









须知:该系列默认是在烧录好nvidia官方系统的jetson板子上操作的。
一、首先将我们训练好的模型导出为onnx格式的权重文件,这一步是在自己的电脑上或者服务器上进行的,如导出yolov5的onnx文件是在yolo官方代码的export.py文件进行操作的。在导出了onnx文件之后就可以将onnx文件拿到自己的板子上。
二、在jetson板子上我们可以通过netron来查看我们onnx模型的输入与输出(百度搜索netron)
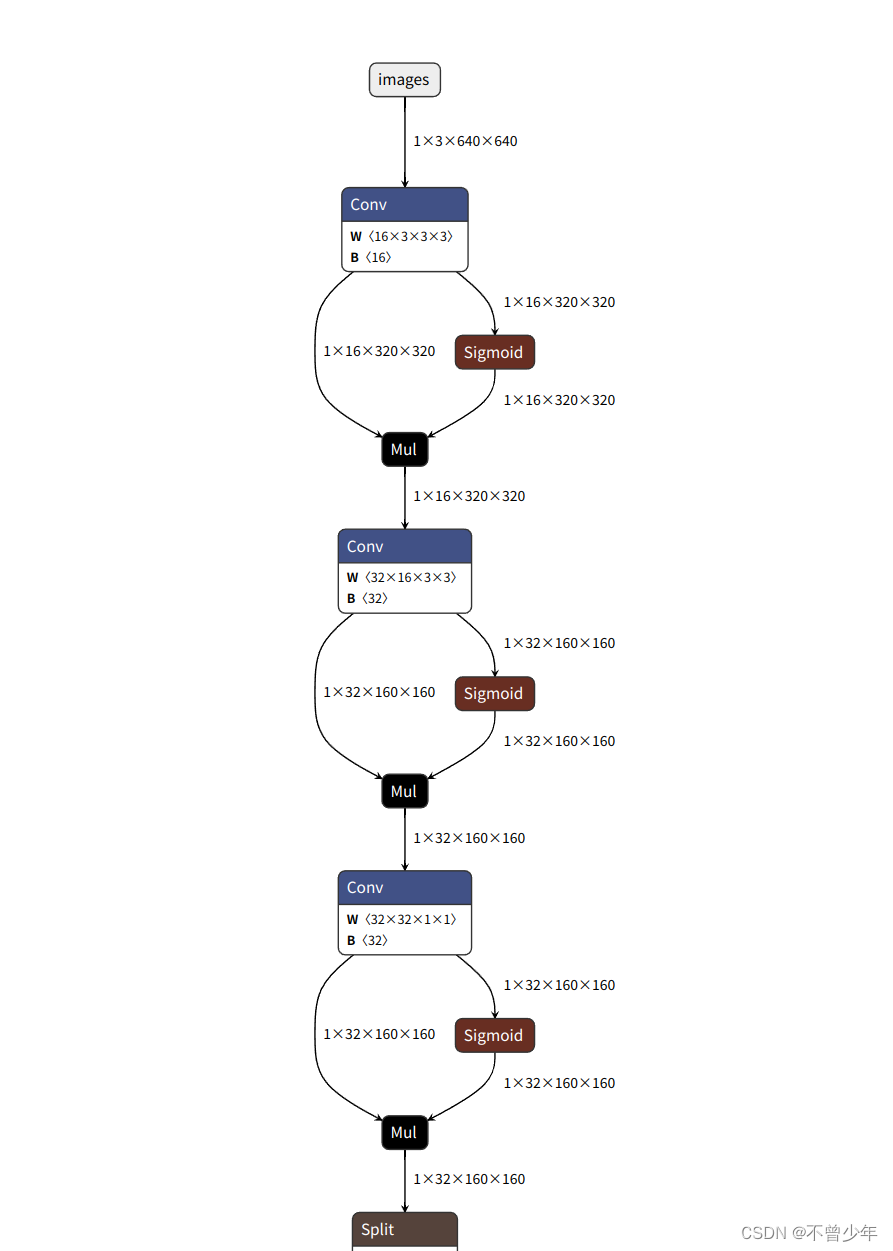
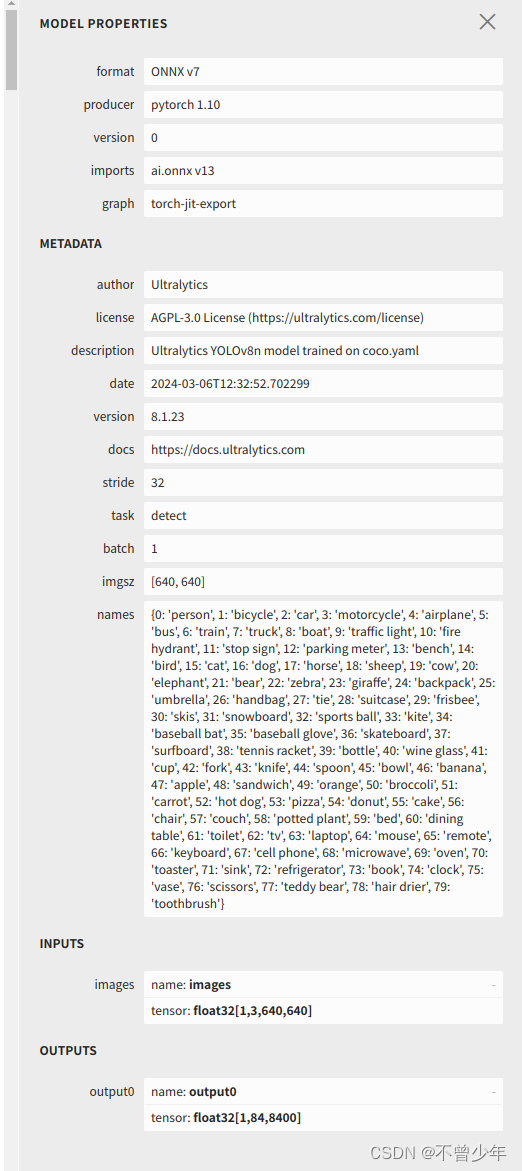
其中要注意模型的输入和输出的name,在后续推理的时候会用到。我的INPUTS的name为images,OUTPUTS为output0。
三、生成.engine文件
jetson如果烧录官方的系统是自带tensorrt的,所以不需要我们去安装。具体位置在
我们进入到bin文件中,在bin文件中打开终端:
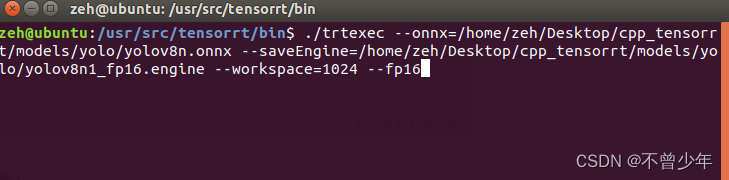
传入了四个参数:onnx位置、生成.engine文件位置、workspace、fp16量化。
其中fp16是对模型参数进行了量化加速,从fp32->fp16,也可以尝试进行int8量化,但最后预测的精度会降低。
运行后大概要等待五分钟,最后输出PASSED就代表通过了。















 866
866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









