函数体内,可以通过
$1,$2, ... 来访问这些参数,其中$1是第一个参数,$2是第二个,以此类推。$0通常代表函数名本身,但在一些Shell中(如 Bash),$0在函数上下文中没有定义或不适用。greet() { echo "Hello, $1!" } greet "Alice" # 调用函数,并传入参数"Alice"返回值
函数可以通过
return命令返回一个整数值作为退出状态码。默认情况下,如果函数正常结束而没有显式使用return,则返回最后一条命令的退出状态码。退出状态码的范围通常是0到255,其中0通常表示成功,非零值表示错误或其他特定状态。double() { local num=$1 echo $((num * 2)) return $? # 可选的,返回上一条命令(这里为echo)的退出状态码 } result=$(double 5) echo "Result is $result"局部变量
在函数内部定义的变量默认是局部变量,只在函数内部有效。如果需要在函数外也能访问这些变量,可以声明为全局变量(不推荐在函数中广泛使用全局变量,因为这会增加脚本的复杂性和潜在错误)。
my_function() { local local_var="I am local" global_var="I am global" echo "$local_var" } my_function echo "$global_var" # 输出 "I am global" # echo "$local_var" # 错误,因为local_var在此处不可见ps:
- 函数定义可以放在脚本的任何地方,但在调用前必须先定义。
- 使用
local关键字声明的变量仅在函数内部可见,有助于避免变量污染全局命名空间。- Shell函数不支持重载,即不能定义两个同名函数。
- 函数内部可以调用其他函数,包括自身(递归调用)。
环境变量的修改(PATH)
配置路径(PATH):最著名的环境变量之一是
PATH,它定义了系统在执行命令时搜索可执行文件的目录列表。这意味着用户可以从任何目录调用程序,而无需指定完整的路径。使代码更加灵活,所以运行shell脚本时可以直接在终端上输入 脚本名 即可。
只对当前终端有效
配置环境变量:
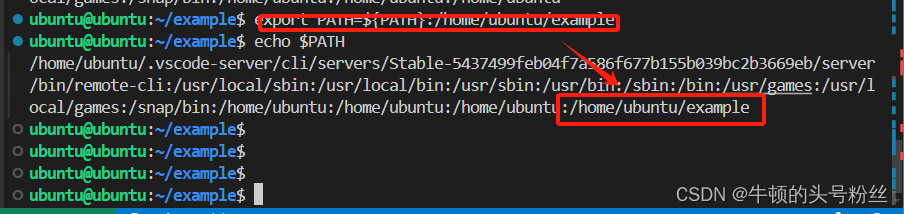
export PATH = ${PATH} : /home/ubuntu
export --》给系统变量赋值
PATH--》 被赋值的变量
= --》赋值
${PATH} --》拿到之前的PATH的值
: --》分隔
/home/ubuntu--》添加的路径
ps:次终端关闭后就要重新添加
只对当前用户有效
修改用户家目录下的~/.bashrc文件
由于是自己用户的家目录,所以不需要加sudo
vim ~/.bashrc ----->将export表达式(路径添加准确)添加在文件的最后一行
ps:重启或source ~/.bashrc 生效
对所有用户生效
①:
修改/etc/environment文件
sudo vim /etc/environment 、
文件中只有一行PATH的信息,将想要添加的路径,以 : 为分隔加到原有路径后面即可
ps:重启或source ~/etc/environment 生效
②:
修改/etc/bash.bashrc文件
sudo vim /etc/bash.bashrc 使用export表达式,添加路径
ps:重启或source ~/etc/bash.bashrc 生效
Makefile
基本作用
Makefile 是一个在 Unix 和类 Unix 系统(如 Linux 和 macOS)中常用的构建自动化工具。它通过允许用户编写一组规则来控制编译、链接等操作,从而自动编译程序或管理项目。Makefile 使得重复编译过程变得更加简单高效,特别是对于大型项目。
规则的基本结构
一个基本的 Makefile 规则由以下几部分组成:
-
目标(Target): 它是要创建的文件名或者是一个动作的名字(如
all,clean)。目标放在一行的最开始,后面跟着一个冒号:。 -
依赖(Prerequisites): 目标依赖的文件列表,紧跟在冒号后面,每个依赖项由空格分隔。
-
命令(Commands): 用于生成目标的 shell 命令序列,每条命令前必须以一个制表符(
\t)开始。
例如:
target: dependency1 dependency2
command1
command2示例解释
- target 是最终想要生成的文件或目标。
- dependency1 和 dependency2 是生成 target 所需的先决条件文件。如果这些依赖比目标文件新,那么Make会执行后面的命令来更新目标。
- command1 和 command2 是实际执行的shell命令,用于从依赖项构建目标。每条命令前的制表符非常重要,不能使用空格代替。
运算关系
在 Makefile 中,常见的赋值运算符包括 =、:=、?= 和 +=,它们具有不同的特点和用途,以下是对这些赋值条件的详细解释:
- 递归赋值(=):
- 延时变量,只有在被使用时才展开定义。
- 赋值操作可能会影响多个其他的变量,即所有与目标变量相关的其他变量都会受到影响。变量的值在使用时才会最终确定,并且可能会因为后续的赋值而发生变化。
- 例如:
x = foo
y = $(x)b
x = new
在上述示例中,最终 x 的值为 new,而 y 的值为 foo。因为 y 的值是在使用 $(x) 时确定的,此时 x 已经被重新赋值为 new。
- foo简单赋值(:=):
- 立即变量,定义时的赋值立即有效。
- 这种赋值方式只针对当前语句的变量有效,不会影响到其他地方对该变量的引用。它类似于其他编程语言中常规的赋值方式,在定义时就确定了变量的值,且不会因为后续其他地方对该变量的重新赋值而改变。
- 例如:
x := foo
y := $(x)
x := new
这里 x 的值为 new,但 y 的值仍然为 foo,因为 y 在定义时就已经确定为 $(x) 的值,即 foo,后续 x 的重新赋值不会影响到 y。
- 条件赋值(?=):
- 条件变量,当变量为空时才进行赋值。如果变量已经定义,则赋值无效。适用于第一次赋值的情况。
- 例如:
x := foo
y := $(x)b
x?= new
由于之前已经给 x 赋值为 foo,所以这里的 x?= new 不会生效,x 的值仍然是 foo。
- 追加赋值(+=):
- 原变量值之后加上一个新值,类似于字符串的添加。原变量值与新值之间由空格隔开。
- 例如:
x := foo
x += new
最终 x 的值为 foo new。
思维导图

















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









